吴恩达深度学习之二《改善深层神经网络:超参数调试、正则化以及优化》学习笔记
一、深度学习的实用层面
1.1 训练/开发/测试集
机器学习时代,数据集很小,可能100、1000、10000条,这种级别。可以按 70%、30% 划分训练集和测试集,训练后直接用测试集评估。或者按 60%、20%、20%划分训练集(train)、验证集(dev)、测试集(test),训练集上训练、验证集上验证调参,测试集上评估,这种划分对应于在80%训练集上做 4 折交叉验证。
大数据时代,数据量可能是百万级这样,此时训练集、验证集、测试集 98% / 1% / 1% 较好。对于超过百万级,按 99.5% / 0.25% / 0.25% 或者 99.5% / 0.4% / 0.1 % 这样。
测试集的目的是对模型做无偏评估,如果没有这个需要,只设验证集便可以了,此时验证集可以看作一个简单的测试集。
深度学习时代,还有一个特点是越来越多的人在训练和测试集分布不匹配下进行训练,吴恩达给出的建议是,要确保 验证集 和 测试集 同一分布,因为 你在验证集上评估并优化性能的模型最重要在测试集上无偏评估。
1.2 偏差/方差
吴恩达指出,偏差/方差易学难精。深度学习中,对偏差和方差的权衡研究甚浅,一般我们总是分开讨论偏差和方差。
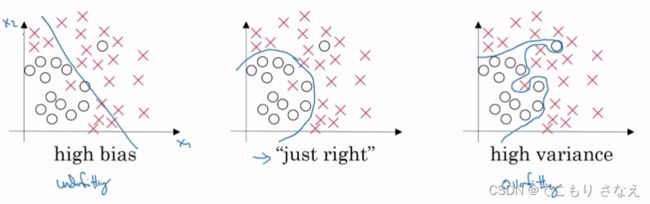
如图,机器学习课程也是这个例子
左边 高偏差 欠拟合,中间 刚刚好,右边 高方差 过拟合
博主的补充:当时学机器学习没细细考虑。高方差 为啥是 过拟合 呢。注意 这个方差 不是 线性回归代价函数的方差。这个方差 样本预测值的样本方差。换言之,形象化地来看,方差大 就是 样本预测值散布大,平滑性差,就是这种 波折比较大,来回拐的这种曲线,如右图所示。那个方差 实际上体现的是 偏差。然后 偏差的估算,一般 比如 可以用 样本标签值的期望 减去 样本预测值的期望。
高方差的具体表现是,在验证集上效果好,但是在测试集上效果不好。高偏差就是单纯误差高。
人眼的一般误差率称作最优误差,或贝叶斯误差。是否高偏差,要把贝叶斯误差考虑进去。
1.3 机器学习基础
首先在训练集上预测看效果,如果偏差大,解决方案有换用更大规模的神经网络、训练更长时间。当偏差较低时,在验证集上看方差,方差较大时,解决方案有增大数据规模、正则化、或者换用更好的神经网络模型,有时可能会一箭双雕,降低方差的同时偏差也变小了。
1.4 正则化
首先,对逻辑回归的正则化
代价函数 
加入正则化项后,代价函数变为
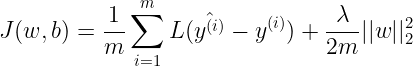
或
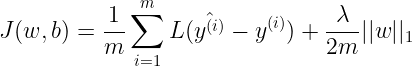
前者用的是对 参数向量 w 的 L2 范数,后者是 L1 范数
范数公式为


L1 范数做出来的结果会使得 w 很多项为 0 ,吴恩达说 很多人表示,这样可以使模型变得稀疏,可以压缩模型,而实际上模型存储内存并没有降低,吴恩达表示这并非 L1 范数的真正目的,真正目的是啥不知道。不过吴恩达表示 一般人都会默认选用 L2 范式。
所以一般可以把 L2 范式的下角标 2 省略掉,写作![]()
λ 是一个超参数,叫作正则化参数,需要注意的是 lambda 在 python 中是一个保留字段,如果我们要命名这样一个变量,通常会写作 lambd。
对神经网络,用的是各层范数之和,另外注意这把不是对向量 w 的范数,而是对矩阵 W
![\large J=\frac{1}{m}\sum_{i=1}^{m}L(\hat{y^{(i)}}-y^{(i)})+\sum_{l=1}^{L}\frac{\lambda}{2m}||W^{[l]}||_F^2](http://img.e-com-net.com/image/info8/5ac7bc8083204476a1bc5789c20df002.gif)
范数公式很简单,是每一个参数的平方和
![\large ||W^{[l]}||_F^2=\sum_{i=1}^{n^{[l-1]}}\sum_{j=1}^{[l]}(W_{ij}^{[l]})^{2}](http://img.e-com-net.com/image/info8/4fd8e6f6746d43d49b899d8322f274a6.gif)
因为一些原因,该范数不称作 L2 范数,而是称作 弗罗贝尼乌斯范数 Frobenius,用下标 F 表示
然后此时反向传播的公式中,多出的一项非常显然
![\large \frac{dJ}{dW^{[l]}}=(from\,\, backforward)+\frac{\lambda}{m}W^{[l]}](http://img.e-com-net.com/image/info8/f4f5138a7232470e96984ad913d28666.gif)
然后有意思的是,你把他写出来
![\large \begin{align*} W^{[l]}=W^{[l]}-\alpha((back forward)+\frac{\lambda}{m}W^{[l]}) \\ =(1-\frac{\alpha\lambda}{m})W^{[l]}-\alpha(back forward) \end{align*}](http://img.e-com-net.com/image/info8/10d83e7503d145cdbd9821f9821cd2ab.gif)
相当于给 ![]() 缩小到了
缩小到了  倍,然后再减去偏导数
倍,然后再减去偏导数
因此 L2 范数又称为 权重衰退
1.5 为什么正则化可以减少过拟合

一个解释是当 λ 很大时,W 会很小,趋近 0,很多隐藏单元几乎可以视作不存在,这就使得结果和逻辑回归差不多,但注意理解是这样,实际上只是作用变得很小,λ 太大可能导致偏差增大,欠拟合,但是有可能找到一个比较适合的 λ 使得刚刚好
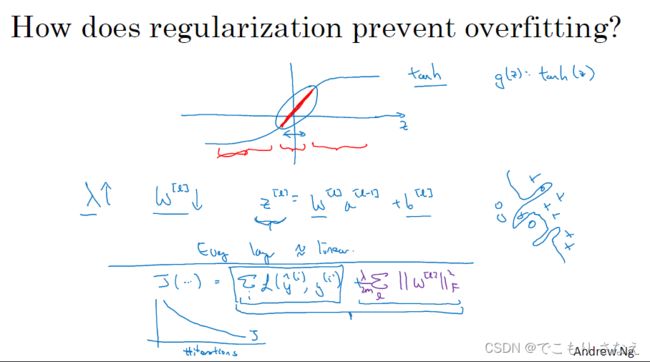
另一个解释是,λ 变大,W 变小,Z 也变小,Z 趋近 0,那么激活函数 tanh 的取值接近 0 附近,近似线性。我们知道线性层是没用的,当然比较极端的情况是没用。这里应该说降低影响到很小。
然后就是数据集本身过拟合的影响是没办法的,所以正则化无法保证完全消除模型的过拟合。
1.6 Dropout正则化

Dropout 正则化(随机失活正则化)也比较常用,它给每一层设定一个概率
对每一次迭代,按这个概率随机地删除一些结点,用删完的网络完成这一次正向传播和反向传播

实际应用中,我们用的都是优化版本 inverted dropout
对 Z = WA + b,在正向传播过程中,由于 dropout 的使用,计算结果的期望值变小了
于是比如 20%概率删除,即 keep-prob = 0.8,A 要除以 keep-prob 增大期望到正常值
图中给出了 dropout 的实现代码,用随机数跟 keep-prob 比较,得到一个布尔矩阵,和 A 直接相乘,便完成了按概率删除一些结点
然后一定要注意的是,测试集上绝对不要用 dropout,只有训练的时候能用
1.7 理解Dropout

dropout 功能上类似 L2,差别是 dropout 可以压缩权重。keep-prob 越小,相当于 L2 的 λ越大。另外 dropout 你可以每层选不同的 keep-prob,这更灵活,比如图中,结点多的层,更容易在这层出现过拟合,就把 keep-prob 设的小一点,结点少的就可以设的大一点,再就是输入输出层,不管多少,一定要设成 1.0,标签绝对不应该缺失,我们就是要预测出所有标签的,然后特征的话,特征一开始就缺失肯定会影响效果的。
dropout一般主要用于CV领域的一些大规模网络。
然后其缺点是代价函数 J 不再被明确定义,难以计算和确切判断。吴恩达的建议是,一般先关掉 keep-prob,确保代价函数单调递减后,再打开 keep-prob。
然后另一个缺点是随机性,这导致没法对模型复查,不可能反复检验,每次随机出的效果都不一样
1.8 其他正则化方法
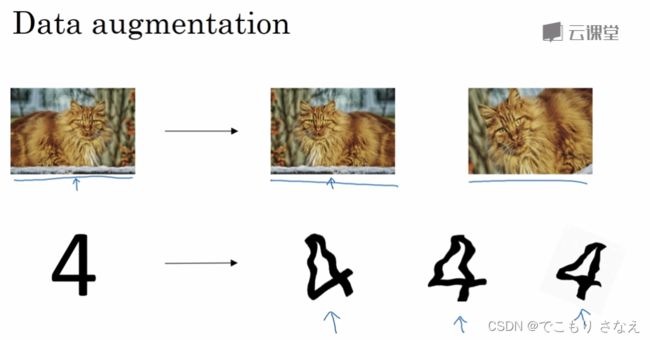
增大数据集、生成假训练数据,可以降低数据集的过拟合
对图片,方法有水平翻转,旋转,随机放大,轻微扭曲等,一般不会垂直翻转
这种人工生成的训练数据,要用算法检验其合理性,即它还是一只猫,还是一个4
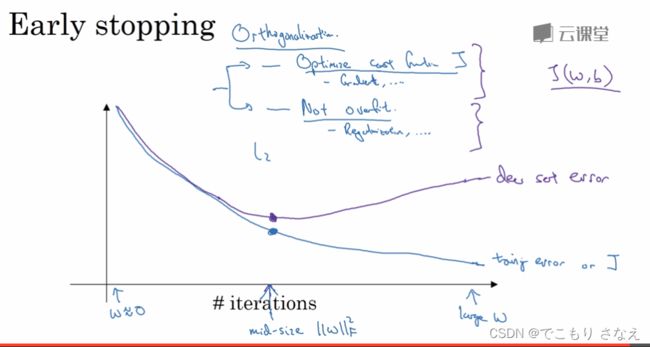
另一种方法是很直观的 early stopping,提前停止梯度下降
在训练集上的代价函数总是不断减小,在验证集上的代价函数总是先减小后增大
所以可以找到验证集上代价函数比较小的一个点,提前停止训练,从而消除过拟合
另外一个好处是,加快了网格搜索,可以尝试更多超参数
缺点是,相当于你放弃了让代价函数变得更小,这种方法相当于在 防止过拟合 和 优化代价函数 之间产生了 冲突矛盾。
1.9 正则化输入
正则化输入,或者叫归一化输入好一些,这是个翻译问题
就是概率学的
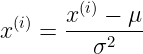
均值 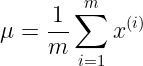
方差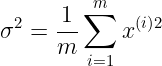
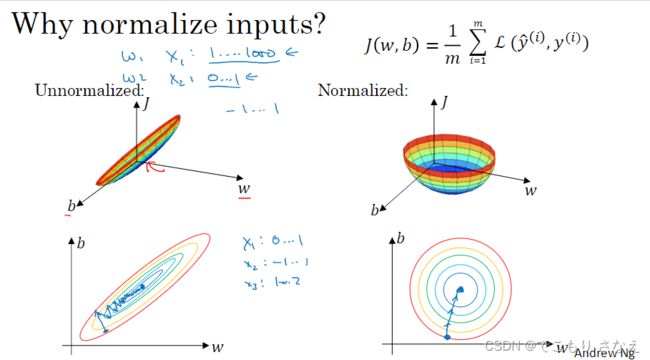
其好处如图所示,让代价函数更平均更对称,在任何位置都能更直接地梯度下降
需要注意的是,对训练集归一化,对测试集就也要归一化,均值和方差统一使用的是训练集的,而不是对测试集归一化用测试集的均值和方差
1.10 梯度消失或梯度爆炸
主要是在深层神经网络中的问题
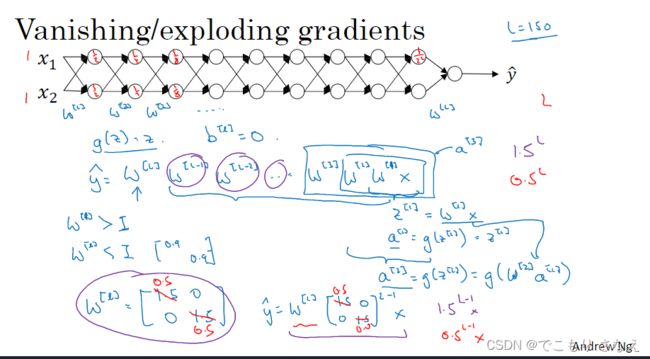
如图,一种极端的情况来理解,假设激活函数 g(z) = z
那么 y帽 实际上就 = 每层 W 的乘积
如果每层 W 都一样,那就是 W 的 L 次幂,指数爆炸
W > E,则 y帽 会非常大,W < E,则 y帽 会趋近 0,代价函数的值也是同理,跟 y帽 走
于是梯度下降会收敛得非常慢,训练难度很大,称之为梯度消失或梯度爆炸问题
这两个指的是同一件事,但更具体来讲,梯度消失指指数爆炸带来的收敛慢这个问题,梯度爆炸指数爆炸其本身太大或太小溢出得NaN
1.11 神经网络的权重初始化
为了消除梯度消失或梯度爆炸,归一化输入是一种解决方案
实际上权重初始化值也有影响
不妨思考 w 全等于 1 合理吗
我们知道 ![\large A^{[l]}=g^{[l]}(W^{[l]}A^{[l-1]}+b^{[l]})](http://img.e-com-net.com/image/info8/9ba44e9536cb43dca06386aa2f18490c.gif)
那么 ![]() 越大,计算出的结果也会越大
越大,计算出的结果也会越大
一般我们要控制 W.var 即 W 的方差在 1 或者 2,实际上就类似归一化的感觉
对 tanh 方差控制在 1 比较好,这时候相当于 W 乘根号 1/n^{[l-1]}
![]() ,称作 Xavier 初始化
,称作 Xavier 初始化
还有一种可以考虑的初始化是
![]()
然后对 RELU,实验证明 W.var 控制在 2 比价好,即
![]()
一般来说,权重的方差是一个超参数,设置方差即可
总体来讲这个方差几乎没太大影响,只是一个起点罢了,一般会放在最后来调整
1.12 梯度的数值逼近
即梯度检验的直观理解
就是判断

具体怎么用下节课讲
1.13 梯度检验
梯度检验,用于检查反向传播中是否有 bug
将所有 W、b 合在一起,构成一个大的向量 θ
对 θ 中的每一个数进行检验
![\large d\theta[i]](http://img.e-com-net.com/image/info8/c98b08b6c9154e7686b86f159091c772.gif) 即其这一轮要下降多少
即其这一轮要下降多少
![\large d\theta_{approx}[i]=\frac{J(\theta_1+\theta_2+...+(\theta_i+\varepsilon),...)-J(\theta_1+\theta_2+...+(\theta_i-\varepsilon),...)}{2\varepsilon}](http://img.e-com-net.com/image/info8/7d29e14d4f8e42e085191e1127f95991.gif)
即看这两个数是否相等
更进一步地,我们用如下公式来估计近似程度
 ,这个值如果小于等于
,这个值如果小于等于 ![]() 的数量级,那就没有问题
的数量级,那就没有问题
比如 ![]()
你算出的近似程度 小于等于 10^-7 那就没问题
比如你算出 10^-5 那可能有问题,要小心
比如你算出 10^-3 那肯定有问题,要检查
然后关于这个公式的补充
![]() 是向量 x 的欧几里得范数,或者叫欧几里得距离,就是平面两点间的线段距离
是向量 x 的欧几里得范数,或者叫欧几里得距离,就是平面两点间的线段距离
1.14 关于梯度检验的注记
五点注意事项
第一,梯度检验计算得很慢,不要在训练过程打开它,只在对训练 debug 的时候打开。
第二,当 ![]() 和
和 ![]() 差得很大的时候,要去看去检查每一项,找出有问题的那一层 W b。
差得很大的时候,要去看去检查每一项,找出有问题的那一层 W b。
第三,当使用正则化时,要注意 ![]() 和
和 ![]() 的正确计算。
的正确计算。
第四,对 dropout 没用。
第五,现实中一般不会出现的情况。可能对 W 趋近 0 的状况下梯度下降正常,但是大一点就不正常,这需要你 随机初始化 后,来做梯度检验。
二、优化算法
2.1 Mini-batch 梯度下降
使用大的数据集可以使得深度学习模型获得更好的效果,然而训练很慢,本章讲的优化算法可以加快训练,大大提高团队的效率
我们正常的,每次梯度下降都用整个数据集做计算的,叫作 batch 梯度下降,共计 1 个 batch,batch size 为 m
遍历整个数据集完成的一轮梯度下降是 1 个 epoch
对 mini-batch,比如对 m = 5000000 的数据集,比如设置 batch size = 1000,那么 batch number = 5000
我们将数据集 X 划分为(对 Y 同理)
![]()
其中,![]() ,其他
,其他![]() 同理,自己算即可
同理,自己算即可
这个 mini-batch 的 1 次 epoch 是 5000 次梯度下降
换句话说,我们每次不用整个训练集做梯度下降,而是每次一个 ![]()
那么问题来了,数据计算次数变了吗,博主认为没变,为什么训练变快了呢,吴恩达这里没有具体讲清楚,不妨回忆计组和操作系统的内容,我们每一层都要放进整个 A 做计算,如果 A 特别大,那么一次放不进,要分好几次,每层都会出现好几次频繁缺页,大量的缺页导致大量时间浪费在页面置换内存和外存间的 IO 上了。而 mini-batch 减小了每次得大小,使得尽可能不会出现缺页。
2.2 理解 mini-batch 梯度下降法
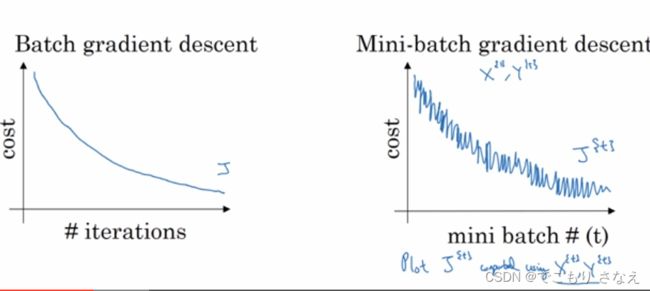
如图所示,mini-batch的代价函数并非单调递减,而是有一些噪声

如图所示
当 batch-size = m,实际上就变成了 batch
当 batch-size = 1,叫作 随机梯度下降 SGD
我们知道,机器学习中 SGD 真的很快,但是 神经网络中,SGD 一次只梯度下降一个样本,失去了向量化优势,并非就一定快
而且 SGD 效果真的差,它一定不会收敛,代价函数在最小值的一个范围内波动
实际上 mini-batch 也不一定收敛,可能会在一个小范围波动
降低学习率可以改善这个状况,叫作学习率的衰减,2.9中会讲到这个

batch size 怎么选
如图,原则上就是 X^{t} Y^{t} 的大小和 CPU/GPU 匹配
常用的是 64、128、256、512,可以挨个尝试,极其偶尔会尝试 1024
一定要 2 的次幂,读取效果更好,这也是根据硬件的原理来的
2.3~2.5 指数加权平均
首先要说的是,这一部分讲的内容,主要是给出公式,给出一个形象化的理解,没有涉及具体的应用,不要疑惑于图中的数据是怎样使用的,这只是一个用于优化算法的理论基础,具体使用根据不同算法有着不同的结合
对气温这类序列化数据,设 ![]() 是当天的真实平均温度,
是当天的真实平均温度,![]() 是当天拟合温度
是当天拟合温度
指数加权平均就是设一个超参数权重 ![]() ,令
,令
![]()
这样拟合的今天的温度就是包含了过去温度的影响,比直接的平均更为平滑
注意这是一个递推函数
令 ![]()
展开后你会发现
![]()
由于 ![]() ,
,![]() 会随 k 的增大而减小,换言之就是天数越早越久远,越不会产生影响
会随 k 的增大而减小,换言之就是天数越早越久远,越不会产生影响
![]() 取多大,取决于你要平均多少天的温度
取多大,取决于你要平均多少天的温度
![]()
当系数小于 0.35 时,可以认为没有影响
这里 ![]() 就是
就是 ![]()
于是你平均的天数是 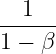
比如 ![]() ,那么你平均的就是 50 天
,那么你平均的就是 50 天
然后有一个问题是 ![]() ,那么
,那么 ![]() 等于多少呢
等于多少呢
没错,![]()
注意到什么问题了吗,若 ![]() ,那么 v1 只有正常平均值的 0.02 倍
,那么 v1 只有正常平均值的 0.02 倍
换言之开始的几个点都会很小,偏差很大
当然,如果你不需要预测前部,那么这个完全无所谓
但是,如果前面对你很重要,你就需要做 偏差修正
修正方式是 ![]()
随 t 增大,![]() 逐渐趋近 1,就没什么影响了,具体就不分析了,就是成功修正了前部
逐渐趋近 1,就没什么影响了,具体就不分析了,就是成功修正了前部
看一下下面的图
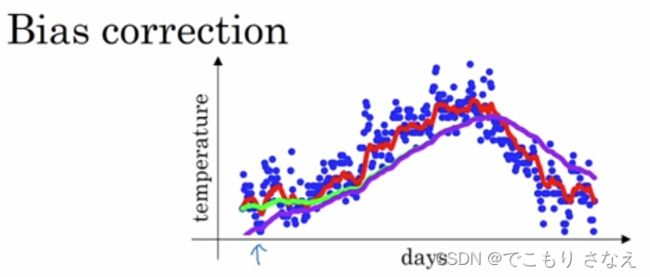
红色可能是 β = 0.9,绿色可能是 β = 0.98,β越大,加权平均的天数就越多,曲线就越平滑
注意实际上 0.98 应该是紫色那条线,开始几天非常的小,实际上 红绿是修正后的
然后要说的是,前几次会有偏差,具体前几次呢,不难想象,比如 0.9,就是前 10 次有偏差
2.6 动量梯度下降法

如图所示,梯度下降的过程中,尤其是 mini-batch,往往会在无关方向上来回摆动,比如图中的上下摆动
于是,不妨思考在梯度下降中,使用指数加权平均
![]()
![]()
可以想象一下,这样一个一个累加起来,就可以消掉无关方向上的位移
相关方向上的累加,让相关方向的下降不断以一个小幅度的加速度加快,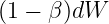 效果就和物理的加速度是一样的,于是称作动量梯度下降法 ( Momentum )
效果就和物理的加速度是一样的,于是称作动量梯度下降法 ( Momentum )
这个方法很好,比普通的梯度下降效率总是要快的
![]() 一般取 0.9,具有很强的鲁棒性,就是说适应大部分情况的意思
一般取 0.9,具有很强的鲁棒性,就是说适应大部分情况的意思
需要注意一开始梯度下降有点小,也就是前期的偏差问题,但是没有人会选择偏差修正,那样浪费的计算时间还不如不用,实际上对 ![]() 只需要熬过 10 次迭代,就可以正常且不断加速地下降,对于我们那么多次地迭代,这 10 次完全就是一个很小的数
只需要熬过 10 次迭代,就可以正常且不断加速地下降,对于我们那么多次地迭代,这 10 次完全就是一个很小的数
由于前期地偏差,也有人使用这种方法 ![]() ,这种的话效果也会很不错,但是
,这种的话效果也会很不错,但是 ![]() 比较难调,所以吴恩达建议用正常的那种方法
比较难调,所以吴恩达建议用正常的那种方法
然后这种优化算法下 ![]() 调得大一点也很难出现大幅偏离,所
调得大一点也很难出现大幅偏离,所 ![]() 可以调得大一点,学习起来就快了,
可以调得大一点,学习起来就快了, ![]() 和
和 ![]() 配合着来调,最后效果就会很不错
配合着来调,最后效果就会很不错
2.7 RMSprop
RMSprop 全称 root mean square prop 均方根传播
公式是
![]()
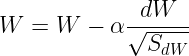
为什么这样做可行呢,回看上一节的图,你会发现,梯度下降总是在无关方向上步幅很大,在相关方向上步幅很小
对于一个越是大的数,平方后就越是大。换言之 W 中在无关方向上的项,就会被大幅除掉,相关方向上的项,除以的数就相对较小,再配合上一个较大的 ![]() ,便加快了学习速度
,便加快了学习速度
然后一个问题是,如果除以一个无穷小的数,就会导致结果无穷大
于是 一般 取 ![]()
做 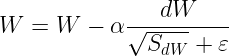
2.8 Adam 优化算法
Adam优化算法是对 偏差修正的 Momentum 和 RMSprop 的结合
是 Adaptive Moment Estimation 的缩写
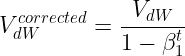


公式中,t 是迭代次数,注意两个 ![]() 和
和 ![]() 是不一样的
是不一样的
![]() 叫作第一炬,推荐使用 0.9
叫作第一炬,推荐使用 0.9
![]() 叫作第二炬,Adam的作者推荐 0.999
叫作第二炬,Adam的作者推荐 0.999
![]() 使用
使用 ![]()
实际上这些不用特意管,都是缺省值,没人去调,直接缺省值就可以了
2.9 学习率衰减
如果用 mini-batch 的话,一个问题是,它不会收敛,而是在一个小范围内来回振荡,学习率越大,这个范围就越大,所以学习率小,最后的结果就会好
一开始的话,学习率多大都无所谓,所以这就用到了学习率衰减

这是一个常用的方法,decay_rate 是衰减率,epoch_num 是第几代,![]() 是学习率初始值
是学习率初始值
其他的方法有:
指数衰减: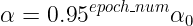
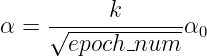 ,k 是自己设的一个常数
,k 是自己设的一个常数
 ,注意 t 是 batch_size,就是一个数据集中的第几个 batch
,注意 t 是 batch_size,就是一个数据集中的第几个 batch
还有一种是离散下降

虽然学习率衰减确实有效,但它不是最优先的,最后再开启并调参即可
2.10 局部最优问题
人们认为神经网络优化难的问题是大量极值点造成的
而实际上2014的一篇论文指出,高维和低维是不同的,有很多鞍点

如图,所有偏导为0,在一些方向上取极大值,在一些方向上取极小值的点,称作鞍点
对于极值点,我们总是会困在极值点处出不去
而对于鞍点,他所在的一带叫作 plateaus 平稳段,如图所示

实际上可以走出去的,只不过非常非常慢
实际上极值点几乎没有,在大量参数的神经网络高维空间中,你想象一下,不仅得每个参数偏导都等于零,每个参数方向上还都得同为极小或极大值才行,这个概率是非常小的,我们的模型其实不太容易困在极值点,反而是鞍点要比极值点多得多
我们从前总是认为困在极值点走不动了,实则不然,我们总是在平稳段缓慢下降,实际上大部分情况是有机会走出去的,而且只要走出去就万事大吉,我们需要一些成熟的观察法来调整,实际上Adam算法就能很好地解决这个问题
三、超参数调试、Batch正则化和程序框架
3.1 调试处理
重要性第一位:![]()
重要性第二位:![]() 、
、![]() 、
、![]()
重要性第三位:![]() 、
、![]()
如果用 Adam、缺省值 ![]() 即可,不用挑中
即可,不用挑中
机器学习中我们一般用网格搜索,深度学习超参数太多,当你无法确认哪个参数对你来说最重要最优先,一般建议随机搜索
然后还有一个策略是从粗糙到精细的搜索方法,使用网格或随机搜索,先在一个大范围搜索,看到几个比较好的点都聚集在某个小范围内,再到小范围进一步精细地搜索
3.2 为超参数选择合适的范围
比如隐藏层单元数 ![\large n^{[l]}](http://img.e-com-net.com/image/info8/c7dea524f73f41a6b2446445cb94a465.gif) 你觉得 50 到 100 比较合适,那就随机均匀取数试一试就好
你觉得 50 到 100 比较合适,那就随机均匀取数试一试就好
比如层数 layers 你觉得 2 到 4 比较合适,那就挨个试一试就好
但是比如学习率,范围 0.0001 到 1 比较好,不妨设想 小于 0.1 的概率约 1/10,小于 0.01 的概率越 1/100,实际上数量级小的几乎根本取不到,应该分别对不同数量级均匀随机
于是建议是,指数 [ -4 , 0 ] 随机,然后再用 ![]() 乘以一个随机数,或者直接用
乘以一个随机数,或者直接用 ![]() 也行
也行
![]()
对 momentum 的 ![]() 的建议是,
的建议是,![]() 太大始终处于偏差阶段对吧,这肯定会出问题的
太大始终处于偏差阶段对吧,这肯定会出问题的
所以范围建议 ![]()
然后这时候应该对 ![]() 在数量级内取,即
在数量级内取,即 ![]()
即 ![]() ,
,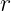 在
在 ![]()
3.3 超参数训练的实战:Pandas VS Caviar

左边是对一个模型一天天地观察,一点点地调整参数,吴恩达称之为 熊猫模型 Pandas
右边是快速训练一些模型,尝试一些参数,然后选择其中一个最好的,吴恩达称之为 鱼子酱模型 Caviar
对于有些不得不应用大型网络模型的环境下,实际上是没有尝试机会的,所以一上来就要全心全力去调整好一个思考好的模型,于是就只能用 熊猫模型
3.4 正则化网络的激活函数
正则化网络,这个翻译有点小问题,实际上这几节讲的是 batch 归一化
不妨回忆反向传播过程,直接影响 ![]() 的实际上是
的实际上是 ![]() ,对中间过程的归一化就叫做 batch 归一化
,对中间过程的归一化就叫做 batch 归一化
一个问题是,归一化 A 还是 归一化激活前的 Z,实践中,我们总是归一化 Z
涉及的问题是,对比如 sigmoid 函数,我们可能有时并不希望 Z 在 0 附近
所以归一化后,再给 Z 设上一定的均值和标准差,整个过程称作规范化
规范化公式:
![]()
![]()

![]()
公式中省略了上标 ![\large [l]](http://img.e-com-net.com/image/info8/7181655c8b5d43e9beaaaafd5925f7f4.gif) ,就是说
,就是说 ![]() 和
和 ![]() 是按层来调的超参数
是按层来调的超参数
3.5 将 Batch Norm 拟合进神经网络
本节课就是把上节课的公式往里面带了下,具体说了下工作流程,对于 mini-batch 也是同理,就不具体谈了
需要注意的是,想象一下 WX+b,同一层加的是同一个 b,在减均值的时候把 b 全都一起减去了,所以 +b 没有意义,所以对归一化网络没有 +b 的意义,不需要设置偏置单元
3.6 Batch Norm 为什么奏效
想象一下,对其中一层做 batch 正则化,那么他收到的 Z 总是规范化后具有相同的均值和方差,即相同的分布,这使得这一层稍稍独立于前面的层,对适应性的要求一定程度降低了
而且想象一下,归一化输入实际上只加速了第一层参数的梯度下降,毫无疑问 batch 正则化加速的是整个网络的训练
本节课需要着重注意的几点是
对 mini-batch 我们每次是对其中一个 mini-batch 计算的均值和方差
因此,相比于 batch,对 mini-batch 归一化会带来轻微的噪音,其影响方式类似于 dropout
最后,batch norm 实际上有轻微的正则化效果,尤其是 mini-batch norm,实际上那个轻微的噪音带来的就是一个正则化的效果
进一步,我们可以把 batch norm 和 dropout 来一起用
3.7 测试时的 Batch Norm
大概讲的就是指 梯度检验 的时候,经过 一个 epoch,检验 实际下降值,和导数估计值 是否近似,那 mini-batch 是分成 size 次下降的,于是我们计算规范化后的 Z,要怎么计算呢,方法是对每个 epoch 的所有次梯度下降的 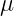 和
和 ![]() 做指数加权平均拿来用来计算这个 epoch 后的 Z
做指数加权平均拿来用来计算这个 epoch 后的 Z
3.8 Softmax 回归
二分类,0,1,我们可以用 sigmoid 实现
三分类,-1,0,1,我们可以用 tanh 实现
更多的分类呢
这就需要其他方式,称为 Softmax 回归,输出层称作 Softmax 层
比如你要四分类,他就输出四个单元,(4,1) 的向量分别是对每个类别的预测的概率
我们知道概率和应当为 1,根据吴恩达没有讲的某些概率统计知识,最终归一化方法如下
Softmax 激活函数:
![\large A^{[L]}=\frac{e^{Z^{[L]}}}{\sum e^{Z^{[L]}}_i}](http://img.e-com-net.com/image/info8/71258e92cab54d37a5532c36bedc4c61.gif)
举个例子,比如算出 ![]()
那么最终结果的概率 ![\large A^{[L]}=(\frac{e^1}{e^1+e^2},\frac{e^2}{e^1+e^2})](http://img.e-com-net.com/image/info8/08776dc3f0904547b0bf4cb2ccc99c33.gif)
softmax 的名字是和 hardmax 相对的,比如 ( 1, 0 )^T 就是一个 hardmax,( 0.9, 0.1 )^T 就是一个softmax
3.10 深度学习框架

如图所示是吴恩达推荐的框架,自己根据具体需求选择即可
3.11 Tensorflow
吴恩达使用的是 1.x 版本的功能,笔者在写这篇博客时已经是 2.7 了。。然后需要一点兼容操作
如图是代价函数 ![]() 梯度下降的一个小例子
梯度下降的一个小例子
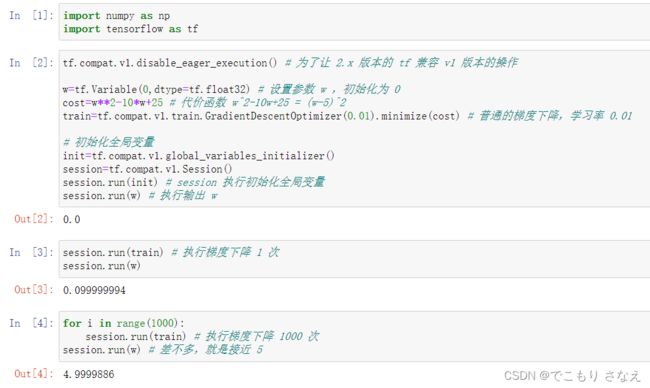
如果要加入训练数据怎么做呢
如下图所示,加入了一个训练样本 x = ( 1 , -10 , 25 )^T
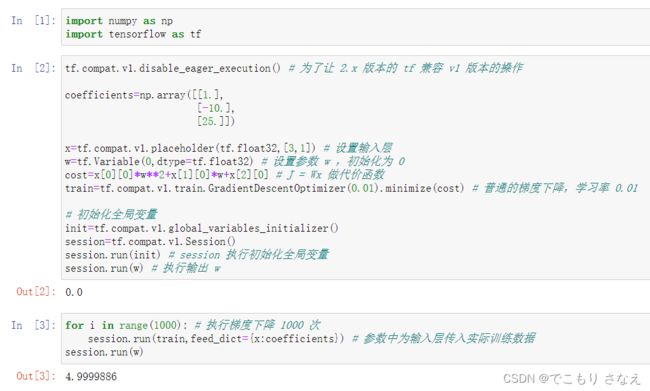
对于 session
一般还有一个写法是
with tf.Session() as session:
session.run(init)
session.run(w)with as 结构在 tf 中十分常用,和直接写其实基本等价
差别是,比如打开文件,我们往往要 try catch finally,很麻烦,用 with as 的话,它自带一个 __enter__() 函数 和 __exit__() 函数,不论是否异常,最终它都会自动清理、自动释放资源,就有点像JAVA的感觉,写起来十分便捷