yolov3/yolov4/yolov5/yolov6/yolov7/lite/mask/faster/fastdet/efficientdet各系列模型开发、项目交付、组合改造创新之—水稻检测
目前单阶段目标检测模型依旧是主流技术,yolo系列一直是但阶段目标检测领域的翘楚,迭代更新至今,已经从yolov3、yolov4、yolov5更新到了如今的yolov6和yolov7,相信随着新技术的不断涌现,一定还有更快更准更强的检测模型面世,yolo全系列的模型都有很高的学习研究和应用实践价值,对于每一个想要入门目标检测领域的人来讲都是必不可少的一堂课。
当然了出来yolo以外还有很多其他的检测模型,比如:lite、fastestdet、effcientdet、fasterrcnn、maskrcnn、fcos等等,都是不错的检测模型,都有学习借鉴的价值,可以根据自身的具体的也无需求进行技术选型即可,当然了如果有项目开发的需求也都是可以的,深耕CV领域数十载,自建海量的数据资源库,积累了大量的项目经验。
文本主要是简单讲解水稻检测这一目标检测任务。
数据样例如下:

yolo格式标注文件如下所示:
VOC格式数据标注如下所示:
数据解析处理核心实现如下所示:
#将labels下的txt转为 Unix 格式
txt_list=['labels/'+one.strip() for one in os.listdir('labels/') if one.endswith('txt')]
print('txt_list_length: ', len(txt_list))
cut_list_res=cut2List(txt_list,c=500)
print('cut_list_res_length: ', len(cut_list_res))
for one_list in cut_list_res:
one_content=' '.join(one_list)
one_order='dos2unix '+one_content
os.system(one_order)
#将labels下的txt复制到JPEGImages目录下
txt_list=['labels/'+one.strip() for one in os.listdir('labels/') if one.endswith('txt')]
print('txt_list_length: ', len(txt_list))
cut_list_res=cut2List(txt_list,c=500)
print('cut_list_res_length: ', len(cut_list_res))
for one_list in cut_list_res:
one_content=' '.join(one_list)
one_order='cp '+one_content+' JPEGImages/'
os.system(one_order)
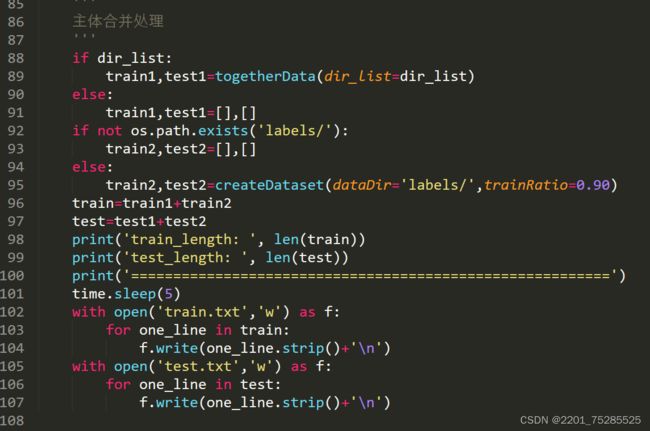
整体数据融合核心实现如下所示:
模型配置如下:
[net]
# Training
batch=32
subdivisions=2
width=320
height=320
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 50200
policy=steps
steps=40000,45000
scales=.1,.1
[convolutional]
filters=8
size=3
groups=1
stride=2
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=8
size=3
groups=8
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=4
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[convolutional]
filters=24
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=24
size=3
groups=24
stride=2
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=6
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[convolutional]
filters=36
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=36
size=3
groups=36
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=6
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
[convolutional]
filters=36
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=36
size=3
groups=36
stride=2
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=8
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[convolutional]
filters=48
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=48
size=3
groups=48
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=8
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
[convolutional]
filters=48
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=48
size=3
groups=48
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=8
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
######################
[convolutional]
filters=48
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=48
size=3
groups=48
stride=2
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=16
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[convolutional]
filters=96
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=96
size=3
groups=96
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=16
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
[convolutional]
filters=96
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=96
size=3
groups=96
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=16
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
[convolutional]
filters=96
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=96
size=3
groups=96
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=16
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
[convolutional]
filters=96
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=96
size=3
groups=96
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=24
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[convolutional]
filters=144
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=144
size=3
groups=144
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=24
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
[convolutional]
filters=144
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=144
size=3
groups=144
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=24
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
[convolutional]
filters=144
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=144
size=3
groups=144
stride=2
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=40
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[convolutional]
filters=240
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=240
size=3
groups=240
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=40
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
[convolutional]
filters=240
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=240
size=3
groups=240
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=40
size=1
groups=1
stride=1
pad=1
batch_normalize=1
activation=linear
[shortcut]
from=-4
activation=linear
### SPP ###
[maxpool]
stride=1
size=3
[route]
layers=-2
[maxpool]
stride=1
size=5
[route]
layers=-4
[maxpool]
stride=1
size=9
[route]
layers=-1,-3,-5,-6
##############################
[convolutional]
filters=144
size=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=144
size=3
groups=144
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=48
size=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=144
size=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 3,4,5
anchors = 26, 48, 67, 84, 72,175, 189,126, 137,236, 265,259
classes=1
num=6
jitter=.1
ignore_thresh = .5
truth_thresh = 1
random=0
#################
scale_x_y = 1.1
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
##################################
[route]
layers= 64
[upsample]
stride=2
[route]
layers=-1,47
#################################
[convolutional]
filters=40
size=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=96
size=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=96
size=3
groups=96
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=48
size=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
filters=96
size=1
stride=1
pad=1
batch_normalize=1
activation=relu
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 26, 48, 67, 84, 72,175, 189,126, 137,236, 265,259
classes=1
num=6
jitter=.1
ignore_thresh = .5
truth_thresh = 1
random=0
#################
scale_x_y = 1.05
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
检测效果样例如下所示: