CV-02-VGG论文阅读总结
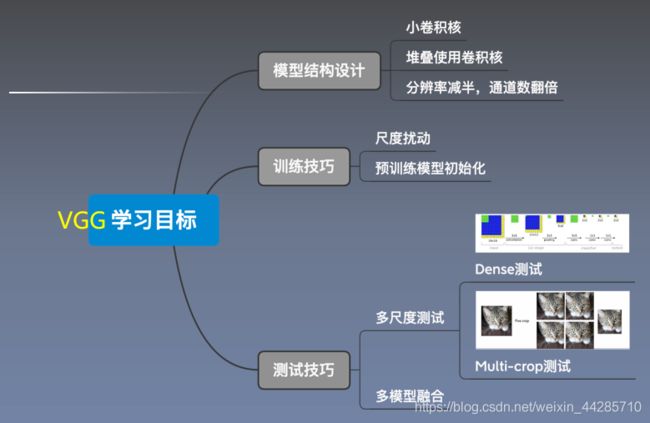
VGG借鉴的思想:

1、数据
输入:224*224 RGB彩色图像
预处理:对图像的每个像素做了减去均值的操作。
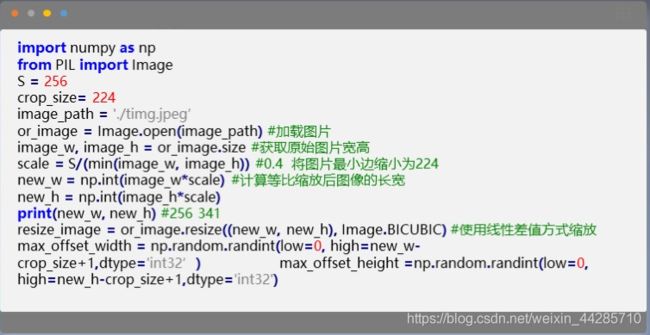
设置S为最小边长,对原图进行各向同性缩放也可以理解为等比例缩放(不破坏原图的长宽比),然后从等比例缩放后的图像中随机裁剪224*224的部分通过数据增强后用于训练

多尺度训练:
- 最小边尺寸S随机从[256,512]中随机选取,然后对原图进行等比例缩放,然后从中随机裁剪224*224的部分通过数据增强后用于训练
- S固定为256或384
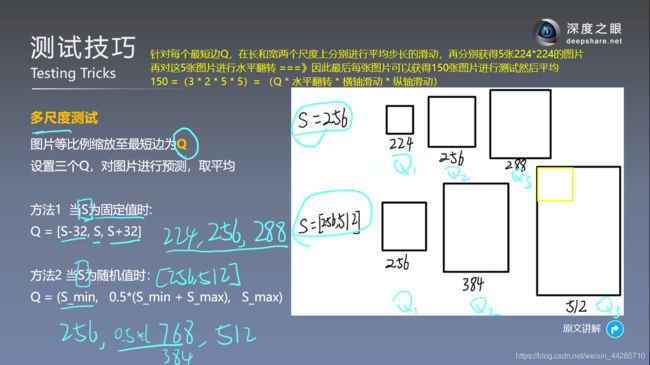
多尺度测试:测试最小边尺寸为分别为[256,384,512],然后对原图进行等比例缩放,从中心裁剪224*224的部分用于测试
数据增强:随机水平翻转和随机RGB colour shift

数据处理代码:

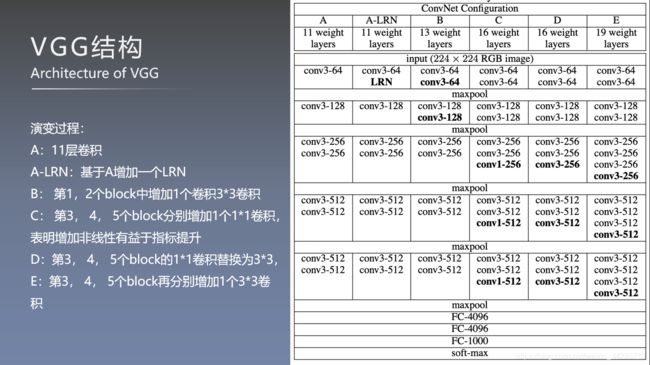
2、网络结构
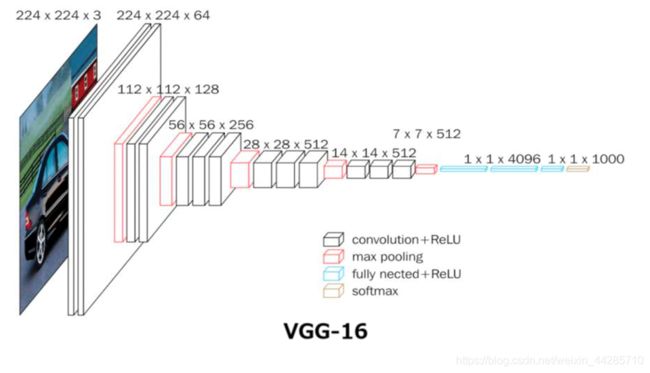
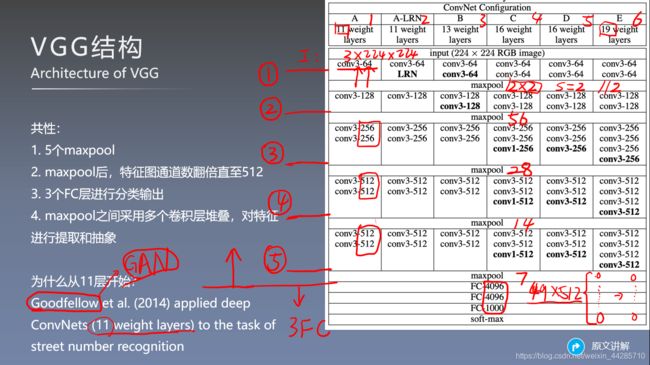
- 池化操作之后设置通道翻倍的可能原因:池化后特征图分辨率减半,为了尽可能的保留图片信息,因此增加卷积核的数量。
 网络参数量计算:
网络参数量计算:

- 关于内存的消耗:每个像素占4bytes,那么每张图片在只有前向传播的情况下大约需要96M,加上反向传播之后大约还要扩大2倍
- 关于右图的VGG结构图,第三个卷积block少了一个卷积层
VGG16各层输出计算

使用多个小卷积核代替大卷积核的原因:
- 增大感受野
- 增加了非线性激活函数,增加特征抽象能力
- 减少训练参数


- 借鉴NIN引入1*1卷积的作用:增加了非线性 激活函数,提升模型效果
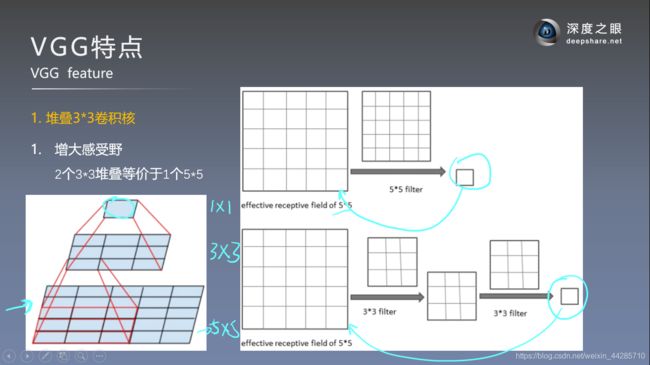
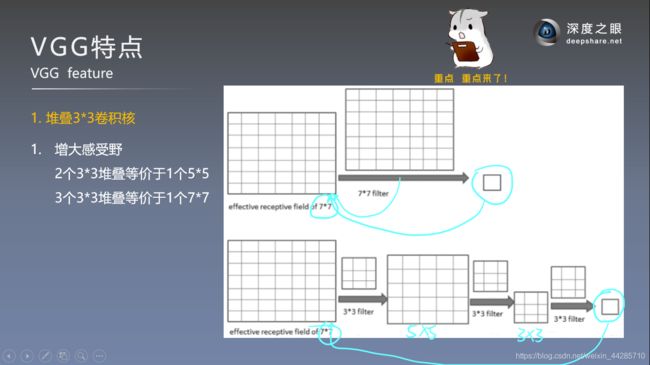
参数量计算解释:如果输入通道为C,则有C个特征图需要分别进行卷积,卷积核大小为3*3=9,输出通道也就是卷积核的数量为D,因此一共的卷积核参数量为C*3*3*D(每个通道的卷积核参数不同)
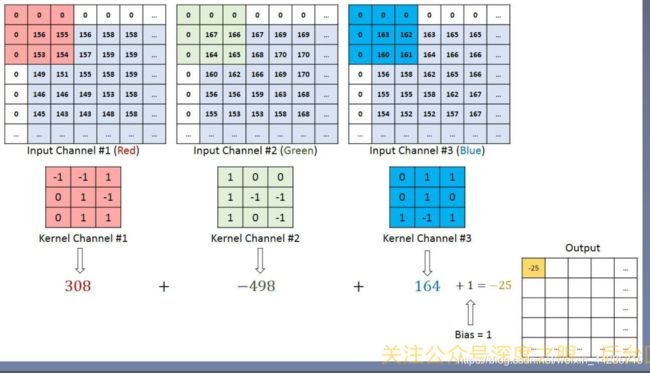
VGG相比AlexNet的改进:
- 使用连续的几个3*3的卷积核代替AlexNet中较大尺寸的卷积核(11*11、5*5),采用堆叠小卷积核可以达到与大卷积核一样的感受野,此外还增加了网络的深度和复杂度(由于多引入了激活函数)
- 采用了更深的网络结构
- 使用多尺度的图片训练和测试网络
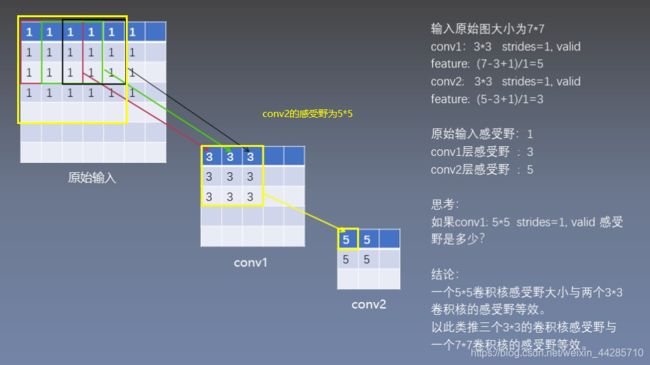
2.1感受野的计算
感受野定义:卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小,通俗来说就是特征图上一个点跟原图上有关系的点的区域。(上面关于感受野的解释更清楚)

2.2 全连接层替换成卷积层
网络测试阶段将训练阶段的三个全连接层替换为3个卷积层,并使用训练时获得的参数,使得网络成为全卷积网络,从而可以输入任意尺寸的图片。

3.1训练细节与技巧
- 训练过程与AlexNet基本相似,除了从各种尺寸的图像中心裁剪图片
- batch size:256
- momentum:0.9(优化方式为带动量的SGD)
- weight decay: 5*e-4
- dropout用在前两个FC层,P=0.5
- 学习率初始化为0.01,衰减因子为0.1(验证集准确率不再上升时衰减)
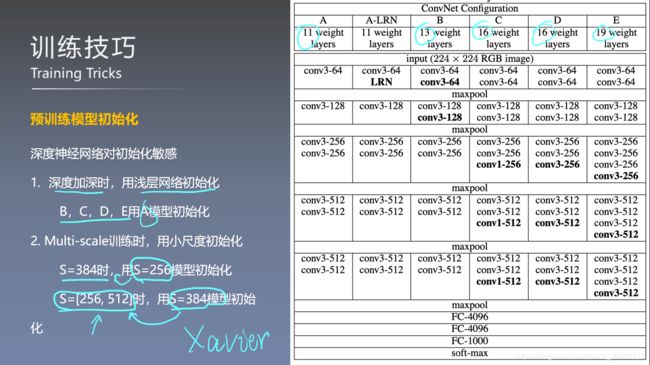
- 为了解决网络深度造成的不好训练,作者首先在A结构上使用随机初始化的权重进行训练,在训练更深的网络时,前四个卷积以及全连接层使用A结构训练获得的参数,其他层随机初始化权重。服从0均值方差为0.01的正态分布,偏置被初始化为0
- 论文后面提到:Xavier初始化方法就可以获得不错的效果,不再需要上述麻烦的初始化方法
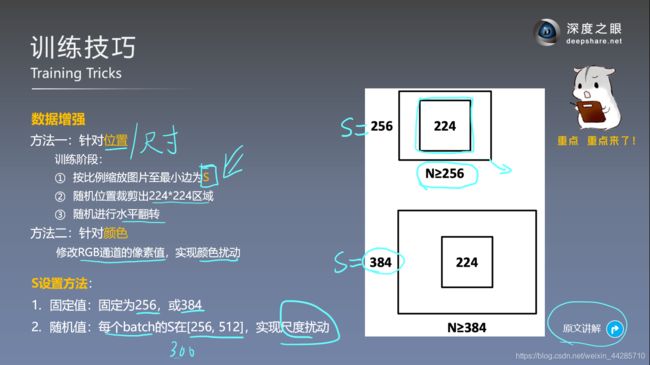
两种训练方式:
-
单尺度训练:评估了两个尺寸的模型,S=256和S=384,为了加速后者的训练速度,使用了前者的参数初始化后者的网络,并使用小的学习率
-
多尺度训练:每个训练样本从[S_min=256,S_max=512]中随机选择一个尺寸缩放图像,这可以看成是一种数据增强方法(scale jittering)出于速度原因,通过微调具有单尺度模型的所有层来训练多尺度模型,预先训练固定的S=384模型
3.2.测试技巧

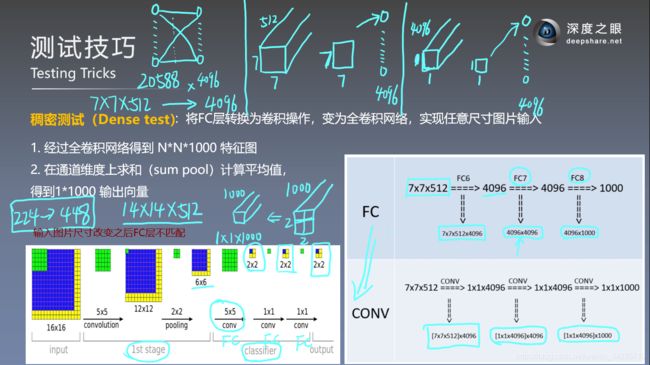
- 若输入图片尺寸从224变为448,则最后一个卷积输出特征图尺寸变为14*14*512,与全连接层神经元个数不匹配导致报错
- 采用稠密测试将全连接层替换为卷积层后,输入图片尺寸的改变仅会改变最终获得特征图的大小,而特征图大小的改变可以看做是对图片不同位置进行特征提取的结果,比如2*2的特征图,左上角的值是对原始图片左上角的子区域提取特征的结果,而右下角的值是对应于原始图片的右下角,因此特征图的每个位置是提取了图片不同位置的特征。要进行最后的分类时,仅需要对最后的特征图进行平均池化的操作,即可获得1*1*类别数(通道数)的输出。

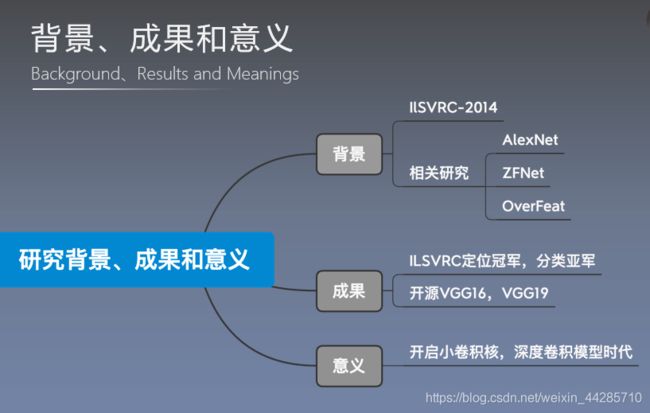
4.实验结果及分析
在2014年ILSVRC比赛中获得分类项目的第二名(第一名是GoogLeNet)和定位项目的第一名。
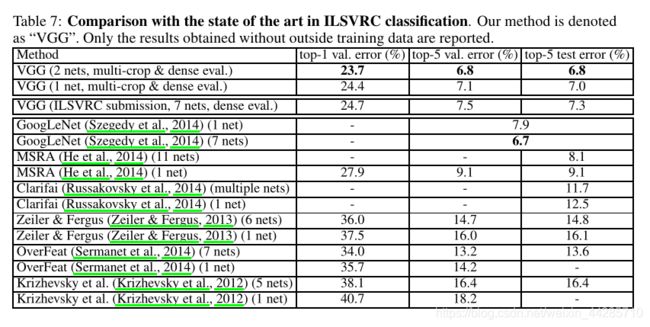
- 单模型上,VGG优于GoogleNet
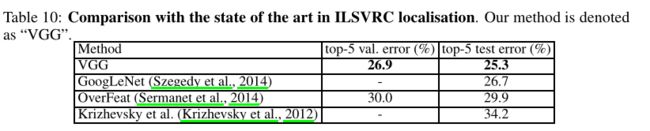
VGG由于其结构简单,提取特征能力强,应用场景广泛,在很多模型中被用来提取基础特征
- 目标检测框架的backbone,用来提取特征(Faster-RCNN,SSD等)
- GAN的特征内容提取
单尺度测试结果比对:
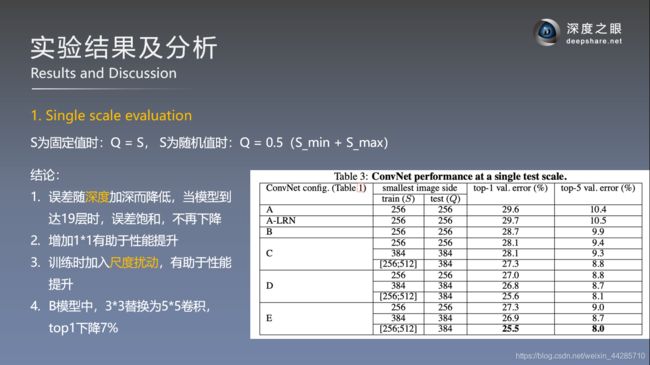
- LRN层对网络性能提升没有帮助(A与A-LRN的对比)
- 单独扩大数据尺度也没有改善性能,对同一个网络结构使用多尺度训练可以提高网络精度(C)
- E网络(VGG19)效果最好,证明了在一定程度上加深网络深度可以提高网络性能
多尺度测试结果对比:
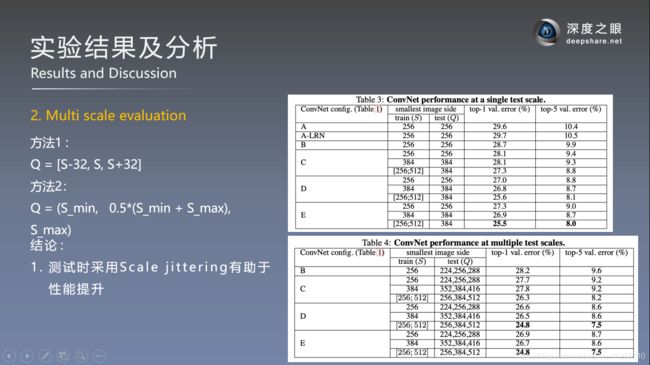
- 多尺度测试可以提升预测的精度
- VGG16效果最好(D)
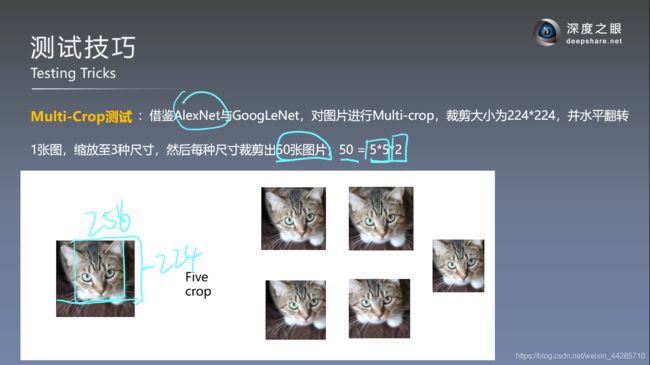
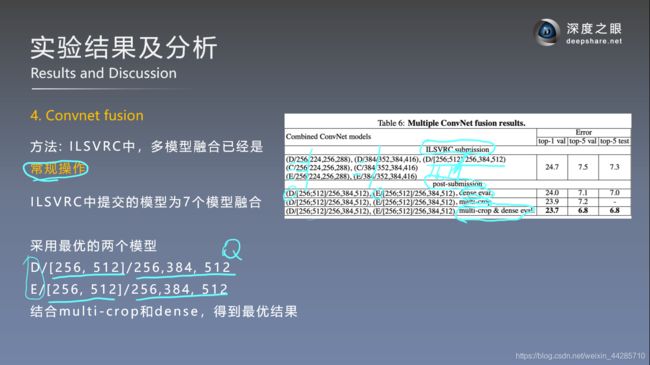
Multi crop & dense对比

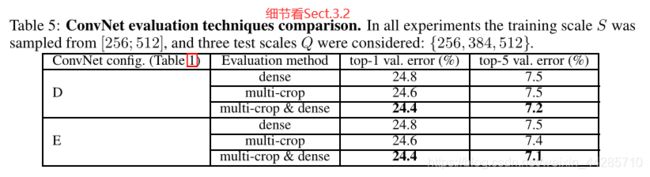
- dense evluation和multi-crop两种测试方式联合使用效果最好
5.代码实现
5.1 预测代码实现
图片预处理
# 图片预处理
def img_transform(img_rgb, transform=None):
"""
将数据转换为模型读取的形式
:param img_rgb: PIL Image
:param transform: torchvision.transform
:return: tensor
"""
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def process_img(path_img):
# hard code
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([
transforms.Resize(256), # 最短边缩放至256,等比例缩放
transforms.CenterCrop((224, 224)),
transforms.ToTensor(), # 数据成为tensor形式,大小为[-1,1]
transforms.Normalize(norm_mean, norm_std),
])
# path --> img
img_rgb = Image.open(path_img).convert('RGB')
# img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0) # 增加batch维度 chw --> bchw
img_tensor = img_tensor.to(device)
return img_tensor, img_rgb
path_img = os.path.join(BASE_DIR, "..", "data","Golden Retriever from baidu.jpg")
print(path_img)
img_tensor, img_rgb = process_img(path_img)
print(img_tensor, img_tensor.shape)
print(img_rgb, img_rgb.size)
plt.imshow(img_rgb)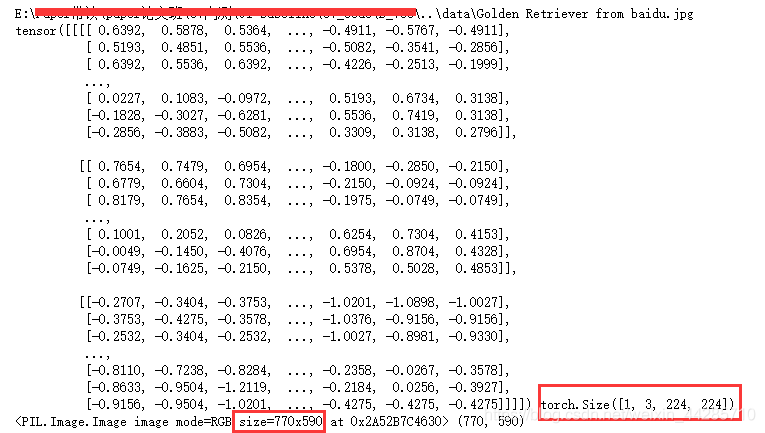
加载ImageNet数据集标签名
def load_class_names(p_clsnames, p_clsnames_cn):
"""
加载标签名
:param p_clsnames:
:param p_clsnames_cn:
:return:
"""
with open(p_clsnames, "r") as f:
class_names = json.load(f)
with open(p_clsnames_cn, encoding='UTF-8') as f: # 设置文件对象
class_names_cn = f.readlines()
return class_names, class_names_cn
path_classnames = os.path.join(BASE_DIR, "..", "Data", "imagenet1000.json")
path_classnames_cn = os.path.join(BASE_DIR, "..", "Data","imagenet_classnames.txt")
cls_n, cls_n_cn = load_class_names(path_classnames, path_classnames_cn)
print(cls_n)
print(cls_n_cn)加载模型
# load model
path_state_dict = os.path.join(BASE_DIR, "data", "vgg16-397923af.pth")
vgg_model = get_vgg16(path_state_dict, device, True)
print(path_state_dict)
print(vgg_model)
#输出结果如下
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-32 [-1, 512, 7, 7] 0
Linear-33 [-1, 4096] 102,764,544
ReLU-34 [-1, 4096] 0
Dropout-35 [-1, 4096] 0
Linear-36 [-1, 4096] 16,781,312
ReLU-37 [-1, 4096] 0
Dropout-38 [-1, 4096] 0
Linear-39 [-1, 1000] 4,097,000
================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.78
Params size (MB): 527.79
Estimated Total Size (MB): 747.15
----------------------------------------------------------------
f:\cv_paper\lesson\B_VGG\data\vgg16-397923af.pth
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)预测分类概率
# %%timeit # 注意变量会被释放掉
# inference tensor --> vector
with torch.no_grad():
time_tic = time.time() # 计算前向传播时间
outputs = vgg_model(img_tensor)
time_toc = time.time()
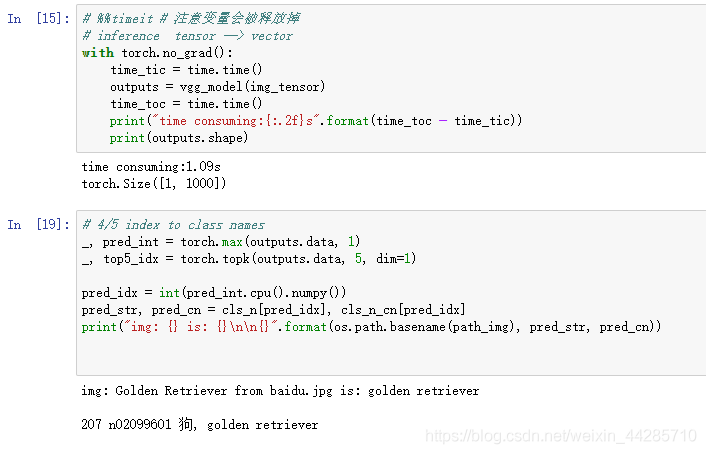
print("time consuming:{:.2f}s".format(time_toc - time_tic))
print(outputs.shape) # 输出shape = [1,1000]
# 4/5 index to class names
_, pred_int = torch.max(outputs.data, 1) # 获得预测概率最大值的索引
_, top5_idx = torch.topk(outputs.data, 5, dim=1) # top-k索引
pred_idx = int(pred_int.cpu().numpy())
pred_str, pred_cn = cls_n[pred_idx], cls_n_cn[pred_idx] # 根据索引读取标签
print("img: {} is: {}\n\n{}".format(os.path.basename(path_img), pred_str, pred_cn))
可视化
# 5/5 visualization
from matplotlib import pyplot as plt
plt.imshow(img_rgb)
plt.title("predict:{}".format(pred_str))
top5_num = top5_idx.cpu().numpy().squeeze()
text_str = [cls_n[t] for t in top5_num]
for idx in range(len(top5_num)):
plt.text(5, 15+idx*40, "top {}:{}".format(idx+1, text_str[idx]), bbox=dict(fc='yellow'))
plt.show()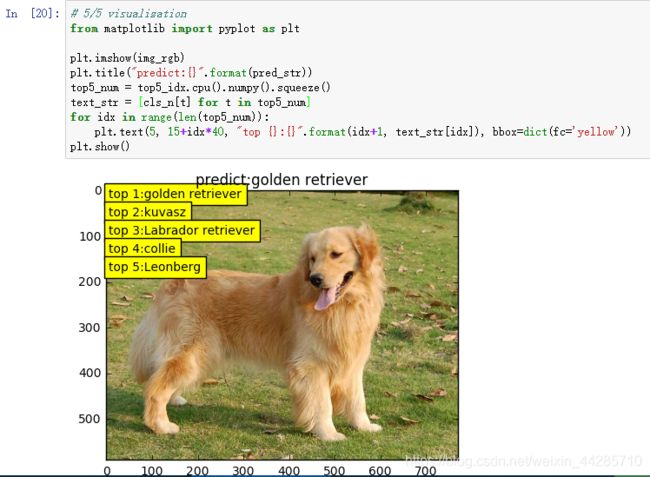
5.2 VGG模型构建
超参数设置

数据集构建及数据预处理
%matplotlib inline
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None]) # 乘以标准差+均值
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train):
img_ = np.array(img_) * 255 # Totensor使得数据变到[0,1] 存疑?
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB') # 3 cha =》彩色图
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze()) # 1 cha =》灰度图
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
class CatDogDataset(Dataset):
def __init__(self, data_dir, mode="train", split_n=0.9, rng_seed=620, transform=None):
"""
分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.mode = mode # 训练还是验证
self.data_dir = data_dir # 数据集所在目录
self.rng_seed = rng_seed
self.split_n = split_n
self.data_info = self._get_img_info() # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
if len(self.data_info) == 0:
raise Exception("\ndata_dir:{} is a empty dir! Please checkout your path to images!".format(self.data_dir))
return len(self.data_info)
def _get_img_info(self):
img_names = os.listdir(self.data_dir)
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names)) # 获取所有图片文件名
random.seed(self.rng_seed) # 保证每次随机的顺序一致,避免训练集与测试集有交叉
random.shuffle(img_names)
img_labels = [0 if n.startswith('cat') else 1 for n in img_names] # 根据文件名获取标签
split_idx = int(len(img_labels) * self.split_n) # 25000* 0.9 = 22500 # 选择划分点
# split_idx = int(100 * self.split_n)
if self.mode == "train":
img_set = img_names[:split_idx] # 数据集90%训练
label_set = img_labels[:split_idx]
elif self.mode == "valid":
img_set = img_names[split_idx:]
label_set = img_labels[split_idx:]
else:
raise Exception("self.mode 无法识别,仅支持(train, valid)")
path_img_set = [os.path.join(self.data_dir, n) for n in img_set] # 拼接路径
data_info = [(n, l) for n, l in zip(path_img_set, label_set)] # 制作样本对,返回为一个list,每个index对应样本的路径和标签
return data_info
norm_mean = [0.485, 0.456, 0.406] # imagenet 训练集中统计得来
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((256)), # (256, 256) 区别
transforms.CenterCrop(256), # 从中心裁剪获得一个256*256的图片
transforms.RandomCrop(224), # 随机裁剪出224*224的图片
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
normalizes = transforms.Normalize(norm_mean, norm_std)
valid_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.TenCrop(224, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([normalizes(transforms.ToTensor()(crop)) for crop in crops])),
])
# dataset
data_dir = os.path.join(BASE_DIR, "..", "Data", "train")
train_data = CatDogDataset(data_dir=data_dir, mode="train", transform=train_transform)
valid_data = CatDogDataset(data_dir=data_dir, mode="valid", transform=valid_transform)
print(train_data.__len__())
print(valid_data.__len__())
# fake dataset 里面共有20张图片
fake_dir = os.path.join(BASE_DIR, "data", "fake_dataset")
train_data = CatDogDataset(data_dir=fake_dir, mode="train", transform=train_transform)
valid_data = CatDogDataset(data_dir=fake_dir, mode="valid", transform=valid_transform)
print(train_data.__len__())
print(valid_data.__len__())
img_tensor, label = train_data.__getitem__(1)
img_rgb = transform_invert(img_tensor, train_transform) # 从tensor还原出图片可视化处理结果
print(img_tensor, label)
print(img_rgb)
plt.imshow(img_rgb)

构建DataLoader
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) # 20 128
valid_loader = DataLoader(dataset=valid_data, batch_size=4) # 2 4
print(BATCH_SIZE)
print(len(train_loader))
print(len(valid_loader)) 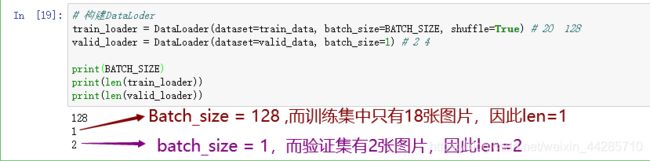
模型构建及预训练权重加载
import torchvision.models as models
def get_vgg16(path_state_dict, device, vis_model=False):
"""
创建模型,加载参数
:param path_state_dict:
:return:
"""
model = models.vgg16()
pretrained_state_dict = torch.load(path_state_dict)
model.load_state_dict(pretrained_state_dict)
model.eval()
if vis_model:
from torchsummary import summary
summary(model, input_size=(3, 224, 224), device="cpu")
model.to(device)
return model
# ============================ step 2/5 模型 ============================
path_state_dict = os.path.join(BASE_DIR, "Data", "vgg16-397923af.pth")
vgg16_model = get_vgg16(path_state_dict, device, False)
num_ftrs = vgg16_model.classifier._modules["6"].in_features
vgg16_model.classifier._modules["6"] = nn.Linear(num_ftrs, num_classes)
print(num_ftrs)
vgg16_model.to(device)
print(vgg16_model)
Pytorch中VGG结构定义
import torch
import torch.nn as nn
# 类定义
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features # 核心:特征提取
self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) # 自适应池化至7*7
self.classifier = nn.Sequential( # 分类器
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x) #
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)VGG16的定义
# _vgg('vgg16', 'D', False, pretrained, progress, **kwargs)
def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs):
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs) # 调用VGG类,进行实例化,核心在make_layers
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def vgg16(pretrained=False, progress=True, **kwargs):
r"""VGG 16-layer model (configuration "D")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg16', 'D', False, pretrained, progress, **kwargs) pytorch中ABDE四种模型的构建方式: 通过一个列表来循环构建
# [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],}损失函数与优化器
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss()
# ============================ step 4/5 优化器 ============================
# 冻结卷积层
# flag = 0
flag = 1
if flag:
fc_params_id = list(map(id, vgg16_model.classifier.parameters())) # 返回的是parameters的 内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, alexnet_model.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR * 0.1}, # 对不同层设置不同的学习率
{'params': vgg16_model.classifier.parameters(), 'lr': LR}], momentum=0.9)
else:
optimizer = optim.SGD(vgg16_model.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
# scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(patience=5)
print(optimizer)
print(scheduler)

迭代训练
# ============================ step 5/5 训练 ============================
for epoch in range(0, 1):
loss_mean = 0.
correct = 0.
total = 0.
vgg16_model.train()
for i, data in enumerate(train_loader):
# 1. forward
inputs, labels = data
print(inputs, inputs.shape, labels, labels.shape)
fake_inputs = torch.randn((1,3, 224, 224), device=device)
fake_labels = torch.ones((1,), dtype=torch.int64, device=device)
outputs = vgg16_model(fake_inputs)
# 2. backward
optimizer.zero_grad()
loss = criterion(outputs, fake_labels)
loss.backward()
# 3. update weights
optimizer.step()
print(outputs)
print(loss.item())
break
scheduler.step() # 更新学习率

6.论文总结







本文为深度之眼paper论文班的学习笔记,仅供自己学习使用,如有问题欢迎讨论!关于课程可以扫描下图二维码

