学习笔记||tensorflow-过拟合及解决
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
(train_image, train_label),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['acc'])
plt.imshow(train_image[0])
train_image[0]
#数据归一化
train_image = train_image/255
test_image = test_image/255
#独热编码
train_label_onehot = tf.keras.utils.to_categorical(train_label)
test_label_onehot = tf.keras.utils.to_categorical(test_label)
#模型初始化并添加层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10,activation = 'softmax'))
#模型编译
model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['acc'])
#模型运行
history = model.fit(train_image, train_label_onehot,
epochs=10,
validation_data=(test_image,test_label_onehot))
#将模型训练过程记录下来
#在训练过程中添加validation_data,使用(test_image,test_label_onehot) 在test数据集上验证
可以看到,在history中几率了训练数据集的正确率acc和验证数据集的正确率val_acc
#训练后看一下
history.history.keys() ![]()
出现了val_loss和val_acc,接下来绘图查看区别
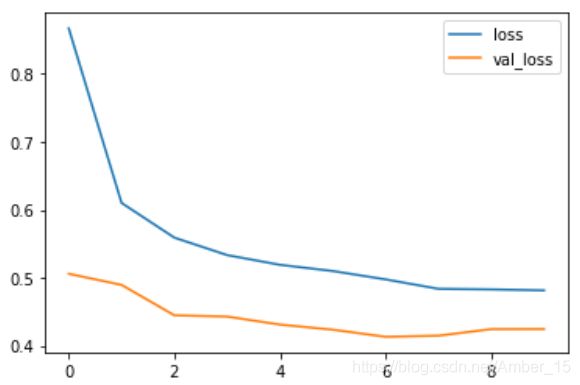
plt.plot(history.epoch, history.history.get('loss'),label='loss')
plt.plot(history.epoch, history.history.get('val_loss'),label='val_loss')
plt.legend()
在曲线图中,loss值随着训练次数的增加一直在下降,但loss在验证集上val_loss的值在第4次训练之后不减反增,这就是出现了过拟合。过拟合也可以通过正确率看出来:
plt.plot(history.epoch, history.history.get('acc'),label='acc')
plt.plot(history.epoch, history.history.get('val_acc'),label='val_acc')
plt.legend()
过拟合:在训练数据上得分很高,但在测试数据上得分相对较低。使用dropout层抑制过拟合,dropout是人为的丢弃了一些层。
参数选择原则:理想的模型是刚好在欠拟合和过拟合的边界上。
首先开发过拟合模型:
(1)添加更多层
(2)让每一层变得更大
(3)多次训练
然后抑制过拟合:
(1)dropout
(2)添加正则化
(3)图像增强
最好的办法是增加训练数据,但由于受各种因素限制,训练数据不能增加,只能使用这些办法。
接下来代码实现:
(1)在添加层的时候增加dropout层
#模型初始化并添加层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
#0.5意味着dropout中rate参数值是50%,表示随机丢弃掉50%的单元数
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))#可以多次添加dropout层,效果会更好
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10,activation = 'softmax'))绘制新的acc和val_acc图像

(2)减少网络规模,迫使模型学习训练集中最重要的数据
#模型初始化并添加层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dense(10,activation = 'softmax'))
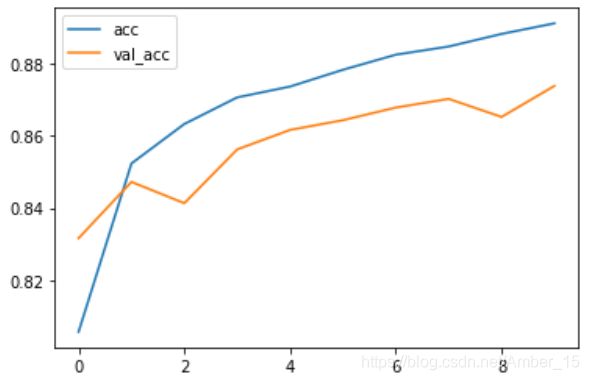
在这个结果中中,acc还处于上升阶段,说明还没有达到最好拟合效果。
(3)正则化
控制参数减小网络规模,不是特别常用。