京东到家埋点治理实践
文|杨红
编辑|刘慧卿
导读:京东到家作为行业领先的即时零售电商平台,又是数据驱动型的公司,埋点的价值日益重要,埋点的可用性、准确率也成了一直在攻克的难题。本文主要讲解京东到家在治理埋点数据、提高埋点数据质量工作中的一些实践经验。
目录:
一 什么是埋点
二 为什么要治理埋点
三 如何治理埋点
3.1 建立统一的埋点流程
3.2 建立完善的埋点规范
3.3 建立完善的质量规范
3.4 优化埋点平台
四 埋点治理收益
五 总结与展望
一 什么是埋点?

埋点数据可以为后续的优化和运营策略提供数据支撑。在京东到家最常见的埋点场景是在商品,例如在商品“曝光”、“点击”、“加车”、“结算”、“提单”这五种行为上做埋点,形成数据漏斗来了解商品、商家、品牌的售卖情况,进而了解用户更喜欢购买哪类商品、哪些商家或者哪个品牌。很明显,如果某个商品用户不喜欢购买,相应的加车会比较少,如果某个商品被多次加购,说明用户喜欢购买这个商品,这样可以评估哪种品类更受欢迎,给后续的用户体验优化做一些数据支撑。
二 为什么要治理埋点
埋点是数据的来源,通过大数据处理、数据统计、数据分析、数据挖掘等加工处理,可以得到衡量产品状态的一些基本指标,从而洞察产品的状态。
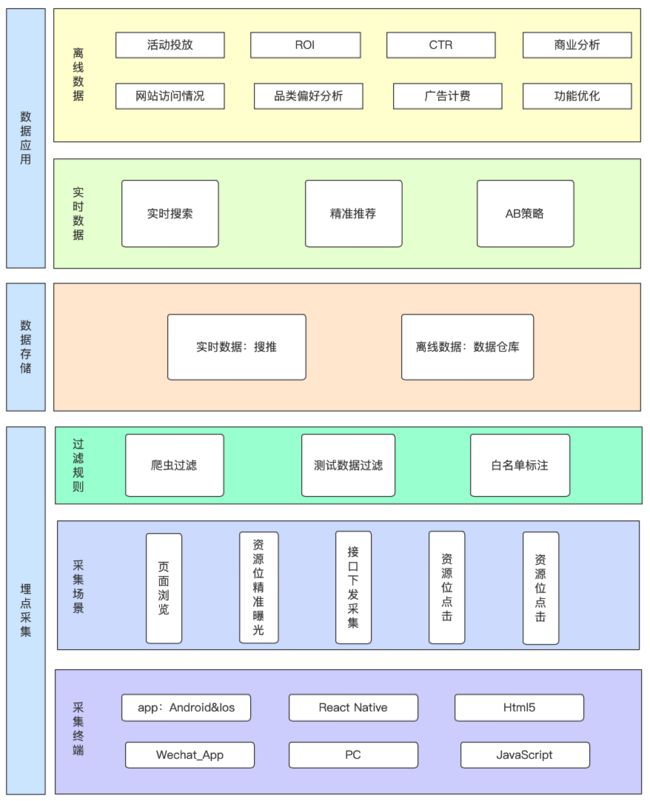
京东到家历史的埋点是可以满足一些常规的数据分析的,但随着业务的发展,历史埋点方案的弊端也就逐渐体现出来了:
流程规划缺失:没有统一的流程规范,关键节点缺失,埋点上线难;
设计规范缺失:埋点上报时机不一致、同样的业务组件上报的内容不一致、数据差异性高;
开发不规范:各端的技术方案不统一、扩展性较差;
质量保障难:缺少质量标准,埋点错误数据非常多,数据信任度比较低;
冗余埋点严重:无用埋点很多,造成资源浪费,维护成本也高;
埋点使用困难:各业务各端不同的规范,以及大量的脏数据,导致数据分析不能用同一种规则去解析,跨业务打通也比较困难。
要解决上述问题,就需要进行埋点治理,提高埋点质量。首先要建立统一的埋点流程,使得产品、研发、测试、数据团队都按照这个规范进行执行落地。其次要建立统一的埋点规范,将历史埋点进行梳理,结合数据团队的使用情况,无用的埋点给予下线,节省资源消耗和降低维护成本,错误的或者不完善的埋点升级成新规范的埋点,节省研发开发的成本以及数据同学提取数据的成本。最后约定质量规范,提高埋点数据质量,从而提高整体效率。
三 如何治理埋点
京东到家一共有5个平台包括android、ios、rn、h5、wechat_app,为了确保埋点治理能够被很好的推进,就需要数据产品制定统一的埋点流程和规范,使整个规划可以顺利的进行落地。
3.1 建立统一的埋点流程
京东到家目前包括跟版和非跟版需求,不管什么类型的需求,埋点涉及到的团队几乎都是一样的。埋点体系上涉及到的团队非常多,不止涉及到数据产品一个团队,一般埋点体系涉及到的人员有:业务方(常说的需求方、市场运营团队),产品(专指前端产品),数据产品(负责埋点需求和全流程),开发(埋点开发人员),测试(埋点数据测试),数仓(解析埋点并规范落库),数据分析师(使用埋点数据进行取数或分析)。每一环又都不可或缺,任何一个环节出现问题,都会导致埋点数据不准确。统一和规范了埋点治理流程是实现埋点治理的关键的一步,也是埋点整体治理体系的第一步。
埋点治理新流程,如图:
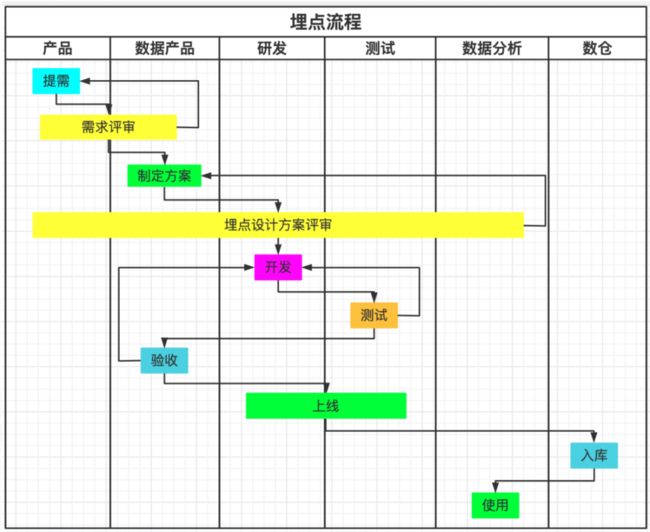
经过几个版本的需求迭代,我们发现埋点治理新流程有如下优势:
1)提升了设计质量:数据产品对业务更加了解,设计埋点的效率提升了50%,同时埋点设计考虑更加全面,比如全归因、推荐场景等;
2)埋点支持扩展、复用:比如商品组件,节省研发以及测试成本,无需重复开发;
3)埋点需求口径一致:节省了数据分析30%的人力成本。
3.2 建立完善的埋点规范
埋点体系上涉及到的团队非常多,为了能够使上述流程可以很好地进行下去,就需要对有关团队制定规范并执行落地。
3.2.1 产品提需规范
随着项目的增多,数据埋点并行上报、量级会对负载能力以及存储能力造成一定的影响,尤其是大促期间,海量的数据会导致埋点的入库延迟,同时也会提高存储设备、服务器、带宽等固定成本,故需要我们在埋点接收环节对埋点进行一定的管控,比如:需求是否合理、是否有遗漏、参数是否完善等;还需要统计每个环节使用的人力成本,统计埋点去向以及分析产生的业务价值。
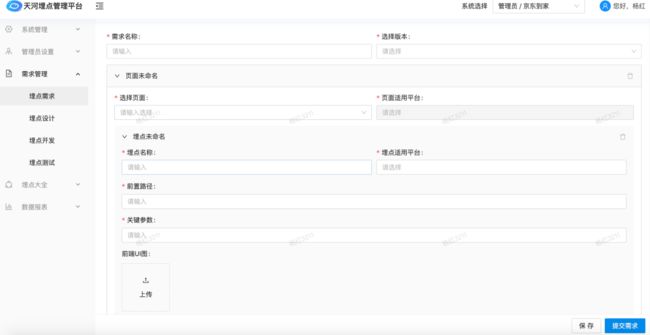
为了使数据产品、研发、测试、数据团队可以对埋点的口径达成统一,我们要求所有的需求都需要通过前端产品在埋点管理平台进行需求提报,包括填写页面、版本、需求名称、需求描述、前置路径、关键参数以及上传对应UI图(标记埋点位置)等。
3.2.2 数据设计规范
我们对历史埋点进行梳理,从中归纳了四大类型,包括ep精准曝光、浏览、点击、api接口下发:
ep精准曝光:资源位露出并且达到一定条件的时候,在同一接口ID下,组合够一定的条数进行上报。
支持配置有效曝光的条件,无需发版:
"epDuration":1,"epPercent":0.5资源位:一般由网关下发userAction给前端,主要下发资源位spm_id, 拼接规则:
res_type|unit_index|res_unit|tpl|index|res_name|sub_page
res_type---资源位类型
unit_index---实际楼层
res_unit---实际房间号
tpl----资源位样式
index---cms配置的楼层
res_name---资源位名称
sub_page---资源位所属父级tab采用资源位的方式,是一旦参数有所变化,是不需要前端发版就可以随时上线的,缩短了数据周期。
浏览:在页面有点击行为且有落地页承接的需要处理成PV埋点,
PV四要素:上一页面名称、当前页面名称、当前页面参数、上一页面资源位参数。
页面有进入和返回,进入的时候携带上一页的资源位信息、页面信息、接口信息,返回的时候增加一个字段进行区分
示例:
正向触发:
pv参数
{
当前页面参数,
ref_par{
来源页相关参数
}
}
逆向触发:
pv参数
{
当前页面参数,
ret_Type:back
}点击: 点击某一个可点区域或者按钮(非跳页)时进行上报,
点击信息主要包括上一页面名称、当前页面名称、点击名称、点击参数。
在场景上主要分为以下6类,包括
1)点击:clickXX
2)点击选中:selectXX
3)点击唤起弹层:showXXLayer
4)点击进入某个地方:goXX
5)用点击模拟曝光:epLayerOpen
6)用点击代替查询结果:getXXResult
大家通过名称就可以知道埋点是用来做什么的,以及具体的功能场景是如何的,代入感比较强。
api接口下发:没有资源位且不需要精准曝光的,只是评估某个功能好坏的采用api,即接口下发数据就上报,主要包括接口名称、接口中对应功能的信息字段。
api的埋点命名采用接口信息,是为了方便大家口径保持一致,精准定位问题。
除了以上四种类型,同时各端各业务还需从以下六个方向在全局上保持统一:
公参提取: 针对不同的类型制定了不同的公参,包括必须上报以及选择上报的公参,同时还设置了可扩展参数,用于后续公参的补充;
上报时机: 是点击上报还是调用接口上报,避免各端各业务有不一样的上报时机;
组件化:相同业务特性,进行组件抽取,相同设计进行复用,比如点击优惠券“click_coupon”,所有页面点击命名一致,通过页面、资源位信息以及优惠券ID来识别具体的优惠券;
事件命名:各端各页面相同业务,采用同样的埋点方式以及埋点命名,比如“加车、结算、提单、支付”等;
字段:各端各页面相同业务所涉及到字段采用同样的,比如商品ID、门店ID等。
事件串联:整体通过页面ID(pageId--唯一ID,产生一条进入pv就生成一次,返回pv与进入保持一致)、接口ID(traceId---唯一ID,识别具体哪次请求产生的埋点)、资源位信息进行精细化地串联,实现前后路径的一对一衔接。
3.2.3 研发落地规范
埋点接入

埋点开发:严格按照数据产品方案落地,包括上报时机和技术规则;

埋点组件化:根据不同类型的埋点制作成标准埋点组件,比如“加减车组件”,

private void addCart(View v) {
if (entity == null || context==null || (context instanceof Activity) && ((Activity) context).isFinishing()) {
return;
}
if (entity.getIconType() == 1) {
if (isAllCart(params)) {
//全局购物车spu加车
addCartSpu(v);
} else {
//mini购物车spu加车
if (context != null && params != null) {
String userAction;
if (!TextUtils.isEmpty(entity.getUserActionSku())) {
userAction = entity.getUserActionSku();
} else {
userAction = entity.getUserAction();
}
DataPointUtil.addRefPar(DataPointUtil.transToActivity(context), pageName, "userAction", userAction, "traceId", traceId);
new SpuSelectDialog(context, params).showDialog();
}
}
//加车监听spu
if (onClickAddListener != null) {
onClickAddListener.onClickSpu(v);
}
} else {
//mini购物车sku加车
if (isMiniCart(params)) {
addMiniCartSku(v, params);
} else if (isAllCart(params)) {
//全局购物车sku加车
addCartSku(v, (OnSpuAdapterParams) params);
}
//加车监听sku
if (onClickAddListener != null) {
onClickAddListener.onClickSku(v);
}
}
//sku加车埋点
if (params != null && params.getPointData() != null) {
pointData.put("storeId", entity.getStoreId());
pointData.put("skuId", entity.getSkuId());
pointData.put("spuId", entity.getSpuId());
pointData.put("traceId", traceId);
if (pointData.get("userAction") == null) {
if (!TextUtils.isEmpty(entity.getUserActionSku())) {
pointData.put("userAction", entity.getUserActionSku());
} else {
pointData.put("userAction", entity.getUserAction());
}
}
DataPointUtil.addClick(DataPointUtil.transToActivity(context), pageName, "click_add", pointData);
}
}埋点自测:通过埋点管理平台研发自测设置为必填项,来限制研发必须进行自测,才可以流转到测试团队。
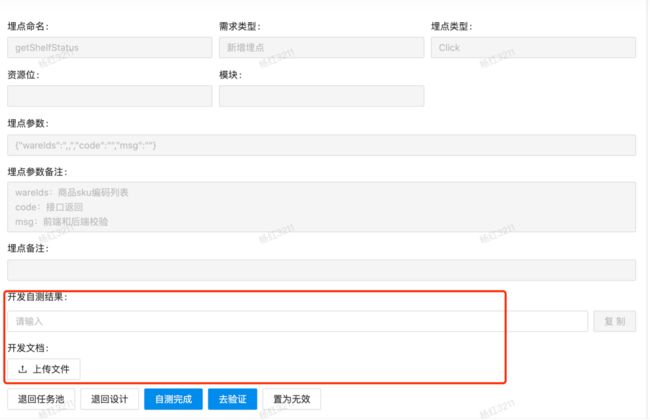
埋点下线:禁止在没有业务需求下,下线任意埋点,下线埋点均需经过数据产品审核。

3.3 建立完善的质量规范
为确保埋点的质量就要做到上线前的测试以及上线后灰度期间的验收。
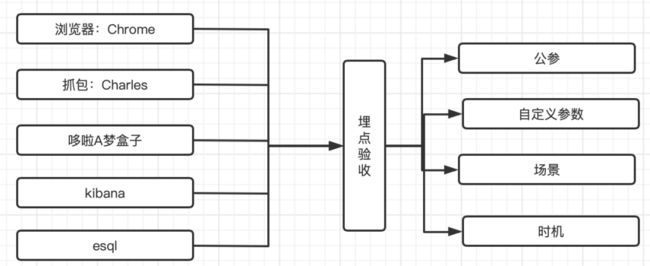
埋点测试范围包含各点击、ep精准曝光、浏览、api接口下发,埋点参数信息,以及由埋点SDK获取的各类字段:
1)埋点上报时机;
2)埋点上报参数;
3)埋点上报场景;
4)埋点是否重复上报;
5)埋点上报是否出现多余的埋点;
6)埋点上报是否有空数组。
埋点验收主要为上线后灰度期间的数据验收,主要是运用简易数据报表验证埋点数据是否适合逻辑上报、量级上是否满足,前后关联是否满足,是否可实现逻辑上的串联。

3.4 优化埋点平台
数据分析对于埋点的口径、上报时机、用途不是很清晰,为了提升双方的沟通效率,在埋点质量平台增加了“页面大全、资源位大全以及埋点大全”,数据团队可以清楚地了解埋点的动态。

同时通过“数据治理平台”也可以查看各页面的基础信息,包括访问量、用户数等。
四 埋点治理收益
京东到家目前的埋点准确率已经平均达到了96.5%,在搜推比较精细化的场景下甚至达到了99%以上,比治理之前有了巨大的提升。来来推业务、京明管家业务、B端业务也都复用了目前京东到家业务的整套治理方案。

五 总结与展望
随着京东到家用户的逐渐壮大和新项目的启动,业务越来越复杂,埋点的数据质量必须得到保障,我们不得不考虑埋点的种种隐患,做到未雨绸缪。埋点数据上报不准确、每个版本人工回溯核心埋点成本的上升、埋点量级的上升对存储以及服务器的压力等,都需要我们有一个完善的埋点监控机制,来持续改善我们的现状。到家埋点后续将重点在监控完善的道路上继续前进。