NeurIPS 2020 | 腾讯 AI Lab 解读机器学习及计算机视觉方向入选论文
感谢阅读腾讯AI Lab微信号第113篇文章。本文将介绍解读 NeurIPS 2020 中腾讯 AI Lab 的14篇入选论文。
神经信息处理系统大会(NeurIPS)是人工智能领域的全球顶级会议,受疫情影响,NeurIPS 2020 将于 12 月 6 - 12 日通过线上的形式进行。
本届会议共收到有效提交论文 9454 篇(相比去年增长近 40%),其中 1900 篇被接收,接受率为 20.09%。
腾讯 AI Lab 共 14 篇论文入选,包括机器学习领域(深度强化学习、深度图学习、神经网络结构搜索,变形器Transformer)及计算机视觉领域(度量学习,特征融合、手语翻译、纹理生成、光流估计)的多个研究主题。本文将汇总介绍这些论文。
机器学习
深度强化学习
深度强化学习(deep RL)是将强化学习(RL)和深度学习相结合的机器学习的一个子领域。RL认为计算代理学习通过反复试验来制定决策的问题。Deep RL将深度学习整合到解决方案中,允许代理根据非结构化输入数据做出决策,而无需手动设计状态空间。深度RL算法能够接受非常大的输入(例如,视频游戏中渲染到屏幕上的每个像素),并决定执行哪些操作来优化目标(例如,最大化游戏得分)。
深度强化学习已有多种应用方向,包括但不限于机器人技术、自然语言处理、计算机视觉等研究领域,以及电子游戏、教育、运输、金融、医疗保健等应用。
1.使用深度强化学习朝着无限制MOBA游戏AI迈进
Towards Playing Full MOBA Games with Deep Reinforcement
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/06d5ae105ea1bea4d800bc96491876e9-Abstract.html
深度解读可移步:腾讯绝悟AI完全体限时开放体验,研究登上国际顶会与顶刊
本文由腾讯AI Lab独立完成,提出了一种MOBA AI的通用学习范式,结合各种新颖和成熟的方法,解决了MOBA游戏中由于英雄池过大,导致英雄阵容组合数“爆炸”从而难以有效训练和测试的问题。
开发MOBA游戏的AI面临多智能体、庞大的状态-动作空间,复杂的操作控制等极具挑战性的问题。相关的研究近来成为热点并受到广泛关注。然而由于MOBA游戏本身的复杂性,现有的工作无法很好地解决智能体阵容组合数随着英雄池扩大而爆炸增长的问题,例如,OpenAI的Dota AI仅支持17名英雄。至今,无限制的完整MOBA游戏还远没有被任何现有的AI系统所掌握。
在本文中,我们提出了一种MOBA AI学习范式,该范式使AI可以在方法论上使用深度强化学习来掌握完整的MOBA游戏。具体地讲,我们结合了各种新颖和成熟的方法,包括curriculum self-play learning、multi-head value estimation、policy distillation、Monte-Carlo tree-search以及off-policy adaption等,在使用很大的英雄池训练的同时巧妙地解决了可扩展性问题。在热门MOBA游戏《王者荣耀》的测试中,我们展示了如何打造能够击败顶级电子竞技玩家的超级AI智能体。文章中展现的首次大规模MOBA AI 智能体性能测试证明了我们训练的AI的优越性。
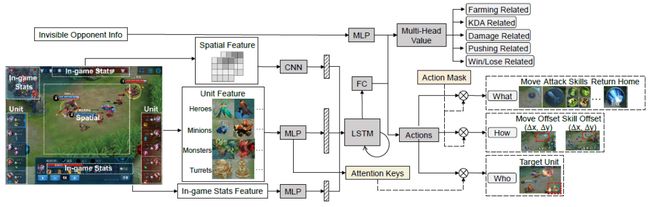
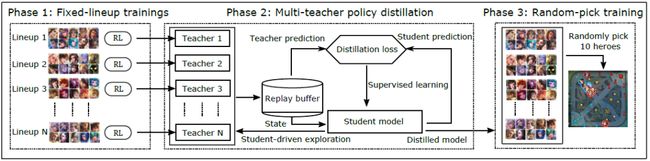
对于学术界,我们相信不受限制地掌握一个典型的MOBA游戏会变成下一个像AlphaStar或者AlphaGo一样的AI里程碑。我们提出的方法是基于通用机器学习组件,适用于任何多人游戏领域。结果表明,课程指导下的强化学习有助于处理非常复杂的,涉及多智能体竞争与合作、实时决策,不完美观测,复杂策略空间和组合行动空间的任务。我们在此期望提供这项工作能对其它复杂现实问题带来启发,例如机器人的实时决策。对于游戏工业界,我们的研究甚至可以改变传统的游戏设计师的工作方式,例如在游戏平衡、PVE玩法、掉线托管等方面。对于电子竞技界,我们甚至可以帮助职业选手训练以及探索更优异的策略。
2.基于分层堆叠注意力机制的用于求解文字游戏的深度强化学习算法
Deep Reinforcement Learning with Stacked Hierarchical Attention for Text-based Games
论文地址:https://arxiv.org/abs/2010.11655
本文由腾讯AI Lab、腾讯Robotics X、悉尼科技大学和伦敦大学学院合作完成,为基于文本的强化学习算法提供了一种分层堆叠注意力机制,通过利用知识图谱的结构来构造推理过程的显式表示,从而帮助智能体作出决策。
我们研究在自然语言环境下的交互式模拟的文本游戏上的强化学习。尽管目前的工作已经开发出了不同的方法来表示环境信息和语言动作,但是现有的强化学习智能体没有任何处理文本游戏的推理能力。在这项工作中,我们旨在使用知识图进行显式推理,以进行决策,从而通过可解释的推理程序生成并支持智能体的决策。我们提出了一种分层堆叠注意力机制,通过利用知识图的结构来构造推理过程的显式表示。我们在一些人造基准游戏中广泛评估了我们的方法,实验结果表明我们的方法比现有其他基于文本的强化学习智能体具有更好的性能。
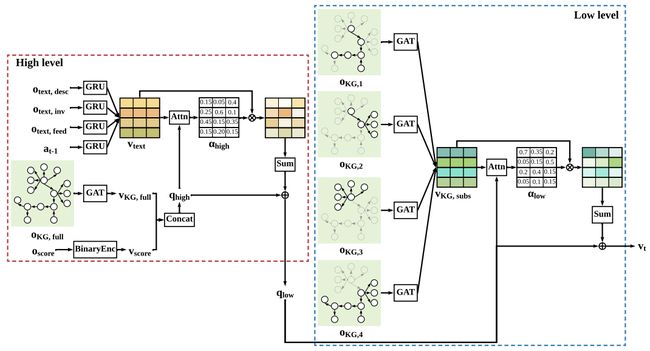
本文研究了智能体如何基于自然语言和环境交互。人类一般都能够通过自然语言对周围环境进行描述和理解,然后进行推断和决策。这项研究的目的就是让智能体也能基于自然语言描述具有一定的推理和决策能力,也对机器人和外在环境交互有一定的启发意义。
深度图学习
深度学习已经在许多领域被证明是成功的,从声学、图像到自然语言处理。然而,由于图的独特性,将深度学习应用于无处不在的图数据并非易事。最近,大量的研究工作致力于将深度学习方法应用于图,从而在图分析技术方面取得了有益的进展。
3.大规模自监督分子图预训练模型
Self-Supervised Graph Transformer on Large-Scale Molecular Data
论文地址:https://arxiv.org/abs/2007.02835
本文由腾讯AI Lab 主导,与清华大学合作完成,提出了完全基于自监督训练的图神经网络框架:GROVER(GraphRepresentation frOm self-superVised mEssage passing tRansformer)。
在基于深度图学习的药物研发应用中,如何获得分子的有效表征是一个非常重要的问题。但是标签数据量的不足严重制约了模型的表达能力和泛化性。
本文提出了的完全基于自监督训练的图神经网络框架:GROVER ,旨在解决在药物发现领域标注数据不足的难题。通过在原子、化学键、分子级别的自监督任务设计,GROVER可以从海量的无标签分子中学习到大量结构/语义信息。与此同时,为了可以编码分子中海量的复杂信息,本文将消息传播网络和Transformer结合得到一个有更强表达能力的图神经网络模型GTransformer。基于更强大的图神经网络模型和自监督任务设计,我们完成了在1000万分子上1亿参数GNN模型的分布式预训练。在属性预测11个数据集上,基于预训练的模型精调的结果均大幅超越现有最优方法。本文验证了海量无标签数据在大规模图神经网络上的自监督预训练方法在提高模型性能上具有巨大的潜力。
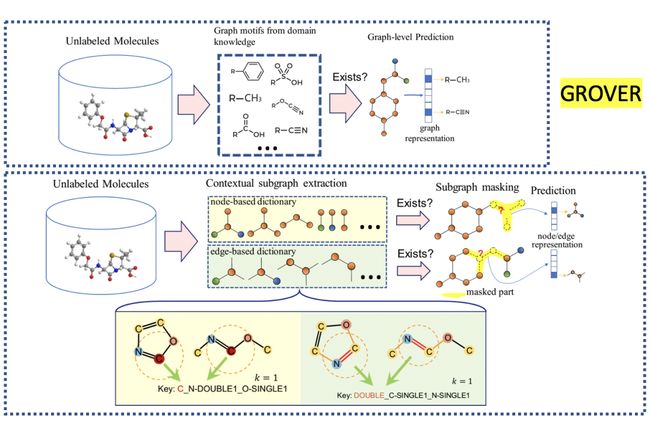
通过在原子、化学键、分子级别的自监督任务设计和更强大的图神经网络结构GTransformer,GROVER可以从海量的无标签分子中学习到大量结构/语义信息。并且显著提升下游任务的性能。
4.狄利克雷图变分自编码器
Dirichlet Graph Variational Autoencoder
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/38a77aa456fc813af07bb428f2363c8d-Abstract.html
本文由腾讯AI Lab 和香港中文大学联合完成,提出了一种新的图变分自编码器框架。
图神经网络与变分自编码器已经被广泛应用于图的建模与生成。然而关于这种模型为什么会有好的效果,以及这种模型中所使用的隐藏变量并没有一个清晰的解释。针对以上问题,本文提出了一种基于狄利克雷分布的图变分自编码器,这种模型中的隐变量代表了图中点所属的类。我们证明了提出的变分自编码器框架与经典平衡图分割方法的等价性,为理解和提升图神经网络性能提供了新的思路。受到图分割算法中低通滤波性质的启发,我们提出了一种新的GNN结构——Heatts, 相对图卷积神经网络,Heatts具有更好的低通特性。实验证明我们提出的模型 在图生成以及图聚类上都有着很好的效果。
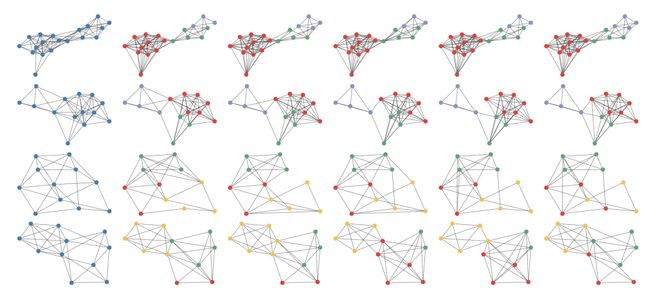
本文将图神经网络与传统图分割方法联系起来,给出了图变分神经网络中隐变量的明确含义,为图神经网络的设计和改进提供了新的思路。
神经网络结构搜索
神经网络结构搜索 (NAS)是一种自动化设计人工神经网络这种在机器学习领域被广泛运用的模型的技术。目前,通过神经结构搜索所设计的模型的性能,已经可以达到甚至超过由人工设计的模型。神经结构搜索的方法可以按照搜索空间、搜索策略和性能估计策略三个方面进行分类。
5.重访深度神经网络通道数量搜索中的参数共享
Revisiting Parameter Sharing for Automatic Neural Channel Number
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/42cd63cb189c30ed03e42ce2c069566c-Abstract.html
本文由腾讯AI Lab主导,与中国科学院自动化研究所,香港中文大学合作完成,提出了新的参数共享方式:仿射参数共享来解决深度卷积神经网络宽度搜索的问题。
近期神经网络结构搜索方法的发展激发了很多新的自动化网络宽度搜索方法。参数共享技术通过在不同的宽度选择上复用参数,可以极大地提高搜索的效率。虽然得到了广泛的使用,参数共享会如何影响宽度搜索的过程仍然没有得到很好的理解。
在本文中,作者尝试更好地理解并应用参数共享技巧。文章首先提出“仿射参数共享 (Affine Parameter Sharing)”来统一此前使用的启发式参数共享机制。基于仿射参数共享,可以定义量化参数共享程度的指标。通过分析,我们发现使用参数共享时,在一个备选支路上的参数更新有益于其他支路参数的优化,因此参数共享可以加速搜索的训练过程。但是参数共享同时会导致不同备选支路的耦合,降低各备选宽度的可区分性。因此,我们提出“过渡性的仿射参数共享”方式来更好地平衡搜索训练速度和备选宽度的可区分性。大量的分析和实验表明,在基准数据集上与许多目前最优的方法相比,所提出的策略在神经网络卷积通道数搜索方面具有优越性。
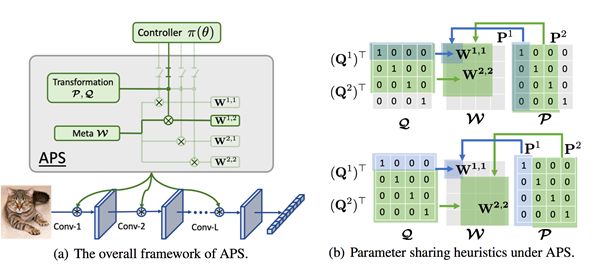
这项研究首次将模型宽度搜索中各类常用的参数共享方式统一起来,并定义了参数共享程度的量化度量方法。基于该度量方法分析了参数共享对模型通道数,即宽度搜索过程的影响,并提出了更好地利用参数共享的方式。对更高效,精准地进行轻量自动化模型设计具有重要意义。
Transformer(变形器)
在引入变形器之前,大多数最新的NLP系统都依赖门控递归神经网络(RNN),例如LSTM和门控递归单元(GRU),并增加了注意力机制。Transformer在不使用RNN结构的情况下基于这些自注意力技术构建而成,突显了这样一个事实,即仅注意力机制(无需进行递归顺序处理)就足够强大,可以实现带有注意力的RNN的性能。
6.用于时间序列预测的对抗性稀疏变形器
Adversarial Sparse Transformer for Time Series Forecasting
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/c6b8c8d762da15fa8dbbdfb6baf9e260-Abstract.html
本文由腾讯AI Lab主导,与清华大学合作完成。主要研究了时间序列预测,属于序列到序列的学习。其中,应用了谷歌变形器,以及生成对抗思想。
鉴于时间序列预测在包括业务需求预测在内的广泛应用中的重要性,研究人员针对它已经提出了许多方法。但是,现有方法存在两个关键限制。首先,大多数点预测模型仅预测每个时间步长的准确值而没有灵活性,这几乎无法捕获数据的随机性。即使使用似然估计的概率预测也同样有这样的缺陷。此外,它们中的大多数都使用自回归生成模式,该模式在训练过程中提供真实标签,并在推理过程中由网络自身的单步提前输出代替,从而导致推理中的错误累积。因此,由于误差累积,他们可能无法长时间预测时间序列。为了解决这些问题,在本文中,我们基于生成对抗网络(GANs),提出了一种新的时间序列预测模型-Adversarial Sparse Transformer(AST)。具体而言,AST采用稀疏变形器作为生成器,以学习用于时间序列预测的稀疏注意力图,并使用鉴别器来改善序列级别的预测性能。在几个真实世界的数据集上进行的大量实验证明了我们方法的有效性和效率。
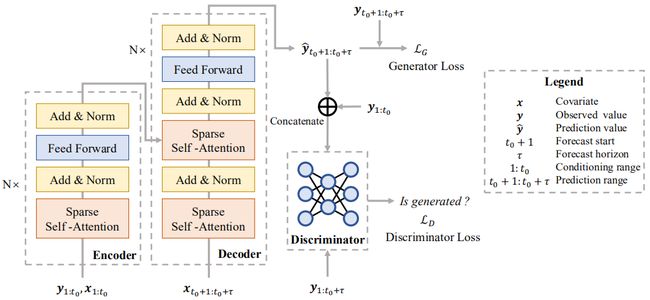
该文首次探索了生成对抗思想对于时间序列预测的有效性。所提算法适应于一系列广泛的应用场景,例如用电负荷预测等,有助于对相关场景准备更充分的预案
7.RetroXpert:像化学家一样分解逆合成预测
RetroXpert: Decompose Retrosynthesis Prediction Like A Chemist
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/819f46e52c25763a55cc642422644317-Abstract.html
本文由腾讯AI Lab主导,与德州大学,清华大学以及中山大学合作完成。主要研究了分子逆合成分析,属于人工智能在化学领域的应用。其中,应用了谷歌变形器,以及深度图学习技术。
逆合成是将目标分子递归分解为可用结构单元的过程。它在解决有机合成规划问题中起着重要作用。为了自动化或辅助逆合成分析,研究人员已经提出了各种逆合成预测算法。然而,它们中的大多数流程繁琐,且不具备对于其预测的可解释性。在本文中,我们设计了一种新颖的无需模板的,自动逆向合成算法。其灵感来自化学家如何进行逆向合成预测。
我们的方法将逆合成分解为两个步骤:i)通过新颖的图神经网络识别目标分子的潜在反应中心,并生成中间合成子;ii)通过稳健的反应物生成模型生成与合成子相关的反应物。我们的模型不仅在性能上远远超过了最新的基准,并且也提供了化学上合理的解释 。
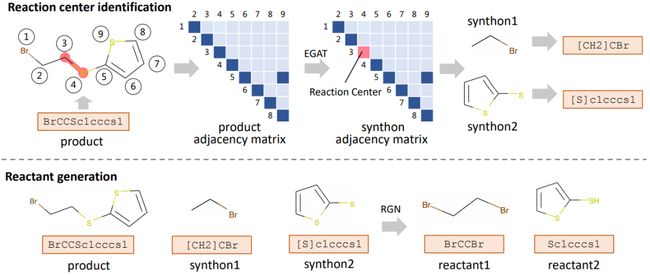
本文探索了利用深度图学习,以及序列到序列学习在分子逆合成中的有效性。所提算法可以有效地辅助药物研发。
其他
8.Min-Max优化问题的最佳历时随机梯度下降上升方法
Optimal Epoch Stochastic Gradient Descent Ascent Methods for Min-Max Optimization
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/3f8b2a81da929223ae025fcec26dde0d-Abstract.html
本文由腾讯AI Lab与爱荷华大学、华盛顿州立大学等合作完成。我们填补了随机min-max问题与随机最小化问题之间的间隔。我们针对一般强凸强凹(SCSC)min-max问题和一般弱凸强凹(WCSC)min-max问题提出了Epoch-GDA算法,不对目标函数的平滑度或结构施加任何其他假设。我们提出的关键引理为这两个问题提供了对Epoch-GDA的清晰分析。
(Hazan and Kale,2011)提出的历时梯度下降方法(又名Epoch-GD)被认为是解随机强凸最小化问题的突破,它实现了O(1 / T)的最佳收敛率,并通过T次更新迭代处理了目标间隙。然而,其扩展到解具有强凸性和强凹性的随机min-max优化问题的方法仍然是开放的,并且仍不清楚在强凸性和强凹性条件下随机min-max优化是否可以达到在对偶间隙上的O(1 / T)的收敛率。尽管最近的一些研究提出了针对min-max问题的具有快速收敛速度的随机算法,但是它们需要对该问题进行额外的假设,例如平滑度、双线性结构等。
在本文中,我们通过提供清晰的分析来弥合这一差距,提出历时随机梯度下降上升方法(称为Epoch-GDA)用于求解强凸强凹(SCSC)的min-max问题,而无需对光滑度或函数的结构施加任何其他假设。据我们所知,我们的结果是第一个表明Epoch-GDA可以针对一般SCSC min-max问题的对偶间隙实现O(1 / T)的最佳收敛率。我们强调,将求解强凸最小化问题的Epoch-GD方法推广到求解SCSC min-max问题的Epoch-GDA方法并非易事,需要新颖的技术分析。此外,我们注意到我们的关键引理也可用于证明Epoch-GDA对于解弱凸强凹的min-max问题的收敛性,从而导致几乎最佳的复杂度,而无需依赖平滑度或其他结构条件的假设。


这项工作在机器学习领域有着广泛的应用,包括AUC最大化,分布式鲁棒学习,GAN训练等等。
9.基于对抗学习的鲁棒性深度聚类
Adversarial Learning for Robust Deep Clustering
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/6740526b78c0b230e41ae61d8ca07cf5-Abstract.html
代码:https://github.com/xdxuyang/ALRDC
本文由腾讯AI Lab与西安电子科技大学、上海交通大学合作完成,提出了一种无监督对抗聚类网络,尝试利用对抗攻击与防御训练方法提升深度聚类网络的鲁棒性。
深度聚类可以结合特征嵌入和聚类以获得最佳的非线性嵌入空间。但是,聚类网络的鲁棒性很难得到保证,尤其是在遇到对抗性攻击时。由于缺少标签信息,因此在特征嵌入空间中的增加一组极小的扰动,就会导致截然不同的聚类结果。在本文中,我们提出了一种基于对抗学习的鲁棒深度聚类方法。我们首先尝试在特征嵌入空间中为聚类网络定义对抗性样本,同时,我们设计了一种对抗攻击策略,以挖掘易于使聚类层出现预测偏差但却不会影响深度嵌入网络性能的样本。然后,我们提供了一种简单而有效的防御算法,以提高聚类网络的鲁棒性。一些基准数据集上的实验结果证明了所提出的对抗学习方法可以显着增强鲁棒性,并进一步提高整体聚类性能。
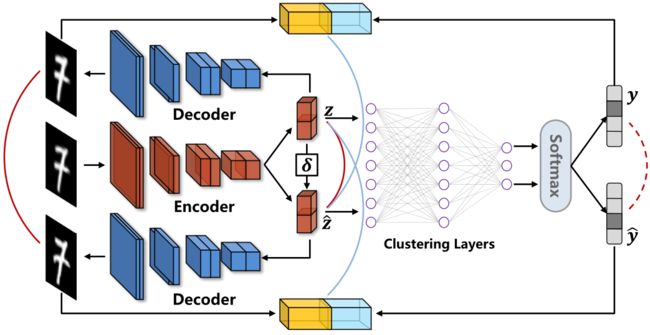
在本项研究中,攻击模型可以学习到一组轻微的扰动以干扰聚类网络,从而在无标签数据中准确挖掘不可靠、易错分的样本。另一方面,所提出的防御策略能够利用所学到的扰动,结合对比学习针对性的强化聚类网络,并提升网络的整体性能。考虑到深度聚类和无监督学习的脆弱性,该方法的优势在于能够对聚类网络进行“查漏补缺”,针对性的挖掘聚类网络的弱点,并进一步优化网络模型。
计算机视觉
CV相关的论文主题主要关注度量学习、多模态特征融合、手语翻译、纹理生成、光流估计等几个方向,提出了新的研究方法。
度量学习是机器学习里面一个比较基础的课题,它的目标是为样本学习一个新的距离度量,有了新的度量之后的任务,比如分类或者聚类会变得相对容易一点。多模态特征融合是为了融合多个模态的特征,主要解决的问题是如何捕捉和建模模态特征之间的交互。
10.少即是多:使用更少代理的深度图度量学习方法
Fewer is More: A Deep Graph Metric Learning Perspective Using Fewer Proxies
论文地址:https://arxiv.org/abs/2010.13636
代码:https://github.com/YuehuaZhu/ProxyGML.
本文由腾讯AI Lab与西安电子科技大学合作完成,提出了一种基于代理和反向标签传播的深度图度量学习方法,该方法通过在训练中自适应地为不同样本挑选最有信息量的参考代理点、动态地调整度量空间的流形结构,从而在高效地捕捉度量空间中的全局和局部关系的同时,促进模型训练的性能与效率。该工作的创新性受到审稿人和领域主席的高度认可,并入选为大会的Spotlight。
深度度量学习在各种机器学习任务中扮演着重要的角色。先前的大多数工作都局限于从小批量数据中采样,而小批量数据无法精确地描述嵌入空间的全局几何结构。尽管研究人员已经开发了基于代理和分类的方法来解决采样问题,但是这些方法不可避免地会产生多余的计算成本。在本文中,我们从图分类的角度提出了一种新颖的基于代理的深度图度量学习(ProxyGML)方法,该方法使用更少的代理,但可以获得更好的综合性能。具体来说,我们利用多个全局代理来全面地估计每个类的原始数据点。为了有效地捕获局部近邻关系,少量代理被自适应地挑选出来并与原始数据点的共同作用下构造相似性子图。此外,我们设计了一种新颖的反向标签传播算法,通过该算法可以根据真实标签对近邻关系进行调整,从而在子图分类过程中可以学习到有判别力的度量空间。在广泛使用的CUB-200-2011,Cars196和Stanford Online Products数据集上进行的大量实验证明,在有效性和效率两方面,所提出的ProxyGML优于最先进的方法。
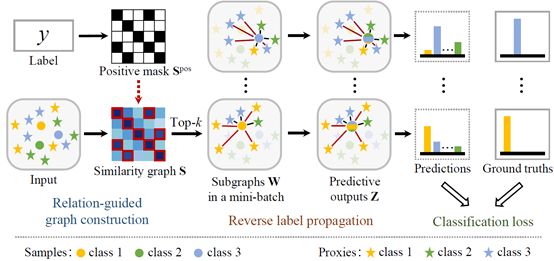
这项研究通过设计一个新颖的反向标签传播算法,首次成功将图分类范式融入到有监督的深度度量学习之中。该方法利用已知标签信息动态调控度量空间的流形结构,在提升度量学习任务精度的同时大大降低了以往方法高额的计算需求。值得一提的是,该方法可作为一个额外的损失函数附加于任意度量学习框架之上,具有很强的灵活性和泛化能力。
11.基于通道交换的深度多模态融合
Deep Multimodal Fusion by Channel Exchanging
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/339a18def9898dd60a634b2ad8fbbd58-Abstract.html
代码:https://github.com/yikaiw/CEN.
本文由腾讯AI Lab与清华大学合作完成。提出了一种新的深度多模融合框架,该框架通过在训练中自我引导地、动态地交换特定通道的特征,从而在保持足够的模态内自身特征学习的同时,促进模态间的特征交互。
利用多数据源进行分类或回归的深度多模态融合在各种应用中比单模态融合具有明显的优势。然而,现有的基于聚集和基于对准的融合方法在处理模态间融合和模态内处理之间的权衡方面还存在不足,成为性能提升的瓶颈。为此,本文提出了信道交换网络(CEN),这是一种无参数的多模态融合框架,可以在不同模式的子网络之间动态地交换信道。具体地说,信道交换过程是由训练中通过批处理标准化(BN)缩放因子的大小来度量的单个信道重要性自行指导的。这种交换过程的有效性也可以通过共享卷积滤波器来保证,同时在不同的模式之间保持分开的BN层,这是一个附加的好处,允许我们的多模态架构几乎和单模态网络一样紧凑。通过对RGB-D数据的语义分割和多域输入的图像翻译的大量实验,验证了CEN方法与目前最先进的方法相比的有效性。详细的实验研究也证实我们所提出的每个组件的优点。
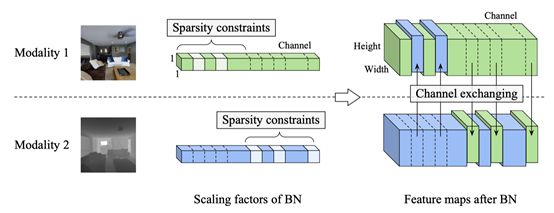
这项研究能够有效地融合来自不同模式的互补信息,这有助于提高自动驾驶汽车和室内操纵机器人的性能,也使它们对环境条件(如光线、天气)更加健壮。此外,我们没有采用现有方法中精心设计的分层融合策略,而是采用了一个全局准则来指导多模态融合,使模型在实际应用中更容易部署。
12.TSPNet:基于时序语义金字塔的手语翻译层次化特征学习
TSPNet: Hierarchical Feature Learning viaTemporal Semantic Pyramid for Sign Language Translation
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/8c00dee24c9878fea090ed070b44f1ab-Abstract.html
代码:https://github.com/verashira/TSPNet
本文由腾讯AI Lab与澳大利亚国立大学,悉尼科技大学合作完成,提出了一种基于多粒度视频片段的手语翻译层次化特征学习方法,该方法自适应地利用多粒度时序信息,对视频语义进行局部和全局的建模,极大缓解了对手势分割的需要,提升了翻译质量。
手语是聋哑人沟通交流的主要媒介。手语翻译旨在利用视觉技术,将手语视频序列解释为自然语言的句子,以实现聋人和听人的沟通交流。由于自然语言和手语的语法不存在严格的对应关系,在时序上对多个连续手语姿势进行分割存在困难。现有模型通过逐帧对手语视频进行建模来规避显式地时序分割,然而牺牲了模型对动作片段的建模能力。以此为出发点,本文提出了基于多粒度视频片段的手语视频表示,缓解了对准确手势分割的需要。在所提出的多粒度片段表示方法基础上,文章研究了一种新的层次化特征学习方式,利用跨尺度注意力模型促进局部语义一致性,利用尺度间注意力模型建模非局部视频信息,实现手语去歧义,从而显著提升手语翻译模型精度。
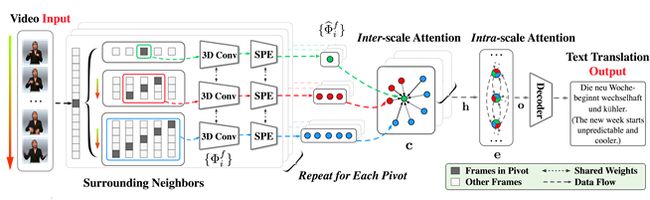
这项研究缓解了手语视频领域对于准确手势边界的依赖,有助于降低开发大规模手语翻译产品的成本,实现聋人和听人的无障碍沟通 ,从而提升听障人群的社会参与度和生活质量。
13.基于人体解析和跨视角一致性的单张图片到三维人体纹理迁移
Human Parsing Based Texture Transfer from Single Image to 3D Human via Cross-View Consistency
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/a516a87cfcaef229b342c437fe2b95f7-Abstract.html
本文由腾讯AI Lab与阿布扎比人工智能研究院、澳大利亚国立大学合作完成,提出了一种新的单图片三维人体纹理生成方法。
该方法使用人体解析作为输入来弱化人体表观变化对模型学习和推断的影响,并保留人体语义部件的信息来使模型能够感知不同的人体姿态,同时利用跨视角一致性学习来改进模型对输入人体图片非可见部分的纹理预测。
具体来说,我们交换两张不同视角图片生成的纹理,并希望所得到的渲染图片能够与彼此的输入图片保持相似性。为了训练模型,我们优化感知损失函数和全变分正则项来最大化渲染图片和输入图片之间的相似性。这一训练过程不需要引入额外的三维纹理监督。在来自监控和网络的两个人体图片数据集上的实验结果表明,相比其他纹理生成方法,我们的方法能够产生更高质量具有更多细节的纹理图片。
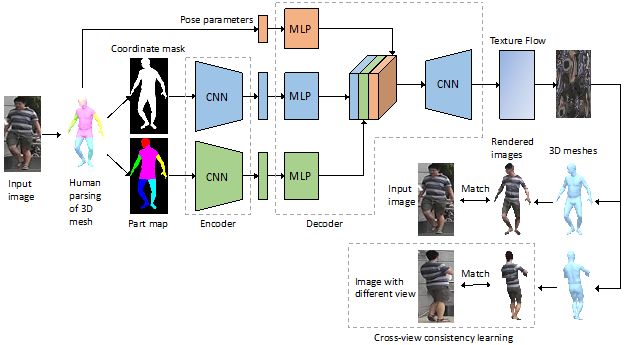
该项研究仅使用单张图片来生成三维人体纹理并且无需使用三维纹理监督来训练模型,这极大的方便了三维人体重建在实际场景中的应用,如VR,三维动画制作,虚拟试衣,训练数据合成等。此外,使用人体解析而非原始图片作为输入能够有效提高模型在实际应用中的泛化能力。
14.基于学习位移不变匹配代价的精确光流估计
Displacement-Invariant Matching Cost Learning for Accurate Optical Flow Estimation
论文地址:
https://proceedings.neurips.cc/paper/2020/hash/add5aebfcb33a2206b6497d53bc4f309-Abstract.html
本文由腾讯 AI Lab 与澳大利亚国立大学、西北工业大学、NEC实验室等合作完成,提出一种新型的匹配代价的学习方法,通过解耦位移跟代价极大地减少运算量,同时仍然可以像立体匹配方法一样,从数据中学习匹配代价。
学习好的匹配代价对于最新深度立体匹配方法的成功至关重要。为了学到好的匹配代价,他们通常需要构建一个4D的特征体然后用3D卷积来处理。但是这种方式从来没有在光流任务上被采用。这主要是因为光流巨大的搜索空间,直接使用类似的方法则需要4D 卷积来处理5D的特征体,这在现有的计算能力上是无法实现的。
本文提供了一种新颖的解决方案,在不需要构建5D 特征体的基础上仍然允许网络来学习合适的匹配代价。我们的关键创新点是解耦2D位移之间的关系,在每一个2D位移上独立学习匹配代价。具体来说,我们用同一个2D卷积网络来处理每一个2D位移候选来构建了一个4D的代价体。同时,为了考虑相邻的位移候选之间的关系以及缓解学习到的代价体的多峰问题,我们提出了一个位移感知投影层来调整不同位移候选之间的代价。最终的光流可以通过一个可导的取最小值操作从代价体中获取。大量的实验表明,这个方法在各个数据集上实现了最高的准确度并且在Sintel数据集上超过了现有的光流算法。
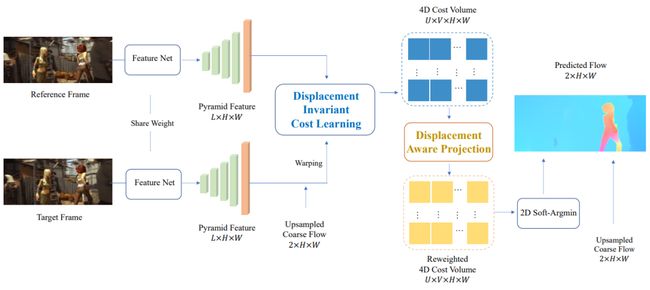
本研究可能应用于姿态估计、动作识别、自动驾驶等场景。
