Optical Flow Guided Feature(OFF)简单介绍
这篇论文的code最初只有Caffe版本,这里附上pytorch版本。
JoeHEZHAO/Optical-Flow-Guided-Feature-Pytorch: Optical Flow Guided Feature for Action Recognition-Pytorch (github.com) https://github.com/JoeHEZHAO/Optical-Flow-Guided-Feature-Pytorch由于一些原因,需要对这篇论文介绍的OFF部分代码进行拆解,因此先上论文中的相关部分,再做进一步解释,水平有限,表达不准确敬请谅解。
https://github.com/JoeHEZHAO/Optical-Flow-Guided-Feature-Pytorch由于一些原因,需要对这篇论文介绍的OFF部分代码进行拆解,因此先上论文中的相关部分,再做进一步解释,水平有限,表达不准确敬请谅解。
论文传送门:
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition (thecvf.com)https://openaccess.thecvf.com/content_cvpr_2018/papers/Sun_Optical_Flow_Guided_CVPR_2018_paper.pdf对于传统的CNN来说,在对视频进行特征提取时比较困难,因为视频不同于图像,空间特征+时间特征更能代表视频。这篇论文基于TSN的网络结构,在此基础上作者设计了一个OFF Unit用来进行时间维度特征的提取,网络的整体结构有兴趣的可以查看论文,在此我仅仅介绍OFF Unit的结构以及代码部分。
首先看看OFF Unit在整体网络结构的位置:

图 1 论文网络结构
上图中有两个特征提取的子网络,提取不同时段的特征,一个由OFF Unit构成的OFF子网通过上面两个子网提取时间信息,最后通过每个子网的Class Score进行融合来进行分类。接下来进一步看OFF Unit的结构图:
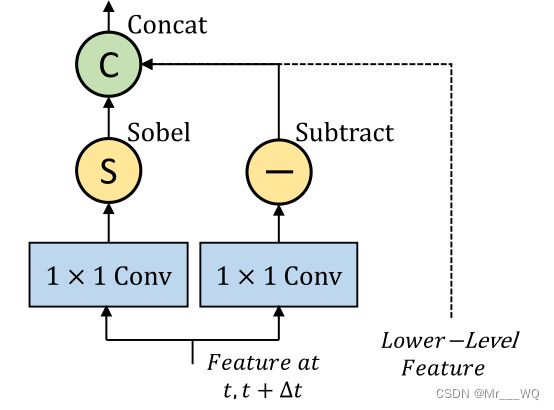
图 2 OFF Unit 结构
论文中Sobel算子和Subtract的结合称为OFF,再加上前面的1*1卷积构成OFF layer。特征经过OFF Unit进行两次卷积,一个分支利用Sobel算子提取空间特征,利用逐元素减法(Subtract)操作提取时间信息,结合图一,经OFF Unit出来的信息通过ReseNet进入下一模块。
OFF模块基本的代码在代码中有所体现,其并未将OFF单独作为Class进行实现,论文中含有多个OFF,部分OFF在进行卷积时输入的通道数以及尺寸均有所不同,此处仅仅以motion_3a为例,至于如何加入到其他的网络结构,需要对里面的shape进行更进一步的计算和设计,否则会出现维度不一致等问题,此处将OFF作为一个Class进行实现,相关代码如下,如有错误敬请指正。
from __future__ import print_function, division, absolute_import
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
import os
import sys
from torch.autograd import Variable
from util import SobelFilter, SobelFilter_Diagonal
from basic_ops import *
import pdb
class OFFNet(nn.Module):
def __init__(self, batch, length, in_channels, h, w):
super(OFFNet, self).__init__()
self.batch = batch
self.length = length
self.motion_conv_gen = nn.Conv2d(in_channels[0], 128, kernel_size=(1, 1), stride=(1,1))
self.motion_spatial_down = nn.Conv2d(in_channels[1], 32, kernel_size=(1,1), stride=(1,1))
self.motion_spatial_grad = nn.Conv2d(in_channels[2], 32, kernel_size=(3,3), stride=(1,1), padding=(1,1), groups=32, bias=True)
self.motion_relu_gen = nn.ReLU()
self.dropout = nn.Dropout(p=0.8)
def forward(self, x):
# print(x.shape)
# motion operating on [batch * length, c, h, w] level
# motion_conv_gen = self.motion_conv_gen(x)
motion_conv_gen = self.motion_conv_gen(x)
motion_relu_gen = self.motion_relu_gen(motion_conv_gen)
channel_size = motion_relu_gen.shape[1] #
reshape_rgb_frames = motion_relu_gen.view(self.batch, -1, self.h, self.w)
# print(reshape_rgb_frames.shape)
last_frames = reshape_rgb_frames[:, channel_size:, :, :]
# print(last_frames.shape)
first_frames = reshape_rgb_frames[:, :-channel_size, :, :]
# print(first_frames.shape)
eltwise_motion = last_frames - first_frames
# print(eltwise_motion.shape)
# convert back to [batch * (time - 1), c, h, w]
temporal_grad = eltwise_motion.view(-1, channel_size, self.h, self.w)
spatial_frames = x[:self.batch * (self.length - 1), :, :, :]
# downgrade dimension to 32
spatial_down = self.motion_spatial_down(spatial_frames)
spatial_grad = self.motion_spatial_grad(spatial_down)
spatial_grad = self.dropout(spatial_grad)
# print(spatial_grad.shape)
# concatenate temporal and spatial dimension
# import pdb;pdb.set_trace()
# print(spatial_grad.shape)
# print(temporal_grad.shape)
motion = torch.cat((spatial_grad, temporal_grad), dim=1)
return motion
#in_channels[motion_3a:[256,256,32],
# motion_3b:[320,320,32],
# motion_3c:[576,576,32],
# motion_4a:[576,576,32],
# motion_4b:[576,576,32],
# motion_4c:[608,608,32],
# motion_4d:[608,608,32],
# motion_5a:[1024,1024,32],
# motion_5b:[1024,1024,32]
# ]
]
代码中均有注释,对应于OFF layer的结构即可读懂,由于论文中OFF进行卷积时,输入通道数不一致,此处将输入通道数作为参数传入,方便将模块加入其他模块中,此论文中输出通道数一致,不做进一步处理,也可自行更改作为参数处理, 最下面的为本文中的所有OFF中操作的输入通道数。至于里面的sobel算子等,想要进一步了解的可以自行查阅相关资料。