K-均值算法的原理与实战
K-均值(K-means)算法是一种常用的聚类算法。
当我们需要对未标记的数据划分类别时,往往用到的算法是聚类(clustering)。聚类是一种无监督的学习,它试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”(cluster);相似的样本归到一个簇中,不相似的样本分到不同的簇中。
K-均值(K-means)算法是一种聚类算法,k 是用户指定的簇个数,每个簇通过其质心(centroid),即簇中所有点的中心来描述。
算法原理
给定样本集 D D D = { x 1 , x 2 , . . . , x m x_1,x_2,...,x_m x1,x2,...,xm}, k k k 均值算法将样本集 D D D划分为 k k k个互不相交的簇 C C C = { C 1 , C 2 , . . . , C k C_1,C_2,...,C_k C1,C2,...,Ck},划分的依据是样本的相似度,相似的样本会归入同一簇,不相似的样本会归入不同簇。
相似度的计算方法有多种,常见的有曼哈顿距离,欧几里得距离,余弦相似度等。 k k k 均值算法使用的是欧几里得距离(Euclidean Distance),即两点间的真实距离。给定样本 x i = ( x i 1 , x i 2 , . . . , x i n ) x_i = (x_{i1},x_{i2},...,x_{in}) xi=(xi1,xi2,...,xin) 与 x j = ( x j 1 , x j 2 , . . . , x j n ) x_j = (x_{j1},x_{j2},...,x_{jn}) xj=(xj1,xj2,...,xjn),计算样本间的欧几里得距离的公式如下:
d i s t e d ( x i , x j ) = ∣ ∣ x i − x j ∣ ∣ 2 = ∑ u = 1 n ∣ x i u − x j u ∣ 2 dist_{ed}(x_i,x_j) = ||x_i-x_j||_2 = \sqrt{\sum_{u=1}^{n}{|x_{iu}-x_{ju}|}^2} disted(xi,xj)=∣∣xi−xj∣∣2=u=1∑n∣xiu−xju∣2
k k k 均值算法的流程是这样的。第一步,从数据集中随机选择 k k k个点作为簇质心。第二步,将样本集中的每个点分配到一个簇中,具体来讲,为每个点找距其最近的质心,并将其分配给该质心所对应的簇。第三步,每个簇的质心更新为该簇所有点的平均值。重复上述步骤二与步骤三,直到所有的簇不再发生变化。该过程的伪代码表示如下:
输入: 样本集 D D D = { x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn};
聚类簇数 k k k
过程:
- 从 D D D中随机选择 k k k个样本作为初始均值向量{ u 1 , u 2 , . . . , u k u_1,u_2,...,u_k u1,u2,...,uk}
- repeat
- 令 C i = ∅ ( 1 ≤ i ≤ k ) C_i = \emptyset (1 \leq i \leq k) Ci=∅(1≤i≤k)
- for j = 1 , 2 , . . . , m j = 1,2,...,m j=1,2,...,m do
- 计算样本 x i x_i xi与各均值向量 u i u_i ui( 1 ≤ i ≤ k ) 1 \leq i \leq k) 1≤i≤k)的距离: d j i = ∣ ∣ x j − u i ∣ ∣ 2 d_{ji}=||x_j-u_i||_2 dji=∣∣xj−ui∣∣2;
- 根据距离最近的均值向量确定 x i x_i xi的簇标记: λ i = a r g m i n i ∈ { 1 , 2 , . . . , k } d j i \lambda_i = argmin_{i \in {\{1,2,...,k\}}} d_{ji} λi=argmini∈{1,2,...,k}dji;
- 将样本 x j x_j xj划入相应的簇: C λ j ⋃ { x j } C_{\lambda_j}\bigcup\{x_j\} Cλj⋃{xj};
- end for
- for i = 1 , 2 , . . . , k i = 1,2,...,k i=1,2,...,k do
- 计算新均值向量: u i ′ = 1 ∣ C i ∣ ∑ x ∈ C i x u_i^{'} = \frac{1}{|C_i|}\sum_{x \in C_i}x ui′=∣Ci∣1∑x∈Cix;
- if u i ′ ≠ u i u_i^{'} \neq u_i ui′=ui then
- 将当前均值向量 u i u_i ui更新为 u i ′ u_i^{'} ui′
- else
- 保持当前均值向量不变
- end if
- end for
- until 所有样本的簇标记均未更新
输出: 簇划分 C = { C 1 , C 2 , . . . , C k } C = \{C_1,C_2,...,C_k\} C={C1,C2,...,Ck}
簇划分完成后,如何评价聚类效果的好与坏呢?一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和),SSE值越小表示数据点越接近于它们的质心,聚类效果也越好。
S S E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − u i ∣ ∣ 2 2 SSE = \sum_{i=1}^k\sum_{x\in C_i}||x-u_i||_2^2 SSE=i=1∑kx∈Ci∑∣∣x−ui∣∣22
其中 u i = 1 ∣ C i ∣ ∑ x ∈ C i x u_i = \frac{1}{|C_i|}\sum_{x \in C_i}x ui=∣Ci∣1∑x∈Cix 是簇 C i C_i Ci的均值向量。该式在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度, S S E SSE SSE值越小则簇内样本相似度越高。
编程实战
首先从百度网盘下载测试数据集,下载链接:https://pan.baidu.com/s/1wShFlsq36Fez5-Qh10Jpog ,提取码:ltaw。然后在Jupyter Notebook中运行以下代码。
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
#文本文件导入矩阵
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t') #当前行切割为列表
fltLine = list(map(float,curLine)) #转换元素的数据类型为float
dataMat.append(fltLine)
return np.mat(dataMat)
#计算两个向量的欧氏距离
def distED(vecA, vecB):
return np.sqrt(np.sum(np.power(vecA - vecB, 2)))
#构建k个初始簇质心
def randCent(dataSet, k):
m = np.shape(dataSet)[0] #总样本数
centIdx = set() #随机样本索引
while len(centIdx) < k:
randj = np.random.randint(m)
centIdx.add(randj)
centroids = dataSet[list(centIdx)] #初始簇质心
return centroids
#K-均值聚类方法
def kMeans(dataSet, k, distMeas=distED, createCent=randCent):
m = np.shape(dataSet)[0] #样本总数
clusterAssment=np.mat(np.zeros((m,2))) #簇分配结果矩阵
centroids=createCent(dataSet,k) #构建k个初始随机质心
clusterChanged=True #簇变化标志
while clusterChanged: #直到簇不再变化
clusterChanged=False
for i in range(m): #遍历所有样本点
minDist=np.inf #样本点离最近质心的距离
minIndex=-1 #样本的簇标记
for j in range(k): #遍历所有的质心
distJI = distMeas(centroids[j,:],dataSet[i,:]) #样本点I到质心J的距离
if distJI < minDist:
minDist=distJI
minIndex=j
if clusterAssment[i,0] != minIndex: clusterChanged = True #样本点的簇标记发生变化
clusterAssment[i,:]= minIndex,minDist**2 #簇分配结果矩阵的两列分别为簇标记和误差
for cent in range(k): #更新质心的位置
ptsInClust = dataSet[np.nonzero(clusterAssment[:,0].A == cent)[0]] #给定簇下的所有样本点
centroids[cent,:] = np.mean(ptsInClust, axis=0) #axis=0表示沿列方向计算均值
return centroids,clusterAssment
#绘制所有样本点与质心
def drawPic(dataMat,centroids,clusterAssment):
type1_x=[];type1_y=[];type2_x=[];type2_y=[];type3_x=[];type3_y=[];type4_x=[];type4_y=[]
for i in range(dataMat.shape[0]):
if clusterAssment[i,0]==0:
type1_x.append(dataMat[i,0])
type1_y.append(dataMat[i,1])
elif clusterAssment[i,0]==1:
type2_x.append(dataMat[i,0])
type2_y.append(dataMat[i,1])
elif clusterAssment[i,0]==2:
type3_x.append(dataMat[i,0])
type3_y.append(dataMat[i,1])
elif clusterAssment[i,0]==3:
type4_x.append(dataMat[i,0])
type4_y.append(dataMat[i,1])
cent_x=centroids[:,0].T.tolist()[0]
cent_y=centroids[:,1].T.tolist()[0]
p1 = plt.scatter(type1_x,type1_y,s=30,marker='x')
p2 = plt.scatter(type2_x,type2_y,s=30,marker='x')
p3 = plt.scatter(type3_x,type3_y,s=30,marker='x')
p4 = plt.scatter(type4_x,type4_y,s=30,marker='x')
cent = plt.scatter(cent_x,cent_y,s=200,marker='o')
plt.legend(["p1","p2","p3",'p4','cent'],bbox_to_anchor=(1, 1))
plt.show()
#加载数据集
dataMat=loadDataSet('kMeansTestSet.txt')
#生成聚类结果(簇质心和簇分配结果)
myCentroids, myClusterAssment = kMeans(dataMat, 4)
#绘制聚类结果图
drawPic(dataMat, myCentroids, myClusterAssment)
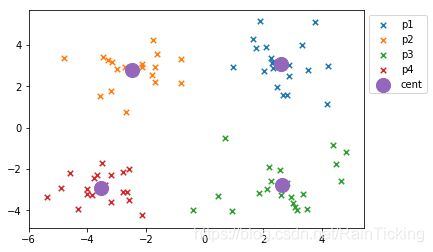
最终的聚类结果图如下,其中p1-p4为划分为4种类别的簇,cent为簇质心。
结语
聚类是一种无监督学习方法。所谓无监督学习是指事先并不知道要寻找的内容,即没有目标变量。聚类试图做到“物以类聚”,即将相似数据点归于同一簇,而不相似数据点归于不同簇。聚类中相似的概念取决于所选择的相似度计算方法。
一种广泛使用的聚类算法是K-均值算法,其中k是用户指定的要创建的簇的数目。K-均值算法以 k k k个随机质心开始。算法会计算每个点到质心的距离,每个点会被分配到距其最近的簇质心。然后基于新分配到簇的点更新簇质心。以上过程重复数次,直到簇质心不再改变。
K-均值算法非常简单有效,但是也容易受到初始簇质心的影响。算法只是收敛到局部最小值,而非全局最小值。一种聚类效果的评估指标是SSE,值越小表示数据点越接近质心,聚类效果也越好。其中一种比较笨的解决办法是,通过多次执行该算法,选择SSE值最小的那一个。
为了克服K-均值算法只收敛到局部最小值的问题,下篇文章将会讲解聚类效果更好的二分K-均值(bisecting K-means)算法。