点云 3D 目标检测 - PointPillars
点云 3D 目标检测 - PointPillars
- 1. 文章信息
- 2. PointPillars 简介
-
- 2.1 算法特点
- 2.2 模型结构
-
- 2.2.1 Pillar Feature Net
- 2.2.2 Backbone (2D CNN)
- 2.2.3 Detection Head (SSD)
- 2.3 数据预处理
- 2.4 数据增强
- 2.4 损失函数和评价指标
1. 文章信息
- 文章标题
PointPillars: Fast Encoders for Object Detection from Point Clouds (2019)
- 文章链接
https://arxiv.org/pdf/1812.05784.pdf
- 文章代码
https://github.com/nutonomy/second.pytorch
推荐:各大流行 3D 目标检测框架 均集成,亦可参考 点云 3D 目标检测 - 开源算法集合
2. PointPillars 简介
2.1 算法特点
开源、运行快、工业界能应用
2.2 模型结构
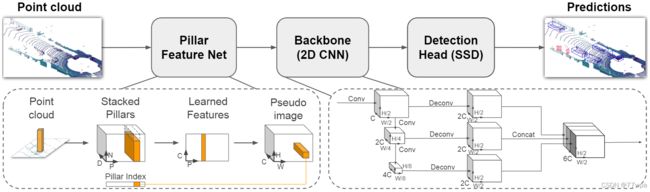
PointPillars 主要由3部分组成:
(看英文原文能更好的理解算法细节,所以就不翻译了)
-
Pillar Feature Net:it uses a non-linear MLP and MaxPool operation to extract features to construct a pseudo image of size (H, W, C), with C representing the feature dimension.
-
Backbone (2D CNN):given pseudo image generated by Pillar Feature Net as input, it uses stacked CNN layers to produce final feature represention which aggregates features from multiple stages.
-
Detection Head (SSD): it is used to make predictions of class, bounding box and direction on the features generated by the CNN backbone, and aggregates them together to generate final predictions.
2.2.1 Pillar Feature Net
Given a sample of point clouds , Pillar Feature Net (PFN for short) will build special pillars per unit of X-Y grid (it doesn’t do partition on Z direction). Firstly, every point in point clouds will be encoded manually to a feature of 9 dimension (detail of the process is in Data Preprocessing). Then, PFN will use a MLP, a 16 channel linear layer with BN and ReLU for example, to convert the 9-dim feature to a 16-dim feature. After that, PFN adopts a MaxPool operation for each pillar to aggregate the 16-dim features of all the points in it to get the maximum response in each dimension, getting a 16-dim feature to represent each pillar.
Finally, the pillar features are scattered back to their spatial locations in X-Y plane, and a tensor of size HxWx16 is created, which is also called Pseudo image. The pseudo image will be used as input to the following backbone.
2.2.2 Backbone (2D CNN)
PointPillars uses a VGG-like structure to construct the 2D CNN backbone. By stacking several convolutional layers, the backbone will produce feature maps with different solution in each stage. Feature maps from several stages will be fused together to create a final feature representation. During feature fusion process, Deconv Layer is introduced to upsample high level feature maps, which have smaller resolutions. After deconvolution, all the ouptut feature maps with same resolution can be concatenated together to form a integrated tensor for final prediction.
2.2.3 Detection Head (SSD)
PointPillars uses SSD as its detection head, which is an anchor-based single stage detection pipeline. 3 prediction branches are introduced to do 3d object detection:
- category classification branch
- bounding-box regression branch
- direction classification branch
During inference, the outputs from these 3 branches will generate predictions based on pre-set anchors. After applying Non-maximum Suppression, the 3d bouding boxes with high confidence are selected out as the final detection results.
2.3 数据预处理
- Since the point cloud is quite different from image data in disorder and sparsity, the preprocess method plays a crucial part in 3D detection based on point cloud. The key idea of VoxelNet, SECOND, PointPillars and other algorithms alike is voxelization. Voxelization discretize 3d space into voxels and assign points to one voxel if they are in it, thus arranging the disordered points by ordered voxels. And by droping the empty voxels, the sparsity can be greatly reduced.
- In particular, PointPillars does not discretize space along height orientation, resulting in pillars go across from bottom to top. In detail, we define pillar size as (0.25, 0.25) in space range (0, -40, 80, 40), resulting in 320x320x1 pillars. For every pillar, we randomly sample points in it with maximum number set at 40. Each point has attribute (x, y, z, r), with (x, y, z) representing its location and r for reflectivity. To enrich the information of points, we derive (xc, yc, zc) and (xp, yp) from original(x, y, z), in which c subscript denotes distance to the arithmetic mean of all points in the pillar and p subscript denotes the offset from the geometry center of the pillar.
2.4 数据增强
Since the point cloud data is expansive to get and annotate, the volume of trainset is limited. Proper data augmentation methods help a lot to improve model performance.
-
Database sampling
One way to compensate for limited trainset and limited object is to oversample objects. Before training, we use the 3d box annotation to crop objects out of all the training samples and store them as database. In training, we randomly take a fixed amount of objects out of database and paste them into training sample. If the pasted object is in confict with the existing objects in the sample, it will be abandoned. And during pasting, geometry transformations can be applied to each object from database. -
Geometry transformations
Common techniques for 2d geometry augmentation can also be used in 3d case. On object level, we apply random rotation and tranlation to each object in the sample. And on sample level, we apply global flip, rotation, scaling and translation to the whole point cloud. -
Shuffling
Since the points are disordered and we can not sample all the points in consideration of computation efficiency under our Voxelization policy, we may drop some points in every sample. To avoid overfitting, we shuffle the points before Voxelization.
2.4 损失函数和评价指标
-
Loss For 3d object detection, we need to predict the label, location, shape and direction right. To regress label efficiently, PointPillars uses FocalLoss to address the problem of extreme foreground-background class imbalance. For the positive anchors, SmoothL1 Loss is adopted to regress location and shape, and CrossEntropy Loss to regress direction. To balance these three losses, coeffience of 1.0 for label loss, 2.0 for bbox regression loss and 0.2 for direction loss is applied.
-
Trick in building Loss Followting the traditional method in regressing bounding box, logarithmic value of the relative distance and size is used as regression target to make learning procedure more controllable and stable. And an angle loss regression task from SECOND is introduced to improve the orientation estimation performance, and make the model perform well on IoU-based metric, which is independent of box orientation.
-
Metric KITTI Metric evaluates 3D object detection performance using the PASCAL criteria also used for 2D object detection. For cars it requires an 3D bounding box overlap of 70%, while for pedestrians and cyclists it requires a 3D bounding box overlap of 50%. Difficulties are defined as follows:
-
Easy: Min. bounding box height: 40 Px, Max. occlusion level: Fully visible, Max. truncation: 15 %
-
Moderate: Min. bounding box height: 25 Px, Max. occlusion level: Partly occluded, Max. truncation: 30 %
-
Hard: Min. bounding box height: 25 Px, Max. occlusion level: Difficult to see, Max. truncation: 50 %