48、深度学习开发笔记
一、开发环境安装
1.1、安装cuda
1.2、安装cudnn
1.3、安装anaconda
1.4、安装pycharm
二、开发环境搭建
如果你去github上下载并安装软件dev-sidecar,运行软件后,可忽略2.1和2.2章节
2.1、设置pip源
pip 是最为广泛使用的 Python 包管理器,作用和conda很像(但是conda更适用,建议适用conda,如果你只使用conda,可忽略此配置,如果你两个都要使用,可以两个都配置),在 user 目录中创建一个 pip 目录,如: C:\Users\xx\pip,xx是用户名,新建文件pip.ini(建议先新建成 .txt 文件,之后将后缀名改回),内容如下:
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = https://pypi.tuna.tsinghua.edu.cn2.2、设置conda源
conda是anaconda自带的Python包管理器,其主要作用是从服务器下载各种包来安装,由于conda的默认服务器地址是国外的,所以在下载包的过程中可能出现网速慢,下载失败等问题。但是我们可以自己指定服务器地址,也就是重新设置conda的源。配置方很简单,可以直接修改C:\Users\BaoTing\.condarc文件,也可以通过conda命令间接修改此文件(无文件自行创建即可)。
# 修改文件 C:\Users\BaoTing\.condarc 为如下内容:<设置conda的源为清华源>
channels:
- defaults
show_channel_urls: true
default_channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/mro
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
ssl_verify: false
# 注1:如果更改后你想重新设置为默认设置,执行如下命令即可:
conda config --remove-key channels
# 注2:如过你有VPN,你可以不用进行此类设置,使用默认的conda源就行。
# 注3:临时使用Anaconda官方源下载
conda install -c conda-forge visdom //使用Anaconda的官方源conda-forge,下载visdom2.3、创建pytorch开发环境
步骤、创建py3.7、安装setuptools包、pytorch包、tensorboard包
# 0、conda create -n pytorch python=3.7
# 1、conda activate pytorch
# 2、conda install setuptools=58.0.4 # 建议版本小于60.0.0
# 3、conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch
# 4、conda install tensorboard=1.15.0 # 建议版本大于等于1.15.0三、深度学习基础
3.1、梯度下降算法
# -*- coding:utf-8 -*-
# -->梯度下降算法<--
# 求整体样本的梯度均值,每个整体更新一次梯度值
# 样本之间是没有依赖的:即此次梯度下降要使用整体样本的梯度(故每次梯度下降可并行)
# 这里的并行该怎么理解?:因为是用的所有样本的loss的求和或平均,故可以并行求每个样本的loss.
# 线性模型y= w * x + b,这里使用b = 0
# 深度学习的目的:寻找合适的权重w,使loss最小
import numpy as np
import matplotlib as plt
# 数据集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return w * x
def cost(xs, ys): # 计算损失函数(MSE)
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost/len(xs)
def gradient(xs, ys): # 计算梯度函数
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad/len(ys)
if __name__ == '__main__':
w = 4.0 # 初始权重猜测
for epoch in range(100): # 训练100次
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w = w - 0.01 * grad_val
print("Epoch:", epoch, "w=", w, "loss=", cost_val)
3.2、随机梯度下降
# -*- coding:utf-8 -*-
# -->随机梯度下降算法<--
# 求单个样本的梯度,每个样本更新一次梯度值
# 样本之间是有依赖的:即此次梯度下降要使用上一个样本的梯度(故每次梯度下降不可并行)
# 线性模型y= w * x + b,这里使用b = 0
# 深度学习的目的:寻找合适的权重w,使loss最小
import numpy as np
import matplotlib as plt
# 数据集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0 # 初始权重设定
def forward(x_in): # f(x) = w * x
return w * x_in
def loss(x, y): # 计算损失:loss = (f(x)-y_data)^2
y_pred = forward(x)
return (y_pred - y) ** 2
def gradient(x, y): # 计算梯度:grad = 2 * x * (x * x -y)
return 2 * x * (x * w - y)
if __name__ == '__main__':
for epoch in range(100): # 训练100次
loss_sum = 0.0
for x, y in zip(x_data, y_data):
grad_val = gradient(x, y)
w = w - 0.01 * grad_val
print("\tgrad:", x, y, grad_val)
loss_sum += loss(x, y)
print("Epoch:", epoch, "w =", w, "mseloss =", loss_sum/len(y_data))
总结:梯度下降算法的性能低,但时间复杂度也低。随机梯度下降性能高,但时间复杂度也高。深度学习上常取折中的方法-Batch:即若干个样本打包在一起求梯度,然后进行一次梯度下降。
3.3、反向传播算法
本例使用pytorch实现反向传播算法,pytorch的tensor类型有两个属性,data和grad,其中data存的就是权重w,grad存的就是损失函数loss对权重w的导数。
# -*- coding:utf-8 -*-
# -->反向传播算法<--
import torch
# 数据集,共三个分别是(1.0,2.0)、(2.0,4.0)、(4.0,8.0)
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 网络的权重
w = torch.Tensor([1.0])
w.requires_grad = True # 指定w是要计算梯度的
def forward(x_): # 模型 y = w * x
return w * x_ # 此处会发生隐式类型转换,把x_转为tensor类型,而且带梯度计算
def loss(x_, y_): # 计算损失:loss = (f(x)-y_data)^2
y_pred = forward(x_)
return (y_pred - y_) ** 2
if __name__ == '__main__':
for epoch in range(100): # 训练100次
loss_sum = 0.0
for x, y in zip(x_data, y_data):
# 反向传播
loss_val = loss(x, y) # 前馈
loss_val.backward() # 反馈、会把梯度结果(loss对w的导数)存到w的grad里面
# 梯度下降
print("\tgrad:", x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # 操作tensor的data不会产生计算图
w.grad.data.zero_() # 梯度数据清零,不清除的下一次会叠加(有的模型会用到梯度叠加)
# 损失叠加
loss_sum += loss_val.item() # 这里使用item()也是为了不产生计算图,因为tensor类型的计算会产生计算图
print("Epoch:", epoch, "w =", w, "mseloss =", loss_sum/len(y_data))3.4、线性回归示例
线性回归其实就是根据数据拟合一个线性函数 ![]() ,线性回归的过程就是求权重w和偏移b的过程,线性回归是一个最简单的神经网络。pytorch有封装好的线性类,权重w和偏移b参数的调整由pytorch提供的优化器进行调整。
,线性回归的过程就是求权重w和偏移b的过程,线性回归是一个最简单的神经网络。pytorch有封装好的线性类,权重w和偏移b参数的调整由pytorch提供的优化器进行调整。
# -*- coding:utf-8 -*-
# -->线性回归示例<--
import torch
from torch.utils.tensorboard import SummaryWriter
# 数据集,共三个分别是(1.0,2.0)、(2.0,4.0)、(4.0,8.0)
x_data = torch.Tensor([[1.0], [2.0], [3.0]]) # 需要注意的是,这是个矩阵***
y_data = torch.Tensor([[2.0], [4.0], [6.0]]) # 需要注意的是,这是个矩阵***
# 定义一个线性模型
class MyDef_linearModel(torch.nn.Module):
def __init__(self):
super(MyDef_linearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1) # 实例化一个线性对象(输入通道数,输出通道数) y^=x*w^T+b,参数w和b由优化器接管
def forward(self, x):
y_pred = self.linear(x)
return y_pred
if __name__ == '__main__':
model_obj = MyDef_linearModel() # 实例化模型
mseloss_sum = torch.nn.MSELoss(reduction='none') # 实例化一个损失计算器对象,计算一个batch中所有所有数据loss的平方差,的和。
optimizer_obj = torch.optim.SGD(model_obj.parameters(), lr=0.01) # 实例化一个优化器,lr为学习率,即w = w - 0.01*w
for epoch in range(500):
y_pred = model_obj(x_data)
loss_val = mseloss_sum(y_pred, y_data)
print("epoch=", epoch, "loss_val =", loss_val)
optimizer_obj.zero_grad() # 使用优化器清空所有权重w的梯度
loss_val.backward() # 反向传播(计算l对w的导数,并存入w的grad参数中),注意反向传播只支持标量,mseloss_sum是加和后,是个标量
optimizer_obj.step() # 根据学习率进行更新权重w(梯度下降)
print("w = ", model_obj.linear.weight.item())
print("b = ", model_obj.linear.bias.item())
print(type(x_data))
# 模型可视化
writer = SummaryWriter("logs-cur") # 实例化一个可视化工具
writer.add_graph(model_obj, x_data) # 把模型载入可视化工具
writer.close() # 关闭可视化工具
# 其它:
# mseloss_mean = torch.nn.MSELoss(reduction='mean') # 实例化一个损失计算器对象,计算一个batch中所有所有数据loss的平方差,的平均。
# mseloss_none = torch.nn.MSELoss(reduction='none') # 实例化一个损失计算器对象,计算一个batch中所有所有数据loss的平方差。输入数据x_data = torch.Tensor([[1.0], [2.0], [3.0]])是一个3*1的tensor,是3个输入数据,mseloss_sum是求的这三个数据的loss的和,然后根据loss的和计算梯度,属于梯度下降而不是随机梯度下降,每个数据都有一个loss,但这3个loss必须组成标量才能计算梯度(反向传播)。3个数据一起输入,就是一个batch输入,batch的目的就是把数据分组打包,一组一个梯度,而不是一个数据一个梯度,这样就是(梯度下降+随机梯度下降)折中的处理方式==>batch。
3.5、逻辑回归示例
逻辑回归虽然叫回归,但是其是用于解决二分类问题。分类问题的输出不是实数,而是一个概率。以二分类为例,输出的![]() ,在线性回归中我们知道,输出是个实数,那么怎么把输出映射到[0,1]呢,这就需要一个函数sigmoid函数(饱和函数),图像如下:
,在线性回归中我们知道,输出是个实数,那么怎么把输出映射到[0,1]呢,这就需要一个函数sigmoid函数(饱和函数),图像如下:

输出值加了sigmoid函数后,损失函数(交叉熵的二分类计算法)也需要更改:

示例代码如下:
# -*- coding:utf-8 -*-
# -->逻辑回归<--
import torch
import torchvision
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
# 数据集,3个输入数据:1.0、2.0、3.0 # 学习时间
# 输入数据的target: 0、 0、 1 # 0:合格、1:不合格
x_data = torch.Tensor([[1.0], [2.0], [3.0]]) # 数据input
y_data = torch.Tensor([[0], [0], [1]]) # 数据target(计算误差时使用)
# 定义一个线性模型
class MyDef_linearModel(torch.nn.Module):
def __init__(self):
super(MyDef_linearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1) # 实例化一个线性对象(输入通道数,输出通道数) y^=x*w^T+b,参数w和b由优化器接管
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x)) # 求模型输出,
return y_pred
if __name__ == '__main__':
model_obj = MyDef_linearModel() # 实例化模型
bceloss_mean = torch.nn.BCELoss(reduction='mean') # 实例化一个损失计算器对象,计算一个batch中所有所有数据loss的BCE,的均值。
optimizer_obj = torch.optim.SGD(model_obj.parameters(), lr=0.01) # 实例化一个优化器,lr为学习率,即w = w - 0.01*w
for epoch in range(5000):
# ->输出计算
y_pred = model_obj(x_data)
# ->损失计算
loss_val = bceloss_mean(y_pred, y_data) # 求三个输出的bce的均值,bce为交叉熵的二分类写法
print("epoch=", epoch, "loss_val =", loss_val.item())
# ->梯度下降
optimizer_obj.zero_grad() # 使用优化器清空所有权重w中存储的梯度信息。
loss_val.backward() # 反向传播(计算l对w的导数,并存入w的grad参数中),注意反向传播只支持标量,mseloss_mean是个标量。
optimizer_obj.step() # 根据学习率进行更新权重w(梯度下降)。
print("w = ", model_obj.linear.weight.item())
print("b = ", model_obj.linear.bias.item())
print(type(x_data))
# 测试一下模型的结果
x_ = np.linspace(0, 10, 200) # 从0-10h之间取200个点(学习时间)
x_t = torch.Tensor(x_).view((200, 1)) # 把x_变成200行1列的矩阵
y_t = model_obj(x_t) # 把数据输入到模型,计算输出
y = y_t.data.numpy() # 把输出数据转换为numpy格式
plt.plot(x_, y)
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel("Hours")
plt.ylabel("P(class=1)") # 及格可能性
plt.grid()
plt.show()
# 模型可视化
writer = SummaryWriter("logs-cur") # 实例化一个可视化工具
writer.add_graph(model_obj, x_data) # 把模型载入可视化工具
writer.close() # 关闭可视化工具
# 其它:深度学习的4个步骤:准备数据 => 设计模型 => 构建损失 => 训练循环3.6、多维特征输入
前面说到,pytorch中,线性部分的数学表达式时![]() ,这里的x为行向量,一行表示一个数据的多个特征,在batch中:x有几行就代表这个batch组有几个数据。如下图示:
,这里的x为行向量,一行表示一个数据的多个特征,在batch中:x有几行就代表这个batch组有几个数据。如下图示:

1个数据有8个特征,对应1个数的target,即输入维度是8,输出维度是1 => torch.nn.Linear(8, 1),in_features和out_features指的就是一个数据的维度,即一个数据包含几个特征(也是列数)。如果是torch.nn.Linear(8, 6),那么![]() 将是一个8*6的矩阵。以多为特征输入的二分类问题为例,示例代码如下:
将是一个8*6的矩阵。以多为特征输入的二分类问题为例,示例代码如下:
# -*- coding:utf-8 -*-
import torch
import numpy as np
xy = np.loadtxt("./diabetes.csv.gz", delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # :-1代表最后一列不要
y_data = torch.from_numpy(xy[:, [-1]]) # [-1]:取出来的是矩阵,-1:取出来的是向量(这里的向量可不是平时说的行向量与列向量,更像是个数组)
# 行向量与列向量只能以矩阵的形式才可以,否则不能参与矩阵运算
# 定义一个线性模型
class My_Model(torch.nn.Module):
def __init__(self):
super(My_Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) # 8维到6维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.linear2 = torch.nn.Linear(6, 4) # 6维到4维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.linear3 = torch.nn.Linear(4, 1) # 4维到1维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.sigmoid = torch.nn.Sigmoid() # 创建一个sigmoid函数(非线性激活函数不止这一个,可以使用不同的激活函数测试哪个效果最好)
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
if __name__ == '__main__':
model_obj = My_Model() # 实例化模型
bceloss_mean = torch.nn.BCELoss(reduction='mean') # 计算一个batch中所有数据loss的平方差,的均值。
optimizer_obj = torch.optim.SGD(model_obj.parameters(), lr=0.01) # 实例化一个优化器,lr为学习率,即w=w-0.01*w。
for epoch in range(20000): # 虽然这里使用是batch,但是只有一个batch,是把所有数据分到一个batch里面了,并没有分很多batch。
# Forward
y_pred = model_obj(x_data)
loss_val = bceloss_mean(y_pred, y_data) # 求输出的bce的均值,bce为交叉熵的二分类写法
if epoch % 1000 == 0:
print("epoch=", epoch, "loss_val =", loss_val.item())
# Backward
optimizer_obj.zero_grad() # 使用优化器清空所有权重w中存储的梯度信息。
loss_val.backward() # 反向传播(计算l对w的导数,并存入w的grad参数中),注意反向传播只支持标量,bceloss_mean,是个标量。
optimizer_obj.step() # 根据学习率进行更新权重w使梯度下降。
数据集下载地址:diabetes.csv.gz
3.7、数据集的加载
数据集的加载主要涉及到两个类,一个是抽象类Dataset:用于设置数据集的位置和格式等,(抽象类不能实例化,只能被继承);另一个是DataLoader:用于管理加载数据的方式,即对数据进行batch、shuffle等。以数据集diabetes.csv.gz为例,示例代码如下:
# -*- coding:utf-8 -*-
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# 定义一个线性模型
class My_Model(torch.nn.Module):
def __init__(self):
super(My_Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) # 8维到6维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.linear2 = torch.nn.Linear(6, 4) # 6维到4维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.linear3 = torch.nn.Linear(4, 1) # 4维到1维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.sigmoid = torch.nn.Sigmoid() # 创建一个sigmoid函数(非线性激活函数不止这一个,可以使用不同的激活函数测试哪个效果最好)
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
# 定义DiabetesDataset类
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # 行数,因为一行是一个数据
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, item):
return self.x_data[item], self.y_data[item]
def __len__(self):
return self.len
dataset = DiabetesDataset("./diabetes.csv.gz")
train_dataloader = DataLoader(dataset=dataset, # 数据集
batch_size=32, # 一个batch包含32个数据集
shuffle=True, # 每轮训前打乱一次数据顺序(重新洗牌也是稍微耗时的)
num_workers=0) # 使用主进程进行加载数据(CPU不好的设置了速度反而会慢)
model_obj = My_Model() # 模型
bceloss_mean = torch.nn.BCELoss(reduction='mean') # 损失函数
optimizer_obj = torch.optim.SGD(model_obj.parameters(), lr=0.01) # 优化器
if __name__ == '__main__':
for epoch in range(20000):
print("epoch=", epoch)
for i, data in enumerate(train_dataloader, 0): # i从0开始,遍历每个batch
inputs, labels = data
y_pred = model_obj(inputs)
loss_val = bceloss_mean(y_pred, labels) # 求输出的bce的均值,bce为交叉熵的二分类写法
if epoch % 500 == 0:
print("i=", i, "loss_val =", loss_val.item())
# Backward
optimizer_obj.zero_grad() # 使用优化器清空所有权重w中存储的梯度信息。
loss_val.backward() # 反向传播(计算l对w的导数,并存入w的grad参数中),注意反向传播只支持标量,bceloss_mean,是个标量。
optimizer_obj.step() # 根据学习率进行更新权重w使梯度下降。3.8、多分类的问题
前面的二分类问题使用的是sigmoid函数,此函数会把输出映射到0-1,这样就能把输出映射成概率,因为只有2个类别,所以求一个类别的概率就行了。但是对于多分类问题,输出不在是一个值,而是多个值,如果把这多个值都用sigmoid,虽然每一个都构成了概率,但是他们和并不一定是1,不满足分布问题。所以多分类问题选用新的非线性激活函数softmax():

损失用交叉熵来求(注意交叉熵损失包含softmax()函数,故模型中就不要使用了):

全连接的神经网络一个示例如下:

# -*- coding:utf-8 -*-
import torch
from torchvision import transforms # 数据转换
from torchvision import datasets # 数据设置
from torch.utils.data import DataLoader # 数据加载
import torch.nn.functional as F # 函数导入
from torch.utils.tensorboard import SummaryWriter # 可视化工具
batch_size = 64
transforms_obj = transforms.Compose([transforms.ToTensor(), # 转换成tensor
transforms.Normalize((0.1307, ), (0.3081, ))]) # 数据标准化(均值:0.1307,标准差:0.3081)
train_dataset = datasets.MNIST(root="./dataset", train=True, download=True, transform=transforms_obj)
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size, num_workers=0)
test_dataset = datasets.MNIST(root="./dataset", train=False, download=True, transform=transforms_obj)
test_loader = DataLoader(dataset=train_dataset, shuffle=False, batch_size=batch_size, num_workers=0)
# 定义一个模型(全连接的网络)、全连接的输入shape需是(batch_size, 数据维度)
class My_Model(torch.nn.Module):
def __init__(self):
super(My_Model, self).__init__()
self.linear1 = torch.nn.Linear(784, 512) # 748维到512维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.linear2 = torch.nn.Linear(512, 256) # 512维到256维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.linear3 = torch.nn.Linear(256, 128) # 256维到128维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.linear4 = torch.nn.Linear(128, 64) # 128维到64维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
self.linear5 = torch.nn.Linear(64, 10) # 64维到10维,维度的减少也是一个数据特征的减小,可理解为对多特征总结后的结果
def forward(self, x):
x = x.view(-1, 784) # shape = 64,784
# x = torch.reshape(x, (-1, 784))
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = F.relu(self.linear3(x))
x = F.relu(self.linear4(x))
return self.linear5(x) # shape = 64,10
if __name__ == '__main__':
model_obj = My_Model()
summary_obj = SummaryWriter("./logs-cur")
loss_obj = torch.nn.CrossEntropyLoss(reduction='mean') # 交叉熵的损失计算器
optimizer = torch.optim.SGD(model_obj.parameters(), lr=0.01, momentum=0.5) # 实例化一个优化器
for epoch in range(25):
# ->训练部分
running_loss = 0.0 # 每200个batch的loss累加,并打印
model_obj.train() # 把网络中层设置为训练模式
for batch_idx, datas in enumerate(train_loader, 0):
inputs, labels = datas
optimizer.zero_grad()
# Forward:前向
outputs = model_obj(inputs)
loss_val = loss_obj(outputs, labels)
# Backward:反向
loss_val.backward()
# Update:更新
optimizer.step()
running_loss += loss_val.item()
if batch_idx % 200 == 199: # 每200个batch输出一次累加和
print("[epoch = %d, %5d] loss = %.3f" % (epoch + 1, batch_idx + 1, running_loss/200))
running_loss = 0.0
# ->测试部分
model_obj.eval() # 把网络中层设置为测试模式
with torch.no_grad():
total_num = 0 # 多少数据
correct_num = 0 # 正确了多少
test_loss_sum = 0.0 # 损失值的和
for batch_idx_t, datas_t in enumerate(test_loader, 0):
inputs_t, labels_t = datas_t
outputs_t = model_obj(inputs_t)
# 统计测试数据总数
total_num += labels_t.size(0)
# 统计测试中预测正确数据的个数
_, predicted = torch.max(outputs_t, dim=1)
correct_num += (predicted == labels_t).sum().item()
# 统计所有batch的总loss
loss_val_t = loss_obj(outputs_t, labels_t)
test_loss_sum += loss_val_t
print("total_num:%d,correct_num:%d,correct_percent:%.2f %%,test_loss_sum=%.3f" % (total_num, correct_num, 100*correct_num/total_num, test_loss_sum))训练20轮后,测试集就能达到百分之98%准确率,总loss约12.00左右:

总结:可以看出,全连接层(原始数据展开后)也可提取特征信息, 其每个像素之间都有联系,提取的是最原始的特征信息。缺点是全连接把数据展开后,数据丧失了原有空间结构,比如第一行的第5个像素和第二行的第五个像素是挨边的,但展开后,"挨边"的这个信息就丧失了(空间结构改变)。所以卷积神经网络CNN出现了,因为卷积提取的特征,很好的保留了图像的空间结构信息,故CNN广泛应用于图像(CV)领域。
关于训练集与测试集,网络从训练集中学习信息,可以记住训练集中的信息,但是测试网络时,输入的信息不能是训练集中的数据,因为网络使用时,不是从训练集中取出的数据,而是新的信息(测试集),所以准确率不可能达到百分之百(不能用训练集测试准确率)。关于过拟合:网络只认识训练集中的数据,不认识训练集外的数据。
3.9、卷积神经网络(CNN)
3.9.1、卷积操作
如图所示,一个3通道的图片,每个通道都需要1个蒙版,3个蒙版构成一个3通道的卷积核(核也是有通道数的),故可知,一个n通道的图片,它的卷积核必须也是n通道的,最后输出一个1通道的图片。

如果想生成多通道,只需怎加卷积核就行了,如图示:

# -*- coding:utf-8 -*-
import torch
in_channels, out_channels = 5, 10
im_width, im_height = 100, 100
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size,
in_channels, # 输入数据的通道数
im_width, # 输入数据的宽度
im_height) # 输入数据的高度
# 实例化一个2d卷积层
conv_layer = torch.nn.Conv2d(in_channels, # 核的通道数 = 输入数据通道数
out_channels, # 核的数量 = 输出数据的通道数
kernel_size=kernel_size) # 核的尺寸 = 自定义
output = conv_layer(input)
if __name__ == '__main__':
print("input.shape =", input.shape) # 输入数据的尺寸、1个->5通道,100*100的数据
print("conv_layer.weight.shape =", conv_layer.weight.shape) # 卷积核的尺寸、、10个>5通道3*3的卷积核
print("output.shape =", output.shape) # 输出数据的尺寸、1个->10通道,98*98的数据
# =>输出结果..............................................................................
# input.shape = torch.Size([1, 5, 100, 100])
# conv_layer.weight.shape = torch.Size([10, 5, 3, 3])
# output.shape = torch.Size([1, 10, 98, 98])从输出结果可以看出,输出数据的图像宽度和高度减小了2,这是卷积导致的,如果你想让卷积前后图像的宽度和高度不变,可以设置边缘补零(padding)。如果你想改变卷积核移动的步长,可以设置步长(stride)。示例如下:

# -*- coding:utf-8 -*-
import torch
inputs = [3, 4, 6, 5, 7,
2, 4, 6, 8, 2,
1, 6, 7, 8, 4,
9, 7, 4, 6, 2,
3, 7, 5, 4, 1]
inputs = torch.Tensor(inputs).view(1, 1, 5, 5) # Batch_size、channel_num、width、height
# 定义一个卷积层
conv_layer = torch.nn.Conv2d(1, # 1个卷积核
1, # 单通道
kernel_size=3, # 3*3
padding=1, # 输入数据边缘补一圈零
bias=False) # 不加偏置
kernel = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8, 9]).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data # 把kernel赋值给卷积层
if __name__ == '__main__':
outputs = conv_layer(inputs)
print(outputs.shape)
print(outputs)
# =>输出结果..............................................................................
# torch.Size([1, 1, 5, 5])
# tensor([[[[ 91., 168., 224., 215., 127.],
# [114., 211., 295., 262., 149.],
# [192., 259., 282., 214., 122.],
# [194., 251., 253., 169., 86.],
# [ 96., 112., 110., 68., 31.]]]], grad_fn=) 3.9.2、池化操作
池化操作实际就是下采样,它没有权重的,我们最常用的就是最大池化和平均池化,池化操作只改变图像尺寸,不改变通道数。以最大池化(max pooling)为例,如图所示:

# -*- coding:utf-8 -*-
import torch
inputs = [3, 4, 5, 6,
2, 4, 6, 8,
1, 6, 7, 8,
9, 7, 4, 6]
inputs = torch.Tensor(inputs).view(1, 1, 4, 4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)
if __name__ == '__main__':
outputs = maxpooling_layer(inputs)
print(outputs.shape)
print(outputs)
3.9.3、CNN示例1
还是以MNIST数据集为例,使用如下网络:

示例代码如下,在3.8的基础上改一下模型即可:
# -*- coding:utf-8 -*-
import torch
from torchvision import transforms # 数据转换
from torchvision import datasets # 数据设置
from torch.utils.data import DataLoader # 数据加载
import torch.nn.functional as F # 激活函数
from torch.utils.tensorboard import SummaryWriter # 可视化工具
batch_size = 32
transforms_obj = transforms.Compose([transforms.ToTensor(), # 转换成tensor
transforms.Normalize((0.1307, ), (0.3081, ))]) # 数据标准化(均值:0.1307,标准差:0.3081)
train_dataset = datasets.MNIST(root="./dataset", train=True, download=False, transform=transforms_obj)
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size, num_workers=0)
test_dataset = datasets.MNIST(root="./dataset", train=False, download=False, transform=transforms_obj)
test_loader = DataLoader(dataset=test_dataset, shuffle=False, batch_size=batch_size, num_workers=0)
# 定义一个模型
class My_Model(torch.nn.Module):
def __init__(self):
super(My_Model, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5) # 卷积核通道数1=输入数据的通道数1,输出通道10=10个卷积核,核尺寸=5
self.conv2 = torch.nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.linear = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0) # 最后一个batch的尺寸可能不是设定的值,所以这里不使用外部的batch_size变量
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # flatten
x = self.linear(x)
return x
if __name__ == '__main__':
model_obj = My_Model()
summary_obj = SummaryWriter("./logs-cur")
loss_obj = torch.nn.CrossEntropyLoss(reduction='mean') # 交叉熵的损失计算器
optimizer = torch.optim.SGD(model_obj.parameters(), lr=0.01, momentum=0.5) # 实例化一个优化器
for epoch in range(30):
# ->训练部分
running_loss = 0.0 # 每200个batch的loss累加,并打印
model_obj.train() # 把网络中层设置为训练模式
for batch_idx, datas in enumerate(train_loader, 0):
inputs, labels = datas
optimizer.zero_grad()
# Forward:前向
outputs = model_obj(inputs)
loss_val = loss_obj(outputs, labels)
# Backward:反向
loss_val.backward()
# Update:更新
optimizer.step()
running_loss += loss_val.item()
if batch_idx % 200 == 199: # 每200个batch输出一次累加和
print("[epoch = %d, %5d] loss = %.3f" % (epoch + 1, batch_idx + 1, running_loss/200))
running_loss = 0.0
# ->测试部分
model_obj.eval() # 把网络中层设置为测试模式
with torch.no_grad():
total_num = 0 # 多少数据
correct_num = 0 # 正确了多少
test_loss_sum = 0.0 # 损失值的和
for batch_idx_t, datas_t in enumerate(test_loader, 0):
inputs_t, labels_t = datas_t
outputs_t = model_obj(inputs_t)
# 统计测试数据总数
total_num += labels_t.size(0)
# 统计测试中预测正确数据的个数
_, predicted = torch.max(outputs_t, dim=1)
correct_num += (predicted == labels_t).sum().item()
# 统计所有batch的总loss
loss_val_t = loss_obj(outputs_t, labels_t)
test_loss_sum += loss_val_t
print("total_num:%d,correct_num:%d,correct_percent:%.3f %%,test_loss_sum=%.3f" % (total_num, correct_num, 100*correct_num/total_num, test_loss_sum))训练结果如下,相对只是用线性的网络,准确率提升了百分之1。

如过想使用GPU版本,可以做如下设置:
# -*- coding:utf-8 -*-
import torch
from torchvision import transforms # 数据转换
from torchvision import datasets # 数据设置
from torch.utils.data import DataLoader # 数据加载
import torch.nn.functional as F # 激活函数
from torch.utils.tensorboard import SummaryWriter # 可视化工具
batch_size = 64
transforms_obj = transforms.Compose([transforms.ToTensor(), # 转换成tensor
transforms.Normalize((0.1307, ), (0.3081, ))]) # 数据标准化(均值:0.1307,标准差:0.3081)
train_dataset = datasets.MNIST(root="./dataset", train=True, download=False, transform=transforms_obj)
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size, num_workers=0)
test_dataset = datasets.MNIST(root="./dataset", train=False, download=False, transform=transforms_obj)
test_loader = DataLoader(dataset=test_dataset, shuffle=False, batch_size=batch_size, num_workers=0)
# 定义一个模型
class My_Model(torch.nn.Module):
def __init__(self):
super(My_Model, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5) # 卷积核通道数1=输入数据的通道数1,输出通道10=10个卷积核,核尺寸=5
self.conv2 = torch.nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.linear = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0) # 最后一个batch的尺寸可能不是设定的值,所以这里不使用外部的batch_size变量
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # flatten
x = self.linear(x)
return x
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 设置(1):选择设备
model_obj = My_Model()
model_obj.to(device) # 设置(2):模型->设备
summary_obj = SummaryWriter("./logs-cur")
loss_obj = torch.nn.CrossEntropyLoss(reduction='mean') # 交叉熵的损失计算器
loss_obj = loss_obj.to(device) # 设置(3):损失->设备
optimizer = torch.optim.SGD(model_obj.parameters(), lr=0.01, momentum=0.5) # 实例化一个优化器
for epoch in range(30):
# ->训练部分
running_loss = 0.0 # 每200个batch的loss累加,并打印
model_obj.train() # 把网络中层设置为训练模式
for batch_idx, datas in enumerate(train_loader, 0):
inputs, labels = datas
inputs, labels = inputs.to(device), labels.to(device) # 设置(4):训练数据->设备
optimizer.zero_grad()
# Forward:前向
outputs = model_obj(inputs)
loss_val = loss_obj(outputs, labels)
# Backward:反向
loss_val.backward()
# Update:更新
optimizer.step()
running_loss += loss_val.item()
if batch_idx % 200 == 199: # 每200个batch输出一次累加和
print("[epoch = %d, %5d] loss = %.3f" % (epoch + 1, batch_idx + 1, running_loss/200))
running_loss = 0.0
# ->测试部分
model_obj.eval() # 把网络中层设置为测试模式
with torch.no_grad():
total_num = 0 # 多少数据
correct_num = 0 # 正确了多少
test_loss_sum = 0.0 # 损失值的和
for batch_idx_t, datas_t in enumerate(test_loader, 0):
inputs_t, labels_t = datas_t
inputs_t, labels_t = inputs_t.to(device), labels_t.to(device) # 设置(5):测试数据->设备
outputs_t = model_obj(inputs_t)
# 统计测试数据总数
total_num += labels_t.size(0)
# 统计测试中预测正确数据的个数
_, predicted = torch.max(outputs_t, dim=1)
correct_num += (predicted == labels_t).sum().item()
# 统计所有batch的总loss
loss_val_t = loss_obj(outputs_t, labels_t)
test_loss_sum += loss_val_t
print("total_num:%d,correct_num:%d,correct_percent:%.3f %%,test_loss_sum=%.3f" % (total_num, correct_num, 100*correct_num/total_num, test_loss_sum))
3.9.4、CNN示例2
<例一>:这里介绍几种复杂一点网络,Inception(又称GoogLeNet),下图是一个使用Inception构建的网络,可以看出GoogLeNet核心就是这个Inception Module,它可以增加网络的宽度,增加了网络对尺度的适应性,不同的支路的感受野是不同的,所以有多尺度的信息在里面(需要注意的是Inception Module有V1=>V4几个版本演变,这里以V1为例):


# -*- coding:utf-8 -*-
import torch
from torch import nn
from torchvision import transforms # 数据转换
from torchvision import datasets # 数据设置
from torch.utils.data import DataLoader # 数据加载
import torch.nn.functional as F # 激活函数
from torch.utils.tensorboard import SummaryWriter # 可视化工具
batch_size = 64
transforms_obj = transforms.Compose([transforms.ToTensor(), # 转换成tensor
transforms.Normalize((0.1307, ), (0.3081, ))]) # 数据标准化(均值:0.1307,标准差:0.3081)
train_dataset = datasets.MNIST(root="./dataset", train=True, download=False, transform=transforms_obj)
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size, num_workers=0)
test_dataset = datasets.MNIST(root="./dataset", train=False, download=False, transform=transforms_obj)
test_loader = DataLoader(dataset=test_dataset, shuffle=False, batch_size=batch_size, num_workers=0)
# 实例化一个Inception Module(V1)
class InceptionModel(torch.nn.Module):
def __init__(self, in_channels):
super(InceptionModel, self).__init__()
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
def forward(self, x):
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
outputs = [branch_pool, branch1x1, branch5x5, branch3x3]
return torch.cat(outputs, dim=1) # dim=1:沿着第一个维度拼接,第一个维度是通道
# 定义一个模型(使用Inception Module)
class My_Model(torch.nn.Module):
def __init__(self):
super(My_Model, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5)
self.incep1 = InceptionModel(in_channels=10)
self.conv2 = torch.nn.Conv2d(in_channels=88, out_channels=20, kernel_size=5)
self.incep2 = InceptionModel(in_channels=20)
self.max_pool = torch.nn.MaxPool2d(2)
self.cur_line = torch.nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.max_pool(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.max_pool(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.cur_line(x)
return x
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 设置(1):选择设备
model_obj = My_Model()
model_obj.to(device) # 设置(2):模型->设备
summary_obj = SummaryWriter("./logs-cur")
loss_obj = torch.nn.CrossEntropyLoss(reduction='mean') # 交叉熵的损失计算器
loss_obj = loss_obj.to(device) # 设置(3):损失->设备
optimizer = torch.optim.SGD(model_obj.parameters(), lr=0.01, momentum=0.5) # 实例化一个优化器
for epoch in range(30):
# ->训练部分
running_loss = 0.0 # 每200个batch的loss累加,并打印
model_obj.train() # 把网络中层设置为训练模式
for batch_idx, datas in enumerate(train_loader, 0):
inputs, labels = datas
inputs, labels = inputs.to(device), labels.to(device) # 设置(4):训练数据->设备
optimizer.zero_grad()
# Forward:前向
outputs = model_obj(inputs)
loss_val = loss_obj(outputs, labels)
# Backward:反向
loss_val.backward()
# Update:更新
optimizer.step()
running_loss += loss_val.item()
if batch_idx % 200 == 199: # 每200个batch输出一次累加和
print("[epoch = %d, %5d] loss = %.3f" % (epoch + 1, batch_idx + 1, running_loss/200))
running_loss = 0.0
# ->测试部分
model_obj.eval() # 把网络中层设置为测试模式
with torch.no_grad():
total_num = 0 # 多少数据
correct_num = 0 # 正确了多少
test_loss_sum = 0.0 # 损失值的和
for batch_idx_t, datas_t in enumerate(test_loader, 0):
inputs_t, labels_t = datas_t
inputs_t, labels_t = inputs_t.to(device), labels_t.to(device) # 设置(5):测试数据->设备
outputs_t = model_obj(inputs_t)
# 统计测试数据总数
total_num += labels_t.size(0)
# 统计测试中预测正确数据的个数
_, predicted = torch.max(outputs_t, dim=1)
correct_num += (predicted == labels_t).sum().item()
# 统计所有batch的总loss
loss_val_t = loss_obj(outputs_t, labels_t)
test_loss_sum += loss_val_t
print("total_num:%d,correct_num:%d,correct_percent:%.3f %%,test_loss_sum=%.3f" % (total_num, correct_num, 100*correct_num/total_num, test_loss_sum))

<例二>:Residual Network,名为残差网络。引言:在一定范围内随着神经网络随着层数增加可以更明确的学习出不同的特征从而提升网络性能。但是由于具体实现时其他问题的干扰导致普通的神经网络在增加层数到一定数量后再进行这样的操作反而会导致性能下降,如下图所示:

导致上述问题其中一个主要的原因就是“梯度消失与梯度爆炸”,梯度消失:当前向传播的梯度绝对值小于1时,经过多层传播,其指数性接近于零,导致网络靠前的网络层无法获取传播信息。导致此问题的原因主要有两个:一个是不恰当的选择“激活函数”(如sigmoid等,其在大部分区域梯度接近于0,选择类似“relu”函数等可以有效解决此问题),另一个就是网络过深,在梯度绝对值小于1时,经过多层传播那么其指数性接近于零。梯度爆炸:同样由于网络过深当网络较深层梯度绝对值大于1,那么在经过多层传播后可能出现指数增长从而超过计算机的表达范围出现训练问题导致系统性能的下降。此问题不是此处残差网络要解决的问题,解决此问题的是如“BatchNorlization”等等类似的方法。Residual Network可以很好的解决梯度消失问题,如下图所示:


还是以MNIST为例,使用一个残差网络示例,如下图所示:


# -*- coding:utf-8 -*-
import torch
from torch import nn
from torchvision import transforms # 数据转换
from torchvision import datasets # 数据设置
from torch.utils.data import DataLoader # 数据加载
import torch.nn.functional as F # 激活函数
from torch.utils.tensorboard import SummaryWriter # 可视化工具
batch_size = 64
transforms_obj = transforms.Compose([transforms.ToTensor(), # 转换成tensor
transforms.Normalize((0.1307, ), (0.3081, ))]) # 数据标准化(均值:0.1307,标准差:0.3081)
train_dataset = datasets.MNIST(root="./dataset", train=True, download=False, transform=transforms_obj)
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size, num_workers=0)
test_dataset = datasets.MNIST(root="./dataset", train=False, download=False, transform=transforms_obj)
test_loader = DataLoader(dataset=test_dataset, shuffle=False, batch_size=batch_size, num_workers=0)
# 实例化一个Inception Module(V1)
class ResidualBloock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBloock, self).__init__()
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
# 定义一个模型(使用Inception Module)
class My_Model(torch.nn.Module):
def __init__(self):
super(My_Model, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5)
self.conv2 = torch.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5)
self.max_pool = torch.nn.MaxPool2d(2)
self.resblock1 = ResidualBloock(16)
self.resblock2 = ResidualBloock(32)
self.cur_line = torch.nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.max_pool(F.relu(self.conv1(x)))
x = self.resblock1(x)
x = self.max_pool(F.relu(self.conv2(x)))
x = self.resblock2(x)
x = x.view(in_size, -1)
x = self.cur_line(x)
return x
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 设置(1):选择设备
model_obj = My_Model()
model_obj.to(device) # 设置(2):模型->设备
summary_obj = SummaryWriter("./logs-cur")
loss_obj = torch.nn.CrossEntropyLoss(reduction='mean') # 交叉熵的损失计算器
loss_obj = loss_obj.to(device) # 设置(3):损失->设备
optimizer = torch.optim.SGD(model_obj.parameters(), lr=0.01, momentum=0.5) # 实例化一个优化器
for epoch in range(30):
# ->训练部分
running_loss = 0.0 # 每200个batch的loss累加,并打印
model_obj.train() # 把网络中层设置为训练模式
for batch_idx, datas in enumerate(train_loader, 0):
inputs, labels = datas
inputs, labels = inputs.to(device), labels.to(device) # 设置(4):训练数据->设备
optimizer.zero_grad()
# Forward:前向
outputs = model_obj(inputs)
loss_val = loss_obj(outputs, labels)
# Backward:反向
loss_val.backward()
# Update:更新
optimizer.step()
running_loss += loss_val.item()
if batch_idx % 200 == 199: # 每200个batch输出一次累加和
print("[epoch = %d, %5d] loss = %.3f" % (epoch + 1, batch_idx + 1, running_loss/200))
running_loss = 0.0
# ->测试部分
model_obj.eval() # 把网络中层设置为测试模式
with torch.no_grad():
total_num = 0 # 多少数据
correct_num = 0 # 正确了多少
test_loss_sum = 0.0 # 损失值的和
for batch_idx_t, datas_t in enumerate(test_loader, 0):
inputs_t, labels_t = datas_t
inputs_t, labels_t = inputs_t.to(device), labels_t.to(device) # 设置(5):测试数据->设备
outputs_t = model_obj(inputs_t)
# 统计测试数据总数
total_num += labels_t.size(0)
# 统计测试中预测正确数据的个数
_, predicted = torch.max(outputs_t, dim=1)
correct_num += (predicted == labels_t).sum().item()
# 统计所有batch的总loss
loss_val_t = loss_obj(outputs_t, labels_t)
test_loss_sum += loss_val_t
print("total_num:%d,correct_num:%d,correct_percent:%.3f %%,test_loss_sum=%.3f" % (total_num, correct_num, 100*correct_num/total_num, test_loss_sum))

和Inception一样,残差网络的形式也不止一种,例如下图所示的两种,具体提议参考相关论文:
<例三>:DenseNet,其主要思想是与其多次学习冗余的特征,特征复用是一种更好的特征提取方式。如下图所示,这里不做阐述,具体参考相关论文:

总结:卷积神经网络的模型还有很多,比如Vgg、U-net等,这里不在赘述,具体可参考相关论文
3.10、循环神经网络(RNN)
循环神经网络适用于有顺序的序列,例如: x1、x2、x3分别为第1天、第2天、第3天的天气信息,要你预测第4天的天气,你就不能打乱前3天的顺序。
3.10.1、Cell操作
Cell,也叫RNNCell,它是RNN的一部分,如上图所示,使用它比较灵活,但需要你自己写循环,示例代码如下:
# RNNcell示例:
# -*- coding:utf-8 -*-
import torch
batch_size = 2 # = 序列的个数
seq_len = 3 # = 序列的长度
input_size = 4 # = 序列中,每个数据的维度
hidden_size = 2 # rnn_cell的输出维度
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
# (seq,batch,featers)
dataset = torch.randn(seq_len, batch_size, input_size) # batch_size个数据,每3个为一个序列
hidden = torch.zeros(batch_size, hidden_size) # h0
if __name__ == '__main__':
print(dataset)
for idx, inputs in enumerate(dataset): # 2组序列,第一次循环取出两组序列首数据...
print('='*20, idx, '='*20)
print('input size:', inputs.shape)
print('inputs=:', inputs)
hidden = cell(inputs, hidden)
print('hidden size:', hidden.shape)
print(hidden)
3.10.2、RNN操作
RNN,它不用你书写循环,你只需要设置尺寸即可,而且每一层hidden都会输出。



# RNN示例
# -*- coding:utf-8 -*-
import torch
batch_size = 2 # 批量(几个序列并行)
seq_len = 3 # 序列维度(1个序列几个数据)
input_size = 4 # 1个数据的的特征数
hidden_size = 2 # 隐藏h的维度
num_layers = 1 # cell的层数
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
# (seqLen, batchSize, inputSize)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
if __name__ == '__main__':
outputs, hidden = cell(inputs, hidden)
print('outputs size = ', outputs.shape)
print('outputs = ', outputs)
print('hidden size = ', hidden.shape)
print('hidden = ', hidden)
一般,我们都喜欢把batch_size放前面,这样代码更清晰,Pytorch,提供了一个参数,如果你把batch_first置位,你就可以把batch_size放在首位,如下所示:

# -*- coding:utf-8 -*-
import torch
batch_size = 2 # 批量(几个序列并行)
seq_len = 3 # 序列维度(1个序列几个数据)
input_size = 4 # 1个数据的的特征数
hidden_size = 2 # 隐藏h的维度
num_layers = 1 # cell的层数
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
# (seqLen, batchSize, inputSize)
inputs = torch.randn(batch_size, seq_len, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
if __name__ == '__main__':
outputs, hidden = cell(inputs, hidden)
print('outputs size = ', outputs.shape)
print('outputs = ', outputs)
print('hidden size = ', hidden.shape)
print('hidden = ', hidden)3.10.3、RNN示例1



# -*- coding:utf-8 -*-
# ======基于RNNCell的程序======
# 'h'->0、'e'->1、'l'->2、'o'->3
import torch
input_size = 4
hidden_size = 4
batch_size = 1
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3] # inputs
y_data = [3, 1, 2, 3, 2] # labels
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
# =>定义模型
class My_Model(torch.nn.Module):
def __init__(self, inputSize, hiddenSize, batchSize):
super(My_Model, self).__init__()
# self.num_layers = num_layers
self.batch_size = batchSize
self.input_size = inputSize
self.hidden_size = hiddenSize
self.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)
def forward(self, input_s, hidden):
hidden = self.rnncell(input_s, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
if __name__ == '__main__':
mode_obj = My_Model(input_size, hidden_size, batch_size)
ceLoss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(mode_obj.parameters(), lr=0.1)
for epoch in range(15):
loss_sum = 0
optimizer.zero_grad()
hidden = mode_obj.init_hidden() # hiddden = h0
print('Predicted string:', end='')
for input, label in zip(inputs, labels): # cell循环
hidden = mode_obj(input, hidden)
loss_sum += ceLoss(hidden, label)
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss_sum.backward()
optimizer.step()
print(',Epoch [%d/15] loss=%.4f' % (epoch+1, loss_sum.item()))# -*- coding:utf-8 -*-
# =========基于RNN的程序========
# 'h'->0、'e'->1、'l'->2、'o'->3
import torch
input_size = 4
hidden_size = 4
num_layers = 1
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3] # inputs
y_data = [3, 1, 2, 3, 2] # labels
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size) # 3维:(sqLen, batch_size, hidden_Size)
labels = torch.LongTensor(y_data) # 2维:((seqLen * batch_size) , 1)
# =>定义模型
class My_Model(torch.nn.Module):
def __init__(self, inputSize, hiddenSize, batchSize, numLayers=1):
super(My_Model, self).__init__()
self.num_layers = numLayers
self.batch_size = batchSize
self.input_size = inputSize
self.hidden_size = hiddenSize
self.rnn = torch.nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=self.num_layers)
def forward(self, input_s):
hidden_s = torch.zeros(self.num_layers, self.batch_size, self.hidden_size) # 构建h0: num_layers * batch_size * hidden_size
out, _ = self.rnn(input_s, hidden_s)
return out.view(-1, hidden_size) # 2维:((seqLen * batch_size), hidden_size)
if __name__ == '__main__':
mode_obj = My_Model(input_size, hidden_size, batch_size, num_layers)
ceLoss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(mode_obj.parameters(), lr=0.1)
for epoch in range(15):
optimizer.zero_grad()
outputs = mode_obj(inputs)
loss = ceLoss(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted:', ''.join([idx2char[x] for x in idx]), end='')
print(',Epoch [%d/15] loss=%.3f' % (epoch + 1, loss.item())) One-hot vectors(独热向量)编码虽然使用简便,但是编码的维度太高且需要自己编码,为了解决这个问题,可以使用Embedding(嵌入层)来解决这个问题,嵌入层的作用就是可以对数据进行编码,进而实现升降维的目的,为如下图所示:



# -*- coding:utf-8 -*-
# 'h'->0、'e'->1、'l'->2、'o'->3
import torch
# parameters
num_class = 4 # 类别是4
input_size = 4 # 数据维度是4
hidden_size = 8 # 输出8维
embedding_size = 10 # 嵌入到10维空间
num_layers = 2 # 2层RNN
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # inputs (batch, seq_len)
y_data = [3, 1, 2, 3, 2] # labels (batch * seq_len)
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
# =>定义模型
class My_Model(torch.nn.Module):
def __init__(self):
super(My_Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.linear = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.linear(x)
return x.view(-1, num_class)
if __name__ == '__main__':
mode_obj = My_Model()
ceLoss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(mode_obj.parameters(), lr=0.1)
for epoch in range(15):
optimizer.zero_grad()
outputs = mode_obj(inputs)
loss = ceLoss(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted:', ''.join([idx2char[x] for x in idx]), end='')
print(',Epoch [%d/15] loss=%.3f' % (epoch + 1, loss.item()))
3.10.4、RNN示例2

如图示,用RNN能解决这个问题,请参考哔哩哔哩上刘二大人的课程,课程PPT下载连接:Pytorch+深度学习(基础)+PPT
3.11、对抗神经网络(GAN)
3.11.1、Li-GAN网络
GAN全称为生成式对抗网络(如图4.1所示),其模型等同于博弈论中的二人零和博弈(有兴趣的可以读一下)。GAN有一个生成器和一个判别器,二者进行对抗,判别器用来区分数据来源于数据集还是生成器,实验想要的结果是判别器无法区分数据的来源。GAN开启了深度学习对图像编辑的大门。(GAN的目的:希望GEN生成器能学习到样本的真实分布)
Li-GAN:生成器和判别器两个模型都是使用全连接实现。(也是最简单的实现方式)

图4.1 GAN模型
 图4.2 GAN常用的激活函数
图4.2 GAN常用的激活函数
判别器和生成器仅仅使用全连接层的GAN示例如下:
拟合<一个高斯噪声的分布>到
# -*- coding:utf-8 -*-
import torch
import numpy as np
import torchvision
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
# 生成器的代码
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 28 * 28),
nn.Tanh() # =>数据值的范围映射到(-1, 1), GAN的判别器对输入数据的要求
)
def forward(self, x): # =>x:长度为100的噪声
img_o = self.main(x)
img_o = img_o.view(-1, 1, 28, 28)
return img_o
# 判别器代码
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.LeakyReLU(),
nn.Linear(512, 256),
nn.LeakyReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x): # =>x:图片
x = x.view(-1, 28 * 28)
x = self.main(x)
return x
if __name__ == '__main__':
device = 'cuda' if torch.cuda.is_available() else 'cpu'
test_inputs = torch.randn(16, 100, device=device) # 测试数据:torch.Size([16, 100])
summary_obj = SummaryWriter("./logs_gan") # 记录每轮的计算结果
# 1、数据准备
transform = transforms.Compose([
transforms.ToTensor(), # =>数据转换为tensor
transforms.Normalize(0.5, 0.5) # =>数据值的范围映射到(-1, 1), GAN的判别器对输入数据的要求
])
train_dis = torchvision.datasets.MNIST('.\\dataset', train=True, transform=transform, download=True)
dataloader = torch.utils.data.DataLoader(train_dis, batch_size=128, shuffle=True)
# 2、创建生成器(输入:长度为100的噪声,输出:1*28*28的图片)
gen_model = Generator().to(device)
gen_optim = torch.optim.Adam(gen_model.parameters(), lr=0.0001)
# 3、创建判别器(输入:长度为1*28*28的图片,输出:二分类的概率值)
dis_model = Discriminator().to(device)
dis_optim = torch.optim.Adam(dis_model.parameters(), lr=0.0001)
# 4、创建损失函数
loss_fn = torch.nn.BCELoss()
# 5、训练循环
for epoch in range(200):
dis_epoch_loss = 0
gen_epoch_loss = 0
count = len(dataloader)
for step, (img, _) in enumerate(dataloader):
img = img.to(device) # torch.Size([batchSize, 1, 28, 28]) => dis
size = img.size(0)
random_noise = torch.randn(size, 100, device=device) # torch.Size([batchSize, 100]) => gen => dis
# ==> 1、固定生成器,优化判别器
dis_optim.zero_grad()
# 计算判别器对真实图片的损失
real_output = dis_model(img) # 判别器对真实图片的输出
d_real_loss = loss_fn(real_output, torch.ones_like(real_output)) # dis在真实图像上的损失
d_real_loss.backward()
# 计算判别器对生成图片的损失
gen_img = gen_model(random_noise)
fake_output = dis_model(gen_img.detach()) # 截断生成器的梯度(即固定gen)
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output)) # dis在生成图像上的损失
d_fake_loss.backward()
# 优化器优化
dis_loss = d_real_loss + d_fake_loss
dis_optim.step() # 优化dis模型的参数
# ==> 2、固定判别器,优化生成器
gen_optim.zero_grad()
fake_output = dis_model(gen_img)
gen_loss = loss_fn(fake_output, torch.ones_like(fake_output))
gen_loss.backward()
gen_optim.step() # 优化gen模型的参数
with torch.no_grad():
dis_epoch_loss += dis_loss
gen_epoch_loss += gen_loss
with torch.no_grad():
dis_epoch_loss /= count
gen_epoch_loss /= count
print('Epoch:', epoch, ',dis:', dis_epoch_loss.item(), ',gen:', gen_epoch_loss.item())
# 参数可视化
summary_obj.add_scalar("dis_loss", dis_epoch_loss, epoch)
summary_obj.add_scalar("gen_loss", gen_epoch_loss, epoch)
summary_obj.add_images("gen_imgs", gen_model(test_inputs), epoch)
summary_obj.close()
# 在终端输入如下命令查看日志:<日志目录根据情况而定>
# tensorboard --logdir=".\\learning\\logs_gan" --host=127.0.0.1 --port=6007训练200轮的结果如下:


可见,生成器和判别器只使用全连接层能实现我们想要的目的,但效果并不是很好。
3.11.2、DC-GAN网络
DC-GAN:Deep Convolutional Generative Adversarial Networks(基于深度卷积生成对抗网络的无监督表示学习),实际上就是将判别器和生成器中的多层感知机制替换成卷积神经网络。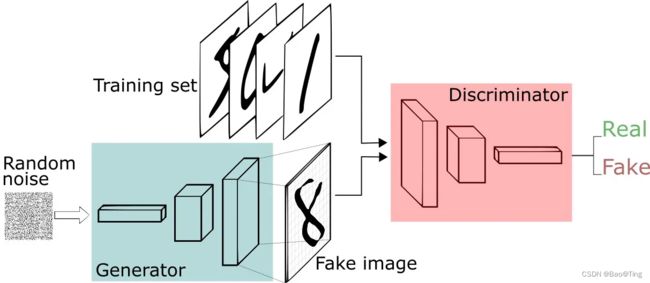
# -*- coding:utf-8 -*-
import os
import torch
import argparse
import numpy as np
import torchvision
from PIL import Image
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
# 生成器的代码
class Generator(nn.Module):
def __init__(self, nz_in, ng_in, ch_in):
self.nz = nz_in # 输入向量的大小
self.ng = ng_in # 生成器的中间通道数
self.ch = ch_in # 图像的通道数
super(Generator, self).__init__()
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d(self.nz, self.ng * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ng * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ng * 8, self.ng * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ng * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ng * 4, self.ng * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ng * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ng * 2, self.ng, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ng),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ng, self.ch, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, x): # =>x:长度为100的噪声
x = self.main(x)
return x # state size. (ngf) x 32 x 32
# 判别器代码
class Discriminator(nn.Module):
def __init__(self, nd_in, ch_in):
self.nd = nd_in # 判别器的中间通道数
self.ch = ch_in # 图像的通道数
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.ch, self.nd, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.nd, self.nd * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.nd * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.nd * 2, self.nd * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.nd * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.nd * 4, self.nd * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.nd * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(self.nd * 8, 1, 4, 1, 0, bias=False),
# state size. (1) x 1 x 1
nn.Sigmoid()
)
def forward(self, x): # =>x:图片
x = self.main(x)
return x
# 定义参数
parser = argparse.ArgumentParser()
parser.add_argument('--batchSize', type=int, default=64, help='批次大小')
# parser.add_argument('--imageSize', type=int, default=64, help='图像缩放尺寸')
parser.add_argument('--nz', type=int, default=100, help='输入向量大小')
parser.add_argument('--ng', type=int, default=32, help='生成器中间通道数')
parser.add_argument('--nd', type=int, default=32, help='鉴别器中间通道数')
parser.add_argument('--epoch', type=int, default=2, help='训练轮数')
parser.add_argument('--lr', type=float, default=0.0002, help='学习率')
parser.add_argument('--beta1', type=float, default=0.5, help='Adam b1')
parser.add_argument('--beta2', type=float, default=0.999, help='Adam b2')
opt = parser.parse_args()
if __name__ == '__main__':
device = 'cuda' if torch.cuda.is_available() else 'cpu'
test_inputs = torch.randn(64, opt.nz, 1, 1).to(device) # 测试数据:torch.Size([32, 100, 1, 1])
summary_obj = SummaryWriter("./logs_gan") # 记录每轮的计算结果
# 1、数据准备
transform = transforms.Compose([
transforms.Resize(64), # =>图片缩放
transforms.CenterCrop(64), # =>中心裁剪
transforms.ToTensor(), # =>数据转换为tensor
transforms.Normalize(0.5, 0.5) # =>数据值的范围映射到(-1, 1), GAN的判别器对输入数据的要求
])
train_dis = torchvision.datasets.MNIST('.\\dataset', train=True, transform=transform, download=True)
dataloader = torch.utils.data.DataLoader(train_dis, batch_size=opt.batchSize, shuffle=True)
# 2、创建生成器(输入:长度为100的噪声,输出:1*28*28的图片)
gen_model = Generator(opt.nz, opt.ng, 1)
if os.path.exists(".\\gen_model.pth"):
gen_model.load_state_dict(torch.load(".\\gen_model.pth"))
gen_model.to(device)
gen_optim = torch.optim.Adam(gen_model.parameters(), lr=opt.lr, betas=(opt.beta1, opt.beta2))
# 3、创建判别器(输入:长度为1*28*28的图片,输出:二分类的概率值)
dis_model = Discriminator(opt.ng, 1)
if os.path.exists(".\\dis_model.pth"):
dis_model.load_state_dict(torch.load(".\\dis_model.pth"))
dis_model.to(device)
dis_optim = torch.optim.Adam(dis_model.parameters(), lr=opt.lr, betas=(opt.beta1, opt.beta2))
# 4、创建损失函数
loss_fn = torch.nn.BCELoss()
# 5、训练循环
for epoch in range(opt.epoch):
dis_epoch_loss = 0
gen_epoch_loss = 0
count = len(dataloader)
for step, (img, _) in enumerate(dataloader):
if step == 0:
summary_obj.add_images("src_imgs", (img + 1.0) / 2.0, epoch)
img = img.to(device) # torch.Size([batchSize, 1, 64, 64]) => dis
size = img.size(0)
random_noise = torch.randn(size, opt.nz, 1, 1).to(device) # torch.Size([batchSize, 100, 1, 1]) => gen => dis
# ==> 1、固定生成器,优化判别器
dis_optim.zero_grad()
# 计算判别器对真实图片的损失
real_output = dis_model(img) # 判别器对真实图片的输出
d_real_loss = loss_fn(real_output, torch.ones_like(real_output)) # dis在真实图像上的损失
d_real_loss.backward()
# 计算判别器对生成图片的损失
gen_img = gen_model(random_noise)
fake_output = dis_model(gen_img.detach()) # 截断生成器的梯度(即固定gen)
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output)) # dis在生成图像上的损失
d_fake_loss.backward()
# 优化器优化
dis_loss = d_real_loss + d_fake_loss
dis_optim.step() # 优化dis模型的参数
# ==> 2、固定判别器,优化生成器
gen_optim.zero_grad()
fake_output = dis_model(gen_img)
gen_loss = loss_fn(fake_output, torch.ones_like(fake_output))
gen_loss.backward()
gen_optim.step() # 优化gen模型的参数
with torch.no_grad():
dis_epoch_loss += dis_loss
gen_epoch_loss += gen_loss
with torch.no_grad():
dis_epoch_loss /= count
gen_epoch_loss /= count
print('Epoch:', epoch, ',dis:', dis_epoch_loss.item(), ',gen:', gen_epoch_loss.item())
# 参数可视化
summary_obj.add_scalars("loss", {"dis_loss": dis_epoch_loss, "gen_loss": gen_epoch_loss}, global_step=epoch)
img_x = gen_model(test_inputs)
img_x = (img_x + 1.0)/2.0
summary_obj.add_images("gen_imgs", img_x, epoch)
# =>保存模型<= #
torch.save(dis_model.state_dict(), ".\\dis_model.pth")
torch.save(gen_model.state_dict(), ".\\gen_model.pth")
summary_obj.close()
# 在终端输入如下命令查看日志:<日志目录根据情况而定>
# tensorboard --logdir=".\\learning\\logs_gan" --host=127.0.0.1 --port=60073.11.3、C-GAN网络
前面两种无论是基于线性连接层的GAN还是基于卷积神经网络的GAN,都是输入一个噪声图生成一张真实的样本,但是你无法控制生成的图像内容(比如你不能确定输出的图像里的数字是几),而C-GAN(条件生成对抗网络)就可以解决这个问题。
基于MINIST数据集的手写数字生成的条件GAN代码如下:
# -*- coding:utf-8 -*-
import os
import torch
import argparse
import numpy as np
import torchvision
from PIL import Image
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
# 生成器的代码
class Generator(nn.Module):
def __init__(self, nz_in, ng_in, ch_in):
self.nz = nz_in # 输入向量的大小
self.ng = ng_in # 生成器的中间通道数
self.ch = ch_in # 图像的通道数
super(Generator, self).__init__()
self.linear1 = nn.Linear(10, self.nz)
self.bn1 = nn.BatchNorm1d(self.nz)
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d(self.nz * 2, self.ng * 8, 4, 1, 0, bias=False), #
nn.BatchNorm2d(self.ng * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ng * 8, self.ng * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ng * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ng * 4, self.ng * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ng * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ng * 2, self.ng, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ng),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ng, self.ch, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, img_in, label_in):
label_in = F.relu(self.linear1(label_in))
label_in = self.bn1(label_in)
label_in = label_in.view(-1, self.nz, 1, 1)
x = self.main(torch.cat([img_in, label_in], axis=1))
return x # state size. (nc) x 64 x 64
# 判别器代码
class Discriminator(nn.Module):
def __init__(self, nd_in, ch_in):
self.nd = nd_in # 判别器的中间通道数
self.ch = ch_in # 图像的通道数
super(Discriminator, self).__init__()
self.linear1 = nn.Linear(10, 1 * 64 * 64)
self.bn1 = nn.BatchNorm1d(1 * 64 * 64)
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.ch * 2, self.nd, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.nd, self.nd * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.nd * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.nd * 2, self.nd * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.nd * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.nd * 4, self.nd * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.nd * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(self.nd * 8, 1, 4, 1, 0, bias=False),
# state size. (1) x 1 x 1
nn.Sigmoid()
)
def forward(self, img_in, label_in): # =>x:图片 b * 1 * 64 *64
label_in = F.relu(self.linear1(label_in))
label_in = self.bn1(label_in)
label_in = label_in.view(-1, 1, 64, 64)
x = self.main(torch.cat([img_in, label_in], axis=1))
return x
# 定义参数
parser = argparse.ArgumentParser()
parser.add_argument('--batchSize', type=int, default=128, help='批次大小')
# parser.add_argument('--imageSize', type=int, default=64, help='图像缩放尺寸')
parser.add_argument('--nz', type=int, default=100, help='输入向量大小')
parser.add_argument('--ng', type=int, default=32, help='生成器中间通道数')
parser.add_argument('--nd', type=int, default=32, help='鉴别器中间通道数')
parser.add_argument('--epoch', type=int, default=10, help='训练轮数')
parser.add_argument('--lr', type=float, default=0.0002, help='学习率')
parser.add_argument('--beta1', type=float, default=0.5, help='Adam b1')
parser.add_argument('--beta2', type=float, default=0.999, help='Adam b2')
opt = parser.parse_args()
# 独热编码:输入x代表默认的torchvision返回的类比值,class_count类别值为10
def one_hot(x, class_count=10):
x = torch.eye(class_count)[x, :]
return x # 切片选取,第一维选取第x个,第二维全要
if __name__ == '__main__':
device = 'cuda' if torch.cuda.is_available() else 'cpu'
test_inputs = torch.randn(10, opt.nz, 1, 1).to(device) # 测试数据:torch.Size([32, 100, 1, 1])
test_labels = one_hot(torch.randint(0, 10, size=(test_inputs.size(0),))).to(device)
summary_obj = SummaryWriter("./logs_gan") # 记录每轮的计算结果
# 1、数据准备
transform = transforms.Compose([
transforms.Resize(64), # =>图片缩放
transforms.CenterCrop(64), # =>中心裁剪
transforms.ToTensor(), # =>数据转换为tensor
transforms.Normalize(0.5, 0.5) # =>数据值的范围映射到(-1, 1), GAN的判别器对输入数据的要求
])
train_dis = torchvision.datasets.MNIST('.\\dataset', train=True, transform=transform, target_transform=one_hot,
download=True)
dataloader = torch.utils.data.DataLoader(train_dis, batch_size=opt.batchSize, shuffle=True)
# 2、创建生成器(输入:长度为100的噪声,输出:1*28*28的图片)
if os.path.exists(".\\gen_model.pt"):
gen_model = torch.load(".\\gen_model.pt")
else:
gen_model = Generator(opt.nz, opt.ng, 1).to(device)
gen_optim = torch.optim.Adam(gen_model.parameters(), lr=opt.lr, betas=(opt.beta1, opt.beta2))
# 3、创建判别器(输入:长度为1*28*28的图片,输出:二分类的概率值)
if os.path.exists(".\\dis_model.pt"):
dis_model = torch.load(".\\dis_model.pt")
else:
dis_model = Discriminator(opt.ng, 1).to(device)
dis_optim = torch.optim.Adam(dis_model.parameters(), lr=opt.lr, betas=(opt.beta1, opt.beta2))
# 4、创建损失函数
loss_fn = torch.nn.BCELoss()
# 5、训练循环
for epoch in range(opt.epoch):
dis_epoch_loss = 0
gen_epoch_loss = 0
count = len(dataloader)
for step, (img, label) in enumerate(dataloader):
if step == 0:
summary_obj.add_images("src_imgs", (img + 1.0) / 2.0, epoch)
img = img.to(device) # torch.Size([batchSize, 1, 64, 64]) => dis
label = label.to(device)
size = img.size(0)
random_noise = torch.randn(size, opt.nz, 1, 1).to(device) # torch.Size([batchSize, 100, 1, 1]) => gen => dis
# ==> 1、固定生成器,优化判别器
dis_optim.zero_grad()
# 计算判别器对真实图片的损失
real_output = dis_model(img, label) # 判别器对真实图片的输出
d_real_loss = loss_fn(real_output, torch.ones_like(real_output)) # dis在真实图像上的损失
d_real_loss.backward()
# 计算判别器对生成图片的损失
gen_img = gen_model(random_noise, label)
fake_output = dis_model(gen_img.detach(), label) # 截断生成器的梯度(即固定gen)
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output)) # dis在生成图像上的损失
d_fake_loss.backward()
# 优化器优化
dis_loss = d_real_loss + d_fake_loss
dis_optim.step() # 优化dis模型的参数
# ==> 2、固定判别器,优化生成器
gen_optim.zero_grad()
fake_output = dis_model(gen_img, label)
gen_loss = loss_fn(fake_output, torch.ones_like(fake_output))
gen_loss.backward()
gen_optim.step() # 优化gen模型的参数(注意:虽然梯度传播到dis里了,但是没有执行dis的优化器,所以dis是固定的)
with torch.no_grad():
dis_epoch_loss += dis_loss
gen_epoch_loss += gen_loss
with torch.no_grad():
dis_epoch_loss /= count
gen_epoch_loss /= count
print('Epoch:', epoch, ',dis:', dis_epoch_loss.item(), ',gen:', gen_epoch_loss.item())
# 参数可视化
summary_obj.add_scalars("loss", {"dis_loss": dis_epoch_loss, "gen_loss": gen_epoch_loss}, global_step=epoch)
img_x = gen_model(test_inputs, test_labels)
img_x = (img_x + 1.0)/2.0
summary_obj.add_images("gen_imgs", img_x, epoch)
# =>保存模型<= #
print(test_labels)
torch.save(gen_model, ".\\gen_model.pt")
torch.save(dis_model, ".\\dis_model.pt")
summary_obj.close()
# 在终端输入如下命令查看日志:<日志目录根据情况而定>
# tensorboard --logdir=".\\learning\\logs_gan" --host=127.0.0.1 --port=6007
缺陷:cGAN生成的图像虽有很多缺陷,譬如图像边缘模糊,生成的图像分辨率太低等,但是它为后面的pix2pixGAN和CycleGAN开拓了道路,这两个模型转换图像风格时对属性特征的 处理方法均受cGAN启发。
3.11.4、Cycle-GAN网络
Cycle-GAN:Unpaired Image-toImage Translation using Cycle-Consistent Adversarial Networks(用循环一致的对抗神经网络实现非配对图像之间的转换)。

3.12、Diffusion Model
四、Pytorch 学习记录
4.1、tensorboard的使用
一、读取日志,会返回一个URL(如果URL的host不是127.0.0.1,可能访问不了,参考二)
tensorboard --logdir=logs # logs为在日志名称、此命令会返回一个IP(端口默认为6006),通过IP访问日志
二、设置日志的访问地址,即返回自己指定的URL(=>常用<=)
tensorboard --logdir=logs-cur --host=127.0.0.1 --port=6007 # logs为日志存放的文件夹的名称4.2、transforms的使用
# 示例:图片转tensor类型,tensor的归一化
# -*- coding:utf-8 -*-
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
if __name__ == '__main__':
writer = SummaryWriter("logs")
# Load image
img_PIL = Image.open("data/train/ants_image/6743948_2b8c096dda.jpg")
# 0、ToTsensor
trans_ToTensor_obj = transforms.ToTensor() # 定义一个ToTsensor转换器
img_tensor = trans_ToTensor_obj(img_PIL)
print("img_tensor.shape=", img_tensor.shape)
# 1、Normalize
trans_Normalize_obj = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_Normalize_obj(img_tensor)
print("img_norm.shape=", img_norm.shape)
# 2、Resize、缩放
trans_Resize_obj = transforms.Resize((512, 512))
img_resize = trans_Resize_obj(img_tensor)
print("img_resize.shape=", img_resize.shape)
# 3、Compose & resize、缩放
trans_Resize2_obj = transforms.Resize(512)
trans_Compose_obj = transforms.Compose([trans_ToTensor_obj, trans_Resize2_obj])
img_resize2 = trans_Compose_obj(img_PIL)
print("img_resize2.shape", img_resize2.shape)
# 4、Compose & RandomCrap、随机裁剪
trans_RandomCorp_obj = transforms.RandomCrop(300) # 值不要大于图片的尺寸
trans_Compose2_obj = transforms.Compose([trans_ToTensor_obj, trans_RandomCorp_obj])
for i in range(10):
img_randomcorp = trans_Compose2_obj(img_PIL)
writer.add_image("img_randomcorp", img_randomcorp, i) # writer - add_image
# Tensorboard add
writer.add_image("img_tensor", img_tensor, 0) # writer - add_image
writer.add_image("img_norm", img_tensor, 0) # writer - add_image
writer.add_image("img_resize", img_resize, 0) # writer - add_image
writer.add_image("img_resize2", img_resize2, 0) # writer - add_image
writer.close() # writer.close() (重点)
# End Of Program
print("over!!!")
4.3、官方数据集的基本使用
# 示例一:下载数据集(建议用迅雷下载)
# -*- coding:utf-8 -*-
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
if __name__ == '__main__':
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)
print("over!!!")# 示例二:以CIFAR10数据集的基本使用为例
# -*- coding:utf-8 -*-
from torch.utils.tensorboard import SummaryWriter
import torchvision
if __name__ == '__main__':
writer = SummaryWriter("logs-P10")
# 定义一个联合的transforms
dataset_transform_obj = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 导入数据集
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform_obj, download=False)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform_obj, download=True)
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
print("over!!!")4.4、dataset
设置数据集的地址,尺寸等信息。
4.5、dataloader
把数据加载到网络中,至于如何加载,类有很多加载方式可选。
# -*- coding:utf-8 -*-
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
if __name__ == '__main__':
writer = SummaryWriter("logs-P10")
# 准备测试的数据集
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,
batch_size=64, # 每64个打包在一起,注意采样器是随机的
shuffle=True, # 遍历一轮test_loader后,是否要重新排序(也叫洗牌)
num_workers=0,
drop_last=False) # 最后一组不满足64个时,是否舍去
img, target = test_data[0]
print(img.shape)
print(target)
step = 0
for data in test_loader:
imgs, targets = data # imgs后续将作为神经网络的输入
writer.add_images("test_data", imgs, step)
step = step+1
writer.close()
print("over!!!")4.6、基本卷积函数
# 示例:基本的卷积函数
# -*- coding:utf-8 -*-
import torch
import torch.nn.functional as F
if __name__ == '__main__':
inputx = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print("(1)inputx.shape=", inputx.shape)
print("(2)kernel.shape=", kernel.shape)
inputx = torch.reshape(inputx, (1, 1, 5, 5)) # (batch_size=1、channel=1、5x5矩阵)(pytorch常用数据格式)
kernel = torch.reshape(kernel, (1, 1, 3, 3)) # (batch_size=1、channel=1、3x3矩阵)(pytorch常用数据格式)
print("(3)inputx.shape=", inputx.shape)
print("(4)kernel.shape=", kernel.shape)
out1 = F.conv2d(inputx, kernel, stride=1) # 步长=1,无边缘填充
out2 = F.conv2d(inputx, kernel, stride=2) # 步长=2,无边缘填充
out3 = F.conv2d(inputx, kernel, stride=1, padding=1) # 步长=1,边缘填充一层0
print("out1=", out1)
print("(5)out1.shape=", out1.shape)
print("out2=", out2)
print("(6)out2.shape=", out2.shape)
print("out2=", out3)
print("(7)out3.shape=", out3.shape)
# 说明:程序中的把矩阵reshape成(1, 1, 5, 5)的数据格式,是因为通常数据都是按组(batch_size)
# 输入到神经网络,而且往往是多通道的,所以最常用(batch_size,channel,row,col)的数据格式
4.7、卷积层的使用
# 示例:卷积层类的使用
# -*- coding:utf-8 -*-
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 实例化一个2d卷积层
self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数=3
out_channels=6, # 输出通道数=6
kernel_size=3, # 卷积核尺寸=3
stride=1, # 步长=1
padding=0) # 边缘不处理
def forward(self, x): # 对传入的参数x进行卷积
ret = self.conv1(x)
return ret
if __name__ == '__main__':
writer = SummaryWriter("logs-P10")
dataset = torchvision.datasets.CIFAR10(root="./dataset",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
m_obj = MyModel()
step = 0
for data in dataloader:
imgs, target = data
output = m_obj(imgs) # 对imgs进行卷积
writer.add_images("input", imgs, step)
writer.add_images("output", torch.reshape(output, (-1, 3, 30, 30)), step)
print("imgs.shape=", torch.reshape(output, (-1, 3, 30, 30)).shape)
print("imgs.shape=", imgs.shape)
print("output.shape=", output.shape)
writer.close()
print("over!!!")
# 说明:in_channels=1和out_channels=1时,生成1个卷积核对输入通道进行卷积,从而产生1个通道的输出
# in_channels=1和out_channels=2时,生成2个卷积核对输入通道进行卷积,从而产生2个通道的输出
# ......依此类推4.8、池化层的使用
# 前言:
# 最大池化也被称为降采样(降采样可以减小数据的尺寸)
# Ceil_model=True:保留不足的部分,Ceil_model=False:舍去不足的部分
# 示例程序如下:
# -*- coding:utf-8 -*-
import torch
from torch import nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.maxpool2d = nn.MaxPool2d(kernel_size=3, ceil_mode=True) # 实例化一个最大池化层
def forward(self, x):
ret = self.maxpool2d(x) # 对传入的参数x进行最大池化
return ret
if __name__ == '__main__':
inputx = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
inputx = torch.reshape(inputx, (-1, 1, 5, 5)) # bath_size,ch_num,width,height
print("inputx.shape=", inputx.shape)
m_obj = MyModel()
output = m_obj(inputx)
print("output,shape=", output.shape)
print("output=", output)
print("over!!!")4.9、非线性激活的使用
# 前言:
# 非线性激活其实就是图像的非线性变换
# 所谓非线性激活,就是让数据通过一个非线性函数进行处理(例如:小于零的数取零,大于零的取原值)
# 常用的非线性函数有ReLU、Sigmoid等,以Relu为例
# 示例程序如下:
# -*- coding:utf-8 -*-
import torch
from torch import nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.relu = nn.ReLU() # 实例化一个非线性激活函数
def forward(self, x):
ret = self.relu(x) # 对传入的参数x进行ReLu非线性激活
return ret
if __name__ == '__main__':
inputx = torch.tensor([[-1, -2],
[+2, +2]])
inputx = torch.reshape(inputx, (-1, 1, 2, 2))
print("inputx.shape=", inputx.shape)
m_obj = MyModel()
output = m_obj(inputx)
print("output,shape=", output.shape)
print("output=", output)
print("over!!!")
4.10、线性层的使用
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.linear = nn.Linear(196608, 10) # 实例化一个线形层(10意为十分类问题)
def forward(self, x):
ret = self.linear(x) # 对传入的参数x进行线性
return ret
if __name__ == '__main__':
dataset = torchvision.datasets.CIFAR10(root="./dataset",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
m_obj = MyModel()
step = 0
for data in dataloader:
imgs, target = data
# output = torch.reshape(imgs, (1, 1, 1, -1)) # 把当前矩阵展平
output = torch.flatten(imgs) # 把当前矩阵展平
output = m_obj(output)
print("output=", output)
break4.11、序列与网络模型

# -*- coding:utf-8 -*-
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
ret = self.model1(x)
return ret
if __name__ == '__main__':
writer = SummaryWriter("logs-P10")
m_obj = MyModel()
input_data = torch.ones((64, 3, 32, 32))
writer.add_graph(m_obj, input_data)
writer.close()
print("over!!!")4.12、损失函数的使用
# 示例1:损失函数L1Loss()与MSELoss()的使用
# -*- coding:utf-8 -*-
import torch
from torch import nn
if __name__ == '__main__':
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
outputs = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
outputs = torch.reshape(outputs, (1, 1, 1, 3))
loss_sum_obj = nn.L1Loss(reduction='sum') # 差的和
loss_mean_obj = nn.L1Loss(reduction='mean') # 差的和的平均
loss_mse_obj = nn.MSELoss() # 差的平方的均值(均方差)
result_sum = loss_sum_obj(inputs, outputs)
result_mean = loss_mean_obj(inputs, outputs)
result_mse = loss_mse_obj(inputs, outputs)
print("result_sum=", result_sum)
print("result_mean=", result_mean)
print("result_mse=", result_mse)
print('hello world')
# 示例2:计算交叉熵的损失函数
# 一个三分类问题,三类:人、狗、猫
# -*- coding:utf-8 -*-
import torch
from torch import nn
if __name__ == '__main__':
# 输入一张图片,输出的结果是:这张图是人的概率是0.1,是狗的概率是0.2,是猫的概率是0.3
cur_out = torch.tensor([0.1, 0.2, 0.3])
cur_out = torch.reshape(cur_out, (1, 3))
# 目标值,[0]代表命中人,[1]代表命中狗,[2]代表命中猫
target = torch.tensor([1])
# 创建交叉熵计算类
loss_cross_obj = nn.CrossEntropyLoss()
result_cross = loss_cross_obj(cur_out, target) # 计算损失函数
print("result_cross=", result_cross)
print('hello world')# 示例3:交叉熵在网络中的使用
# -*- coding:utf-8 -*-
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
ret = self.model1(x)
return ret
if __name__ == '__main__':
writer = SummaryWriter("logs-P10")
dataset = torchvision.datasets.CIFAR10(root="./dataset",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
m_obj = MyModel()
loss_obj = nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
outputs = m_obj(imgs)
result_loss = loss_obj(outputs, targets)
# print("outputs=", outputs)
# print("targets=", targets)
print("result_loss=", result_loss)
# break4.13、反向传播与基础训练
损失函数有一个反向传播函数,此函数会返回梯度数据,优化器可以根据梯度数据对神经网络中的核内部参数进行优化,从而使输出趋近目标值。(意为训练)
# -*- coding:utf-8 -*-
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
ret = self.model1(x)
return ret
if __name__ == '__main__':
# writer = SummaryWriter("logs-P10")
dataset = torchvision.datasets.CIFAR10(root="./dataset",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
model_obj = MyModel() # 实例化神经网络模型
loss_obj = nn.CrossEntropyLoss() # 实例化一个损失计算器
optim_obj = torch.optim.SGD(model_obj.parameters(), lr=0.01) # 实例化一个优化器
for epoch in range(40): # 训练40轮
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = model_obj(imgs)
result_loss = loss_obj(outputs, targets)
optim_obj.zero_grad() # 优化器梯度清零(上一次的梯度数据对这一次没有用)
result_loss.backward() # 反向传播梯度数据
optim_obj.step() # 根据传过来的梯度数据对网络中的参数进行调整
running_loss = running_loss + result_loss
print(running_loss)4.14、现有网络模型的使用及修改
# VGG网络模型的输出有1000种,其适用ImageNet数据集,但是由于ImageNet数据集有100多个G,
# 所以不支持在线下载,可以去网上去搜下载连接。在处理某些问题时,有些做法是先用VGG这种已有的
# 网络模型先处理,从而得到结果,然后再串自己的模型。也可以直接修改VGG中的某个节点来创建新的模型
# 总之,深度学习对于大多数学者是搭积木的,而这些已有的模型就是积木,这些都是后话,不能说所有人都搭积# 木,现实中还有少数特别牛的大神,是能用数学证明的,但不多吧!!!
# -*- coding:utf-8 -*-
import torchvision
from torch import nn
if __name__ == '__main__':
# train_data = torchvision.datasets.ImageNet("./data_image_net",
# split='train',
# download=True,
# transform=torchvision.transforms.ToTensor())
train_data = torchvision.datasets.CIFAR10(root="./dataset",
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
#dataloader = DataLoader(dataset, batch_size=64)
vgg16_true = torchvision.models.vgg16(pretrained=True) # 加载已训练的网络模型、需要下载
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10)) # 在现有的vgg16网络模型的classifier中加一个层
print("vgg16_true=", vgg16_true) # 打印添加后的
vgg16_false = torchvision.models.vgg16(pretrained=False) # 加载未训练的网络模型、不需要下载
vgg16_false.classifier[6] = nn.Linear(4096, 10) # 修改vgg16网络模型的classifier中层,层索引为6
print("vgg16_false=", vgg16_false) # 打印添加后的4.15、网络模型的保存与读取
# 方式一:
# -*- coding:utf-8 -*-
# 模型的保存有两种保存方式
import torch
import torchvision
if __name__ == '__main__':
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存网络模型
# 保存方式1,模型结构+模型参数
torch.save(vgg16, "./model_result/vgg16_method1.pth") # 保存网络模型的结构和参数
# 模型的加载
model = torch.load("./model_result/vgg16_method1.pth")
print(model) # 打印模型的结构(其实模型的参数也保存了可以调试查看)
print("over!!!")# 方式二:
# -*- coding:utf-8 -*-
# 模型的保存有两种保存方式
import torch
import torchvision
if __name__ == '__main__':
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式2,模型参数(官方推荐的保存方式)
torch.save(vgg16.state_dict(), "./model_result/vgg16_method2.pth") # 以字典的形式保存模型的参数(不保存结构)
# 模型参数加载
vgg16_x = torchvision.models.vgg16(pretrained=False) # 实例化一个模型
vgg16_x.load_state_dict(torch.load("./model_result/vgg16_method2.pth")) # 把模型参数导入到模型中
print(vgg16_x)
print("over!!!")注意:加载一个已保存的网络模型,使用前必须先import网络模型的定义(其实就是类的定义)
4.16、完整的网络模型套路(CPU)
# 示例1:最值的索引
import torch
if __name__ == '__main__':
outputs = torch.tensor([[0.1, 0.2],
[0.01, 0.4]])
print(outputs.argmax(0)) # 输出列的最大值的索引,例如第一列的最大值是0.1,0.1的索引是0
print(outputs.argmax(1)) # 输出行的最大值的索引,例如第一行的最大值是0.2,0.2的索引是1
# 示例2:最值的索引应用
import torch
if __name__ == '__main__':
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
preds = outputs.argmax(1)
print("preds:", preds)
target = torch.tensor([0, 1])
print("preds==target:", preds == target)
print("(preds==target.sum()):", (preds == target).sum())
# 说明:以二分类问题看上代码,输入一张图片,期望的网络输出1,可通过上面代码验证最大预测命中是不是1# 示例3:完整的训练框架(CPU)
# ---------------------------->mode.py<----------------------------
# -*- coding:utf-8 -*-
import torch
from torch import nn
# 定义一个网络模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
ret = self.model1(x)
return ret
if __name__ == '__main__':
# 检测网络模型中数据的尺寸的正确性
inputs = torch.ones((64, 3, 32, 32))
model_obj = MyModel()
outputs = model_obj(inputs)
print(outputs.shape)
print("over!!!")
# ---------------------------->train.py<----------------------------
# -*- coding:utf-8 -*-
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch.utils.data import DataLoader
# 主函数
if __name__ == '__main__':
train_data = torchvision.datasets.CIFAR10(root="./dataset", # 训练数据集
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", # 测试数据集
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
print("训练数据集的长度:{}".format(len(train_data))) # 50000张
print("测试数据集的长度:{}".format(len(test_data))) # 10000张
# 利用dataloader来加载数据集
train_dataloader = DataLoader(dataset=train_data, batch_size=64)
test_dataloader = DataLoader(dataset=test_data, batch_size=64)
# 实例化一个 tensorboard
summary_obj = SummaryWriter("./logs_AR10")
# 实例化一个网络模型
model_obj = MyModel()
# 实例化一个损失函数
loss_obj = nn.CrossEntropyLoss()
# 实例化一个优化器
learning_rate = 1e-2
optimizer_obj = torch.optim.SGD(model_obj.parameters(), lr=learning_rate)
# 设置网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
# 训练
for i in range(40):
total_train_step = 0
print("-----第{}轮测试开始了-----".format(i))
model_obj.train() # 把网络中层设置为训练模式(注意只对特定层有作用)
for data in train_dataloader: # 训练
imgs, targets = data
outputs = model_obj(imgs)
loss = loss_obj(outputs, targets)
# 优化器优化模型
optimizer_obj.zero_grad()
loss.backward()
optimizer_obj.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item())) # loss.item(),将loss转为普通数据类型
summary_obj.add_scalar("train_loss", loss.item(), total_train_step)
# 用测试数据集测试当前轮训练的结果
model_obj.eval() # # 把网络中层设置为测试模式(注意只对特定层有作用)
total_test_loss = 0 # 整体的损失
total_accuracy = 0 # 整体的测试和
with torch.no_grad(): # 设置不使用网络的梯度,因为梯度是优化器使用的,测试时是用不到优化器的
for data in test_dataloader: # 训练
imgs, targets = data
outputs = model_obj(imgs)
loss = loss_obj(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = ((outputs.argmax(1) == targets).sum())
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
summary_obj.add_scalar("test_loss", total_test_loss, total_test_step)
print("整体测试集上的正确率:{}".format(total_accuracy/len(test_data)))
summary_obj.add_scalar("test_accuracy", total_accuracy/len(test_data), total_test_step)
total_test_step = total_test_step + 1
torch.save(model_obj, "./model_result/mode_{}.pth".format(i)) # 注意:需要保证文件夹已经存在
print("模型已保存")
summary_obj.close()
4.17、完整的网络模型套路(GPU)
需要转到GPU上的部分:网络模型、数据(输入、标注)、损失函数、.to()/.cuda()
# 使用GPU加速,方式1
# -*- coding:utf-8 -*-
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 定义一个网络模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
ret = self.model1(x)
return ret
# 主函数
if __name__ == '__main__':
train_data = torchvision.datasets.CIFAR10(root="./dataset", # 训练数据集
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", # 测试数据集
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
print("训练数据集的长度:{}".format(len(train_data))) # 50000张
print("测试数据集的长度:{}".format(len(test_data))) # 10000张
# 利用dataloader来加载数据集
train_dataloader = DataLoader(dataset=train_data, batch_size=64)
test_dataloader = DataLoader(dataset=test_data, batch_size=64)
# 实例化一个 tensorboard
summary_obj = SummaryWriter("./logs_AR10")
# 实例化一个网络模型
model_obj = MyModel()
if torch.cuda.is_available(): # 把数据转移到GPU上(1)
model_obj = model_obj.cuda()
# 实例化一个损失函数
loss_obj = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_obj = loss_obj.cuda() # 把数据转移到GPU上(2)
# 实例化一个优化器
learning_rate = 1e-2
optimizer_obj = torch.optim.SGD(model_obj.parameters(), lr=learning_rate)
# 设置网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
# 训练
for i in range(60):
total_train_step = 0
print("-----第{}轮测试开始了-----".format(i))
model_obj.train() # 把网络中层设置为训练模式(注意只对特定层有作用)
for data in train_dataloader: # 训练
imgs, targets = data
if torch.cuda.is_available(): # 把数据转移到GPU上(3)
imgs = imgs.cuda()
targets = targets.cuda()
outputs = model_obj(imgs)
loss = loss_obj(outputs, targets)
# 优化器优化模型
optimizer_obj.zero_grad() # 梯度数据清零
loss.backward() # 反向传播(传递梯度数据给优化器)
optimizer_obj.step() # 根据传播来的梯度数据来优化网络
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item())) # loss.item(),将loss转为普通数据类型
summary_obj.add_scalar("train_loss", loss.item(), total_train_step)
# 用测试数据集测试当前轮训练的结果
model_obj.eval() # # 把网络中层设置为测试模式(注意只对特定层有作用)
total_test_loss = 0 # 整体的损失
total_accuracy = 0 # 整体的测试和
with torch.no_grad(): # 设置不使用网络的梯度,因为梯度是优化器使用的,测试时是用不到优化器的
for data in test_dataloader: # 训练
imgs, targets = data
if torch.cuda.is_available(): # 把数据转移到GPU上(4)
imgs = imgs.cuda()
targets = targets.cuda()
outputs = model_obj(imgs)
loss = loss_obj(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = ((outputs.argmax(1) == targets).sum())
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
summary_obj.add_scalar("test_loss", total_test_loss, total_test_step)
print("整体测试集上的正确率:{}".format(total_accuracy/len(test_data)))
summary_obj.add_scalar("test_accuracy", total_accuracy/len(test_data), total_test_step)
total_test_step = total_test_step + 1
torch.save(model_obj, "./model_result/mode_{}.pth".format(i)) # 注意:需要保证文件夹已经存在
print("模型已保存")
summary_obj.close()
# 使用GPU加速,方式2、此方式比较适用
# -*- coding:utf-8 -*-
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 定义一个网络模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
ret = self.model1(x)
return ret
# 主函数
if __name__ == '__main__':
train_data = torchvision.datasets.CIFAR10(root="./dataset", # 训练数据集
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", # 测试数据集
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
print("训练数据集的长度:{}".format(len(train_data))) # 50000张
print("测试数据集的长度:{}".format(len(test_data))) # 10000张
# 利用dataloader来加载数据集
train_dataloader = DataLoader(dataset=train_data, batch_size=64)
test_dataloader = DataLoader(dataset=test_data, batch_size=64)
# 定义训练的设备
# device = torch.device("cuda:0")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device=", device)
# 实例化一个 tensorboard
summary_obj = SummaryWriter("./logs_AR10")
# 实例化一个网络模型
model_obj = MyModel()
model_obj = model_obj.to(device) # 把模型转移到设备device上(1)
# 实例化一个损失函数
loss_obj = nn.CrossEntropyLoss()
loss_obj = loss_obj.to(device) # 把模型转移到设备device上(2)
# 实例化一个优化器
learning_rate = 1e-2
optimizer_obj = torch.optim.SGD(model_obj.parameters(), lr=learning_rate)
# 设置网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
# 训练
for i in range(60):
total_train_step = 0
print("-----第{}轮测试开始了-----".format(i))
model_obj.train() # 把网络中层设置为训练模式(注意只对特定层有作用)
for data in train_dataloader: # 训练
imgs, targets = data
imgs = imgs.to(device) # 把模型转移到设备device上(3)
targets = targets.to(device)
outputs = model_obj(imgs)
loss = loss_obj(outputs, targets)
# 优化器优化模型
optimizer_obj.zero_grad() # 梯度数据清零
loss.backward() # 反向传播(传递梯度数据给优化器)
optimizer_obj.step() # 根据传播来的梯度数据来优化网络
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item())) # loss.item(),将loss转为普通数据类型
summary_obj.add_scalar("train_loss", loss.item(), total_train_step)
# 用测试数据集测试当前轮训练的结果
model_obj.eval() # # 把网络中层设置为测试模式(注意只对特定层有作用)
total_test_loss = 0 # 整体的损失
total_accuracy = 0 # 整体的测试和
with torch.no_grad(): # 设置不使用网络的梯度,因为梯度是优化器使用的,测试时是用不到优化器的
for data in test_dataloader: # 训练
imgs, targets = data
imgs = imgs.to(device) # 把模型转移到设备device上(4)
targets = targets.to(device)
outputs = model_obj(imgs)
loss = loss_obj(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = ((outputs.argmax(1) == targets).sum())
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
summary_obj.add_scalar("test_loss", total_test_loss, total_test_step)
print("整体测试集上的正确率:{}".format(total_accuracy/len(test_data)))
summary_obj.add_scalar("test_accuracy", total_accuracy/len(test_data), total_test_step)
total_test_step = total_test_step + 1
torch.save(model_obj, "./model_result/mode_{}.pth".format(i)) # 注意:需要保证文件夹已经存在
print("模型已保存")
summary_obj.close()4.18、模型测试
说明:利用已经训练好的模型,给它提供输入,查看它的输出
# -*- coding:utf-8 -*-
import torch
import torchvision
from model import *
from PIL import Image
if __name__ == '__main__':
image_path = "./imgs/dog.jpg"
img = Image.open(image_path)
print(img.size)
transform_obj = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform_obj(img)
image = torch.reshape(image, (1, 3, 32, 32))
model_obj = torch.load("model_result/mode_39.pth")
model_obj.eval() # 测试模式
print(model_obj)
with torch.no_grad():
output = model_obj(image)
print(output)
print(output.argmax(1))
print('over')
4.19、========================
<1>pip 是最为广泛使用的Python包管理器,而conda是anaconda自带的Python 包管理器,建议之后以使用conda为主,pip为辅,因为conda的适用性更强。
conda -V:查看anaconda版本
conda activate base:进入base环境
conda activate py37:进入py37环境
python -V:查看当前环境的python版本
conda info -e:查看已创建的环境列表
conda env list:查看已创建的环境列表
###########################################################################################
conda create -n [env_name] python=X.X #创建python虚拟环境
conda remove -n [env_name] --all #删除python虚拟环境
###########################################################################################
conda install -n [env_name] package_name #在指定虚拟环境中安装某个包
conda remove --name [env_name] package_name #在指定虚拟环境中删除某个包
###########################################################################################
conda install [package-name] # 在当前环境安装名为[package-name]的包
conda install [package-name]=X.X # 在当前环境安装名为[package-name]的包并指定版本X.X
conda update [package-name] # 更新、当前环境下名为[package-name]的包
conda remove [package-name] # 删除、当前环境下名为[package-name]的包
conda list # 列出、当前环境下已安装的所有的packages
conda search [package-name] # 列出、名为[package-name]的包在conda源中的所有可用版本
###########################################################################################
# 在当前环境下安装pytorch的方式一(-c参数会使用默认conda源,需要去github下载dev-sidecar安装并启动)
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch
# 在当前环境下安装pytorch的方式二(去掉-c,则使用你自己配置好的conda源进行安装)
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch
# 验证pytorch是否安装成功
import torch
torch.cuda.is_available()
###########################################################################################
五、YOLO_V7 => Pytorch代码的运行
机器视觉能解决的问题:图像分类、目标检测、图像分割(语义分割、实例分割)
