window10+paddleseg+C++部署
部署环境:VS2019+cuda10.2+cmake3.17.0
v2.0.0参考 兼容并包的PaddleX-Inference部署方式
按照官方步骤基于PaddleInference的推理-Windows环境编译下载paddleX和cuda10.2版本的paddle_inference.zip,将PaddleX中的cpp拷贝出来并新建build_out文件夹

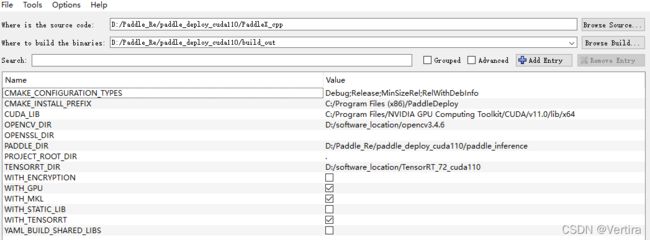
将cpp文件夹下的cmakeList.txt修改为下图,仅对下图中的几行进行修改,其它不变:

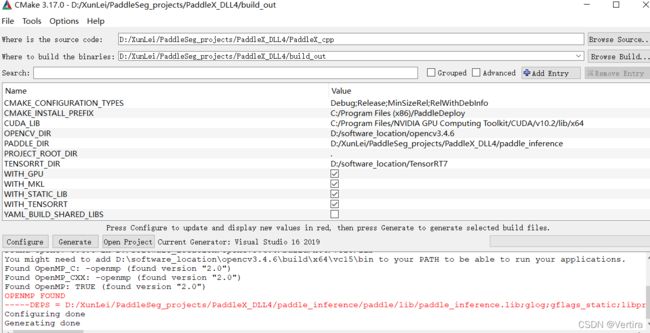
完全按照下图选择进行cmake,不能多也不能少,不然会有麻烦
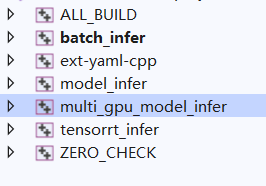
open Project可以看到如下几项
将其中的model_infer.cpp更改如下:
// Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include
#include
#include
#include
#include
#include "model_deploy/common/include/paddle_deploy.h"
using namespace cv;
using namespace std;
//DEFINE_string(model_filename, "", "Path of det inference model");
//DEFINE_string(params_filename, "", "Path of det inference params");
//DEFINE_string(cfg_file, "", "Path of yaml file");
//DEFINE_string(model_type, "", "model type");
//DEFINE_string(image, "", "Path of test image file");
//DEFINE_bool(use_gpu, false, "Infering with GPU or CPU");
//DEFINE_int32(gpu_id, 0, "GPU card id");
// 这里的struct是为了在自己的项目中接收推理结果,因为推理结果是
//vector类型,我们自己的项目中没有
struct result_local
{
std::vector data;
// the shape of mask
std::vector score;
};
//为了导出dll。
#define DLLEXPORT extern "C" _declspec(dllexport)
string model_type = "seg";
PaddleDeploy::Model* model;
//设置接口
DLLEXPORT void Init(string model_filename, string cfg_file, string params_filename, int gpu_id)
{
// create model
model = PaddleDeploy::CreateModel(model_type);
// model init
model->Init(cfg_file);
// inference engine init
PaddleDeploy::PaddleEngineConfig engine_config;
engine_config.model_filename = model_filename;
engine_config.params_filename = params_filename;
engine_config.use_gpu = true;
engine_config.gpu_id = gpu_id;
model->PaddleEngineInit(engine_config);
}
DLLEXPORT void Predict(vector imgs, vector& results_back)
{
cout << "enter Predict imgs.size(): " << imgs.size() << endl;
vector imgs_local;
if (imgs.size() == 0)
{
cout << "nothing pic in";
}
for (int i = 0; i < imgs.size(); i++)
{
imgs_local.push_back(std::move(imgs[i]));
}
// predict
std::vector results;
model->Predict(imgs_local, &results, 1);
for (int i = 0; i < results.size(); i++)
{
result_local temp;
vector data = results[i].seg_result->label_map.data;
vector score = results[i].seg_result->score_map.data;
temp.data = data;
temp.score = score;
results_back.push_back(temp);
}
}
//int main(int argc, char** argv) {
// // Parsing command-line
// google::ParseCommandLineFlags(&argc, &argv, true);
//
// // create model
// PaddleDeploy::Model* model = PaddleDeploy::CreateModel(FLAGS_model_type);
//
// // model init
// model->Init(FLAGS_cfg_file);
//
// // inference engine init
// PaddleDeploy::PaddleEngineConfig engine_config;
// engine_config.model_filename = FLAGS_model_filename;
// engine_config.params_filename = FLAGS_params_filename;
// engine_config.use_gpu = FLAGS_use_gpu;
// engine_config.gpu_id = FLAGS_gpu_id;
// model->PaddleEngineInit(engine_config);
//
// // prepare data
// std::vector imgs;
// imgs.push_back(std::move(cv::imread(FLAGS_image)));
//
// // predict
// std::vector results;
// model->Predict(imgs, &results, 1);
//
// std::cout << results[0] << std::endl;
// delete model;
// return 0;
//} 然后选择model_infer右键设为启动项,点击生成

在VS中新建项目
#include
#include
#include
using namespace std;
using namespace cv;
struct result_now
{
std::vector data;
// the shape of mask
std::vector score;
};
typedef void(*ptrSub_Init)(string model_filename, string cfg_file, string params_filename, int gpu_id);
typedef void(*ptrSub_predict)(vector imgs, vector& results_back);
HMODULE hMod = LoadLibrary("model_infer.dll");
typedef void(*ptrSub_batch_Init)(string model_filename, string cfg_file, string params_filename, int gpu_id,bool use_trt);
typedef void(*ptrSub_batch_predict)(std::vector image_paths, vector& results_back, int batch_size);
HMODULE hMod_batch = LoadLibrary("batch_infer.dll");
//这部分是用于接收model_infer的结果
void normal_infer()
{
string imgs_path = "D:/VS_projects/test/";
string cfg_file = "D:/PaddleSeg_projects/PaddleX_DLL/test/deploy.yaml";
string params_filename = "D:/PaddleSeg_projects/PaddleX_DLL/test/model.pdiparams";
string model_filename = "D:/PaddleSeg_projects/PaddleX_DLL/test/model.pdmodel";
vector img_names;
glob(imgs_path, img_names);
vector imgs;
for (int i = 0; i < img_names.size(); i++)
{
Mat img = imread(img_names[i]);
imgs.push_back(img);
}
vector results;
if (hMod != NULL)
{
ptrSub_Init Init = (ptrSub_Init)GetProcAddress(hMod, "Init");
ptrSub_predict Predict = (ptrSub_predict)GetProcAddress(hMod, "Predict");
if (Init != NULL)
{
Init(model_filename, cfg_file, params_filename, 0);
}
if (Predict != NULL)
{
Predict(imgs, results);
}
}
std::cout << results.size() << endl;
std::vector data = results[0].data;
for (int i = 0; i < imgs[0].rows; i++)
{
for (int j = 0; j < imgs[0].cols; j++)
{
if (data[j + imgs[0].cols * i] == 0)
{
continue;
}
imgs[0].at(i, j)[0] = data[j + imgs[0].cols * i] * 100;
imgs[0].at(i, j)[1] = data[j + imgs[0].cols * i] * 100;
imgs[0].at(i, j)[2] = data[j + imgs[0].cols * i] * 100;
}
}
std::vector data1 = results[1].data;
for (int i = 0; i < imgs[1].rows; i++)
{
for (int j = 0; j < imgs[1].cols; j++)
{
if (data1[j + imgs[1].cols * i] == 0)
{
continue;
}
imgs[1].at(i, j)[0] = data1[j + imgs[1].cols * i] * 100;
imgs[1].at(i, j)[1] = data1[j + imgs[1].cols * i] * 100;
imgs[1].at(i, j)[2] = data1[j + imgs[1].cols * i] * 100;
}
}
namedWindow("re", WINDOW_AUTOSIZE);
imshow("re", imgs[0]);
namedWindow("re2", WINDOW_AUTOSIZE);
imshow("re2", imgs[1]);
waitKey(0);
}
//这部分用于接收batch_infer的结果
void batch_infer()
{
string imgs_path = "D:/VS_projects/test/";
string cfg_file = "D:/PaddleSeg_projects/PaddleX_DLL/test/deploy.yaml";
string params_filename = "D:/PaddleSeg_projects/PaddleX_DLL/test/model.pdiparams";
string model_filename = "D:/PaddleSeg_projects/PaddleX_DLL/test/model.pdmodel";
vector img_names;
glob(imgs_path, img_names);
vector imgs;
for (int i = 0; i < img_names.size(); i++)
{
Mat img = imread(img_names[i]);
imgs.push_back(img);
}
vector results;
if (hMod_batch != NULL)
{
ptrSub_batch_Init Init = (ptrSub_batch_Init)GetProcAddress(hMod_batch, "Init");
ptrSub_batch_predict Predict = (ptrSub_batch_predict)GetProcAddress(hMod_batch, "Predict");
if (Init != NULL)
{
Init(model_filename, cfg_file, params_filename,0,false);
}
if (Predict != NULL)
{
Predict(img_names, results,1);
}
}
std::cout << "local result size "< data = results[0].data;
for (int i = 0; i < imgs[0].rows; i++)
{
for (int j = 0; j < imgs[0].cols; j++)
{
if (data[j + imgs[0].cols * i] == 0)
{
continue;
}
imgs[0].at(i, j)[0] = data[j + imgs[0].cols * i] * 100;
imgs[0].at(i, j)[1] = data[j + imgs[0].cols * i] * 100;
imgs[0].at(i, j)[2] = data[j + imgs[0].cols * i] * 100;
}
}
std::vector data1 = results[1].data;
for (int i = 0; i < imgs[1].rows; i++)
{
for (int j = 0; j < imgs[1].cols; j++)
{
if (data1[j + imgs[1].cols * i] == 0)
{
continue;
}
imgs[1].at(i, j)[0] = data1[j + imgs[1].cols * i] * 100;
imgs[1].at(i, j)[1] = data1[j + imgs[1].cols * i] * 100;
imgs[1].at(i, j)[2] = data1[j + imgs[1].cols * i] * 100;
}
}
namedWindow("re", WINDOW_AUTOSIZE);
imshow("re", imgs[0]);
namedWindow("re2", WINDOW_AUTOSIZE);
imshow("re2", imgs[1]);
waitKey(0);
}
int main()
{
//normal_infer();
batch_infer();
} 将上边生成的dll以及build_out\paddle_deploy中的dll一起放到新建的项目中,即可调用
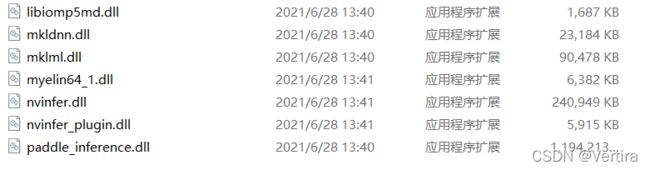
补充:
如果调用batch_infer,则更改batch_infer.cpp的代码:
// Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include
#include
#include
#include
#include
#include
#include
#include "model_deploy/common/include/paddle_deploy.h"
using namespace cv;
using namespace std;
//DEFINE_string(model_filename, "D:/PaddleSeg_projects/PaddleX_DLL4/weights_info/model.pdmodel", "Path of det inference model");
//DEFINE_string(params_filename, "D:/PaddleSeg_projects/PaddleX_DLL4/weights_info/model.pdiparams", "Path of det inference params");
//DEFINE_string(cfg_file, "D:/PaddleSeg_projects/PaddleX_DLL4/weights_info/deploy.yaml", "Path of yaml file");
//DEFINE_string(model_type, "seg", "model type");
//DEFINE_string(image_list, "D:/VS_projects/test/in.txt", "Path of test image file");
//DEFINE_int32(batch_size, 1, "Batch size of infering");
//DEFINE_bool(use_gpu, true, "Infering with GPU or CPU");
//DEFINE_int32(gpu_id, 0, "GPU card id");
//DEFINE_bool(use_trt, false, "Infering with TensorRT");
struct result_local
{
std::vector data;
// the shape of mask
std::vector score;
};
#define DLLEXPORT extern "C" _declspec(dllexport)
string model_type = "seg";
PaddleDeploy::Model* model;
DLLEXPORT void Init(string model_filename, string cfg_file, string params_filename, int gpu_id,bool use_trt)
{
// create model
model = PaddleDeploy::CreateModel(model_type);
// model init
model->Init(cfg_file);
// inference engine init
PaddleDeploy::PaddleEngineConfig engine_config;
engine_config.model_filename = model_filename;
engine_config.params_filename = params_filename;
engine_config.use_gpu = true;
engine_config.gpu_id = gpu_id;
engine_config.use_trt = use_trt;
if (use_trt) {
engine_config.precision = 0;
}
model->PaddleEngineInit(engine_config);
std::cout << "Paddle Init Sucess" << std::endl;
}
DLLEXPORT void Predict(std::vector image_paths, vector& results_back,int batch_size)
{
// infer
std::vector results;
for (int i = 0; i < image_paths.size(); i += batch_size) {
// Read image
results.clear();
int im_vec_size = std::min(static_cast(image_paths.size()), i + batch_size);
std::vector im_vec(im_vec_size - i);
#pragma omp parallel for num_threads(im_vec_size - i)
for (int j = i; j < im_vec_size; ++j) {
im_vec[j - i] = std::move(cv::imread(image_paths[j], 1));
}
std::cout << "im_vec size " << im_vec.size() << endl;
model->Predict(im_vec, &results);
std::vector data = results[0].seg_result->label_map.data;
cv::Mat img = cv::imread(image_paths[i]);
for (int i = 0; i < img.rows; i++)
{
for (int j = 0; j < img.cols; j++)
{
if (data[j + img.cols * i] == 0)
{
continue;
}
img.at(i, j)[0] = data[j + img.cols * i] * 100;
img.at(i, j)[1] = data[j + img.cols * i] * 100;
img.at(i, j)[2] = data[j + img.cols * i] * 100;
}
}
namedWindow("re", WINDOW_AUTOSIZE);
imshow("re", img);
waitKey(0);
for (int i = 0; i < results.size(); i++)
{
result_local temp;
vector data = results[i].seg_result->label_map.data;
vector score = results[i].seg_result->score_map.data;
temp.data = data;
temp.score = score;
results_back.push_back(temp);
}
}
}
//int main(int argc, char** argv) {
// // Parsing command-line
// google::ParseCommandLineFlags(&argc, &argv, true);
//
// // create model
// PaddleDeploy::Model* model = PaddleDeploy::CreateModel(FLAGS_model_type);
//
// // model init
// model->Init(FLAGS_cfg_file);
//
// // inference engine init
// PaddleDeploy::PaddleEngineConfig engine_config;
// engine_config.model_filename = FLAGS_model_filename;
// engine_config.params_filename = FLAGS_params_filename;
// engine_config.use_gpu = FLAGS_use_gpu;
// engine_config.gpu_id = FLAGS_gpu_id;
// engine_config.use_trt = FLAGS_use_trt;
// if (FLAGS_use_trt) {
// engine_config.precision = 0;
// }
// model->PaddleEngineInit(engine_config);
//
// // Mini-batch
// std::vector image_paths;
// if (FLAGS_image_list != "") {
// std::ifstream inf(FLAGS_image_list);
// if (!inf) {
// std::cerr << "Fail to open file " << FLAGS_image_list << std::endl;
// return -1;
// }
// std::string image_path;
// while (getline(inf, image_path)) {
// image_paths.push_back(image_path);
// }
// }
// // infer
// std::vector results;
// for (int i = 0; i < image_paths.size(); i += FLAGS_batch_size) {
// // Read image
// results.clear();
// int im_vec_size =
// std::min(static_cast(image_paths.size()), i + FLAGS_batch_size);
// std::vector im_vec(im_vec_size - i);
// #pragma omp parallel for num_threads(im_vec_size - i)
// for (int j = i; j < im_vec_size; ++j) {
// im_vec[j - i] = std::move(cv::imread(image_paths[j], 1));
// }
// std::cout << im_vec.size() << " :::::::::" << endl;
// model->Predict(im_vec, &results);
//
// std::cout << i / FLAGS_batch_size << " group -----" << std::endl;
// for (auto j = 0; j < results.size(); ++j) {
// std::cout << "Result for sample " << j << std::endl;
// std::cout << results[j] << std::endl;
// }
// std::cout << results.size() << std::endl;
// std::vector data = results[0].seg_result->label_map.data;
// cv::Mat img = cv::imread(image_paths[i]);
// for (int i = 0; i < img.rows; i++)
// {
// for (int j = 0; j < img.cols; j++)
// {
// if (data[j + img.cols * i] == 0)
// {
// continue;
// }
// img.at(i, j)[0] = data[j + img.cols * i] * 100;
// img.at(i, j)[1] = data[j + img.cols * i] * 100;
// img.at(i, j)[2] = data[j + img.cols * i] * 100;
// }
// }
// namedWindow("re", WINDOW_AUTOSIZE);
// imshow("re", img);
// waitKey(0);
// }
// delete model;
// return 0;
//}
关于cuda11.0+vs2019
有如下改动: