Opencv 图片融合 addWeighted性能测试
原文:http://blog.csdn.net/u011503970/article/details/18615537
这次介绍OpenCV中一个简单的点运算函数,用来实现图片合成。 对应于例程中的 (TUTORIAL) AddingImages 和 (TUTORIAL) AddingImagesTrackbar。
Opencv中提供的函数是addWeighted,用法很简单,为了比较性能了,我们手工实现了一段相同功能的代码,并比较两者的性能,到底快了多少,且看下文分解。
图像处理中一个简单而有趣的点运算操作可以用以下的公式表示,可以实现两张图片的线性融合。

这里α 表示两种图片的融合比例,这个g(x) 表示 融合图片中的像素点,f0(x) 和 f1(x) 分别表示背景和前景图片中的像素点。
下面为例程中的函数调用,
- beta = ( 1.0 - alpha );
- addWeighted( src1, alpha, src2, beta, 0.0, dst);
这个函数的原型如下所示,可以看出这个函数最小需要6个参数。
1、 第1个参数,输入图片1,
2、第2个参数,图片1的融合比例
3、第3个参数,输入图片2
4、第4个参数,图片2的融合比例
5、第5个参数,偏差
6、第6个参数,输出图片
- //! computes weighted sum of two arrays (dst = alpha*src1 + beta*src2 + gamma)
- CV_EXPORTS_W void addWeighted(InputArray src1, double alpha, InputArray src2,
- double beta, double gamma, OutputArray dst, int dtype=-1);
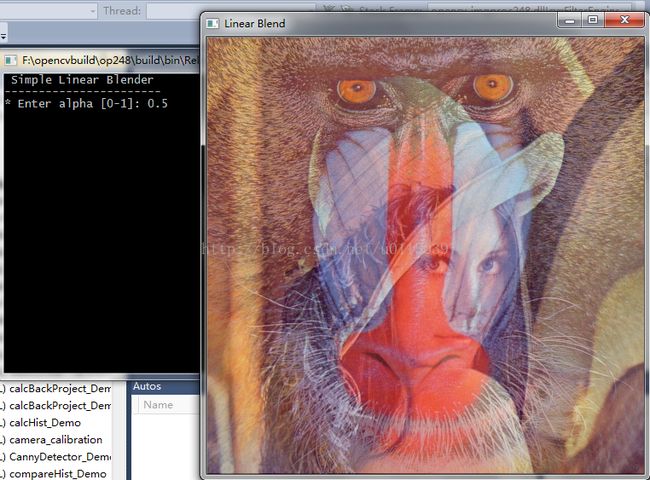
程序会提示输入第一个图片的融合比例,输入0.5时,图片的效果。
不过有时候会想,调节alpha 的值,查看不同情况下的融合结果。这个也不难做到,在例程(TUTORIAL) AddingImagesTrackbar中已经帮我实现了
先看看运行的结果。

相比之前的结果,可以看出在图像上方多了一个滑动条,用来改变alpha的值,范围从0~100。
相应的代码如下:
- /// Create Windows
- namedWindow("Linear Blend", 1);
- /// Create Trackbars
- char TrackbarName[50];
- sprintf( TrackbarName, "Alpha x %d", alpha_slider_max );
- createTrackbar( TrackbarName, "Linear Blend", &alpha_slider, alpha_slider_max, on_trackbar );
- /// Show some stuff
- on_trackbar( alpha_slider, 0 );
- CV_EXPORTS int createTrackbar(const string& trackbarname, const string& winname,
- int* value, int count,
- TrackbarCallback onChange = 0,
- void* userdata = 0);
1、第一个参数,为滑块的名字
2、第二个参数,为滑块所在窗口的名字,用来获取窗口的handle
3、第三个参数,为传人一个数据的指针,通过滑块来改变该数据的值,该变量需要在回调函数TrackbarCallback 中作用域可见,因此例程中将它定义为全局变量
4、第四个参数,为传人数据的最大值,用来控制数据的变化范围
5、第五个参数,回调函数的函数指针,当滑块变化时,便调用回调函数,实现融合画面随着滑块的滑动而变化
下面我们来看下回调函数 on_trackbar, 它被定义了成一个static函数,意味着函数生命周期从被调用开始一直存在知道程序结束,第二个参数对应createTrackbar函数中的第6个参数,用户数据指针。
- /**
- * @function on_trackbar
- * @brief Callback for trackbar
- */
- static void on_trackbar( int, void* )
- {
- alpha = (double) alpha_slider/alpha_slider_max ;
- beta = ( 1.0 - alpha );
- addWeighted( src1, alpha, src2, beta, 0.0, dst);
- imshow( "Linear Blend", dst );
- }
为了测试addWeighted 函数性能,我们手工打造了一段相同功能的函数MyaddWeighted,代码如下
- void MyaddWeight(InputArray _src1, double alpha, InputArray _src2, double beta, double gamma, OutputArray _dst)
- {
- CV_Assert(_src1.depth() == CV_8U && _src2.depth() == CV_8U);
- CV_Assert(_src1.channels() == _src2.channels() &&_src1.size() == _src2.size());
- _dst.create(_src1.size(),_src1.type());
- Mat src1 = _src1.getMat();
- Mat src2 = _src2.getMat();
- Mat dst = _dst.getMat();
- int rows = src1.rows;
- int cols = src1.cols * src1.channels();
- if (src1.isContinuous() && src2.isContinuous() && dst.isContinuous())
- {
- cols *= rows;
- rows = 1;
- }
- uchar* pSrc1 = NULL;
- uchar* pSrc2 = NULL;
- uchar* pDst = NULL;
- for (int i=0; i
- {
- pSrc1 = src1.ptr
(i); - pSrc2 = src2.ptr
(i); - pDst = dst.ptr
(i); - for (int j=0; j
- {
- pDst[j] = saturate_cast
(pSrc1[j]*alpha + pSrc2[j]*beta + gamma); - }
- }
- }
在手工打造的程序中,运用C [ ]下标对图像像素点进行遍历,在前面的例程有过相关介绍,C[ ] 是三种遍历方法中性能最好的。
下图是各自方法 运行1000次的平均时间,可以看出手工打造的代码,虽然很好理解,但相对于opencv 的addWeightd函数性能差了很多,运行时间是6:1 。

注意到在我们代码中有用到 saturate_cast
可以看出,平均运行时间从3.7毫秒缩短到了2.4毫秒,占了运行时间的1/3。
现在换过一个方法来写MyAddWeight 函数,还记得opencv中LUT函数中用到的NAryMatIterator,这次我们利用它来重写MyAddWeight
- void MyaddWeight2(InputArray _src1, double alpha, InputArray _src2, double beta, double gamma, OutputArray _dst)
- {
- CV_Assert(_src1.depth() == CV_8U && _src2.depth() == CV_8U);
- CV_Assert(_src1.channels() == _src2.channels() &&_src1.size() == _src2.size());
- _dst.create(_src1.size(),_src1.type());
- Mat src1 = _src1.getMat();
- Mat src2 = _src2.getMat();
- Mat dst = _dst.getMat();
- int cn = src1.channels();
- AddFun fun = AddFunTable[src1.depth()]; // 通过数据类型,从函数指针数组中选择相应的函数进行调用
- const Mat* arrays[] = {&src1, &src2, &dst,0}; // 注意需要在最后加一个0,作为指针数组结束的标志,以确定数组中有效指针的个数
- uchar* ptrs[3];
- NAryMatIterator it(arrays, ptrs);
- int len = (int)it.size;
- for( size_t i = 0; i < it.nplanes; i++, ++it )
- fun(ptrs[0], ptrs[1], ptrs[2], len, cn, alpha, beta, gamma);
- }
AddFun 是我们定义的一个函数指针类型,利用它加上一个函数指针数组AddFunTable,我们可以很容易的扩展MyAddWeight的使用范围,使它对CV_16S, CV_32F的数据类型也能适用
- typedef void (*AddFun) (const uchar*, const uchar*, const uchar*, int, int, double, double, double);
- static void ADD8u_(const uchar* src1, const uchar* src2, uchar* dst, int len, int cn, double aplha, double beta, double gamma)
- {
- for (int i=0; i
- dst[i] = src1[i]*aplha + src2[i]*beta + gamma;
- }
这个是函数ADD8u_ 的定义,相应的,我们可以快速的写出适合其他数据类型,如CV_8U,CV_16S,CV_32F的处理函数,
- static AddFun AddFunTable[] =
- {
- (AddFun)ADD8u_, 0
- };
这个是函数指针数组,目前只实现了对数据类型CV_8U的操作,这样就可以根据数据的类型,调用相应的函数,而不必针对每一种数据类型写一个函数,大大提高了代码的重用率,也大大减少了以后代码维护的工作量,是一个很值得学习的技巧。
下面看下,这种写法是否对性能有所提高。
可以看到,运行时间从2.48 毫秒减少到了2.29毫秒,性能提高了大约 7.6%左右,相对于代码重用方面,性能上面的提高不是很明显。