【Python】爬取2019年男篮世界杯数据,并可视化
【Python】爬取2019年男篮世界杯数据,并可视化
本届男篮世界杯已经结束,本届比赛最让人失意的还是中国和美国两支队伍,一个本来以为可以小组出线,结果要去打奥运落选赛,另一个本来以为最起码进四强的,结果要去打7-8名排位赛。不过也有出乎意料的队伍,阿根廷和西班牙,这两支队伍辉煌的老一辈球员基本都没参赛,都是依然打到了决赛,强队底蕴一直都在,年轻球员也很给力。这个中国队真的可以取取经。话不多说,先爬到数据。
一,目标
本次爬取的网站新浪体育,有个模块是男篮世界杯的。2019年男篮世界杯
爬虫思路:爬取赛程页面,比赛数据统计来获取球队信息,比赛对战信息,球队比赛数据,球员个人数据。
二,页面分析
按照新浪的套路,直接请求相应的页面是肯定获取不到任何数据,一般都是动态加载json数据,所以要找到这些数据。通过浏览器的开发者工具没发现什么有用的信息,改用Fiddler试下,就有结果了。强烈安利Fiddler!!!
在加载赛程页面时,有一个响应中有很多json数据
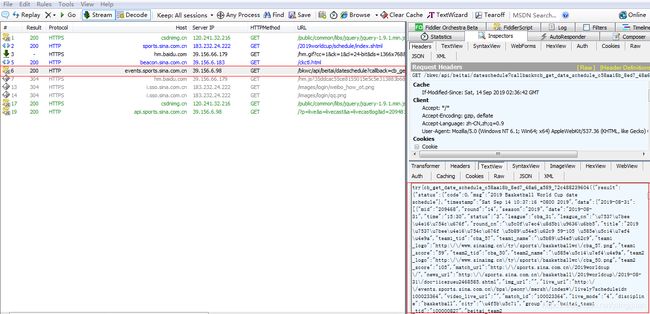
看下里面数据有时间、球队id、比分之类的数据,虽然编码不对,但是基本确定这些数据就是我们需要的。赛程数据url
接下来看下比赛数据统计页面,同样的,可以发现有个响应携带了很多json数据。里面的数据带有球员名称之类的
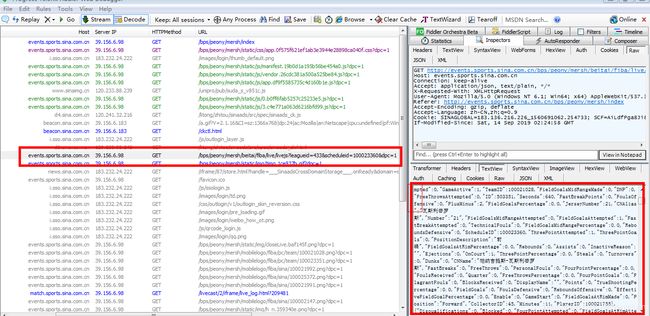
请求的url是:http://events.sports.sina.com.cn/bps/peony/mersh/beitai/fiba/live/livejs?leagueid=433&scheduleid=100023360&dpc=1 其中的scheduleid应该是赛程中对用的场次id。
数据来源已经弄清楚了,接下就直接解析数据得到我们需要的数据。
三,代码实现
#下载的页面需要对编码进行转换获取到对应的数据。
def download(self,url):
"""
页面下载
:param url: 页面url
:return: json格式数据
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
if url.startswith('http://events.sports.sina.com.cn/bkwc/'):
response = requests.get(url, headers=headers)
text = response.text.encode('utf-8').decode('unicode_escape')
else:
response = requests.get(url, headers=headers)
text = str(response.content, 'utf-8')
return text
完整代码已经上传github
https://github.com/yangjunjians/Crawlers/blob/master/PageParser/WorldCupParser.py
四,数据可视化
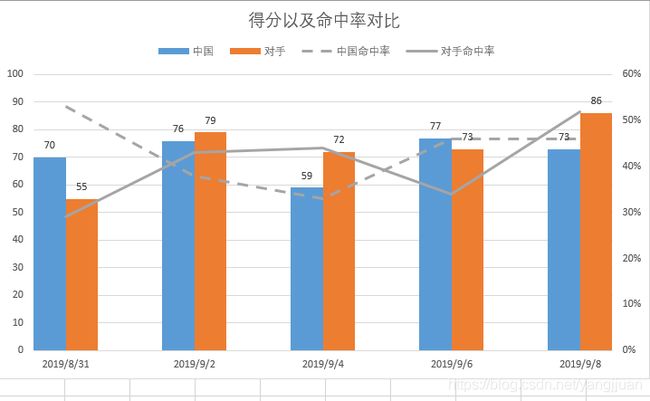
中国队5场比赛的得分以及命中率
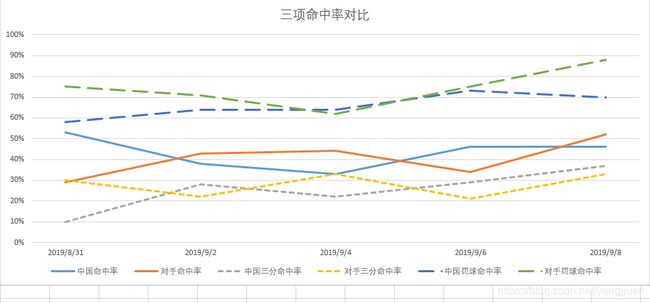
球队的各项场均数据
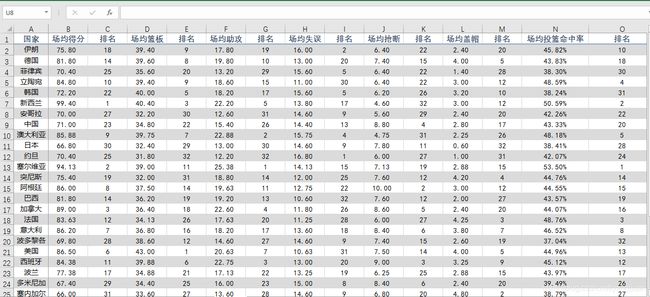
中国的数据基本都是处于中等水平,都处于在20-名以后,甚至垫底和倒数的,比如场均助攻排在26,场均三分命中率排在29,场均罚球命中率排在32。看过比赛都知道,中国队基本每场球都是在三分线外互传,没机会,然后就靠个人单干。或者被对手放三分,并且三分很不稳定,没有射手。这些都不说先,基本的罚篮都是垫底的,怪不得大家都说国手们太飘了。
最后还是要说,中国队!总,,,