Python数据分析 3.numpy数据科学库
Python数据分析 3.numpy基础库
1.数组的创建
import numpy as np
t1 = np.array([1,2,3,])
print(t1)
print(type(t1))
t2 = np.array(range(3))
print(t2)
t3 = np.arange(4,10,2)
print(t3)
print(t3.dtype)
[1 2 3]
[0 1 2]
[4 6 8]
int32
numpy中常见的数据类型:

#numpy中的数据类型
t4 = np.array(range(1,4),dtype="i1")
print(t4)
print(t4.dtype)
#numpy中的bool类型
t5 = np.array([1,1,0,1,0,0],dtype=bool)
print(t5)
print(t5.dtype)
#调整数据类型
t6 = t5.astype("int8")
print(t6)
print(t6.dtype)
#numpy中的小数
t7 = np.array([random.random() for i in range(3)])
print(t7)
print(t7.dtype)
#numpy小数点后几位
t8 = np.round(t7,2)
print(t8)
print("%.2f"%random.random())
[1 2 3]
int8
[True True False True False False]
bool
[1 1 0 1 0 0]
int8
[0.50897424 0.78931079 0.69345471]
float64
[0.51 0.79 0.69]
0.78
数组的形状:
import numpy as np
t1 = np.arange(12)
print(t1)
print(t1.shape)
t2 = np.array([[1,2,3],[4,5,6]])
print(t2)
print(t2.shape)
# 三维数组
t3 = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(t3)
print(t3.shape)
[ 0 1 2 3 4 5 6 7 8 9 10 11]
(12,)
[[1 2 3]
[4 5 6]]
(2, 3)
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]]
(2, 2, 3)
import numpy as np
t4 = np.arange(12).reshape((3,4))
print(t4)
# shape(块数,行数,列数)
t5 = np.arange(24).reshape((2,3,4))
print(t5)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
注:reshape有返回值,对原来的值无变化
import numpy as np
t4 = np.arange(12).reshape((3,4))
print(t4)
# shape(块数,行数,列数)
t5 = np.arange(24).reshape((4,6))
print(t5)
print(t5.reshape((24,)))
#shape[0]代表行数,shape[1]代表列数
t6 = t5.reshape((t5.shape[0]*t5.shape[1],))
print(t6)
print(t5.flatten())
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
2.数组的计算
数组和数字计算(广播机制):
import numpy as np
t5 = np.arange(24).reshape((4,6))
print(t5+2)
print(t5/2)
print(t5/0)
[[ 2 3 4 5 6 7]
[ 8 9 10 11 12 13]
[14 15 16 17 18 19]
[20 21 22 23 24 25]]
[[ 0. 0.5 1. 1.5 2. 2.5]
[ 3. 3.5 4. 4.5 5. 5.5]
[ 6. 6.5 7. 7.5 8. 8.5]
[ 9. 9.5 10. 10.5 11. 11.5]]
[[nan inf inf inf inf inf]
[inf inf inf inf inf inf]
[inf inf inf inf inf inf]
[inf inf inf inf inf inf]]
# nan: not a number
# inf: infinity
数组和数组(同维度/不同维度)计算:
import numpy as np
t5 = np.arange(24).reshape((4,6))
t6 = np.arange(100,124).reshape((4,6))
print(t5+t6)
t7 = np.arange(6)
print(t5-t7)
t8 = np.arange(4).reshape((4,1))
print(t5-t8)
[[100 102 104 106 108 110]
[112 114 116 118 120 122]
[124 126 128 130 132 134]
[136 138 140 142 144 146]]
[[ 0 0 0 0 0 0]
[ 6 6 6 6 6 6]
[12 12 12 12 12 12]
[18 18 18 18 18 18]]
[[ 0 1 2 3 4 5]
[ 5 6 7 8 9 10]
[10 11 12 13 14 15]
[15 16 17 18 19 20]]
数组的轴:

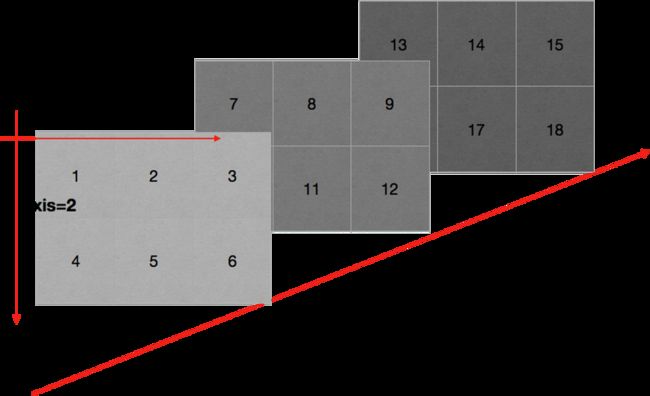
3.读取数据
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)

import numpy as np
us_file_path = "D:/数据分析资料/day03/code/youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "D:/数据分析资料/day03/code/youtube_video_data/GB_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
t2 = np.loadtxt(uk_file_path,delimiter=",",dtype="int")
# 转置的方法
t1.transpose()
t1.T
t1.swapaxes(1,0)
4.索引和切片
# 取行
print(t2[2]) # 取第三行数据
# 取连续多行
print(t2[2:4])
# 取不连续多行
print(t2[[2,8,10]])
# 取列
print(t2[:,0])
#取连续多列
print(t2[:,1:])
# 取不连续多列
print(t2[:,[2,3]])
# 取多行多列
print(t2[1,2])
print(t2[[0,1],[0,2]]) # 取的是(0,0)和(1,2)
数值的修改:
import numpy as np
t2 = np.arange(24).reshape((4,6))
# 大小判断
t2[t2<10]=3
# 布尔索引
print(t2<10)
# 三元运算符
print(np.where(t2<10,0,10))
# clip裁剪
t2.clip(10,18) # 小于10替换为10,大于18替换为18
5.拼接和处理:
# 竖直拼接
np.vstack((t1,t2))
# 水平拼接
np.vstack((t1,t2))
练习:合并两个国家的数据并保留国家信息
import numpy as np
us_file_path = "D:/数据分析资料/day03/code/youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "D:/数据分析资料/day03/code/youtube_video_data/GB_video_data_numbers.csv"
us_data = np.loadtxt(us_file_path,delimiter=",",dtype=int)
uk_data = np.loadtxt(uk_file_path,delimiter=",",dtype=int)
# 添加国家信息
# 构造全为0/1的数据
zeros_data = np.zeros((us_data.shape[0],1)).astype(int)
ones_data = np.ones((uk_data.shape[0],1)).astype(int)
us_data = np.hstack((us_data,zeros_data))
uk_data = np.hstack((uk_data,ones_data))
# 拼接两组数据
final_data = np.vstack((us_data,uk_data))
print(final_data)
numpy更多方法:
- 获取最大值最小值的位置
np.argmax(t,axis=0)
np.argmin(t,axis=1) - 创建一个全0的数组: np.zeros((3,4))
- 创建一个全1的数组:np.ones((3,4))
- 创建一个对角线为1的正方形数组(方阵):np.eye(3)
numpy中的随机方法:
nan的性质:
np.nan == np.nan #False
#判断数组中nan的个数
np.count_nonzero(t != t)
处理nan,不能直接替换为0,可以替换成均值。
6.常用统计方法
求和:t.sum(axis=None)
均值:t.mean(a,axis=None)
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None)
标准差:t.std(axis=None)
练习:填充nan为均值
import numpy as np
def fill_ndarray(t1):
for i in range(t1.shape[1]):
temp_col = t1[:,i] # 当前这一列
nan_num = np.count_nonzero(temp_col != temp_col)
if nan_num != 0:
temp_not_nan_col = temp_col[temp_col == temp_col] # 当前一列不为nan
temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean() # 赋值
return t1
if __name__ == "__main__":
t1 = np.arange(12).reshape((3,4)).astype("float")
t1[1,2:] = np.nan
print(t1)
t2 = fill_ndarray(t1)
print(t2)
7.总结
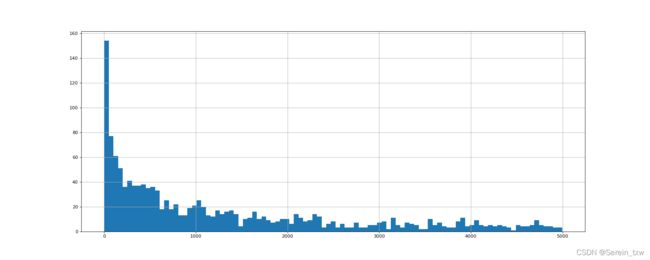
练习1:绘制美国YouTube评论数量的直方图
import numpy as np
from matplotlib import pyplot as plt
us_file_path = "D:/数据分析资料/day03/code/youtube_video_data/US_video_data_numbers.csv"
t_us = np.loadtxt(us_file_path,delimiter=",",dtype="int")
# 取评论数据
# 选择比5000小的数据
t_us_comments = t_us[:,-1]
t_us_comments = t_us_comments[t_us_comments<=5000]
# 设置组数
d = 50
bins_num = (t_us_comments.max() - t_us_comments.min())//d
# 绘图
plt.figure(figsize=(20,8),dpi=80)
plt.grid()
plt.hist(t_us_comments,bins_num)
练习2:英国YouTube数据评论数和喜欢数的关系
import numpy as np
from matplotlib import pyplot as plt
us_file_path = "D:/daily/大二下/量化/拜师/数据分析资料/day03/code/youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "D:/daily/大二下/量化/拜师/数据分析资料/day03/code/youtube_video_data/GB_video_data_numbers.csv"
t_us = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t_uk = np.loadtxt(uk_file_path,delimiter=",",dtype="int")
t_uk = t_uk[t_uk[:,1]<=500000]
t_uk_comment = t_uk[:,-1]
t_uk_like = t_uk[:,1]
plt.figure(figsize=(20,8),dpi=80)
plt.scatter(t_uk_like,t_uk_comment)
