基于MegEngine实现目标检测【附部分源码及模型】
文章目录
- 前言
- 目标检测发展史及意义
- 一、数据集的准备
-
- 1.标注工具的安装
- 2.数据集的准备
- 3.标注数据
- 4.解释xml文件的内容
- 二、基于MegEngine的目标检测框架构建
-
- 1.引入库
- 2.CPU/GPU配置
- 3.设置模型字典及配置文件
- 4.解析数据集到列表中
- 5.设置数据迭代器
- 6.数据增强
- 7.获取loader
- 8.模型构建
- 9.模型训练
-
- 1.优化器及参数初始化
- 2.模型训练
- 3.模型保存
- 10.模型预测
- 三、基于MegEngine的模型构建
-
- 1.FasterRCNN实现
- 四、模型主入口
- 五、效果展示
-
- 1.自定义数据集效果展示
- 2.COCO数据集效果展示
- 六、COCO各模型免费下载
- 总结
前言
本文主要讲解基于megengine深度学习框架实现目标检测,鉴于之前写chainer的麻烦,本结构代码也类似chainer的目标检测框架,各个模型只需要修改网络结构即可,本次直接一篇博文写完目标检测框架及网络结构的搭建,让志同道合者不需要切换文章。
环境配置:
python 3.8
megengine 1.9.1
cuda 10.1
目标检测发展史及意义
图像分类任务的实现可以让我们粗略的知道图像中包含了什么类型的物体,但并不知道物体在图像中哪一个位置,也不知道物体的具体信息,在一些具体的应用场景比如车牌识别、交通违章检测、人脸识别、运动捕捉,单纯的图像分类就不能完全满足我们的需求了。
这时候,需要引入图像领域另一个重要任务:物体的检测与识别。在传统机器领域,一个典型的案例是利用HOG(Histogram of Gradient)特征来生成各种物体相应的“滤波器”,HOG滤波器能完整的记录物体的边缘和轮廓信息,利用这一滤波器过滤不同图片的不同位置,当输出响应值幅度超过一定阈值,就认为滤波器和图片中的物体匹配程度较高,从而完成了物体的检测。
一、数据集的准备
首先我是用的是halcon数据集里边的药片,去了前边的100张做标注,后面的300张做测试,其中100张里边选择90张做训练集,10张做验证集。
1.标注工具的安装
pip install labelimg
进入cmd,输入labelimg,会出现如图的标注工具:

2.数据集的准备
首先我们先创建3个文件夹,如图:

DataImage:100张需要标注的图像
DataLabel:空文件夹,主要是存放标注文件,这个在labelimg中生成标注文件
test:存放剩下的300张图片,不需要标注
DataImage目录下和test目录的存放样子是这样的(以DataImage为例):
3.标注数据
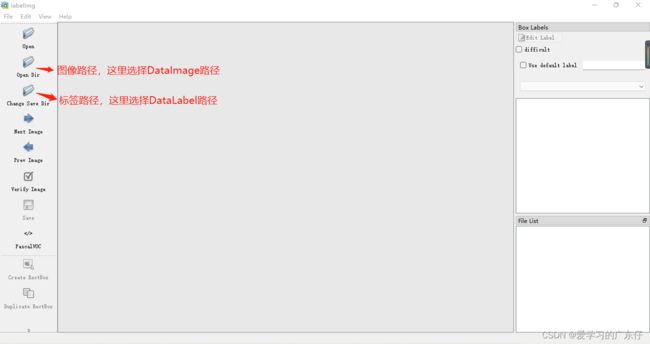
首先我们需要在labelimg中设置图像路径和标签存放路径,如图:
然后先记住快捷键:w:开始编辑,a:上一张,d:下一张。这个工具只需要这三个快捷键即可完成工作。
开始标注工作,首先按下键盘w,这个时候进入编辑框框的模式,然后在图像上绘制框框,输入标签(框框属于什么类别),即可完成物体1的标注,一张物体可以多个标注和多个类别,但是切记不可摸棱两可,比如这张图像对于某物体标注了,另一张图像如果出现同样的就需要标注,或者标签类别不可多个,比如这个图象A物体标注为A标签,下张图的A物体标出成了B标签,最终的效果如图:

最后标注完成会在DataLabel中看到标注文件,json格式:
4.解释xml文件的内容
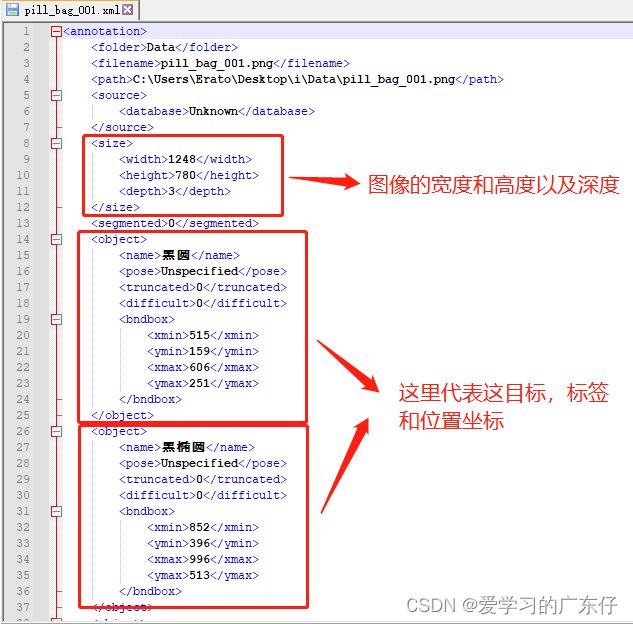
xml标签文件如图,我们用到的就只有object对象,对其进行解析即可。
二、基于MegEngine的目标检测框架构建
本目标检测框架目录结构如下:

BaseModel:此目录保存基于COCO数据集已经训练好的模型
core:此目录主要保存标准的py文件,功能如目标检测nms等计算
data:此目录主要保存标准py文件,功能如数据加载器,迭代器等
nets:此目录主要保存模型结构
result_Model:此目录是自定义训练数据集的保存模型位置
Ctu_Detection.py:目标检测主类实现及主入口
1.引入库
import bisect,sys,os,time,megengine,json,math,cv2,random
sys.path.append('.')
import numpy as np
from PIL import Image,ImageFont,ImageDraw
import megengine.distributed as dist
from megengine.autodiff import GradManager
from megengine.data import DataLoader, Infinite, RandomSampler
from megengine.data import transform as T
from megengine.optimizer import SGD
2.CPU/GPU配置
if USEGPU!='-1' and dist.helper.get_device_count_by_fork("gpu") > 0:
megengine.set_default_device('gpux')
else:
megengine.set_default_device('cpux')
USEGPU='-1'
os.environ['CUDA_VISIBLE_DEVICES']= USEGPU
3.设置模型字典及配置文件
这里主要是体现本目标检测工程的网络结构,可根据自己爱好自行选择:
self.network_Name={
'atss':ATSS,
'fasterrcnn':FasterRCNN,
'fcos':FCOS,
'freeanchor':FreeAnchor,
'retinanet':RetinaNet
}
self.network_Config = {
'atss': ATSSConfig,
'fasterrcnn': FasterRCNNConfig,
'fcos':FCOSConfig,
'freeanchor':FreeAnchorConfig,
'retinanet':RetinaNetConfig
}
4.解析数据集到列表中
def CreateDataList_Detection(IMGDir,XMLDir,train_split):
ImgList = os.listdir(IMGDir)
XmlList = os.listdir(XMLDir)
classes = []
dataList=[]
for each_jpg in ImgList:
each_xml = each_jpg.split('.')[0] + '.xml'
if each_xml in XmlList:
dataList.append([os.path.join(IMGDir,each_jpg),os.path.join(XMLDir,each_xml)])
with open(os.path.join(XMLDir,each_xml), "r", encoding="utf-8") as in_file:
tree = ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls)
random.shuffle(dataList)
if train_split <=0 or train_split >=1:
train_data_list = dataList
val_data_list = dataList
else:
train_data_list = dataList[:int(len(dataList)*train_split)]
val_data_list = dataList[int(len(dataList)*train_split):]
return train_data_list, val_data_list, classes
5.设置数据迭代器
class PascalVOC(Dataset):
def parse_voc_xml(self, node):
voc_dict = {}
children = list(node)
if children:
def_dic = collections.defaultdict(list)
for dc in map(self.parse_voc_xml, children):
for ind, v in dc.items():
def_dic[ind].append(v)
if node.tag == "annotation":
def_dic["object"] = [def_dic["object"]]
voc_dict = {
node.tag: {
ind: v[0] if len(v) == 1 else v for ind, v in def_dic.items()
}
}
if node.text:
text = node.text.strip()
if not children:
voc_dict[node.tag] = text
return voc_dict
def get_img_info(self, index, image=None):
if image is None:
image = cv2.imread(self.data_list[index][0], cv2.IMREAD_COLOR)
if index not in self.img_infos:
self.img_infos[index] = dict(
height=image.shape[0],
width=image.shape[1],
file_name=self.data_list[index][0],
)
return self.img_infos[index]
def __init__(self, data_list,classes_names):
super().__init__()
self.data_list = data_list
self.classes_names = classes_names
self.img_infos = dict()
def __getitem__(self, index):
target = []
image = cv2.imread(self.data_list[index][0], cv2.IMREAD_COLOR)
target.append(image)
anno = self.parse_voc_xml(ET.parse(self.data_list[index][1]).getroot())
boxes = [obj["bndbox"] for obj in anno["annotation"]["object"]]
boxes = [
(bb["xmin"], bb["ymin"], bb["xmax"], bb["ymax"]) for bb in boxes
]
boxes = np.array(boxes, dtype=np.float32).reshape(-1, 4)
target.append(boxes)
boxes_category = [obj["name"] for obj in anno["annotation"]["object"]]
boxes_category = [
self.classes_names.index(bc) + 1 for bc in boxes_category
]
boxes_category = np.array(boxes_category, dtype=np.int32)
target.append(boxes_category)
info = self.get_img_info(index, image)
info = [info["height"], info["width"], info["file_name"]]
target.append(info)
return tuple(target)
def __len__(self):
return len(self.data_list)
6.数据增强
transforms=[
T.ShortestEdgeResize(
self.min_size,
self.max_size,
sample_style="choice",
),
T.RandomHorizontalFlip(),
T.ToMode(),
]
7.获取loader
self.train_dataloader = DataLoader(
train_dataset,
sampler=train_sampler,
transform=T.Compose(
transforms=[
T.ShortestEdgeResize(
self.min_size,
self.max_size,
sample_style="choice",
),
T.RandomHorizontalFlip(),
T.ToMode(),
],
order=["image", "boxes", "boxes_category"],
),
collator=DetectionPadCollator(),
num_workers=num_workers,
)
8.模型构建
这里根据模型字典及类别即可得到模型结构,后续会对此模型字典内部实现进行解析
self.model = self.network_Name[self.network](self.network_Config[self.network](num_classes=len(self.classes_names),backbone=self.backbone))
9.模型训练
1.优化器及参数初始化
params_with_grad = []
for name, param in self.model.named_parameters():
if "bottom_up.conv1" in name and self.model.cfg.backbone_freeze_at >= 1:
continue
if "bottom_up.layer1" in name and self.model.cfg.backbone_freeze_at >= 2:
continue
params_with_grad.append(param)
opt = SGD(
params_with_grad,
lr=learning_rate,
momentum=0.9,
weight_decay=0.0001,
)
gm = GradManager()
gm.attach(params_with_grad)
2.模型训练
with gm:
loss_dict = self.model(image=megengine.tensor(mini_batch["data"]), im_info=megengine.tensor(mini_batch["im_info"]), gt_boxes=megengine.tensor(mini_batch["gt_boxes"]))
gm.backward(loss_dict["total_loss"])
loss_list = list(loss_dict.values())
3.模型保存
模型保存结构必须保持结构一致,如图:

主要包含主干网络结构,类别,图像大小,模型选择,模型保存路径
megengine.save(
{"epoch": epoch, "state_dict": self.model.state_dict()}, ClassDict['model_path'],
)
10.模型预测
def predict(self,img_cv,predict_score=0.3):
start_time = time.time()
original_height, original_width, _ = img_cv.shape
im_size_min = np.min([original_height, original_width])
im_size_max = np.max([original_height, original_width])
scale = (self.min_size + 0.0) / im_size_min
if scale * im_size_max > self.max_size:
scale = (self.max_size + 0.0) / im_size_max
resized_height, resized_width = (
int(round(original_height * scale)),
int(round(original_width * scale)),
)
resized_img = cv2.resize(img_cv, (resized_width, resized_height), interpolation=cv2.INTER_LINEAR,)
trans_img = np.ascontiguousarray(resized_img.transpose(2, 0, 1)[None, :, :, :], dtype=np.float32)
im_info = np.array([(resized_height, resized_width, original_height, original_width)], dtype=np.float32,)
box_cls, box_delta = self.model(image=megengine.tensor(trans_img), im_info=megengine.tensor(im_info))
box_cls, box_delta = box_cls.numpy(), box_delta.numpy()
dtboxes_all = list()
all_inds = np.where(box_cls > self.model.cfg.test_cls_threshold)
for c in range(self.model.cfg.num_classes):
inds = np.where(all_inds[1] == c)[0]
inds = all_inds[0][inds]
scores = box_cls[inds, c]
if self.model.cfg.class_aware_box:
bboxes = box_delta[inds, c, :]
else:
bboxes = box_delta[inds, :]
dtboxes = np.hstack((bboxes, scores[:, np.newaxis])).astype(np.float32)
if dtboxes.size > 0:
if self.model.cfg.test_nms == -1:
keep = dtboxes[:, 4].argsort()[::-1]
else:
assert 0 < self.model.cfg.test_nms <= 1.0
keep = py_cpu_nms(dtboxes, self.model.cfg.test_nms)
dtboxes = np.hstack(
(dtboxes[keep], np.full((len(keep), 1), c, dtype=np.float32))
).astype(np.float32)
dtboxes_all.extend(dtboxes)
if len(dtboxes_all) > self.model.cfg.test_max_boxes_per_image:
dtboxes_all = sorted(dtboxes_all, reverse=True, key=lambda i: i[4])[
:self.model.cfg.test_max_boxes_per_image
]
pred_res = np.array(dtboxes_all, dtype=np.float)
img_cv = np.array(img_cv)
origin_img_pillow = self.cv2_pillow(img_cv)
font = ImageFont.truetype(font='./BaseModel/simhei.ttf', size=np.floor(3e-2 * np.shape(origin_img_pillow)[1] + 0.5).astype('int32'))
thickness = max((np.shape(origin_img_pillow)[0] + np.shape(origin_img_pillow)[1]) // self.min_size, 1)
bboxes_result=[]
for det in pred_res:
b=[]
bb = det[:4].astype(int)
cls_id = int(det[5])
score = det[4]
if score > predict_score:
xmin, ymin, xmax, ymax = [int(x) for x in bb]
class_name = self.classes_names[cls_id]
b.append([(xmin,xmax,ymin,ymax),class_name,score])
top, left, bottom, right = ymin, xmin, ymax, xmax
label = '{}-{:.3f}'.format(class_name, score)
draw = ImageDraw.Draw(origin_img_pillow)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle([left + i, top + i, right - i, bottom - i], outline=self.colors[cls_id])
draw.rectangle([tuple(text_origin), tuple(text_origin + label_size)], fill=self.colors[cls_id])
draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font)
del draw
bboxes_result.append(b)
result_data={
'imges_result':self.pillow_cv2(origin_img_pillow),
'bboxes_result':bboxes_result,
'time':time.time()-start_time
}
return result_data
三、基于MegEngine的模型构建
先看下模型字典及nets文件夹目录,代表会有此类模型:
self.network_Name={
'atss':ATSS,
'fasterrcnn':FasterRCNN,
'fcos':FCOS,
'freeanchor':FreeAnchor,
'retinanet':RetinaNet
}
引入库:
from nets.atss import ATSS,ATSSConfig
from nets.faster_rcnn import FasterRCNN,FasterRCNNConfig
from nets.fcos import FCOS,FCOSConfig
from nets.freeanchor import FreeAnchor,FreeAnchorConfig
from nets.retinanet import RetinaNet,RetinaNetConfig
1.FasterRCNN实现
配置类:
class FasterRCNNConfig:
def __init__(self,num_classes=80,backbone='resnet50'):
self.backbone = backbone
self.num_classes = num_classes
self.backbone_norm = "FrozenBN"
self.backbone_freeze_at = 2
self.fpn_norm = None
self.fpn_in_features = ["res2", "res3", "res4", "res5"]
self.fpn_in_strides = [4, 8, 16, 32]
self.fpn_out_channels = 256
if self.backbone == 'resnet18' or self.backbone == 'resnet34':
self.fpn_in_channels = [64, 128, 256, 512]
else:
self.fpn_in_channels = [256, 512, 1024, 2048]
if self.backbone == 'resnext101_32x8d' or self.backbone=='resnext50_32x4d':
self.lr_decay_stages = [24, 32]
else:
self.lr_decay_stages = [42, 50]
self.img_mean = [103.530, 116.280, 123.675] # BGR
self.img_std = [57.375, 57.120, 58.395]
self.rpn_stride = [4, 8, 16, 32, 64]
self.rpn_in_features = ["p2", "p3", "p4", "p5", "p6"]
self.rpn_channel = 256
self.rpn_reg_mean = [0.0, 0.0, 0.0, 0.0]
self.rpn_reg_std = [1.0, 1.0, 1.0, 1.0]
self.anchor_scales = [[x] for x in [32, 64, 128, 256, 512]]
self.anchor_ratios = [[0.5, 1, 2]]
self.anchor_offset = 0.5
self.match_thresholds = [0.3, 0.7]
self.match_labels = [0, -1, 1]
self.match_allow_low_quality = True
self.rpn_nms_threshold = 0.7
self.num_sample_anchors = 256
self.positive_anchor_ratio = 0.5
self.rcnn_stride = [4, 8, 16, 32]
self.rcnn_in_features = ["p2", "p3", "p4", "p5"]
self.rcnn_reg_mean = [0.0, 0.0, 0.0, 0.0]
self.rcnn_reg_std = [0.1, 0.1, 0.2, 0.2]
self.pooling_method = "roi_align"
self.pooling_size = (7, 7)
self.num_rois = 512
self.fg_ratio = 0.5
self.fg_threshold = 0.5
self.bg_threshold_high = 0.5
self.bg_threshold_low = 0.0
self.class_aware_box = True
self.rpn_smooth_l1_beta = 0 # use L1 loss
self.rcnn_smooth_l1_beta = 0 # use L1 loss
self.num_losses = 5
self.train_prev_nms_top_n = 2000
self.train_post_nms_top_n = 1000
self.test_prev_nms_top_n = 1000
self.test_post_nms_top_n = 1000
self.test_max_boxes_per_image = 100
self.test_cls_threshold = 0.05
self.test_nms = 0.5
fasterrcnn实现
class FasterRCNN(M.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.backbone_name = {
'resnet18': resnet18,
'resnet34': resnet34,
'resnet50': resnet50,
'resnet101': resnet101,
'resnet152': resnet152,
'resnext101_32x8d': resnext101_32x8d,
'resnext50_32x4d': resnext50_32x4d
}
bottom_up = self.backbone_name[cfg.backbone](
norm=get_norm(cfg.backbone_norm)
)
del bottom_up.fc
self.backbone = FPN(
bottom_up=bottom_up,
in_features=cfg.fpn_in_features,
out_channels=cfg.fpn_out_channels,
norm=cfg.fpn_norm,
top_block=FPNP6(),
strides=cfg.fpn_in_strides,
channels=cfg.fpn_in_channels,
)
self.rpn = RPN(cfg)
self.rcnn = RCNN(cfg)
def preprocess_image(self, image):
padded_image = get_padded_tensor(image, 32, 0.0)
normed_image = (
padded_image
- np.array(self.cfg.img_mean, dtype="float32")[None, :, None, None]
) / np.array(self.cfg.img_std, dtype="float32")[None, :, None, None]
return normed_image
def forward(self, image, im_info, gt_boxes=None):
image = self.preprocess_image(image)
features = self.backbone(image)
if self.training:
return self._forward_train(features, im_info, gt_boxes)
else:
return self.inference(features, im_info)
def _forward_train(self, features, im_info, gt_boxes):
rpn_rois, rpn_losses = self.rpn(features, im_info, gt_boxes)
rcnn_losses = self.rcnn(features, rpn_rois, im_info, gt_boxes)
loss_rpn_cls = rpn_losses["loss_rpn_cls"]
loss_rpn_bbox = rpn_losses["loss_rpn_bbox"]
loss_rcnn_cls = rcnn_losses["loss_rcnn_cls"]
loss_rcnn_bbox = rcnn_losses["loss_rcnn_bbox"]
total_loss = loss_rpn_cls + loss_rpn_bbox + loss_rcnn_cls + loss_rcnn_bbox
loss_dict = {
"total_loss": total_loss,
"rpn_cls": loss_rpn_cls,
"rpn_bbox": loss_rpn_bbox,
"rcnn_cls": loss_rcnn_cls,
"rcnn_bbox": loss_rcnn_bbox,
}
self.cfg.losses_keys = list(loss_dict.keys())
return loss_dict
def inference(self, features, im_info):
rpn_rois = self.rpn(features, im_info)
pred_boxes, pred_score = self.rcnn(features, rpn_rois)
pred_boxes = pred_boxes.reshape(-1, 4)
scale_w = im_info[0, 1] / im_info[0, 3]
scale_h = im_info[0, 0] / im_info[0, 2]
pred_boxes = pred_boxes / F.concat([scale_w, scale_h, scale_w, scale_h], axis=0)
clipped_boxes = get_clipped_boxes(
pred_boxes, im_info[0, 2:4]
).reshape(-1, self.cfg.num_classes, 4)
return pred_score, clipped_boxes
四、模型主入口
本人主要习惯简洁方式,因此主入口的实现过程也是很简单的
if __name__ == "__main__":
# ctu = Ctu_Detection(USEGPU='0',min_size=416,max_size=416)
# ctu.InitModel(DataDir=r'C:\Users\Ctu\Desktop\1\test',train_split=0.9,batch_size=4,Pre_Model=None,backbone='resnet18',network='retinanet', num_workers=0)
# ctu.train(TrainNum=400,learning_rate=0.0001,lr_decay_rate=0.9,ModelPath='result_Model')
ctu = Ctu_Detection(USEGPU='-1')
ctu.LoadModel(r'./BaseModel/ctu_params_retinanet_resnet18.json')
cv2.namedWindow("result", 0)
cv2.resizeWindow("result", 480, 480)
for root, dirs, files in os.walk(r'./BaseModel'):
for f in files:
img_cv = ctu.read_image(os.path.join(root, f))
if img_cv is None:
continue
result = ctu.predict(img_cv,0.5)
print(result['time'])
for each_bbox in result['bboxes_result']:
print(each_bbox)
cv2.imshow("result", result['imges_result'])
cv2.waitKey()
五、效果展示
1.自定义数据集效果展示


2.COCO数据集效果展示
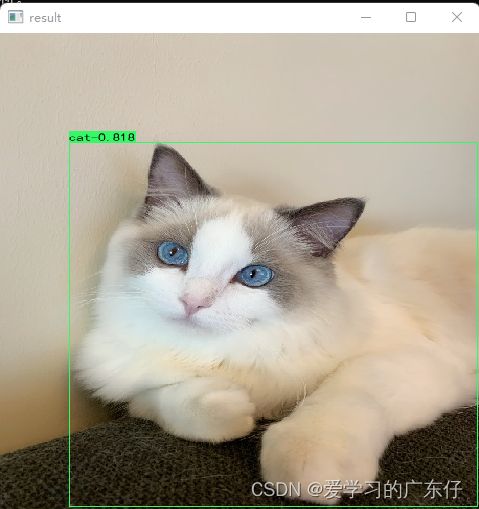

六、COCO各模型免费下载
atts_resnet18
atts_resnet34
atts_resnet50
atts_resnet101
atts_resnext101
fasterrcnn_resnet18
fasterrcnn_resnet34
fasterrcnn_resnet50
fasterrcnn_resnet101
fasterrcnn_resnext101
fcos_resnet18
fcos_resnet34
fcos_resnet50
fcos_resnet101
fcos_resnext101
freeanchor_resnet18
freeanchor_resnet34
freeanchor_resnet50
freeanchor_resnet101
freeanchor_resnext101
retinanet_resnet18
retinanet_resnet34
retinanet_resnet50
retinanet_resnet101
retinanet_resnext101
总结
本文调用方式简单,模型结构丰富,博客只是展示了几个模型结构的实现,对模型感兴趣的或者其他问题的可以私聊