HALCON 21.11:深度学习笔记---对象检测, 实例分割(11)
HALCON 21.11:深度学习笔记---对象检测, 实例分割(11)
HALCON 21.11.0.0中,实现了深度学习方法。
本章介绍了如何使用基于深度学习的对象检测。
通过对象检测,我们希望在图像中找到不同的实例,并将它们分配给一个类。实例可以部分重叠,但仍然可以区分为不同的。下面的模式说明了这一点。
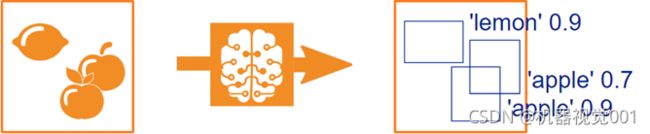
对象检测的例子: 在输入图像中找到三个实例并分配给一个类
实例分割是对象检测的一种特殊情况,在这种情况下,模型还预测一个实例掩码,标记该实例在图像中的特定区域。下面的模式说明了这一点。一般来说,对对象检测的解释也适用于实例分割。在具体的部分中提出了可能的差异。
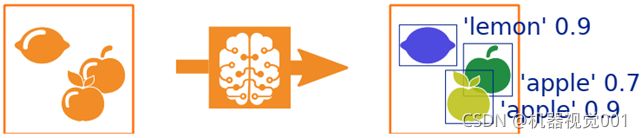
实例分割例子: 在输入图像中发现三个实例。每个实例被分配给一个类,并获得标记其特定区域的掩码
对象检测导致两个不同的任务:找到实例并对它们进行分类。为了做到这一点,我们使用一个由三个主要部分组成的组合网络。
第一部分称为骨干网,由预先训练的分类网络组成。它的任务是生成各种特征图,因此删除了分类层。这些特征图在不同的尺度上编码不同种类的信息,这取决于它们在网络中的深度。请参见深度学习一章。因此,具有相同宽度和高度的地物图被称为同属一层。
第二部分对不同层次的骨干层进行了组合。更准确地说,将不同层次的主干层次指定为对接层。他们的特征图被合并。因此,我们得到了包含较低层次和较高层次信息的特征图。这些是我们将在第三部分中使用的特性映射。第二部分也称为特征金字塔,与第一部分一起构成特征金字塔网络。
第三部分为每一层所选的额外网络,称为头(heads)。他们获得相应的特征图作为输入,并学习如何分别定位和分类潜在对象。此外,这第三部分包括减少重叠预测边框。下面的图显示了这三个部分的概述。
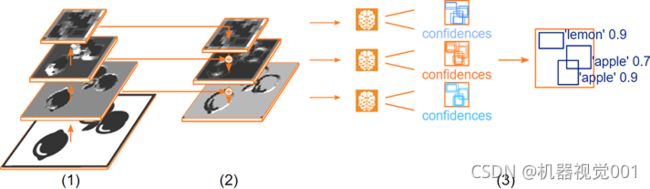
概述了上述三部分的原理图: (1)骨干网。(2)合并主干特征图,生成新的特征图。(3)附加网络,称为头,分别学习如何定位和分类潜在目标。重叠边框被抑制
让我们来看看第三部分发生了什么。在对象检测中,实例在图像中的位置是由矩形边界框给出的。因此,第一个任务是为每个实例找到一个适合的边界框。为了做到这一点,网络生成参考边界框,并学习如何修改它们,使其最适合实例。这些参考边界框称为锚。这些锚越好的表示不同的ground truth边界框的形状,网络就越容易学习它们。为此,网络在每个锚点上生成一组锚点,从而在特征金字塔的使用特征地图的每个像素上生成锚点。这样的一组锚包括形状、大小的所有组合,例如类型“rectangle2”(见下文)以及方向。这些盒子的形状受到参数'anchor_aspect_ratio'的影响,大小受参数'anchor_num_subscales'的影响,方向受参数'anchor_angles'的影响,参见下面的说明和get_dl_model_param。如果参数产生多个相同的锚点,网络内部会忽略这些重复的锚点。
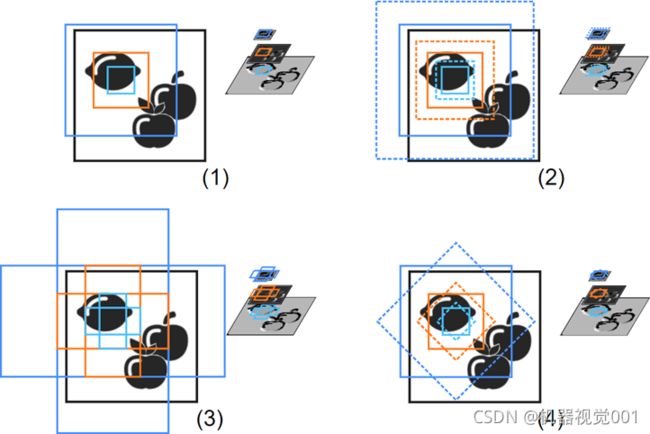
特征映射(右)和输入图像(左)中的锚的模式
(1)锚点在不同级别的特征地图上创建,例如绘制的特征地图(浅蓝色、橙色、深蓝色)
(2)设置'anchor_num_subscales'来创建不同大小的锚点
(3)设置'anchor_aspect_ratio'来创建不同形状的锚点
(4)设置'anchor_angles'来创建不同方向的锚点(仅用于实例类型'rectangle2')
该网络预测了如何修改锚点以获得更好地拟合潜在实例的边界盒。网络通过它的边界盒头学习到这一点,它将为它们的水平生成的锚与相应的ground truth边界盒进行比较,从而得到图像中单个实例的位置信息。下图显示了一个说明。
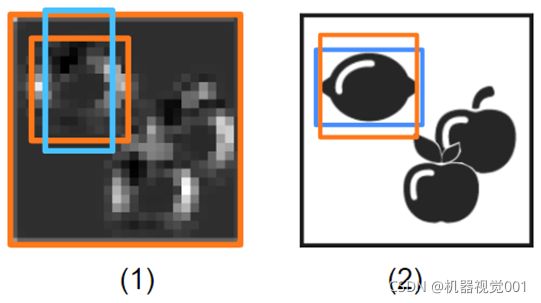
举例说明类型为“rectangle1”的边界框比较
(1)网络修改锚点(浅蓝色)以预测更好拟合的边界框(橙色)
(2)在训练过程中,将预测的边界框(橙色)与重叠最多的ground truth边界框(蓝色)进行比较,使网络能够学习到必要的修改。
如前所述,我们使用了不同层次的特征图。大小取决于你的实例相比总图像有利于包括早期特征图(功能地图不是很压缩,因此小功能仍然可见)和更深层次的特征映射(功能映射非常压缩,只有大型的特性是可见的)。这可以由参数“min_level”和“max_level”控制,它们决定了特征金字塔的级别。
有了这些边界框,我们就有了一个潜在实例的本地化,但实例还没有分类。因此,第二个任务包括在边界框中对图像部分的内容进行分类。这是由类头做的。关于一般分类的更多信息,请参阅深度学习/分类章节和“分类解决方案指南”。
最有可能的是,网络会为单个对象找到几个有希望的边界框。减少重叠预测边界框是通过非最大抑制来完成的,在创建模型或使用set_dl_model_param之后在参数'max_overlap'和'max_overlap_class_agnostic'上设置。下图给出了一个说明。
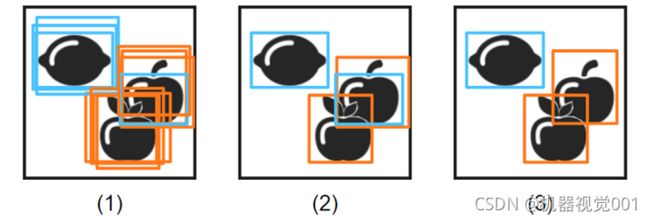
举例说明类型为“rectangle1”的抑制重要重叠边框
(1)网络为类apple(橙色)和lemon(蓝色)找到了几个有希望的实例
(2)相同类的重叠实例抑制由max_overlap设置。不同类的重叠实例不会被抑制
(3)使用参数'max_overlap_class_agnostic',同样强烈重叠的不同类的实例被抑制
作为输出,您会得到建议对象和置信值的可能本地化的边界框,表示此图像部分与其中一个类的相关性。
实例分割的进一步内容如下:一个额外的头部作为输入获得与预测边界框相对应的特征映射的那些部分,由此预测出一个(类不可知的)二值掩模图像。此掩码标记图像中属于预测实例的区域。概览如下。
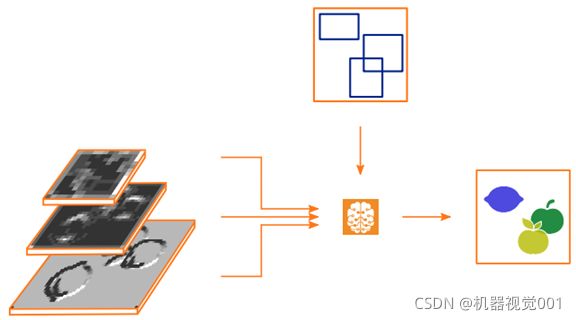
掩模预测的原理图概述。图中使用了上述物体检测网络的三个部分的概述中所示的部分。
在HALCON中,基于深度学习的对象检测是在更通用的深度学习模型中实现的。关于后者的更多信息,请参见深度学习/模型一章。实现了两种不同的对象检测模型实例类型,它们在边界框的方向上不同:
- “rectangle1”实例类型:矩形边框是轴向对齐的。
- “rectangle2”实例类型:矩形边框具有任意方向。
为了应用深度学习,具体的系统要求请参阅HALCON《安装指南》。
以下各节将介绍对象检测所需的一般工作流程,所涉及的数据和参数的相关信息,以及评价措施的说明。
一般工作流程
在本节中,我们描述了基于深度学习的对象检测任务的一般流程。它分为四个部分:模型创建和数据预处理、模型训练、训练模型评估和对推断新图像。因此,我们假设,您的数据集已经标记,参见下面的“数据”部分。看看HDevelop示例系列detect_pills_deep_learning的一个应用程序。
创建模型和数据集预处理
本部分介绍了DL对象检测模型的创建以及该模型的数据适配。在HDevelop示例detect_pills_deep_learning_1_prepare.hdev中也显示了单个步骤。
- 使用create_dl_model_detection函数创建模型。因此,至少必须指定要区分的主干和类的数量。例如分割参数'instance_segmentation'必须被设置来创建一个根据模型。进一步的参数可以在DLModelDetectionParam字典上设置。它们的值应该针对特定的任务进行适当的选择,不仅仅是为了可能减少内存消耗和运行时。有关更多信息,请参阅函数文档。可以使用函数determine_dl_model_detection_param估计适合您的数据集的锚参数。如果数据集不能代表网络在训练期间将面临的所有方向(例如,由于扩展),建议值需要相应地调整。注意,在模型创建之后,它的底层网络体系结构被固定为指定的输入值。作为结果,函数返回一个句柄'DLModelHandle'。或者你也可以使用read_dl_model读取已经用write_dl_model保存的模型。
- 需要读入要在训练数据集的哪个图像上找到的信息。这可以通过读入数据来完成:
使用read_dict读取的DLDataset字典,或
使用函数read_dl_dataset_from_coco读取的一个COCO数据格式的文件,并由此创建一个字典DLDataset。
字典DLDataset充当一个数据库,存储关于您的数据的所有必要信息。要了解更多关于数据及其传输方式的信息,请参阅下面的“数据”一节和深度学习/模型一章。 - 使用函数split_dl_dataset拆分字典DLDataset表示的数据集。产生的分割将在DLDataset的每个样例条目的键分割上保存。
- 网络对图像有一定的要求,比如图像的宽度和高度。您可以使用函数get_dl_model_param检索每个单独的值。或者您可以使用函数create_dl_preprocess_param_from_model检索所有必要的参数。注意,对于由'class_ids_no_orientation'声明的类,边界框需要在预处理期间进行特殊处理。因此,这些类应该最晚在此时设置。现在您可以使用函数preprocess_dl_dataset对数据集进行预处理了。本过程还提供了如何实现定制的预处理过程的指导。我们建议在开始训练之前预处理并存储所有用于训练的图像,因为这可以显著加快训练速度。可用函数dev_display_dl_data对预处理后的数据进行可视化。
模型训练
本部分介绍了DL对象检测模型的训练。在HDevelop示例detect_pills_deep_learning_2_train.hdev中也显示了单个步骤。
- 设置训练参数并将它们存储在字典TrainingParam中。这些参数包括:
超参数,请参阅下面的“模型参数和超参数”一节以及深度学习一章。
用于可能的数据扩充的参数。 - 使用函数train_dl_model训练模型。这个函数包括:模型句柄DLModelHandle、包含DLDataset数据信息的字典、带有训练参数TrainingParam的字典、训练将在多少个epochs进行的信息。在训练过程中,你应该看到总损失是如何最小化的。
评估训练模型
在这一部分中,我们评估了对象检测模型。在HDevelop示例detect_pills_deep_learning_3_evaluate.hdev中也显示了单个步骤。
- 设置可能影响评价的模型参数。
- 使用函数evaluate_dl_model可方便地进行评价。这个函数需要一个包含求值参数的字典GenParamEval。将参数detailed_evaluation设置为“true”,以获得可视化所需的数据。
- 您可以使用函数dev_display_detection_detailed_evaluation可视化您的评估结果。
推理新图像
本部分将介绍DL对象检测模型的应用。在HDevelop示例detect_pills_deep_learning_4_helper .hdev中也显示了单个步骤。
- 使用函数get_dl_model_param或create_dl_preprocess_param_from_model请求网络对图像的要求。
- 使用函数set_dl_model_param设置下面“模型参数和超参数”一节中描述的模型参数。'batch_size'通常可以独立于要推断的图像数量进行设置。有关如何设置此参数以提高效率的详细信息,请参阅apply_dl_model。
- 使用函数gen_dl_samples_from_images为每个图像生成一个数据字典DLSample。
- 使用函数preprocess_dl_samples对每个图像像训练一样进行预处理。
- 使用函数apply_dl_model应用模型。
- 从字典'DLResultBatch'中检索结果。
数据
我们区分用于训练和评估的数据(包含实例信息的图像)和用于推理的数据(裸露图像)。对于第一个类,您提供信息来定义每个实例属于哪个类以及它在图像中的位置(通过它的边界框)。例如,分割对象的像素精确区域是需要的(通过蒙版提供)。
作为一个基本概念,模型通过字典处理数据,这意味着它通过字典DLSample接收输入数据,并分别返回字典DLResult和DLTrainResult。关于数据处理的更多信息可以在深度学习/模型一章中找到。
用于训练和评估的数据
数据集由图像和相应的信息组成。必须以模型能够处理它们的方式提供它们。关于图像要求,请在下面的“图像”部分找到更多信息。
训练数据用于为您的特定任务训练和评估网络。有了这些数据的帮助,网络可以知道哪些类应该被区分,这样的例子是什么样子的,以及如何找到它们。通过告诉每个图像中的每个对象这个对象属于哪个类以及它位于何处,可以提供必要的信息。这是通过为每个对象提供一个类标签和一个边界框来实现的。在实例分割的情况下,每个实例都需要一个掩码。有不同的方法来存储和检索这些信息。在深度学习/模型一章中解释了如何在HALCON中为DL模型格式化数据。简而言之,字典DLDataset可作为训练和评价程序所需信息的数据库。您可以使用MVTec深度学习工具(可从MVTec网站获得)以各自的格式标记您的数据并直接创建字典DLDataset。如果你已经用标准的COCO格式标记了你的数据,你可以使用函数read_dl_dataset_from_coco (仅适用'instance_type' = 'rectangle1')。它格式化数据并创建字典DLDataset。有关COCO数据格式所需部分的进一步信息,请参阅程序的文件。
您还需要足够的训练数据来将其划分为三个子集,用于训练、验证和测试网络。这些子集最好是独立的、同分布的,请参阅深度学习一章中的“数据”一节。
注意,在对象检测中,网络必须学习如何找到实例的可能位置和大小。这就是为什么后面重要的实例位置和大小需要在您的训练数据集中有代表性地出现。
图像
不管应用程序如何,网络都对图像提出了要求,例如图像的尺寸。具体的值取决于网络本身,可以用get_dl_model_param查询。为了满足这些要求,您可能必须对您的图像进行预处理。整个数据集的标准预处理,同时图像也在preprocess_dl_dataset和preprocess_dl_samples中分别为单个样本实现。本过程还提供了如何实现定制的预处理过程的指导。
边界框
根据对象检测模型的实例类型,边界框被参数化的方式不同:
- “rectangle1”实例类型:边界框定义在左上角('bbox_row1', 'bbox_col1')和右下角('bbox_row2', 'bbox_col2')的坐标上。这与gen_rectangle1是一致的。
- “rectangle2”实例类型:边界框定义在它们的中心坐标('bbox_row', 'bbox_col'),方向'Phi'和半边长度'bbox_length1'和'bbox_length2'上。方向以圆弧度量给出,表示水平轴和'bbox_length1'之间的角度(数学上为正)。这与gen_rectangle2是一致的。
如果在‘rectangle2’的情况下,你对定向边界框感兴趣,但是不考虑边界框内对象的方向,参数‘ignore_direction’可以设置为‘true’。下图说明了这一点。
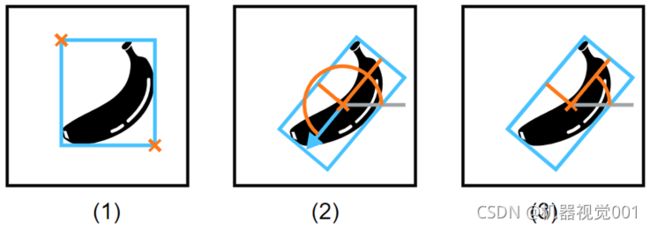
不同对象检测实例类型的边界框格式:
(1) 'rectangle1'实例类型
(2) 'rectangle2'实例类型,其中边框朝向香蕉端
(3) 'rectangle2'实例类型,其中感兴趣的是有方向的边界框,而不考虑香蕉在边界框中的方向
掩码
实例分割除了需要一个紧密的边界框外,还需要为每个要学习的对象提供一个掩码。这样的面具是作为一个区域给出的。注意,这些区域是根据图像给出的。
单个图像的掩码以区域对象元组的形式给出,见下图。掩码的顺序对应于包围框注释的顺序。

图像的掩模说明: tupel包含每个要学习的对象的一个独立区域
网络输出
作为训练输出:函数train_dl_model_batch将返回一个字典DLTrainResult,其中包含总损失的当前值以及模型中包含的所有其他损失的值。
作为推理和评估输出:函数apply_dl_model将为每个图像返回一个字典DLResult。对于对象检测,该字典将包括每个被检测实例的边界框和赋值类的置信值,以及实例分割时的掩码。因此,对于图像中的同一目标,可能会检测到多个实例,参见上面对非最大抑制的解释。生成的边界框根据实例类型(在'instance_type'中指定)进行参数化,并以像素为中心的亚像素精确坐标给出。有关坐标系统的更多信息,请参见“转换/ 2D转换”一章。关于输出字典的更多信息可以在深度学习/模型一章中找到。
模型参数和超参数
除了深度学习中解释的一般DL超参数外,还有一些与对象检测相关的超参数:“bbox_heads_weight”、“class_heads_weight”、“class_weights”、'mask_head_weight' (in case of instance segmentation)。
get_dl_model_param中详细解释了这些超参数,可使用create_dl_model_detection进行设置。
对于一个对象检测模型,有两种不同类型的模型参数:
定义您的模型结构的参数。一旦创建了模型,它们就不能再被更改了。这些参数都是在创建模型时使用create_dl_model_detection函数设置。
影响预测从而影响评估结果的参数。那些只与对象检测相关的是:'mask_threshold' (in case of instance segmentation) 、“max_num_detections”、“max_overlap”、“max_overlap_class_agnostic”、“min_confidence”。
在get_dl_model_param中有更详细的解释。要设置它们,你可以在创建模型时使用create_dl_model_detection,或者在创建模型后使用set_dl_model_param。
对象检测结果的评价方法
对于对象检测,HALCON支持以下评估措施。注意,为了计算图像的这种度量,需要相关的ground truth信息。
Mean average precision, mAP and average precision (AP) of a class for an IoU threshold, ap_iou_classname
AP值是不同召回率下的最大精度的平均值。简单地说,它告诉我们,这类预测的对象通常是正确的检测或不是。因此,我们更关注置信度高的预测。值越高越好。
要将一个预测算作命中,我们需要它的top-1分类和定位都是正确的。这个度量告诉我们定位的正确性是union上的交集IoU:如果IoU高于要求的阈值,实例就被正确定位了。IoU将在下面更详细地解释。由于这个原因,AP值取决于类别和IoU阈值。
您可以获得具体的AP值、类别的平均值、IoU阈值的平均值以及类别和IoU阈值的平均值。后者是平均精度,mAP,一种衡量方法,告诉我们如何找到和分类实例。
True Positives(真阳性), False Positives(假阳性), False Negatives(假阴性)
深度学习解释了真阳性、假阳性和假阴性的概念。它适用于物体检测,但有不同种类的假阳性,如:
- 一个实例分类错误。
- 在只有背景的地方找到了一个实例。
- 实例定位不良,即实例与其基础事实之间的IoU低于评估IoU阈值。
- 有一个重复,因此至少有两个实例主要与相同的ground truth边界框重叠,但它们的重叠不超过彼此的'max_overlap',所以它们都没有被抑制。
注意,这些值只能从详细的计算中获得。这意味着,在evaluate_dl_model中参数detailed_evaluation必须设置为“true”。
角度精度得分(SoAP)
SoAP值是推断的方向角的精度的分数。这个分数是由推断的实例(I)和相应的ground truth annotation (GT)之间的角度差决定的:
![]()
其中索引k运行所有推断的实例。此分数仅适用于'instance_type' = 'rectangle2'的检测模型。
前面提到的度量方法使用交并比(IoU)。IoU是一种测量对象检测准确性的方法。对于一个提出的边界框,它比较与ground truth边界盒的交点面积和重叠面积的比率。下面的模式显示了一个可视化示例。
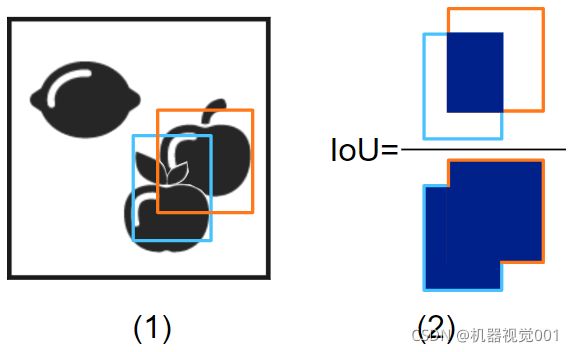
IoU的可视化示例,举例说明类型为'rectangle1'
(1)输入图像的ground truth边界框(橙色)和预测边界框(浅蓝色)
(2)IoU是面积相交与面积重叠的比值
在实例分割的情况下,IoU是根据掩码计算的(默认)。可以改变默认值并使用边界框代替。