pytorch 中使用tensorboard,详解writer.add_embedding函数的作用(一)
首先给出pytorch官方文档对tensorboard的教程
https://pytorch.apachecn.org/docs/1.4/6.html
目录
1 导包
2 实例化
3 显示图片(writer.add_image)
4 查看网络结构(writer.add_image),第一个参数为自定义网络,第二个参数为输入
5 低维映射(writer.add_embedding)
6 查看训练过程中训练情况(writer.add_figure)
1 导包
from torch.utils.tensorboard import SummaryWriter2 实例化
# default `log_dir` is "runs" - we'll be more specific here
writer = SummaryWriter('runs/fashion_mnist_experiment_1')记住这个目录runs,是相对位置,等下需要进到runs所在目录(如a/runs,就要进入a中)执行
tensorboard --logdir runs这里的runs与之前的runs是同一个东西,你如果写runss,这里就改成runss,
3 显示图片(writer.add_image)
writer.add_image('four_fashion_mnist_images', img_grid)第一个参数是名称,第二个参数是要显示的图片(三维tensor,如果是四维小batch tensor会报错,解决方式在图中),小tips:jupyter notebook中使用help函数可以查看函数细节
4 查看网络结构(writer.add_image),第一个参数为自定义网络,第二个参数为输入
writer.add_graph(net, images)#把图写入
writer.close()必须加上close函数,因此建议如下格式
with writer as w:
w.add_graph(net, images)会自动调用close函数

tips:?和help()类似,更好看点
5 低维映射(writer.add_embedding)
writer.add_embedding(features,
metadata=class_labels,
label_img=images.unsqueeze(1))
writer.close()说实话这个函数很抽象,看api不太可能看出来他是在做什么,不信看下图
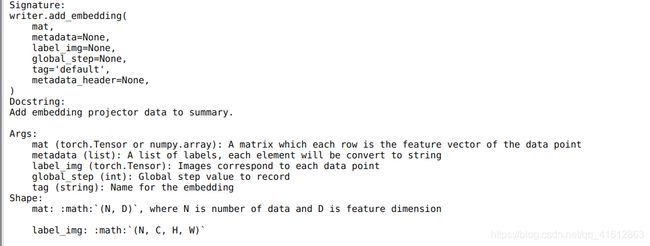 干脆不看,直接看效果图
干脆不看,直接看效果图


截了两个角度,大概看出猫腻了,其实就是在可视化高维数据,三维空间中每一个点都是一个三维tensor,可以通过这个方式观察数据点之间的最近邻关系,这个时候回过头再看参数,加粗部分是说人话系列,根据该例描述其作用
writer.add_embedding(features,
metadata=class_labels,
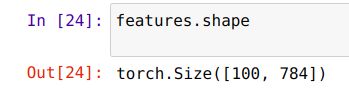
label_img=images.unsqueeze(1))mat (torch.Tensor or numpy.array): 一个矩阵,每行代表特征空间的一个数据点(features:二维tensor,每行代表一张照片的特征,其实就是把一张图片的28*28个像素拉平,一张图片就产生了784个特征)
metadata (list or torch.Tensor or numpy.array, optional): 一个一维列表,mat 中每行数据的 label,大小应和 mat 行数相同(metadata:一维列表,代表每张图片的类别,图中不同颜色代表着不同类别)
label_img (torch.Tensor, optional): 一个形如 NxCxHxW 的张量,对应 mat 每一行数据显示出的图像,N 应和 mat 行数相同
(首先先说images,是一百张图片,features就是这里的特征,但是因为这里是灰度图,所以是N*H*W,api这么设计是为了RGB彩图考虑的,因此我们需要reshape一下,满足api要求,具体看下面)

global_step (int, optional): 训练的 step
tag (string, optional): 数据名称,不同名称的数据将分别展示
6 查看训练过程中训练情况(writer.add_figure)
writer.add_figure('predictions vs. actuals',
plot_classes_preds(net, inputs, labels),
global_step=epoch * len(trainloader) + i)参数为标题,测试结果,测试时长,比如再经过训练1000次(step=1000)时,网络的表现如何?可以使用这个方式
困了睡觉,剩下的丢下一篇继续写咯
pytorch 中使用tensorboard,详解writer.add_pr_curve函数的作用(二)