机器学习实战 ----- 泰坦尼克号生存预测
数据集下载
链接:https://pan.baidu.com/s/1f6x0ZHlAdwch52rHKDYBgA
提取码:9hgz
数据集简介
PassengerId: 乘客ID
Survived: 是否生存,0代表遇难,1代表还活着
Pclass: 船舱等级:1Upper,2Middle,3Lower
Name: 姓名
Sex:性别
Age: 年龄
SibSp: 兄弟姐妹及配偶个数
Parch:父母或子女个数
Ticket: 乘客的船票号
Fare: 乘客的船票价
Cabin: 乘客所在的仓位(位置)
Embarked:乘客登船口岸
代码演示
导入所需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
导入数据集
train = pd.read_csv('E:/persional/数据挖掘/train.csv',engine='python')
test = pd.read_csv('E:/persional/数据挖掘/test.csv',engine='python')
print(np.array(train).shape)#(891, 12)
print(np.array(test).shape)#(418, 11)
train.head()

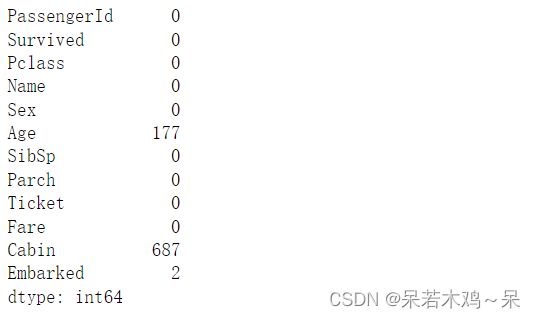
检测缺失值
print(pd.isnull(train).sum())
数据分析
性别分析
#对女性人数进行统计与归一化
train["Survived"][train["Sex"]=='female'].value_counts(normalize=True)
#1 0.742038
#0 0.257962
#对男性人数进行统计与归一化
train["Survived"][train["Sex"]=='male'].value_counts(normalize=True)
#0 0.811092
#1 0.188908
#女性存活率
print(train["Survived"][train["Sex"]=='female'].value_counts(normalize=True)[1]*100)
#74.20382165605095
#男性存活率
print(train["Survived"][train["Sex"]=='male'].value_counts(normalize=True)[1]*100)
#18.890814558058924
sns.barplot(x="Sex",y="Survived",data=train)

父母或子女个数分析
print(train["Survived"][train["Parch"]==0].value_counts(normalize=True)[1]*100)
#34.365781710914455
print(train["Survived"][train["Parch"]==1].value_counts(normalize=True)[1]*100)
#55.08474576271186
print(train["Survived"][train["Parch"]==2].value_counts(normalize=True)[1]*100)
#50.0
print(train["Survived"][train["Parch"]==3].value_counts(normalize=True)[1]*100)
#60.0
sns.barplot(x="Parch",y="Survived",data=train)

年龄分析
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=‘raise’)
plt.figure(figsize=(10,10))
train["Age"] = train["Age"].fillna(-0.5)#填缺失值
test["Age"] = test["Age"].fillna(-0.5)
bins = [-1,0,5,12,18,24,35,60,np.inf]
labels = ['Unknown','Baby','Child','Teenager','Student','Young Adult','Adult','Senior']
#print(pd.cut(train["Age"],bins=bins,labels=labels))
train["AgeGroup"] = pd.cut(train["Age"],bins,labels=labels)
test["AgeGroup"] = pd.cut(train["Age"],bins,labels=labels)
sns.barplot(x="AgeGroup",y="Survived",data=train)

乘客所在的仓位(位置) 分析
# 检查是否不为空值或缺失值
#有空值或缺失值时返回False,否则返回的是True
train["CabinBool"] = (train["Cabin"].notnull().astype('int'))
test["CabinBoll"] = (test["Cabin"].notnull().astype('int'))
#print(train["Cabin"].notnull().astype('int'))
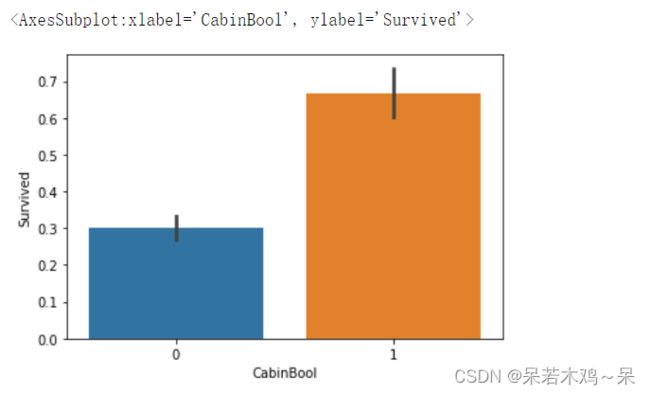
print(train["Survived"][train["CabinBool"]==1].value_counts(normalize=True)[1]*100)
#66.66666666666666
print(train["Survived"][train["CabinBool"]==0].value_counts(normalize=True)[1]*100)
#29.985443959243085
sns.barplot(x="CabinBool",y="Survived",data=train)
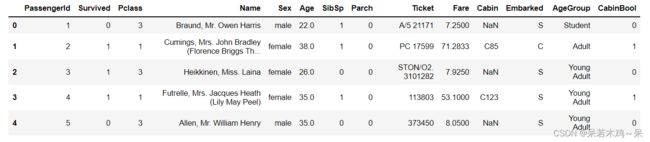
train.head()
#删掉Cabin与TIcket这两列
train = train.drop(["Cabin"],axis=1)
test = test.drop(["Cabin"],axis=1)
train = train.drop(["Ticket"],axis=1)
test = test.drop(["Ticket"],axis=1)

数据预处理
southampton = train[train["Embarked"]=='S'].shape[0]
print(southampton)
#644
cherbourg = train[train["Embarked"]=='C'].shape[0]
print(cherbourg)
#168
queenstown = train[train["Embarked"]=='Q'].shape[0]
print(queenstown)
#77
#添加缺失值
train = train.fillna({"Embarked":"S"})
print(pd.isnull(train["Embarked"]).sum())
#0
combine = [train,test]
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.',expand=False)#对姓名正则化添加到新的列Title
#交叉表
pd.crosstab(train['Title'],train['Sex'])

display(train)

#依据Title对姓名进行等级划分
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady','Capt','Col','Don','Dr','Myjor','Rev','Jonkheer','Dona'],'Rare')
dataset['Title'] = dataset['Title'].replace(['Countess','Lady','Sir'],'Roayal')
dataset['Title'] = dataset['Title'].replace('Mlle','Miss')
dataset['Title'] = dataset['Title'].replace('Ms','Miss')
dataset['Title'] = dataset['Title'].replace('Mme','Mrs')
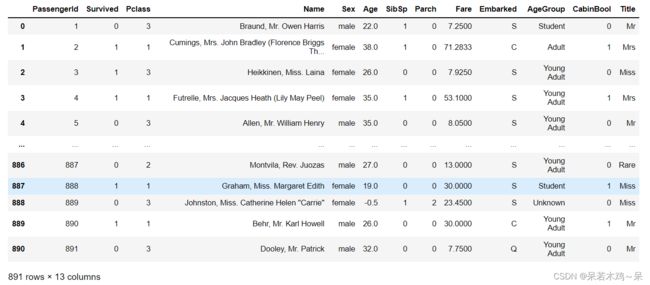
#统计划分好的等级
print(train[['Title','Survived']].groupby(['Title'],as_index=False).count())
#求取平均值
print(train[['Title','Survived']].groupby(['Title'],as_index=False).mean())

display(train)
#对划分好的等级进行映射
title_mapping = {"Mr":1,"Miss":2,"Mrs":3,"Master":4,"Royal":5,"Rare":6}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
display(train['Title'])
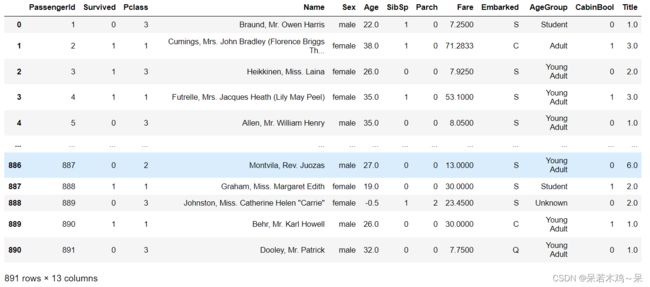
#根据每一个划分好的等级求最多的年龄段即为众数
mr_age = train[train["Title"]==1]["AgeGroup"].mode()#Young Adult
miss_age = train[train["Title"]==2]["AgeGroup"].mode()#Student
mrs_age = train[train["Title"]==3]["AgeGroup"].mode()#Adult
master_age = train[train["Title"]==4]["AgeGroup"].mode()#Baby
royal_age = train[train["Title"]==5]["AgeGroup"].mode()#Adult
rare_age = train[train["Title"]==6]["AgeGroup"].mode()#Adult
# display(train["Title"])
age_title_mapping={1:"Young Adult",2:"Student",3:"Adult",4:"Baby",5:"Adult",6:"Adult"}
#填补Unknown缺失值
for x in range(len(train["AgeGroup"])):
if train["AgeGroup"][x]=="Unknown":
train["AgeGroup"][x]=age_title_mapping[train["Title"][x]]
for x in range(len(test["AgeGroup"])):
if test["AgeGroup"][x]=="Unknown":
test["AgeGroup"][x]=age_title_mapping[test["Title"][x]]
display(train)

#每个年龄段进行映射
age_mapping = {'Baby':1,'Child':2,'Teenager':3,'Student':4,'Young Adult':5,'Adult':6,'Senior':7}
train['AgeGroup'] = train['AgeGroup'].map(age_mapping)
test['AgeGroup'] = test['AgeGroup'].map(age_mapping)
display(train)
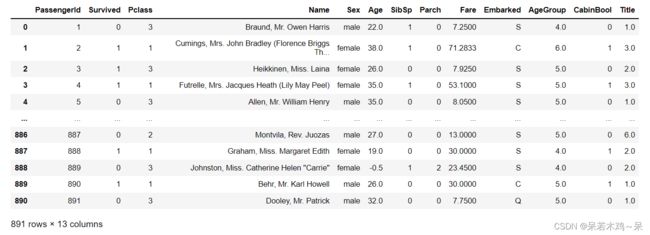
#删除名字这一特征
train = train.drop(['Name'],axis=1)
test = test.drop(['Name'],axis=1)
display(train)

#对性别进行映射
sex_mapping = {'male':0,'female':1}
train['Sex'] = train['Sex'].map(sex_mapping)
test['Sex'] = test['Sex'].map(sex_mapping)
display(train)

#对每个港口进行映射
embarked_mapping = {'S':1,'C':2,'Q':3}
train['Embarked'] = train['Embarked'].map(embarked_mapping)
test['Embarked'] = test['Embarked'].map(embarked_mapping)
display(train)

#填补测试集的船票价格,依据训练集的船舱等级
for x in range(len(test['Fare'])):
if pd.isnull(test['Fare'][x]):
pclass = test['Pclass'][x]
test['Fare'][x] = round(train[train['Pclass']==pclass]['Fare'].mean(),4)
#依据船票划分为四个等级
train['FareBand'] = pd.qcut(train['Fare'],4,labels=[1,2,3,4])
test['FareBand'] = pd.qcut(test['Fare'],4,labels=[1,2,3,4])
display(train['FareBand'])
display(test['FareBand'])

#检查数据
train.head()

test.head()
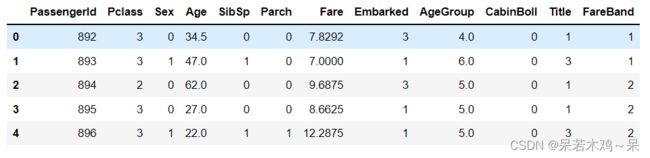
display(train.drop(['Survived','PassengerId'],axis=1))

训练数据
from sklearn.model_selection import train_test_split
predictors = train.drop(['Survived','PassengerId'],axis=1)
target = train['Survived']
X_train,X_val,y_train,y_val = train_test_split(predictors,target,test_size=0.22,random_state=0)
print(X_train.shape)#(694, 11)
print(X_val.shape)#(197, 11)
print(y_train.shape)#(694,)
print(y_val.shape)
#(197,)
分别用不同的模型训练数据,并计算其准确率
GNB
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
gaussian = GaussianNB()
gaussian.fit(X_train,y_train)
y_pred = gaussian.predict(X_val)
acc_gaussian = round(accuracy_score(y_pred,y_val)*100,2)
print(acc_gaussian)#79.7
LR
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(X_train,y_train)
y_pred = logreg.predict(X_val)
acc_logreg = round(accuracy_score(y_pred,y_val)*100,2)
print(acc_logreg)#79.19
SVC
from sklearn.svm import SVC
svc = SVC()
svc.fit(X_train,y_train)
y_pred = svc.predict(X_val)
acc_svc = round(accuracy_score(y_pred,y_val)*100,2)
print(acc_svc)#73.1
Perceptron
from sklearn.linear_model import Perceptron
perceptron = Perceptron()
perceptron.fit(X_train,y_train)
y_pred = perceptron.predict(X_val)
perceptron_logreg = round(accuracy_score(y_pred,y_val)*100,2)
print(perceptron_logreg)#62.44
DT
from sklearn.tree import DecisionTreeClassifier
decisiontree = DecisionTreeClassifier()
decisiontree.fit(X_train,y_train)
y_pred = decisiontree.predict(X_val)
acc_decisiontree = round(accuracy_score(y_pred,y_val)*100,2)
print(acc_decisiontree)#77.16
RF
from sklearn.ensemble import RandomForestClassifier
randomforset = RandomForestClassifier()
randomforset.fit(X_train,y_train)
y_pred = randomforset.predict(X_val)
acc_randomforset = round(accuracy_score(y_pred,y_val)*100,2)
print(acc_randomforset)#86.8
KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
y_pred = knn.predict(X_val)
acc_knn = round(accuracy_score(y_pred,y_val)*100,2)
print(acc_knn)#76.65
GBC
from sklearn.ensemble import GradientBoostingClassifier
gbk = GradientBoostingClassifier()
gbk.fit(X_train,y_train)
y_pred = gbk.predict(X_val)
acc_gbk = round(accuracy_score(y_pred,y_val)*100,2)
print(acc_gbk)#86.8
SGD
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier()
sgd.fit(X_train,y_train)
y_pred = sgd.predict(X_val)
acc_sgd = round(accuracy_score(y_pred,y_val)*100,2)
print(acc_sgd)#77.61
预测结果总结
models = pd.DataFrame({
'Model':['Support Vector Machines', 'KNN', 'Logistic Regression','Random Forest', 'Naive Bayes', 'Perceptron','Decision Tree', 'Stochastic Gradient Descent', 'Gradient Boosting Classifier'],
'Score': [acc_svc, acc_knn, acc_logreg,acc_randomforset, acc_gaussian, perceptron_logreg, acc_decisiontree,acc_sgd, acc_gbk]
})
models.sort_values(by='Score',ascending=False)
准确率结果如下:
