【机器学习】数据增强(Data Augmentation)
文章目录
- 一、引言 - 背景
- 二、为什么需要数据增强?
- 三、什么是数据增强?
-
- 定义
- 分类
- 四、有监督的数据增强
-
- 1. 单样本数据增强
-
- (1)几何变换类
- (2)颜色变换类
- 2. 多样本数据增强
-
- (1)SMOTE
- (2)SamplePairing
- (3)mixup
- 五、无监督的数据增强
-
- 1. GAN
- 2. Conditional GANs
- 3. Autoaugmentation
- 六、数据增强过程中需要注意的问题
- 七、总结
- 参考链接
一、引言 - 背景
很多实际的项目,我们都难以有充足的数据来完成任务,要保证完美的完成任务,有两件事情需要做好:
- 寻找更多的数据。
- 充分利用已有的数据进行数据增强。(本文介绍数据增强)
实际上,你不必寻找新奇的图片增加到你的数据集中。为什么?
因为,神经网络在开始的时候并不是那么聪明。比如,一个欠训练的神经网络会认为这三个如下的网球是不同、独特的图片。但它们是相同的网球,只是被移位(translated)了。

所以,为了获得更多的数据,我们只要对现有的数据集进行微小的改变。比如旋转(flips)、移位(translations)、旋转(rotations)等微小的改变。我们的网络会认为这是不同的图片。
这就是通过简单数据增强就可以丰富我们的数据集的原因。
二、为什么需要数据增强?
一个卷积神经网络,如果能够对物体(即使它放在不同的地方)进行稳健的分类,就被称为具有不变性的属性。
更具体的,CNN可以对移位(translation)、视角(viewpoint)、大小(size)、照明(illumination)(或者以上的组合)具有不变性。
这本质上是数据增强的前提。在现实场景中,我们可能会有一批在有限场景中拍摄的数据集。但是我们的目标应用可能存在于不同的条件,比如在不同的方向、位置、缩放比例、亮度等。我们通过额外合成的数据来训练神经网络来解释这些情况。
如果我有很多的数据,数据增强会有用吗? 是的。它能增加你数据集中相关数据的数据量。这与神经网络的学习方式有关。让我们用一个例子来阐述它。
例子:
在我们的假想数据集中分为两类。左侧为品牌A(Ford),有车为品牌B(Chevrolet):

假设我们有一个数据集,含两种品牌的车,如上所示。我们假设A品牌的车都如上面左侧一样对齐(所有的车头朝向左侧)。同样B如右侧(所有的都朝向右侧)。现在,你将你的数据集送入“最先进的”神经网络,你希望等训练结束后获得令人印象深刻的结果。
Ford车(A品牌)却朝向右侧:

当训练结束后,你将上面的品牌A车的图片送入网络。 但是你的神经网络却认为它是一辆B品牌的车!你很困惑。难道不是刚刚通过这个“最先进的”神经网络获得了95%的准确率吗?
为什么发生了这件事? 它的发生正是很多机器学习算法工作的原理。它会去寻找最能区分两个类别的、最明显的特征。这里,A品牌与B品牌最明显的区别是A都是朝向左侧,B是朝向右侧。
你的神经网络会与你喂给它的数据质量一样好或坏。
我们如何去阻止这件事发生呢? 我们不得不减少数据集中不相关的特征(或者说丰富不相关的特征使其不能成为区别特征)。对于上面的轿车模型分类器,一个简单的方案是增加分别朝向原始方向反向的两种车的图片。更好的方法是,你可以从沿着水平方向翻转图片以便它们都朝着反方向!现在,在新数据集上训练神经网络,你将会获得你想要获得的性能。
通过执行数据增强,你可以阻止神经网络学习不相关的特征,从根本上提升整体性能。
三、什么是数据增强?
定义
数据增强也叫数据扩增,意思是在不实质性的增加数据的情况下,让有限的数据产生等价于更多数据的价值。
举例说明:

比如上图,第1列是原图,后面3列是对第1列作一些随机的裁剪、旋转操作得来。
每张图对于网络来说都是不同的输入,加上原图就将数据扩充到原来的10倍。假如我们输入网络的图片的分辨率大小是256×256,若采用随机裁剪成224×224的方式,那么一张图最多可以产生32×32张不同的图,数据量扩充将近1000倍。虽然许多的图相似度太高,实际的效果并不等价,但仅仅是这样简单的一个操作,效果已经非凡了。
如果再辅助其他的数据增强方法,将获得更好的多样性,这就是数据增强的本质。
分类
- 数据增强可以分为,有监督的数据增强和无监督的数据增强方法。
- 其中有监督的数据增强又可以分为单样本数据增强和多样本数据增强方法。
- 无监督的数据增强分为生成新的数据和学习增强策略两个方向。
四、有监督的数据增强
有监督数据增强,即采用预设的数据变换规则,在已有数据的基础上进行数据的扩增。
它包含单样本数据增强和多样本数据增强。
其中单样本又包括几何操作类,颜色变换类。
1. 单样本数据增强
所谓单样本数据增强,即增强一个样本的时候,全部围绕着该样本本身进行操作,包括几何变换类,颜色变换类等。
(1)几何变换类
几何变换类即对图像进行几何变换,包括翻转,旋转,移位,裁剪,变形,缩放等各类操作,下面展示一些操作的效果。
-
翻转(Flip):水平翻转和垂直翻转
水平翻转类似于做对称,垂直翻转就是翻转180度:

垂直翻转:

-
随机旋转:

-
移位:
移位只涉及沿X或Y方向(或两者)移动图像。在下面的示例中,我们假设图像在其边界之外具有黑色背景,并且被适当地移位。这种增强方法非常有用,因为大多数对象几乎可以位于图像的任何位置。这迫使你的卷积神经网络看到所有角落。

-
裁剪:随机裁剪

-
变形缩放

翻转操作和旋转操作,对于那些对方向不敏感的任务,比如图像分类,都是很常见的操作(在caffe等框架中翻转对应的就是mirror操作)。
翻转和旋转不改变图像的大小,而裁剪会改变图像的大小。通常在训练的时候会采用随机裁剪的方法,在测试的时候选择裁剪中间部分或者不裁剪。
值得注意的是,在一些竞赛中进行模型测试时,一般都是裁剪输入的多个版本然后将结果进行融合,对预测的改进效果非常明显。
以上操作都不会产生失真,而缩放变形则是失真的。
很多的时候,网络的训练输入大小是固定的,但是数据集中的图像却大小不一,此时就可以选择上面的裁剪成固定大小输入或者缩放到网络的输入大小的方案,后者就会产生失真,通常效果比前者差。
- 关于插值(interpolation)的说明
问题:
一个关键性的问题是当旋转之后图像的维数可能并不能保持跟原来一样。
如果你的图片是正方形的,那么以直角旋转将会保持图像大小。如果它是长方形,那么180度的旋转将会保持原来的大小。
但是以更精细的角度旋转图像也会改变最终的图像尺寸。
也就是说,在我们使用随机旋转、移位等方法的时候,会涉及图片边界之外的东西。如果我们使用一种技术迫使我们猜出图像边界之外的东西,会发生什么?在这种情况下,我们需要插入一些信息。
在我们执行转换(可能涉及图片边界之外的信息)后,我们需要保留原始图像大小。由于我们的图像没有关于其边界之外的任何信息,我们需要做出一些假设。通常,假设图像边界之外的空间在每个点都是常数0。因此,当您进行这些转换时,会得到一个未定义图像的黑色区域(从左至右,图像顺时针旋转45度,向右移位,向内缩放):

但是这是个正确的假设吗?在现实世界的情况下,它主要是否定的。图像处理和ML框架有一些标准方法,您可以使用它们来决定如何填充未知空间。它们的定义如下(从左至右,常数,边缘,反射,对称和包裹模式):

1.常数(Constant)
最简单的插值方法是用一些常数值填充未知区域。这可能不适用于自然图像,但可以用于在单色背景下拍摄的图像。
2.边界(Edge)
在边界之后扩展图像的边缘值。此方法适用于温和移位。
3.反射(Reflect)
图像像素值沿图像边界反射。此方法适用于包含树木,山脉等的连续或自然背景。
4.对称(Symmetric)
该方法类似于反射,除了在反射边界处制作边缘像素的副本的事实。通常,反射和对称可以互换使用,但在处理非常小的图像或图案时会出现差异。
5.包裹(Wrap)
图像只是重复超出其边界,就好像它正在平铺一样。这种方法并不像其他方法那样普遍使用,因为它对很多场景都没有意义。
(2)颜色变换类
上面的几何变换类操作,没有改变图像本身的内容,它可能是选择了图像的一部分或者对像素进行了重分布。
如果要改变图像本身的内容,就属于颜色变换类的数据增强了,常见的包括噪声、模糊、颜色变换、擦除、填充等等。
- 基于噪声的数据增强
它就是在原来的图片的基础上,随机叠加一些噪声,最常见的做法就是高斯噪声。
合理性:当您的神经网络试图学习可能无用的高频特征(大量出现的模式)时,通常会发生过度拟合。具有零均值的高斯噪声基本上在所有频率中具有数据点,从而有效地扭曲高频特征。这也意味着较低频率的组件(通常是您的预期数据)也会失真,但你的神经网络可以学会超越它。添加适量的噪音可以增强学习能力。
更复杂一点的就是在面积大小可选定、位置随机的矩形区域上丢弃像素产生黑色矩形块,从而产生一些彩色噪声,以Coarse Dropout方法为代表,甚至还可以对图片上随机选取一块区域并擦除图像信息。
添加Coarse Dropout噪声: - 颜色变换的另一个重要变换是颜色扰动
就是在某一个颜色空间通过增加或减少某些颜色分量,或者更改颜色通道的顺序。
颜色扰动:

另外:
几何变换类,颜色变换类的数据增强方法细致数来还有非常多,推荐给大家一个git项目:
https://github.com/aleju/imgaug
2. 多样本数据增强
不同于单样本数据增强,多样本数据增强方法利用多个样本来产生新的样本,下面介绍几种方法。
(1)SMOTE
SMOTE即Synthetic Minority Over-sampling Technique(合成少数过采样技术),它是通过人工合成新样本来处理样本不平衡问题,从而提升分类器性能。
背景:类不平衡现象指的是数据集中各类别数量不近似相等。如果样本类别之间相差很大,会影响分类器的分类效果。假设小样本数据数量极少,如仅占总体的1%,则即使小样本被错误地全部识别为大样本,在经验风险最小化策略下的分类器识别准确率仍能达到99%,但由于没有学习到小样本的特征,实际分类效果就会很差。
SMOTE方法是基于插值的方法,它可以为小样本类合成新的样本,主要流程为:
(SMOTE通过在小样本类中的样本之间进行插值来生成新样本)
第一步,定义好特征空间,将每个样本对应到特征空间中的某一点,根据样本不平衡比例确定好一个采样倍率N;
第二步,对每一个小样本类样本(x,y),按欧氏距离找出K个最近邻样本,从中随机选取一个样本点,假设选择的近邻点为(xn,yn)。在特征空间中样本点与最近邻样本点的连线段上随机选取一点作为新样本点,满足以下公式:
![]() 第三步,重复以上的步骤,直到大、小样本数量平衡。
第三步,重复以上的步骤,直到大、小样本数量平衡。
图示:
在python中,SMOTE算法已经封装到了imbalanced-learn库中,如下图为算法实现的数据增强的实例,左图为原始数据特征空间图,右图为SMOTE算法处理后的特征空间图。
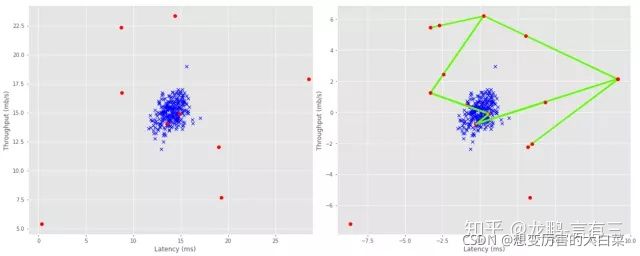
(2)SamplePairing
原理:从训练集中随机抽取两张图片分别经过基础数据增强操作(如随机翻转等)处理后经像素以取平均值的形式叠加合成一个新的样本,标签为原样本标签中的一种。
这两张图片甚至不限制为同一类别,这种方法对于医学图像比较有效。

经SamplePairing处理后可使训练集的规模从N扩增到N×N。
实验结果表明,因SamplePairing数据增强操作可能引入不同标签的训练样本,导致在各数据集上使用SamplePairing训练的误差明显增加,而在验证集上误差则有较大幅度降低。
尽管SamplePairing思路简单,性能上提升效果可观,符合奥卡姆剃刀原理,但遗憾的是可解释性不强。
(3)mixup
mixup是Facebook人工智能研究院和MIT在“Beyond Empirical Risk Minimization”中提出的基于邻域风险最小化原则的数据增强方法,它使用线性插值得到新样本数据。
令(xn,yn)是插值生成的新数据,(xi,yi)和(xj,yj)是训练集随机选取的两个数据,则数据生成方式如下:

λ的取指范围介于0到1。
提出mixup方法的作者们做了丰富的实验,实验结果表明可以改进深度学习模型在ImageNet数据集、CIFAR数据集、语音数据集和表格数据集中的泛化误差,降低模型对已损坏标签的记忆,增强模型对对抗样本的鲁棒性和训练生成对抗网络的稳定性。
SMOTE,SamplePairing,mixup三者思路上有相同之处,都是试图将离散样本点连续化来拟合真实样本分布,不过所增加的样本点在特征空间中仍位于已知小样本点所围成的区域内。如果能够在给定范围之外适当插值,也许能实现更好的数据增强效果。
五、无监督的数据增强
相对于有监督的数据增强方法,无监督的数据增强是更高级的方法。
考虑这样的场景:
现实世界中,自然数据仍然可以存在于上述简单方法无法解释的各种条件下。例如,识别照片中的景观。景观可以是任何东西:冻结苔原,草原,森林等。我们忽略了影响照片表现中的一个重要特征 - 拍摄照片的季节。
如果我们的神经网络不了解某些景观可以在各种条件下(雪,潮湿,明亮等)存在的事实,它可能会将冰冻的湖岸虚假地标记为冰川或湿地作为沼泽。
缓解这种情况的一种方法是添加更多图片,以便我们考虑所有季节性变化。但这是一项艰巨的任务。扩展我们的数据增强概念,想象一下人工生成不同季节的效果有多酷?(条件对抗生成网络 Conditional GANs 来救援!)
无监督的数据增强方法包括两类:
- 通过模型学习数据的分布,随机生成与训练数据集分布一致的图片,代表方法GAN。
- 通过模型,学习出适合当前任务的数据增强方法,代表方法AutoAugment。
1. GAN
关于GAN(generative adversarial networks),请参考我的上一篇文章【机器学习】生成对抗网络 GAN。
它包含两个网络,一个是生成网络,一个是对抗网络,基本原理如下:
(1) G是一个生成图片的网络,它接收随机的噪声z,通过噪声生成图片,记做G(z) 。
(2) D是一个判别网络,判别一张图片是不是“真实的”,即判断图片是真实的还是由G生成的。
GAN训练好的生成器G能生成出以假乱真的图片。
2. Conditional GANs
在没有进入血腥细节的情况下,条件GAN可以将图像从一个域转换为图像到另一个域。
这就是这个神经网络的强大功能!以下是用于将夏季风景照片转换为冬季风景的条件GAN的示例。
使用CycleGAN改变季节:

上述方法是稳健的,但计算密集。更便宜的替代品将被称为神经风格转移(neural style transfer)。
它抓取一个图像(又称“风格”)的纹理、氛围、外观,并将其与另一个图像的内容混合。使用这种强大的技术,产生类似于条件GAN的效果(事实上,这种方法是在cGAN发明之前引入的!)。
3. Autoaugmentation
AutoAugment是Google提出的自动选择最优数据增强方案的研究,这是无监督数据增强的重要研究方向。
它的基本思路是使用增强学习从数据本身寻找最佳图像变换策略,对于不同的任务学习不同的增强方法,流程如下:
- 准备16个常用的数据增强操作。
- 从16个中选择5个操作,随机产生使用该操作的概率和相应的幅度,将其称为一个sub-policy,一共产生5个sub-polices。
- 对训练过程中每一个batch的图片,随机采用5个sub-polices操作中的一种。
- 通过模型在验证集上的泛化能力来反馈,使用的优化方法是增强学习方法。
- 经过80~100个epoch后网络开始学习到有效的sub-policies。
- 之后串接这5个sub-policies,然后再进行最后的训练。
总的来说,就是学习已有数据增强的组合策略,对于门牌数字识别等任务,研究表明剪切和平移等几何变换能够获得最佳效果。
六、数据增强过程中需要注意的问题
在数据增强过程中,有一个需要注意的问题:在使用增强技术时,我们必须确保不增加不相关的数据。
如果我使用数据增强技术,我的机器学习算法会很健壮(robust),对吗?
如果你以正确的方式使用它,那么是的!你问的正确方法是什么?好吧,有时并非所有的增强技术都对数据集有意义。再考虑我们的汽车示例。以下是一些修改图像的方法(原始图像,水平翻转,180度旋转,90度顺时针旋转):

当然,它们是同一辆车的照片,但你的目标应用可能永远不会看到以最后一张图的方向呈现的汽车。
例如,如果你只是想在路上对随机汽车进行分类,那么只有第二张图像才能在数据集上进行分类。但是,如果你拥有一家处理车祸的保险公司,并且你想要确定倒车,破车的车型,那么第三张图片就有意义了。对于上述两种情况,最后一张图像可能没有意义。
七、总结
我们总是在使用有限的数据来进行模型的训练,因此数据增强操作是不可缺少的一环。
从研究人员手工定义数据增强操作,到基于无监督的方法生成数据和学习增强操作的组合,这仍然是一个开放的研究领域,感兴趣的同学可以自行了解更多。
参考链接
- 【技术综述】深度学习中的数据增强方法都有哪些?
- 数据增强(Data Augmentation)