文本情感倾向分析——机器学习模型
一、文本情感倾向分析
1. 内容
通过算法去判断一段文本、评论的情感倾向,从而快速地了解文本原作者的主观情绪。情感分析的结果可以用于舆情监控、信息预测,或用于判断产品的口碑,进而帮助生产者改进产品。
2. 难点
- 文本特征较难提取,文字讨论的主体可能是人、商品、事件。
- 文本较难规范化。
- 词与词之间有联系,关联关系纳入模型中不容易。
- 不带情感色彩的停用词会影响文本情感打分。
- 中文复杂,一个词在不同语境下可能表达完全不一样的情感含义,“冬天能穿多少穿多少,夏天能穿多少穿多少。”
- 不同语义差别巨大,比如“路上小心点”。
- 否定词的存在“我其实不是很喜欢你”。
- 多维情绪识别。
3. 方法
3.1 情感词典
- 质量良好的中文情感词典非常少。
- 不带情感的停用词会影响情感打分。
- 中文博大精深,词性的多变影响准确性。
- 无法结合上下文分析情感。

3.2 高维向量模型
- 解决了多维语义问题。
- 可利用强大的机器学习,深度学习学习模型。
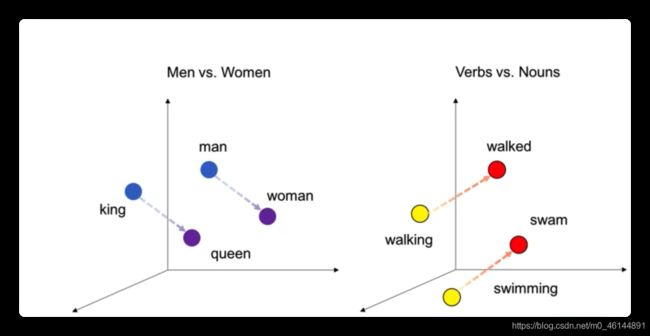
二、向量表示
1. TF-IDF向量表示
1.1 定义
TF-IDF:Term Frequency - Inverse Document Frequency,即“词频-逆文本频率”。它由两部分组成,TF和IDF。TF-IDF是一种加权技术,采用一种统计方法,根据字词在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。
优点:能过滤掉一些常见的却无关紧要的词语,同时保留整个文本的重要词语,简单快速,容易理解。
缺点:
(1)没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
(2)按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
(3)传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
(4)对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
IDF:InversDocument Frequency,表示计算倒文本频率。文本频率是指某个关键词在整个语料所有文章中出现的次数。倒文本频率是文本频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低,而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。比如100篇文章里的某一篇文章大量的出现了“机器学习”,说明“机器学习”是关键词,应该给它较高的权重,而比如100篇文章里100篇都大量出现了“的”,”你“,“我”,说明这是不重要的词。
1.2 TF-IDF的实现
使用sklearn库来计算tfidf值
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
words = ['它由两部分组成,TF和IDF。TF-IDF是一种加权技术,采用一种统计方法,根据字词在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度......']
tfidf_vec = TfidfVectorizer(stop_words={'english'})
"""
相关参数
token_pattern:使用正则表达式进行分词。
max_df/min_df:用于过滤出现太多的无意义词语。
stop_words:list类型,直接过滤指定的停用词。
vocabulary:dict类型,值使用特定的词汇,制定对应关系。
"""
tfidf_maxtrix = tfidf_vec.fit_transform(valid_words)
# 输出generator
print(tfidf_matix)
# 得到语料库所有不重复的词
print(tfidf_vec.get_feature_names())
# 得到每个单词对应的id值
print(tfidf_vec.vocabulary_)
# 得到每个句子对应的向量
print(tfidf_matrix.toarray())
使用jieba实现TF-IDF算法
import jieba.analyse
text='关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作'
keywords=jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=())
print(keywords)
2. Word2Vec 向量表示
2.1 定义
Word2Vec:把每一个单词表示成一个向量,向量在空间中越近则词的含义越近。这些模型一般是基于某种文本中与单词共现相关的统计量来构造。一旦向量表示算出,就可以像使用TF-IDF向量一样使用这些模型。一个比较通用的例子是使用单词的向量表示基于单词的含义计算两个单词的相似度。
2.2 词向量
下图为man、boy、water三个单词用50维向量的热度图表示,可以看到,man和boy有一些相似的地方,在向量空间中相隔比较近。而water与之没有相似之处。简单地说,这个模型可以根据上下文的语境来推断出每个词的词向量,如果两个词在上下文的语境中可以被互相替换,那么这两个词的距离就非常近。
2.3 Word2Vec的实现
from gensim.models.word2vec import Word2Vec
w2v = Word2Vec(x_train,min_count=5,size=n_dim)
w2v.build_vocab(x_train)
w2v.train(x_train_examples=w2v.corpus_count,epochs=10)
三、各种机器学习分类模型
分别使用了SGD、SVM、NB、ANN、LR等九种模型进行分类,并比较各种模型的测试结果。
1. TF-IDF & SGD
1.1 代码演示
from typing import List
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import SGDClassifier
from sklearn.svm import SVC
import pickle
import jieba
import os
import re
import string
file_path1 = '../dataset/train/neg.txt'
file_path2 = '../dataset/train/pos.txt'
# 训练分词
def train_fenci():
list_words = []
test_text = open(file_path1, 'r', encoding='utf-8').readlines()
for line in test_text:
# 清洗数据
text = ''.join(line.split())
# 实现目标文本中对正则表达式中的模式字符串进行替换
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()~-]+", "", text)
# 利用jieba包自动对处理后的文本进行分词
test_list = jieba.cut(text, cut_all=False)
# 得到所有分解后的词
list_words.append(' '.join(test_list))
test_text = open(file_path2, 'r', encoding='utf-8').readlines()
for line in test_text:
# 清洗数据
text = ''.join(line.split())
# 实现目标文本中对正则表达式中的模式字符串进行替换
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()~-]+", "", text)
# 利用jieba包自动对处理后的文本进行分词
test_list = jieba.cut(text, cut_all=False)
# 得到所有分解后的词
list_words.append(' '.join(test_list))
return list_words
# 测试分词
def test_fenci():
FindPath1 = '../dataset/test/pos.txt_utf8'
neg_words = []
lines = open(FindPath1, 'r', encoding='utf-8').readlines()
for line in lines:
temp = ''.join(line.split())
# 实现目标文本中对正则表达式中的模式字符串进行替换
temp = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()~-]+", "", temp)
# 利用jieba包自动对处理后的文本进行分词
temp_list = jieba.cut(temp, cut_all=False)
# 得到所有分解后的词
neg_words.append(' '.join(temp_list))
return neg_words
if __name__ == '__main__':
tfidf_vect = TfidfVectorizer(analyzer='word', stop_words=['我', '你', '是', '的', '在', '这里'])
train_tfidf = tfidf_vect.fit_transform(train_fenci())
test_tfidf = tfidf_vect.transform(test_fenci())
# words = tfidf_vect.get_feature_names()
# print(words)
# print(train_tfidf)
# print(len(words))
# print(train_tfidf)
# print(tfidf_vect.vocabulary_)
lr = SGDClassifier(loss='log', penalty='l1')
lr.fit(train_tfidf, ['neg'] * len(open(file_path1, 'r', encoding='utf-8').readlines()) +
['pos'] * len(open(file_path2, 'r', encoding='utf-8').readlines()))
y_pred = lr.predict(test_tfidf)
print(y_pred)
# 统计结果和准确率
sum_counter = 0
pos_counter = 0
neg_counter = 0
for i in y_pred:
sum_counter += 1
if i == 'pos':
pos_counter += 1
else:
neg_counter += 1
print("总测试语句数:", sum_counter)
print("积极语句数:", pos_counter)
print("消极语句数:", neg_counter)
# model = SVC(kernel='rbf',verbose=True)
# model.fit(train_tfidf,['neg']*3000+['pos']*3000)
# model.predict(test_tfidf)
1.2 预测结果分析
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:
2. TF-IDF && SVM
2.1 代码演示
使用SVM模型:
from sklearn.svm import SVC
lr = SVC(kernel='rbf', verbose=True)
2.2 预测结果分析
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:

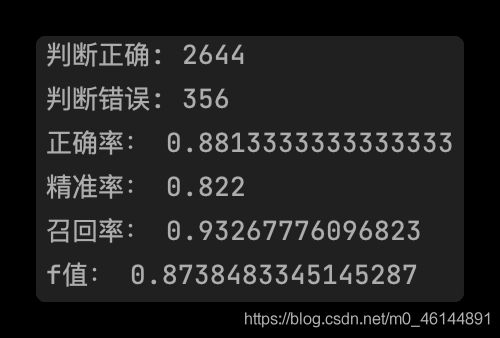
3. TF-IDF & NB
3.1 代码演示
使用朴素贝叶斯模型:
from sklearn.naive_bayes import MultinomialNB
lr = MultinomialNB()
3.2 预测结果分析
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:
4. TF-IDF & ANN
4.1 代码演示
使用人工神经网络模型:
from sklearn.neural_network import MLPClassifier
lr = MLPClassifier(hidden_layer_sizes=1, activation='logistic', solver='lbfgs', random_state=0)
4.2 预测结果分析
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:

5. TF-IDF & LR
5.1 代码演示
使用逻辑回归模型:
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=1, penalty='l2')
5.2 预测结果分析
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:

6. Word2Vec & SVM
6.1 代码演示
import jieba # 结巴分词
import numpy as np # numpy处理向量
import pandas as pd
neg = pd.read_excel('data/neg.xls',head = None) # 读取负面词典
pos = pd.read_excel('data/pos.xls',head = None) # 读取正面词典
neg['words'] = neg[0].apply(lambda x: jieba.lcut(x)) # 负面词典分词
pos['words'] = pos[0].apply(lambda x: jieba.lcut(x)) # 正面词典分词
x = np.concatenate((pos['words'],neg['words'])) # 将原句子丢弃掉,并合并正面和负面分词结果
y = np.concatenate((np.ones(len(pos)),np.zeros(len(neg)))) # 向量空间,1表示positive,0表示negative
from gensim.models.word2vec import Word2Vec # 使用Word2Vec包
w2v = Word2Vec(size=300, min_count=10) # 初始化高维向量空间,300个维度,一个词出现的次数小于10则丢弃
w2v.build_vocab(x) # build高维向量空间
w2v.train(x,total_examples=w2v.corpus_count,epochs=w2v.iter) # 训练,获取到每个词的向量
w2v.save(u'w2v_model.model') # 保存训练好的模型
def total_vec(words): # 获取整个句子的向量
w2v = Word2Vec.load('w2v_model.model')
vec = np.zeros(300).reshape((1,300))
for word in words:
try:
vec += w2v.wv[word].reshape((1,300))
except KeyError:
continue
return vec
train_vec = np.concatenate([total_vec(words) for words in x]) # 计算每一句的向量,得到用于训练的数据集,用来训练高维向量模型
from sklearn.externals import joblib
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
model = SVC(kernel='rbf',verbose=True)
model.fit(train_vec,y) # 训练SVM模型
joblib.dump(model,'svm_model.pkl') # 保存训练好的模型
# 对测试数据进行情感判断
def svm_predict():
df = pd.read_csv("comments.csv") # 读取测试数据
model = joblib.load('svm_model.pkl') # 读取支持向量机模型
comment_setiment = []
sum = 0;
pos_counter = 0;
neg_counter = 0;
for string in df['评论内容']:
sum += 1;
# 对评论分词
words = jieba.lcut(str(string))
words_vec = total_vec(words)
result = model.predict(word_vec)
comment_sentiment.append('积极' if int(result[0]) else '消极')
if sum_counter < 1500:
if int(result[0]) == 1:
right += 1
else:
wrong += 1
else:
if int(result[0]) == 0:
right += 1
else:
wrong += 1
sum_counter += 1
result = right / sum_counter
print("判断正确:", right)
print("判断错误:", wrong)
print("准确率:", result)
svm_pridict()
6.2 预测准确率
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:

7. Word2Vec & SGD
7.1 代码演示
from sklearn.linear_model import SGDClassifier
model = SGDClassifier(loss='log', penalty='l1')
7.2 预测准确率
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:

8. Word2Vec & NB
8.1 代码演示
from sklearn.naive_bayes import BernoulliNB
model = BernoulliNB()
8.2 预测准确率
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:

. Word2Vec & ANN
9.1 代码演示
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(hidden_layer_sizes=1, activation='logistic', solver='lbfgs', random_state=0)
9.2 预测准确率
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:

10. Word2Vec & LR
10.1 代码演示
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(C=1, penalty='l2')
10.2 预测准确率
在3000条测试语句(1500条积极,1500条消极)中,测试结果如下:

四、各种机器学习模型评估结果
4.1 某购物网站评论语料
采用20000条(10000条积极,10000条消极)来自某购物网站的评论语句作为训练集,3000条作为测试集,各种模型的测试结果如下:
| 模型 | 测试(条) | 判断正确(条) | 精准率(precision) | 召回率(recall) | F1-score |
|---|---|---|---|---|---|
| TF-IDF & SGD | 3000 | 2490 | 0.7853 | 0.8624 | 0.8221 |
| TF-IDF & SVM | 3000 | 2762 | 0.8760 | 0.9619 | 0.9170 |
| TF-IDF & NB | 3000 | 2644 | 0.8220 | 0.9327 | 0.8738 |
| TF-IDF & ANN | 3000 | 2714 | 0.8833 | 0.9227 | 0.9026 |
| TF-IDF & LR | 3000 | 2658 | 0.8440 | 0.9214 | 0.8810 |
| TF-IDF & DT | 3000 | 2558 | 0.8073 | 0.8878 | 0.8457 |
| TF-IDF & RF | 3000 | 2630 | 0.8233 | 0.9216 | 0.8697 |
| TF-IDF & AdaBoost | 3000 | 2276 | 0.6747 | 0.8109 | 0.7365 |
| TF-IDF & GBM | 3000 | 2324 | 0.6447 | 0.8712 | 0.7410 |
| Word2Vec & SGD | 3000 | 2279 | 0.8933 | 0.7049 | 0.7880 |
| Word2Vec & SVM | 3000 | 2611 | 0.8233 | 0.9088 | 0.8639 |
| Word2Vec & NB | 3000 | 2094 | 0.7040 | 0.6957 | 0.6998 |
| Word2Vec & ANN | 3000 | 2439 | 0.8146 | 0.8120 | 0.8133 |
| Word2Vec & LR | 3000 | 2498 | 0.7900 | 0.8637 | 0.8252 |
| Word2Vec & DT | 3000 | 2586 | 0.8080 | 0.9058 | 0.8541 |
| Word2Vec & RF | 3000 | 2608 | 0.8153 | 0.9141 | 0.8619 |
| Word2Vec & AdaBoost | 3000 | 2600 | 0.8107 | 0.9129 | 0.8588 |
| Word2Vec & GBM | 3000 | 2609 | 0.8167 | 0.9135 | 0.8624 |
五、使用情感词典优化
在机器学习的模块中加入情感词典,对测试样本进行情感词典的判断,得出 样本中每个数据的情感倾向。在机器学习的模型对测试样本进行判断之中加入情 感词典的判断结果,从而辅助机器学习对样本的判断,可以有效提高判断的准确率。
| 模型 | 测试(条) | 判断正确(条) | 精准率(precision) | 召回率(recall) | F1-score |
|---|---|---|---|---|---|
| TF-IDF & SGD | 3000 | 2791 | 0.9647 | 0.9027 | 0.9326 |
| TF-IDF & SVM | 3000 | 2927 | 0.9800 | 0.9716 | 0.9758 |
| TF-IDF & NB | 3000 | 2886 | 0.9740 | 0.9512 | 0.9625 |
| TF-IDF & ANN | 3000 | 2899 | 0.9860 | 0.9487 | 0.9670 |
| TF-IDF & LR | 3000 | 2869 | 0.9733 | 0.9413 | 0.9570 |
| Word2Vec & SGD | 3000 | 2720 | 0.9873 | 0.8502 | 0.9136 |
| Word2Vec & SVM | 3000 | 2889 | 0.9827 | 0.9455 | 0.9637 |
| Word2Vec & NB | 3000 | 2687 | 0.9780 | 0.8397 | 0.9036 |
| Word2Vec & ANN | 3000 | 2816 | 0.9840 | 0.9022 | 0.9413 |
| Word2Vec & LR | 3000 | 2839 | 0.9787 | 0.9192 | 0.9480 |
参考:https://www.bilibili.com/video/BV16t411d7ZY