数字图像与机器视觉基础补充(1)
文章目录
- 一、相关概念
-
- 1.位图||矢量图
- 2.常见图像格式
- 3.BMP文件结构
- 二、文件格式变换与比较
-
- 1.格式转化
- 2.对比
- 三、图片处理编程
-
- 1.奇异函数分解(SDV)
- 2.图像的开闭运算(腐蚀-膨胀)
- 3.图像梯度、开闭、轮廓运算
- 四、总结
- 参考链接
一、相关概念
1.位图||矢量图
①位图图像(bitmap),亦称为点阵图像或栅格图像,是由称作像素(图片元素)的单个点组成的。这些点可以进行不同的排列和染色以构成图样。当放大位图时,可以看见赖以构成整个图像的无数单个方块。扩大位图尺寸的效果是增大单个像素,从而使线条和形状显得参差不齐。然而,如果从稍远的位置观看它,位图图像的颜色和形状又显得是连续的。用数码相机拍摄的照片、扫描仪扫描的图片以及计算机截屏图等都属于位图。位图的特点是可以表现色彩的变化和颜色的细微过渡,产生逼真的效果,缺点是在保存时需要记录每一个像素的位置和颜色值,占用较大的存储空间。
②矢量图,也称为面向对象的图像或绘图图像,在数学上定义为一系列由点连接的线。矢量文件中的图形元素称为对象。每个对象都是一个自成一体的实体,它具有颜色、形状、轮廓、大小和屏幕位置等属性。
矢量图是根据几何特性来绘制图形,矢量可以是一个点或一条线,矢量图只能靠软件生成,文件占用内在空间较小,因为这种类型的图像文件包含独立的分离图像,可以自由无限制的重新组合。它的特点是放大后图像不会失真,和分辨率无关,适用于图形设计、文字设计和一些标志设计、版式设计等。
2.常见图像格式
常见的图像文件格式有:BMP、JPG(JPE,JPEG)、GIF、PNG等。
我们主要来看BMP:BMP图像文件(Bitmap-File)格式是Windows采用的图像文件存储格式,在Windows环境下运行的所有图像处理软件都支持这种格式。Windows 3.0以后的BMP文件都是指设备无关位图(DIB,device-independent bitmap)。BMP位图文件默认的文件扩展名是.BMP,有时它也会以.DIB或.RLE作扩展名。
3.BMP文件结构
BMP文件由4部分组成:
1.位图文件头(bitmap-file header)
2.位图信息头(bitmap-informationheader)
3.颜色表(color table)
4.颜色点阵数据(bits data)
注意:24位真彩色位图没有颜色表,所以只有1、2、4这三部分。
打开一张bmp图片,发现是32位真彩色。
图像大小:14.6MB×1024≈14950KB(不包含头文件信息大小)

①位图文件头

注意 Windows的数据是倒着念的,这是PC电脑的特色。如果一段数据为50 1A 25 3C,倒着念就是3C 25 1A50,即0x3C251A50。因此,如果bfSize的数据为36 00 0C 00,实际上就成了0x000C0036,也就是0xC0036。
②位图信息头
位图信息头共40字节,这里就不一一叙述了,我们主要来看位图的高度和宽度,题目以像素为单位各占四个字节
③颜色表
如果位图是16位、24位和32位色,则图像文件中不保留调色板,即不存在调色板,图像的颜色直接在位图数据中给出。
16位图像使用2字节保存颜色值,常见有两种格式:5位红5位绿5位蓝和5位红6位绿5位蓝,即555格式和565格式。555格式只使用了15位,最后一位保留,设为0。
24位图像使用3字节保存颜色值,每一个字节代表一种颜色,按红、绿、蓝排列。
32位图像使用4字节保存颜色值,每一个字节代表一种颜色,除了原来的红、绿、蓝,还有Alpha通道,即透明色。
如果图像带有调色板,则位图数据可以根据需要选择压缩与不压缩,如果选择压缩,则根据BMP图像是16色或256色,采用RLE4或RLE8压缩算法压缩。
④颜色点阵数据
位图全部的像素,是按照自下向上,自左向右的顺序排列的。
RGB数据也是倒着念的,原始数据是按B、G、R的顺序排列的。
二、文件格式变换与比较
1.格式转化
①使用PS转化为32,16位位图
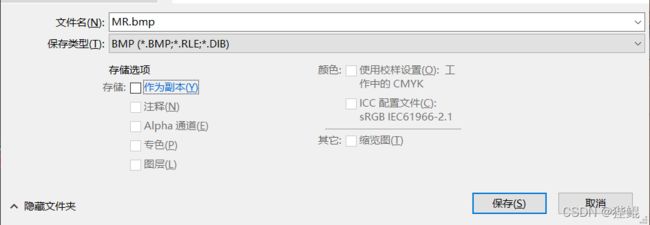

②使用画图转化为256/16/单色位图,另存为即可
2.对比
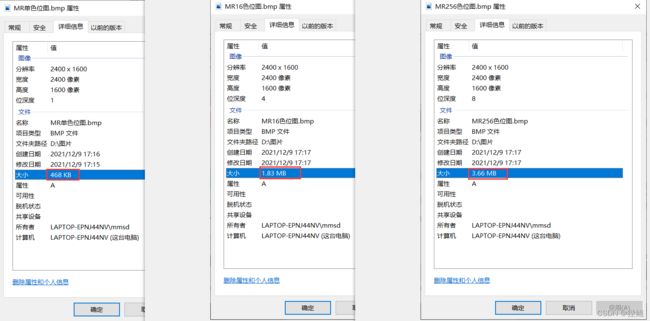
①16位,32位位图对比,可以发现,图片看不出有什么大的不同,但是大小压缩了将近一半


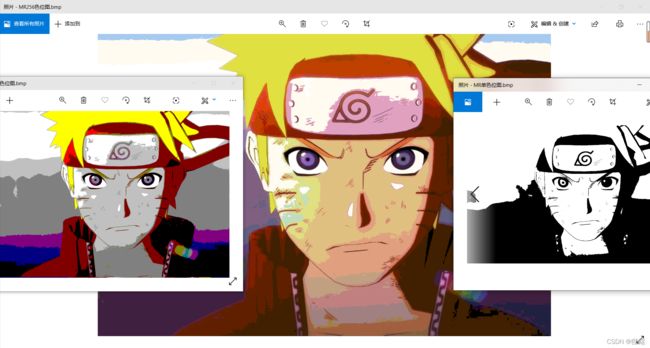
②256/16/单色位图对比
同样的,色位越少,大小越小,图片有明显变化
③不同图片格式的压缩比
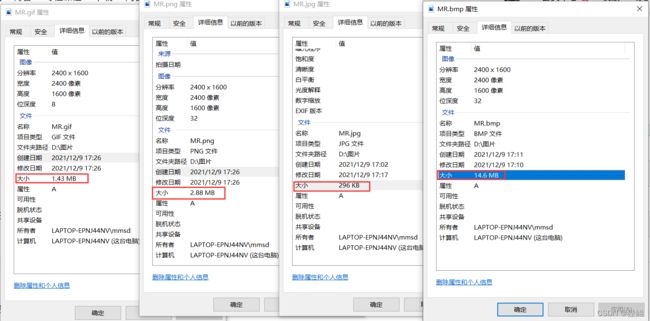
| 图片格式 | 图片大小 | 压缩比 |
|---|---|---|
| BMP | 14.6MB | ---- |
| PNG | 2.88MB | 80.2% |
| GIF | 1.43MB | 88.4% |
| JPG | 296KB | 91.2% |
三、图片处理编程
1.奇异函数分解(SDV)
代码及运行结果,可以看到随着奇异值减小图片越来越模糊。
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib as mpl
from pprint import pprint
def restore1(sigma, u, v, K): # 奇异值、左特征向量、右特征向量
m = len(u)
n = len(v[0])
a = np.zeros((m, n))
for k in range(K):
uk = u[:, k].reshape(m, 1)
vk = v[k].reshape(1, n)
a += sigma[k] * np.dot(uk, vk)
a[a < 0] = 0
a[a > 255] = 255
# a = a.clip(0, 255)
return np.rint(a).astype('uint8')
def restore2(sigma, u, v, K): # 奇异值、左特征向量、右特征向量
m = len(u)
n = len(v[0])
a = np.zeros((m, n))
for k in range(K+1):
for i in range(m):
a[i] += sigma[k] * u[i][k] * v[k]
a[a < 0] = 0
a[a > 255] = 255
return np.rint(a).astype('uint8')
if __name__ == "__main__":
A = Image.open("D:/try45/MR/MR.jpg", 'r')
print(A)
output_path = r'./SVD_Output'
if not os.path.exists(output_path):
os.mkdir(output_path)
a = np.array(A)
print(a.shape)
K = 50
u_r, sigma_r, v_r = np.linalg.svd(a[:, :, 0])
u_g, sigma_g, v_g = np.linalg.svd(a[:, :, 1])
u_b, sigma_b, v_b = np.linalg.svd(a[:, :, 2])
plt.figure(figsize=(11, 9), facecolor='w')
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False
for k in range(1, K+1):
print(k)
R = restore1(sigma_r, u_r, v_r, k)
G = restore1(sigma_g, u_g, v_g, k)
B = restore1(sigma_b, u_b, v_b, k)
I = np.stack((R, G, B), axis=2)
Image.fromarray(I).save('%s\\svd_%d.png' % (output_path, k))
if k <= 12:
plt.subplot(3, 4, k)
plt.imshow(I)
plt.axis('off')
plt.title('奇异值个数:%d' % k)
plt.suptitle('SVD与图像分解', fontsize=20)
plt.tight_layout()
# plt.subplots_adjust(top=0.9)
plt.show()
2.图像的开闭运算(腐蚀-膨胀)
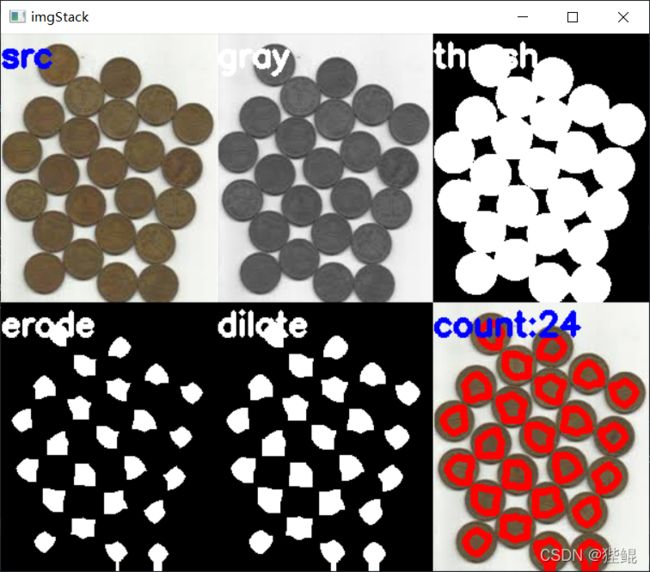
通过对彩色图片灰度化,二值化,腐蚀,再膨胀,往复几次就可以较为清晰的得到图片中物体的轮廓。借助于此原理可以进行条形码识别等应用。
代码
import cv2
import numpy as np
def stackImages(scale, imgArray):
"""
将多张图像压入同一个窗口显示
:param scale:float类型,输出图像显示百分比,控制缩放比例,0.5=图像分辨率缩小一半
:param imgArray:元组嵌套列表,需要排列的图像矩阵
:return:输出图像
"""
rows = len(imgArray)
cols = len(imgArray[0])
rowsAvailable = isinstance(imgArray[0], list)
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]),
None, scale, scale)
if len(imgArray[x][y].shape) == 2: imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank] * rows
hor_con = [imageBlank] * rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None, scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor = np.hstack(imgArray)
ver = hor
return ver
#读取图片
src = cv2.imread("D:/try45/MR/YB.png")
img = src.copy()
#灰度
img_1 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#二值化
ret, img_2 = cv2.threshold(img_1, 127, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
#腐蚀(腐蚀主要为了把每个硬币区分开。过大会造成缺失,过低会无法区分开。参数可以自己设置以达到合适。)
kernel = np.ones((17, 17), int)
img_3 = cv2.erode(img_2, kernel, iterations=1)
#膨胀(膨胀到合适的值,这样每一个白色区域就是一个硬币。)
kernel = np.ones((3, 3), int)
img_4 = cv2.dilate(img_3, kernel, iterations=1)
#找到硬币中心
contours, hierarchy = cv2.findContours(img_4, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)[-2:]
#标识硬币
cv2.drawContours(img, contours, -1, (0, 0, 255), 5)
#显示图片
cv2.putText(img, "count:{}".format(len(contours)), (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(src, "src", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_1, "gray", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_2, "thresh", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_3, "erode", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_4, "dilate", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
imgStack = stackImages(1, ([src, img_1, img_2], [img_3, img_4, img]))
cv2.imshow("imgStack", imgStack)
cv2.waitKey(0)
硬币识别结果。
细胞识别结果。
3.图像梯度、开闭、轮廓运算
对图片中的条形码进行定位提取;再调用条码库获得条码字符
代码
import cv2
import numpy as np
import imutils
from pyzbar import pyzbar
def stackImages(scale, imgArray):
"""
将多张图像压入同一个窗口显示
:param scale:float类型,输出图像显示百分比,控制缩放比例,0.5=图像分辨率缩小一半
:param imgArray:元组嵌套列表,需要排列的图像矩阵
:return:输出图像
"""
rows = len(imgArray)
cols = len(imgArray[0])
rowsAvailable = isinstance(imgArray[0], list)
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]),
None, scale, scale)
if len(imgArray[x][y].shape) == 2: imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank] * rows
hor_con = [imageBlank] * rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None, scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor = np.hstack(imgArray)
ver = hor
return ver
#读取图片
src = cv2.imread("D:/try45/MR//TXM2.jpg")
img = src.copy()
#灰度
img_1 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#高斯滤波
img_2 = cv2.GaussianBlur(img_1, (5, 5), 1)
#Sobel算子
sobel_x = cv2.Sobel(img_2, cv2.CV_64F, 1, 0, ksize=3)
sobel_y = cv2.Sobel(img_2, cv2.CV_64F, 0, 1, ksize=3)
sobel_x = cv2.convertScaleAbs(sobel_x)
sobel_y = cv2.convertScaleAbs(sobel_y)
img_3 = cv2.addWeighted(sobel_x, 0.5, sobel_y, 0.5, 0)
#均值方波
img_4 = cv2.blur(img_3, (5, 5))
#二值化
ret, img_5 = cv2.threshold(img_4, 127, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
#闭运算
kernel = np.ones((18, 18), int)
img_6 = cv2.morphologyEx(img_5, cv2.MORPH_CLOSE, kernel)
#开运算
kernel = np.ones((100,100), int)
img_7 = cv2.morphologyEx(img_6, cv2.MORPH_OPEN, kernel)
#绘制条形码区域
contours = cv2.findContours(img_7, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
c = sorted(contours, key = cv2.contourArea, reverse = True)[0]
rect = cv2.minAreaRect(c)
box = cv2.cv.BoxPoints(rect) if imutils.is_cv2() else cv2.boxPoints(rect)
box = np.int0(box)
cv2.drawContours(img, [box], -1, (0,255,0), 6)
#显示图片信息
cv2.putText(img, "results", (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_1, "gray", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_2, "GaussianBlur",(40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_3, "Sobel", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_4, "blur", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_5, "threshold", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_6, "close", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_7, "open", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
#输出条形码
barcodes = pyzbar.decode(src)
for barcode in barcodes:
barcodeData = barcode.data.decode("utf-8")
cv2.putText(img, barcodeData, (50, 70), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 3)
#显示所有图片
imgStack = stackImages(0.5, ([img_1, img_2,img_3,img_4],[img_5,img_6,img_7,img]))
cv2.imshow("imgStack", imgStack)
cv2.waitKey(0)

四、总结
在本次实验中,学到了各种图片格式以及他们各自的特点,了解了他们在内存中各自所占的大小。学会了图像处理,利用奇异值分解,图像的开闭、轮廓运算等方法。
参考链接
Python与OpenCV图像处理-概述
10个步骤检测出图片中条形码