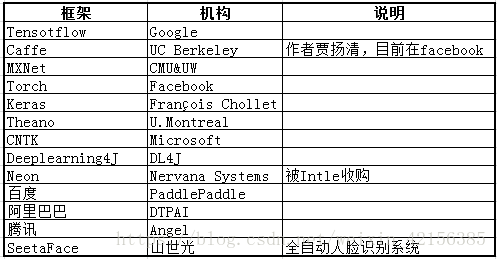
AI三驾马车之深度学习框架
[转] http://www.leiphone.com/news/201611/KTwbq22oseK6B6iJ.html
导语:本文是微软美国总部机器学习科学家彭河森博士在雷锋网硬创公开课的分享,由雷锋网旗下栏目“AI科技评论”整理。
这里说的深度学习框架,主要是指开源的框架。原文彭河森老师讲的非常清晰具体,这里摘录要点进行整理。
一、深度学习开源平台的 5 大参考标准
今天主要探讨的平台(或者软件)包括:Caffe, Torch, MXNet, CNTK, Theano, TensorFlow, Keras。
如何选择一个深度学习平台?我总结出了下面的这些考量标准。因人而异,因项目而异。可能你是做图像处理,也可能是自然语言处理,或是数量金融,根据你不同的需求,对平台做出的选择可能会不同。
标准1:与现有编程平台、技能整合的难易程度
无论是学术研究还是工程开发,在上马深度学习课题之前一般都已积累不少开发经验和资源。可能你最喜欢的编程语言已经确立,或者你的数据已经以一定的形式储存完毕,或者对模型的要求(如延迟等)也不一样。标准1 考量的是深度学习平台与现有资源整合的难易程度。这里我们将回答下面的问题:
是否需要专门为此学习一种新语言?
是否能与当前已有的编程语言结合?
标准 2: 和相关机器学习、数据处理生态整合的紧密程度
我们做深度学习研究最后总离不开各种数据处理、可视化、统计推断等软件包。这里我们要回答问题:
建模之前,是否具有方便的数据预处理工具?当然大多平台都自身带了图像、文本等预处理工具。
建模之后,是否具有方便的工具进行结果分析,例如可视化、统计推断、数据分析?
标准 3:通过此平台做深度学习之外,还能做什么?
上面我们提到的不少平台是专门为深度学习研究和应用进行开发的,不少平台对分布式计算、GPU 等构架都有强大的优化,能否用这些平台/软件做其他事情?
比如有些深度学习软件是可以用来求解二次型优化;有些深度学习平台很容易被扩展,被运用在强化学习的应用中。哪些平台具备这样的特点?
这个问题可以涉及到现今深度学习平台的一个方面,就是图像计算和自动化求导。
标准 4:对数据量、硬件的要求和支持
当然,深度学习在不同应用场景的数据量是不一样的,这也就导致我们可能需要考虑分布式计算、多 GPU 计算的问题。例如,对计算机图像处理研究的人员往往需要将图像文件和计算任务分部到多台计算机节点上进行执行。
当下每个深度学习平台都在快速发展,每个平台对分布式计算等场景的支持也在不断演进。今天提到的部分内容可能在几个月后就不再适用。
标准 5:深度学习平台的成熟程度
成熟程度的考量是一个比较主观的考量因素,我个人考量的因素包括:社区的活跃程度;是否容易和开发人员进行交流;当前应用的势头。
讲了 5 个参考标准后,接下来我们用上面的这些标准对各个深度学习平台进行评价:
二、深度学习平台评价
评判1:与现有编程平台、技能整合的难易程度
标准1 考量的是深度学习平台与现有资源整合的难易程度。这里我们将回答下面的问题:是否需要专门为此学习一种新语言?是否能与当前已有的编程语言结合?
这一个问题的干货在下面这个表格。这里我们按照每个深度学习平台的底层语言和用户语言进行总结,可以得到下表。
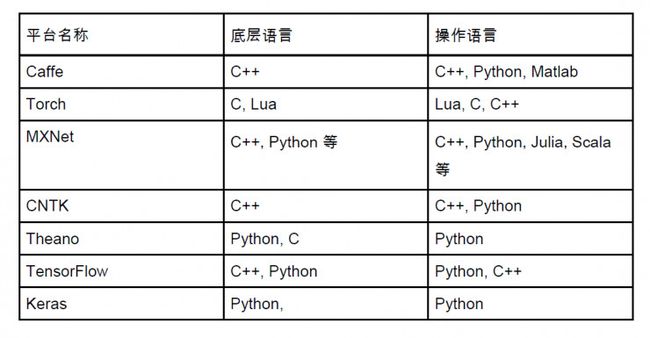
其中 Keras 通过 Theano, TensorFlow 作为底层进行建模。
我们可以看到这样的趋势:
深度学习底层语言多是 C++ / C 这样可以达到高运行效率的语言。
操作语言往往会切近实际,我们大致可以断定 Python 是未来深度学习的操作平台语言,微软在 CNTK 2.0 加入了对 Python 的支持。
当然,还有不少平台可以通过脚本的方式配置网络并且训练模型。
从格局上来说,Python 作为深度学习建模的基本语言是可以确定的。如果你最喜欢编程语言是 Python,恭喜您,大多数平台都可以和你的技术无缝衔接。如果是 Java 也不用担心,不少平台也具有 Java 支持,Deeplearning4J 还是一个原生的 Java 深度学习平台。
评判 2: 和相关机器学习、数据处理生态整合的紧密程度
这里我们要提一下现在主要的数据处理工具,比较全面的数据分析工具包括 R 及其相关生态,Python 及其相关生态,小众一点的还包括 Julia 及其相关生态。
完成深度学习建模等任务之后,和生态的整合也尤为重要。
我们可以发现,上面和 Python, R, 整合较为紧密,这里 Keras 生态(TensorFlow, Theano), CNTK, MXNet, Caffe 等占有大量优势。
同时 Caffe 具有大量图像处理包,对数据观察也具有非常大的优势。
评判 3:通过此平台做深度学习之外,还能做什么?
下图是本次公开课的核心:
 其实深度学习平台在创造和设计时的侧重点有所不同,我们按照功能可以将深度学习平台分为上面六个方面:
其实深度学习平台在创造和设计时的侧重点有所不同,我们按照功能可以将深度学习平台分为上面六个方面:
CPU+GPU控制,通信:这一个最低的层次是深度学习计算的基本层面。
内存、变量管理层:这一层包含对于具体单个中间变量的定义,如定义向量、矩阵,进行内存空间分配。
基本运算层:这一层主要包含加减乘除、正弦、余弦函数,最大最小值等基本算数运算操作。
基本简单函数:
○ 包含各种激发函数(activation function),例如 sigmoid, ReLU 等。
○ 同时也包含求导模块
神经网络基本模块,包括 Dense Layer, Convolution Layer (卷积层), LSTM 等常用模块。
最后一层是对所有神经网络模块的整合以及优化求解。
众多机器学习平台在功能侧重上是不一样的,我将他们分成了四大类:
1. 第一类是以 Caffe, Torch, MXNet, CNTK 为主的深度学习功能性平台。这类平台提供了非常完备的基本模块,可以让开发人员快速创建深度神经网络模型并且开始训练,可以解决现今深度学习中的大多数问题。但是这些模块很少将底层运算功能直接暴露给用户。
2. 第二类是以 Keras 为主的深度学习抽象化平台。Keras 本身并不具有底层运算协调的能力,Keras 依托于 TensorFlow 或者 Theano 进行底层运算,而 Keras 自身提供神经网络模块抽象化和训练中的流程优化。可以让用户享受快速建模的同时,具有很方便的二次开发能力,加入自身喜欢的模块。
3. 第三类是 TensorFlow。TensorFlow 吸取了已有平台的长处,既能让用户触碰底层数据,又具有现成的神经网络模块,可以让用户非常快速的实现建模。TensorFlow 是非常优秀的跨界平台。
4. 第四类是 Theano, Theano 是深度学习界最早的平台软件,专注底层基本的运算。
所以对平台选择可以对照上图按照自己的需求选用:
如果任务目标非常确定,只需要短平快出结果,那么第 1 类平台会适合你。
如果您需要进行一些底层开发,又不想失去现有模块的方便,那么第 2、3 类平台会适合你。
如果你有统计、计算数学等背景,想利用已有工具进行一些计算性开发,那么第 3, 4 类会适合你。
这里我介绍下深度学习的一些副产品,其中一个比较重要的功能就是符号求导。
图计算和符号求导:深度学习对开源社区的巨大贡献
大家可能会有疑问:我能训练出来深度学习模型就蛮好的了,为什么需要接触底层呢?
这里我先介绍下深度学习的一些副产品,其中一个比较重要的功能就是符号求导。符号求导英文是 Symbolic Differentiation,现在有很多有关的文献和教程可以使用。
符号求导是什么意思?
以前我们做机器学习等研究,如果要求导往往需要手动把目标函数的导数求出来。最近一些深度学习工具,如 Theano, 推出了自动化符号求导功能,这大大减少了开发人员的工作量。
当然,商业软件如 MatLab, Mathematica 在多年前就已具有符号计算的功能,但鉴于其商业软件的限制,符号计算并没有在机器学习应用中被大量采用。
深度学习由于其网络的复杂性,必须采用符号求导的方法才能解决目标函数过于复杂的问题。另外一些非深度学习问题,例如:二次型优化等问题,也都可以用这些深度学习工具来求解了。
更为优秀的是,Theano 符号求导结果可以直接通过 C程序编译,成为底层语言,高效运行。
这里我们给一个 Theano 的例子:
>>> import numpy
>>> import theano
>>> import theano.tensor as T
>>> from theano import pp
>>> x = T.dscalar('x')
>>> y = x ** 2
>>> gy = T.grad(y, x)
>>> f = theano.function([x], gy)
>>> f(4)
8
上面我们通过符号求导的方法,很容易的求出 y 关于 x 的导数在 4 这个点的数值。
评判 4:对数据量、硬件的要求和支持
对于多 GPU 支持和多服务器支持,我们上面提到的所有平台都声称自己能够完成任务。同时也有大量文献说某个平台的效果更为优秀。我们这里把具体平台的选择留给在座各位,提供下面这些信息:
首先想想你想要干什么。现在深度学习应用中,需要运用到多服务器训练模型的场景往往只有图像处理一个,如果是自然语言处理,其工作往往可以在一台配置优秀的服务器上面完成。如果数据量大,往往可以通过 hadoop 等工具进行数据预处理,将其缩小到单机可以处理的范围内。
本人是比较传统的人,从小就开始自己折腾各种科学计算软件的编译。现在主流的文献看到的结果是,单机使用 GPU 能比 CPU 效率提高数十倍左右。
但是其实有些问题,在 Linux 环境下,编译 Numpy 的时候将线性函数包换为 Intel MLK 往往也可以得到类似的提高。
当然现在很多评测,往往在不同硬件环境、网络配置情况下,都会得到不一样的结果。
就算在亚马逊云平台上面进行测试,也可能因为网络环境、配置等原因,造成完全不同的结果。所以对于各种测评,基于我的经验,给的建议是:take it with a grain of salt,自己要留个心眼。前面我们提到的主要工具平台,现在都对多 GPU、多节点模型训练有不同程度的支持,而且现在也都在快速的发展中,我们建议听众自己按照需求进行鉴别。
评判 5:深度学习平台的成熟程度
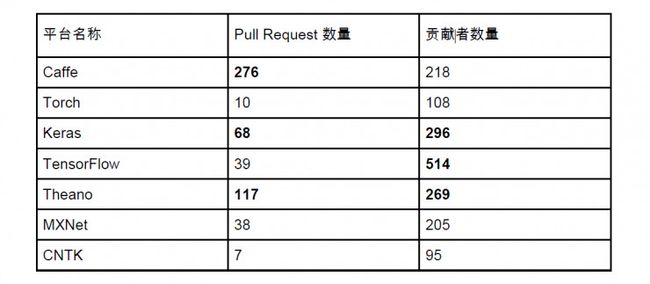
对于成熟程度的评判往往会比较主观,结论大多具有争议。我在这里也只列出数据,具体如何选择,大家自己判断。
这里我们通过 Github 上面几个比较受欢迎的数量来判断平台的活跃程度。这些数据获取于今天下午(2016-11-25)。我们用黑体标出了每个因子排名前三的平台:
第一个因子是贡献者数量,贡献者这里定义非常宽泛,在 Github issues 里面提过问题的都被算作是 Contributor,但是还是能作为一个平台受欢迎程度的度量。我们可以看到 Keras, Theano, TensorFlow 三个以 Python 为原生平台的深度学习平台是贡献者最多的平台。
第二个因子是 Pull Request 的数量,Pull Request 衡量的是一个平台的开发活跃程度。我们可以看到 Caffe 的 Pull Request 最高,这可能得益于它在图像领域得天独厚的优势,另外 Keras 和 Theano 也再次登榜。
另外,这些平台在应用场景上有侧重:
自然语言处理,当然要首推 CNTK,微软MSR(A) 多年对自然语言处理的贡献非常巨大,CNTK 的不少开发者也是分布式计算牛人,其中所运用的方法非常独到。
当然,对于非常广义的应用、学习,Keras/TensorFlow/Theano 生态可能是您最好的选择。
对于计算机图像处理,Caffe 可能是你的不二选择。
关于深度学习平台的未来:
微软在对 CNTK 很有决心,Python API 加的好,大家可以多多关注。
有观点认为深度学习模型是战略资产,应该用国产软件,防止垄断。我认为这样的问题不用担心,首先 TensorFlow 等软件是开源的,可以通过代码审查的方法进行质量把关。另外训练的模型可以保存成为 HDF5 格式,跨平台分享,所以成为谷歌垄断的概率非常小。
很有可能在未来的某一天,大家训练出来一些非常厉害的卷积层(convolution layer),基本上能非常优秀地解决所有计算机图像相关问题,这个时候我们只需要调用这些卷积层即可,不需要大规模卷积层训练。另外这些卷积层可能会硬件化,成为我们手机芯片的一个小模块,这样我们的照片拍好的时候,就已经完成了卷积操作。
——————————————————————————————————————————————
关于那些框架的优劣,网上也是众说纷纭,小白有些凌乱,后期再进行整理,这里稍微整理一点知识:
(【转】从Tensorflow到PyTorch:九大深度学习框架哪款最适合你? http://xilinx.eetrend.com/article/11406
【转】深度学习领域开源框架对比 https://blog.csdn.net/u012905422/article/details/52497389 )