最详细的语义分割---04PSPNet的训练
**
实例化模型
**
由于我们前面已经把相应的模块都已经准备好了,我们在这一部分只需要把他们导入过来,并对相应的超参数进行赋值即可。这里device是对设备的类型进行判断,若存在GPU,我们则使用GPU加速训练。
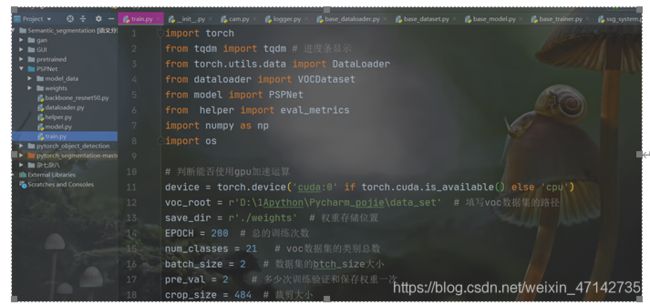
实例化我们之前写好的dataloder和网络。拿到网络的优化器,和学习率调整方式、损失函数。这里需要注意的是,voc数据集的背景类,即标签中黑色的部分,它的标签是255,所以我们在这里计算预测结果和真实标签的时候忽略背景。关于如何忽略背景,只要在交叉熵函数中的ignore_idex=255即可。
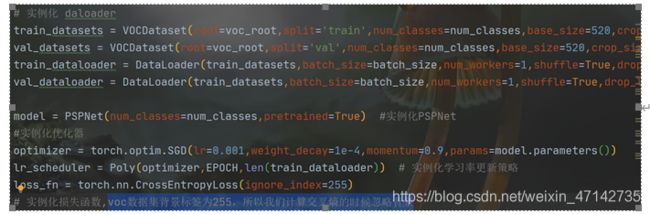
train_epoch
定义训练一个epoch的函数,这个函数传入的参数是我们当前训练到那个epoch了,特别要注意的一点是,在进行训练的时候,第一步一定要把优化器的梯度清零,不然可能会造成梯度爆炸。每行代码的意思,我都进行了注释,这里就不一一解释了。
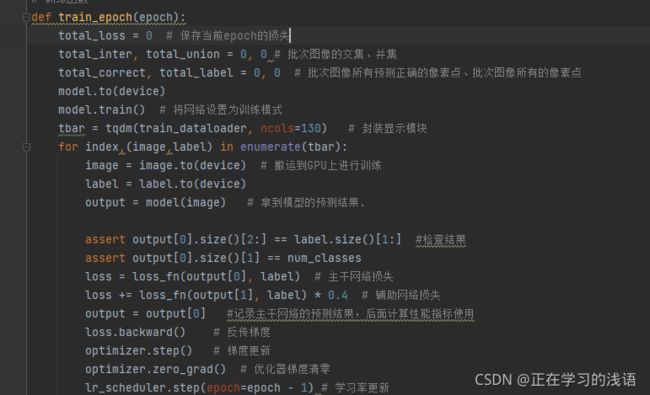
这里会调用eval_metrics方法计算当前训练的性能指标,它的输入是网络预测输出,标签和分类类别总数。
具体的实现方式可以参见我的博客:https://blog.csdn.net/weixin_47142735/article/details/115792241?spm=1001.2014.3001.5501。
这个函数会返回一个列表,其内容如下[分类正确的像素总数,该批次像素总数,[每个类别预测图于标签相交的像素总数],[每个类别预测图标签图相并的像素总数]]。其中前两个元素是两个数,后面的两个元素是一个列表,列表中的每个元素是每类像素相交的元素总数。这里我们会把每次计算出来的Iou和PA保存起来,方便显示当前模型的性能指标。
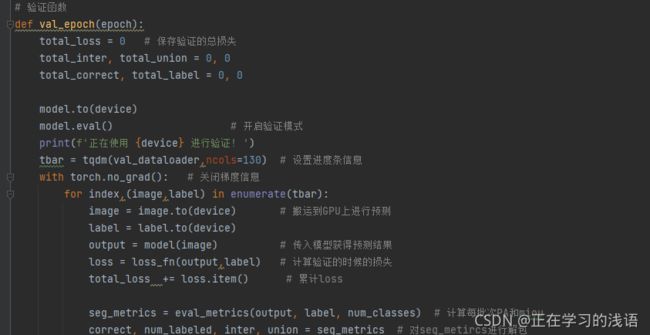
val_epoch
验证函数的作用就是监视网络训练,避免网络训练过拟合。它的编写思路整体于训练脚本类似,只不过整个过程不需要反传梯度。我们需要注意的是,验证时一定要把模型设置为验证模式。
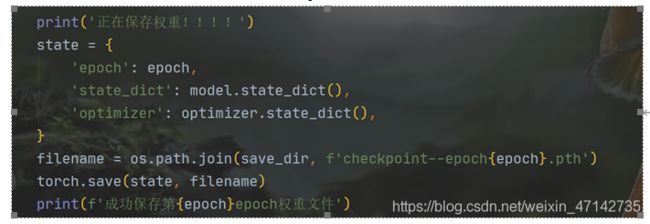
权值保存
我们训练网络的目的就是为了找到最合适的权值,但是我们没有必要把每个权值都保存下来,我么只需要在验证的时候按条件保存权值即可。很多时候,训练网络都是一个漫长的过程,总会出现无法一次训练结束的情况,所以这个时候也许要保存权值,方便下次的继续训练。
这一小段代码就可以实现上面的功能,当我们保存权值的时候以字典的形式记录epoch,权值字典和优化器参数,这样在下次训练的时候就可以接着之前的epoch和学习率接着训练了。
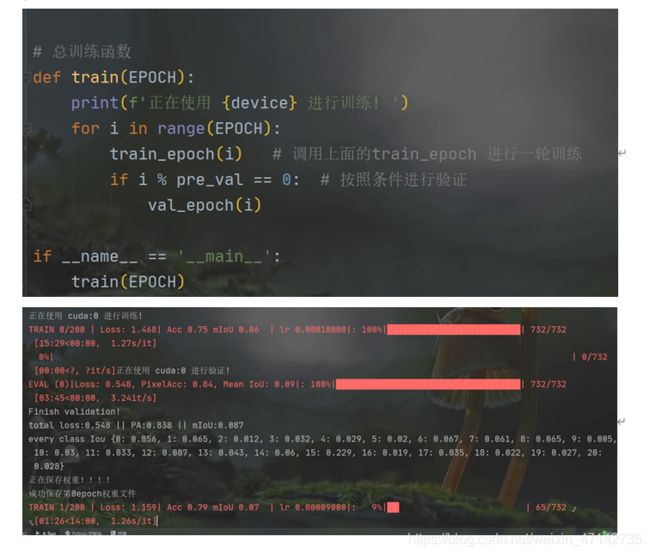
整个训练
前面的tian和val都是只训练一个epoch,即只轮流训练了一个数据集中所有图片一次,这是远远不够的,所以,我们还要在这个基础上进行大的循环,多训练记次网络,同时按照条件进行验证。
整个代码
import torch
from tqdm import tqdm # 进度条显示
from torch.utils.data import DataLoader
from dataloader import VOCDataset
from model import PSPNet
from helper import eval_metrics
import numpy as np
import os
# 判断能否使用gpu加速运算
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
voc_root = r'D:\1Apython\Pycharm_pojie\data_set\VOCdevkit' # 填写voc数据集的路径
save_dir = r'./weights' # 权重存储位置
EPOCH = 200 # 总的训练次数
num_classes = 21 # voc数据集的类别总数
batch_size = 4 # 数据集的btch_size大小
pre_val = 2 # 多少次训练验证和保存权重一次
crop_size = 284 # 裁剪大小
# 实例化 daloader
train_datasets = VOCDataset(root=voc_root,split='train',num_classes=num_classes,base_size=300,crop_size=crop_size)
val_datasets = VOCDataset(root=voc_root,split='val',num_classes=num_classes,base_size=300,crop_size=crop_size)
train_dataloader = DataLoader(train_datasets,batch_size=batch_size,num_workers=1,shuffle=True,drop_last=True)
val_dataloader = DataLoader(train_datasets,batch_size=batch_size,num_workers=1,shuffle=True,drop_last=True)
model = PSPNet(num_classes=num_classes,pretrained=True) #实例化PSPNet
#实例化优化器
optimizer = torch.optim.SGD(lr=0.005,params=model.parameters())
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.9)
# 实例化学习率更新策略,可以根据自己的需求选择不同的调整方法,这里随便使用了一个StepLR
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=255)
# 实例化损失函数,voc数据集背景标签为255,所以我们计算交叉熵的时候忽略背景
def get_lr(optimizer): # 拿到变化的学习率
for param_group in optimizer.param_groups:
#print(param_group['lr'])
return param_group['lr']
# 训练函数
def train_epoch(epoch):
total_loss = 0 # 保存当前epoch的损失
total_inter, total_union = 0, 0 # 批次图像的交集、并集
total_correct, total_label = 0, 0 # 批次图像所有预测正确的像素点、批次图像所有的像素点
model.to(device)
model.train() # 将网络设置为训练模式
tbar = tqdm(train_dataloader, ncols=130) # 封装显示模块
for index,(image,label) in enumerate(tbar):
image = image.to(device) # 搬运到GPU上进行训练
label = label.to(device)
output = model(image) # 拿到模型的预测结果.
assert output[0].size()[2:] == label.size()[1:] #检查结果
assert output[0].size()[1] == num_classes
loss = loss_fn(output[0], label) # 主干网络损失
loss += loss_fn(output[1], label) * 0.4 # 辅助网络损失
output = output[0] #记录主干网络的预测结果,后面计算性能指标使用
loss.backward() # 反传梯度
optimizer.step() # 梯度更新
optimizer.zero_grad() # 优化器梯度清零
lr_scheduler.step(epoch=epoch - 1) # 学习率更新
lr = get_lr(optimizer) # 拿到当前学习率
total_loss += loss.item() # 保存损失
seg_metrics = eval_metrics(output, label, num_classes) # 计算每批次PA和miou
#返回一个列表[计算正确的像素总数,像素总数,标签与预测图相交部分,标签与预测图相并部分(每个类别)]
correct, num_labeled,inter, union = seg_metrics # 对seg_metircs进行解包
"将该epoch中所有正确的像素总数、所有像素总数、交集、和并集累加起来"
total_correct += correct # 更新批次图像计算正确的像素
total_label += num_labeled # 更新总的像素值
total_inter += inter # 更新相交区域的值
total_union += union # 更新相并部分的值
# 计算平均值
"这里计算的PA和mIoU是将一个epoch中每个batch的交并比进行累加,然后计算平均交并比"
pixAcc = 1.0 * total_correct / (np.spacing(1) + total_label) #计算PA=正确分类像素总数/像素总数
IoU = 1.0 * total_inter / (np.spacing(1) + total_union) # 计算Iou = 相交部分/相并部分 np.spacing(1)防止分母为0的情况
mIoU = IoU.mean() # 计算类别的平均IoU
# 显示打印信息
tbar.set_description(
'TRAIN {}/{} | Loss: {:.3f}| Acc {:.2f} mIoU {:.2f} | lr {:.8f}|'.format(
epoch,EPOCH, np.round(total_loss/(index+1),3),np.round(pixAcc,3),
np.round(mIoU,3),lr))
lr_scheduler.step() # 学习率更新
# 验证函数
def val_epoch(epoch):
total_loss = 0 # 保存验证的总损失
total_inter, total_union = 0, 0
total_correct, total_label = 0, 0
model.to(device)
model.eval() # 开启验证模式
print(f'正在使用 {device} 进行验证! ')
tbar = tqdm(val_dataloader,ncols=130) # 设置进度条信息
with torch.no_grad(): # 关闭梯度信息
for index,(image,label) in enumerate(tbar):
image = image.to(device) # 搬运到GPU上进行预测
label = label.to(device)
output = model(image) # 传入模型获得预测结果
loss = loss_fn(output,label) # 计算验证的时候的损失
total_loss += loss.item() # 累计loss
seg_metrics = eval_metrics(output, label, num_classes) # 计算每批次PA和miou
correct, num_labeled, inter, union = seg_metrics # 对seg_metircs进行解包
"将该epoch中所有正确的像素总数、所有像素总数、交集、和并集累加起来"
total_correct += correct # 更新批次图像计算正确的像素
total_label += num_labeled # 更新总的像素值
total_inter += inter # 更新相交区域的值
total_union += union # 更新相并部分的值
# 计算平均值
"这里计算的PA和mIoU是将一个epoch中每个batch的交并比进行累加,然后计算平均交并比"
pixAcc = 1.0 * total_correct / (np.spacing(1) + total_label) # 计算PA=正确分类像素总数/像素总数
IoU = 1.0 * total_inter / (np.spacing(1) + total_union) # 计算Iou = 相交部分/相并部分 np.spacing(1)防止分母为0的情况
mIoU = IoU.mean() # 计算类别的平均IoU
# 显示当前的预测信息
tbar.set_description('EVAL ({})|Loss: {:.3f}, PixelAcc: {:.2f}, Mean IoU: {:.2f}|'.format(epoch,
total_loss/(index+1),(pixAcc), mIoU))
print('Finish validation!') # 显示所有验证图片的平均信息
print(f'total loss:{np.round(total_loss/(index+1),3)} || PA:{np.round(pixAcc,3)} || mIoU:{np.round(mIoU,3)}')
print(f'every class Iou {dict(zip(range(num_classes), np.round(IoU,3)))}')
print('正在保存权重!!!!')
state = {
'epoch': epoch,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
}
filename = os.path.join(save_dir, f'checkpoint--epoch{epoch}.pth')
torch.save(state, filename)
print(f'成功保存第{epoch}epoch权重文件')
# 总训练函数
def train(EPOCH):
print(f'正在使用 {device} 进行训练! ')
for i in range(EPOCH):
train_epoch(i) # 调用上面的train_epoch 进行一轮训练
if i % pre_val == 0: # 按照条件进行验证
val_epoch(i)
if __name__ == '__main__':
train(EPOCH)
如果需要整个文件的代码,可以到下面这个网盘链接下载
链接:https://pan.baidu.com/s/19-CMyQvzIduxGeVwtVN7cQ
提取码:fbkd
