通过显式寻找物体的 extremity 区域加快 DETR 的收敛:Conditional DETR
关注公众号,发现CV技术之美
本文系52CV粉丝Charles投稿。
原文:https://zhuanlan.zhihu.com/p/401916664
在这篇文章,我们解读一下我们发表在 ICCV 2021的工作: “Conditional DETR for Fast Training Convergence”. 我们针对 DEtection Transformer (DETR) 训练收敛慢的问题(需要训练500 epoch才能获得比较好的效果) 提出了conditional cross-attention mechanism,通过 conditional spatial query 显式地寻找物体的 extremity 区域,从而缩小搜索物体的范围,加速了收敛。结构上只需要对 DETR 的 cross-attention 部分做微小的改动,就能将收敛速度提高 6~10 倍。

作者单位:中国科学技术大学,北京大学,微软亚洲研究院
代码:https://github.com/Atten4Vis/ConditionalDETR
论文:https://arxiv.org/pdf/2108.06152.pdf
背景和动机
(1) DETR 简介
最近提出的 DETR 成功地将 transformer 引入到物体检测任务中,获得了很不错的性能。DETR 的重要意义在于去除了物体检测算法里需要人工设计的部分,比如 anchor 的生成和 NMS 操作。这大大简化了物体检测的设计流程。DETR 由 CNN backbone,transformer encoder,transformer decoder 和 prediction heads 组成。(1) CNN backbone 提取图像的 feature。(2) Encoder 通过 self-attention 建模全局关系对 feature 进行增强。(3) Decoder 主要包含 self-attention 和 cross-attention。Cross- attention 中有若干 queries,每个 query 去由 encoder feature 构造的 key 中进行查询,找到跟物体有关的区域,将这些区域的 feature 提取出来。Self-attention 则在不同的 query 之间进行交互,实现类似 NMS 的效果。(4) 最后的 prediction heads 基于每个 query 在 decoder 中提取到的特征,预测出物体的 bounding box 的位置和类别。然而,DETR的训练收敛速度非常慢,要训练 500 epochs 才能达到比较好的性能。

下图是对 DETR 的 decoder cross-attention 中 attention map 的可视化。我们可以看到,DETR decoder cross-attention 里的 query 查询到的区域都是物体的 extremity 区域,比如左图中大象的鼻子、后背、脚掌。通过这些关键区域,我们能够准确地定位物体的位置,识别出物体的类别。
(2) DETR收敛慢的原因
为了分析 DETR 为什么收敛慢,我们对 DETR decoder cross-attention 中的 spatial attention map 进行了可视化。下图中第一行是我们的 Conditional DETR 的结果,第二行是 DETR 训练 50 epoch 的结果,第三行是 DETR 训练 500 epoch 的结果。由于 DETR 使用了 multi-head attention,这里的每一列对应了一个 head。

我们可以看到,每个 head 的 spatial attention map 都在尝试找物体的一个 extremity 区域,例如: 围绕物体的 bounding box 的某条边。训练了 500 epoch 的 DETR 基本能够找准 extremity 区域的大概位置,然而只训练了 50 epoch 的 DETR 却找不准。我们认为,DETR 在计算 cross-attention 时,query 中的 content embedding 要同时和 key 中的 content embedding 以及 key 中的 spatial embedding 做匹配,这就对 content embedding 的质量要求非常高。而训练了 50 epoch 的DETR,因为 content embedding 质量不高,无法准确地缩小搜寻物体的范围,导致收敛缓慢。所以用一句话总结 DETR 收敛慢的原因,就是 DETR 高度依赖高质量的 content embedding 去定位物体的 extremity 区域,而这部分区域恰恰是定位和识别物体的关键。
为了解决对高质量 content embedding 的依赖,我们将 DETR decoder cross-attention 的功能进行解耦,并提出 conditional spatial embedding。Content embedding 只负责根据外观去搜寻跟物体相关的区域,而不用考虑跟 spatial embedding 的匹配; 对于 spatial 部分,conditional spatial embedding 可以显式地定位物体的 extremity 区域,缩小搜索物体的范围。
Conditional DETR
(1) Overview
我们的方法沿用了 DETR 的整体流程,包括 CNN backbone,transformer encoder,transformer decoder, 以及 object class 和 box 位置的预测器。Encoder 和 decoder 各自由6个相同的 layer 堆叠而成。我们相对于 DETR 的改动主要在 cross-attention 部分。
—— Box Regression
我们从每个 decoder embedding (一个 object query 会对应一个 decoder embedding)预测一个候选框:
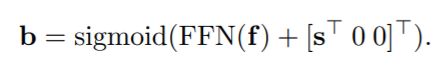
这里, 是decoder embedding, 是4维向量: ,前两维是box的中心,后两维是长和宽。sigmoid 函数用来将预测的向量处理到 [0, 1]区间,表示相对于这个图像的位置/相对于图像长宽的大小。 用来预测 unnormalized box, 是从 reference point 产生的 unnormalized 2D 坐标。Reference point 是从 object query 预测出的一个坐标,大概估计了这个 query 负责的区域范围。在原始 DETR 中没有 reference point 的概念,因此它的 是 。这里 也可以直接作为一个模型参数来学习,而非从 reference point 预测,我们的实验发现效果仅仅略微差一些。
—— Category prediction
我们使用 FFN 预测每个候选框的类别:
(2) DETR Cross-Attention
DETR 的 cross-attention 有三个输入:query, key, value。Query 由来自 decoder 中 self-attention 的输出 (content query: ) 和所有图片共享的 object query (spatial query: , 在DETR中其实就是 object query ) 相加得到。Key 由来自 encoder 的输出 (content key: ) 和对于 2D 坐标的位置编码 (spatial key: ) 相加得到。Value 的组成和 key 相同。在这里,content 代表这个向量的内容和图像 (颜色、纹理等) 是相关的,而 spatial 代表这个向量它更多包含空间上的信息,他的内容和图像的内容无关。Attention 模块的输出,就是对 query 和 key 算一次内积得到注意力的权重,用这个权重给 value 进行加权。我们将这个过程写成下面的形式:

(3) Conditional Cross-Attention
我们对 DETR 的 cross-attention 中 query 和 key 的形式做了些改变。Query 由 content query 和 spatial query concat 而成,key 由 content key 和 spatial key concat 而成。这样 query 和 key 做内积,得到如下结果:
这里只有两项,第一项计算 content 相似度,第二项计算 spatial 相似度。
—— Conditional spatial query prediction

上文提到,我们是基于 (1) 当前 layer 的 decoder embedding 中包含的信息,以及 (2) reference point 一起预测 box 信息的。这也就是说, decoder embedding 中包含了 box 有关的区域 (比如box的四条边、或者box内部的点)到 reference point 的偏移量。因此,我们在生成 conditional spatial query 的时候,也要同时考虑 reference point 和 decoder embedding :
和 box prediction 类似,我们的 也由两部分组成,一个 reference,一个“偏移量”。因为这里的 reference 在一个高维位置编码空间中,所以“偏移量”也不再是 xy 方向的值,而是一个施加在高维向量上的 projection 函数。
首先,我们将该 query 对应的 reference point 的 2D 坐标归一化之后映射到和 spatial key 相同的正弦位置编码空间中,得到 reference: ,

然后,我们将 decoder embedding 中包含的偏移量信息通过一个 FFN (linear + ReLU + linear) 映射到高维空间中,得到针对 的“偏移量”:
那么,最终的 conditional spatial query 就可以由 reference 和偏移量组合得到: 。对于 我们选择一种计算上较为简单的设计:对角矩阵。假设 所处的空间是 256-d 的,那么对角矩阵的对角线上的 256 个元素可以记为向量 。那么 conditional spatial query 可以通过 element-wise multiplication 得到:
—— Multi-head cross-attention
和 DETR 一样,我们在 cross-attention 中使用 multi-head 的设计。对于同一个 query,我们使用 8 个 head,即将 query/key 通过 linear projection 映射到 8 个维度更低的 sub-query/sub-key。通过这 8 个 head 各自计算出的 conditional spatial sub-query,我们可以得到关于一个物体的位置的不同角度的表达:bounding box 的四条边,或者 bounding box 的内部。这个我们在下面的可视化部分展示一下。
(3) Visualization and Analysis

在这个图中,我们可视化了同一个 query 不同 head 的 attention map。左右两侧是两个样例,一个是同类别只有一个个体的情况,另一个是同类别多个体的情况。图中的高亮部分是 attention map 权重较高的区域。
第一行是 spatial attention map: ,第二行是 content attention map: ,第三行是组合之后的 attention map: 。
每一列表示一个head。我们只画了 8 个 head 中的 5 个,其余 3 个 head 对应的区域和这 5 个有重叠,所以没有进行展示。
从图中,我们可以得出结论:
每个 head 的 spatial attention map 对应了跟 box 有关的一个区域。有趣的是,有些 head 对应的区域甚至跟 bounding box 的几条边重合了,分别对应了上、下、左、右四条边。另外一个对应了物体内部的一小块区域,这个区域的特征经过 transformer encoder 的处理,或许已经足够主要作用是用来对物体进行识别和分类。
每个 head 的 content attention map 对应了跟物体外观相似的一些区域 (甚至是同类别的其他个体)。我们从右边的例子可以看出来,想检测小牛,但是 content attention 很多都聚焦到大牛的身上,这显然是不利于检测的。
当我们将 content 和 spatial attention map 进行组合,我们发现当前物体以外的区域被完美地过滤掉了,剩下的高亮区域基本存在于物体的一些 extremity 区域,比如右侧样例中小牛的头上、脚上这些跟 bounding box 有重合的区域。
—— 对可视化的一些分析
根据上面的可视化结果,我们对 conditional spatial query 的作用做了分析。它的作用有两方面:
(1) 将spatial attention map 的高亮区域映射到物体的四条边界上和中心区域。有趣的是,对于不同的物体,同一个 head 的这些高亮区域相对于 bounding box 的位置是类似的。
(2) 可以根据物体的大小将 spatial attention map 高亮的区域做缩放:对于大物体,有更大的 spread 范围,对于小物体则有更小的 spread 范围。这些作用都归功于之前提到的作用于 reference 的变换 。
实验
(1) 数据集介绍
我们在 COCO 2017 Detection dataset 上进行实验,该数据集包括 118K 图像的训练集和 5K 图像的验证集。
(2) 和 DETR 的性能对比

从表中我们可以看到,
(1) DETR 50 epoch 的模型比 500 epoch 的模型差很多。
(2) 当使用 ResNet-50/ResNet-101 作为 backbone 时,Conditional DETR 训练 50 epoch 的模型比 DETR 训练 500 epoch 的模型稍差一些;当使用 DC5-ResNet-50/DC5-ResNet-101 作为 backbone 时,Conditional DETR 训练 50 epoch 可以达到与 DETR 训练 500 epoch 差不多/更高的结果。当 Conditional DETR 训练 75 epoch 及以上,4 种不同的 backbone 都可以超过 DETR 训练 500 epoch 的结果。这也说明了在更强的backbone下,Conditional DETR 相对于 DETR 能表现得更好。
(3) DC5-ResNet backbone下,Conditional DETR 可以比 DETR 的收敛速度快 10倍;ResNet backbone 下,Conditional DETR 可以比 DETR 的收敛速度快 6.67倍。
除此之外,我们在 single-scale 的条件下,还跟 Deformable DETR 以及 UP-DETR 进行对比。在 ResNet-50/DC5-ResNet-50 backbone下,我们的方法都超过了 Deformable DETR-SS。尽管他们的计算量、参数量不同,仍然说明了 Conditional DETR 是很有效的。当与 UP-DETR 比较,我们的方法用更少的 epoch 获得了更高的结果。
(3) 和多尺度/高分辨率下的 DETR 的变种算法的对比
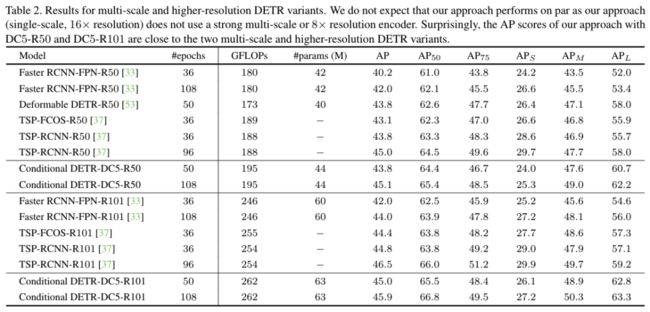
Conditional DETR 的目的是加速 DETR 的训练过程,所以并没有处理 encoder 带来的大量计算量的问题。因此,我们并没有期望 Conditional DETR 能够达到其他使用8x的分辨率/多尺度的方法相近的结果。
然而,我们发现在 DC5-R50 的backbone下,我们的方法居然和 Deformable DETR 表现的一样好,均达到了 43.8 的 AP。值得一提的是,只使用 single scale 的模型 Deformable DETR-DC5-R50-SS 仅有 41.5 的 AP,说明他们的算法很大程度上受益于 multi-scale 的设计。
我们的方法也取得了跟 TSP-FCOS/TSP-RCNN 持平的结果。他们的方法是对 FCOS/Faster FCNN 的扩展。没有使用 transformer decoder,而是将 transformer encoder 放在少量的选定的位置之后 (在 Faster RCNN 中他们用的 region proposal),这使得他们在 self-attention 部分的计算量大幅减小。
总结
在这篇论文中,为了加速 DETR 的收敛速度,我们提出一个简单而有效的 conditional cross-attention 机制。该机制的核心是从 decoder embedding 和 reference point 中学习到一个 conditional spatial query。这个 query 可以显式地去找物体的 extremity 区域,从而缩小了搜索物体的范围,帮助物体的定位,缓解了 DETR 训练中对于 content embedding 过度依赖的问题。
END,入群????备注:目标检测
