[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising
DN-DETR:引入query去噪训练用于加速DETR训练
- Abstract
- Section I Introduction
- Section II Related Work
- Section III Why denoising accelaretes DETR training?
- Section IV DN-DETR
-
- Part 1 Overview
- Part 2 Intro to DAB-DETR
- Part 3 Denoising
- Part 4 Attention Mask
- Part 5 Label Embedding
- Section V Experiment
-
- Part 1 Set up
- Part 2 Denoising Training Improves Performance
- Part 3 1x Setting
- Part 4 Compared with SOTA
- Part 5 Ablation Study
- Section VI Conclusion
from CVPR2022
Code
Paper
Abstract
本文提出一种新的去噪训练的方法来加速DETR的训练,加深对DETR收敛问题的理解。本文发现DETR收敛版的原因主要是DETR 二分图匹配的不稳定导致的。为了解决这一问题,除了使用匈牙利损失,本文还将带噪声的GT boxes作为DETR decoder的输入,输出重建后的bbox,这样有效减少了二分图失配的问题同时加速了DETR的收敛。本文的方法是通用的,可作为一种即插即用的插件加入到DETR类的代码中。最终实验结果显示,DN-DETR有效提升了目标检测的精度,平均提升了1.9AP,与基线模型相比训练时间减少了50%。
Section I Introduction
目标检测是计算机视觉领域中的一类基础任务,旨在推测图像中的物体类别和边界框(nnox),传统的目标检测算法已经取得了一定的性能,主要基于卷积神经网络。直到Carion等人近期的DETR将Trabnsformer引入到目标检测领域。与之前的目标检测器相比,DETR使用了可学习的queries来从Transformer encoder中获得图像特征,然后基于二分图匹配获得预测的box,有效排除了手动锚框的参与和非极大值抑制的参与。但是DETR的训练难以收敛,经常需要在COCO数据集上训练500个epoches,而Faster-RCNN只需要12个epoch。
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第1张图片](http://img.e-com-net.com/image/info8/5f3df57ad9974e22ac99361bfcf1e7a7.jpg)
已经有诸多研究来探究DETR收敛慢的问题,有的致力于改进模型架构,比如Sun等人认为是交叉注意力部分导致的收敛过慢,因此提出仅包含encoder部分的DETR。Dai等人设计了基于ROI的动态decoder结构帮助decoder聚焦ROI区域。近期还有将DETR的query限制在一定空间位置,从而提升特征探测的效率。比如Conditional DETR将每一个query解耦成内容部分和位置部分。Defoemable DETR和Anchor DETR则直接将2D参考点作为query来计算交叉注意力,DAB-DETR则是将query视作4D Anchor逐层优化他们。
尽管DETR已在上述做出了一系列改进,但是很少有工作关注到二分图适配影响训练效率这一方面。本文发现DETR收敛慢的一个原因是由于二分图匹配导致的,在训练早期由于随机优化很不稳定。因此同一图片的query常常在不同epoch匹配到不同的物体上,这样就使得优化过程具有二义性、前后不一致。
为了解决这一问题,本文提出一种新的训练方法-DN-DETR,引入了query 去噪,因为参考点和Anchor DETR都显示出对query添加约束可以有效提升性能,本文遵循同样的思路使用4D ANCHOR作为query。本文的解决方案是将带有噪声的GT bbox作为noised query,与需要学习的anchor box一同输入Transformer decoder。两种query输入格式一样,对于noised queries,执行去噪任务来重建真的GT bbox,对于需要学习的anchor bbox则保持与原始DETR一样的训练过程。由于noised query不需要进行二分图匹配,因此退化为辅助任务帮助DETR减轻二分图失配的问题,使得bbox的预测更高效。
为了最大化发挥这一辅助任务的作用,本文将每一个query看做bbox+cls label嵌入后的结果,这样可以同时进行bbox去噪和label去噪。
总的来说,本文是一种去噪训练的方法。损失函数包含两部分,一是重建损失函数二是匈牙利损失函数,后者与DETR方法保持一致。本文的方法可以方便的嵌入到其他DETR类的模型中。
本文使用DAB-DETR来评估本文方法的有效性,因为其直接使用4D Anchor作为输入,别的方法主要使用的是2D Anchor。
,本文的工作总结如下:
(1)本文提出一个新的训练方式-DN-DETR来加速DETR的训练。实验结果显示可以加速模型收敛,并且有很大的性能提升(1.9AP).
(2)本文分析了DETR收敛过慢的原因,对DETR的训练有了更深入的认识。并且本文设计了评估二分图匹配不稳定的新的评价方法。
(3)一系列消融实验的结果显示本文噪声、label embedding和attention mask的有效性。
Section II Related Work
基于CNN的目标检测器主要分为两类:一阶段模型和两阶段模型。两阶段模型会首先生成RP,然后决定每一块区域包含的物体类别,生成bbox。Ren等人提出使用RPN来预测bbox。一阶段模型则是直接生成bbox。
Carion提出首个基于Transformer的目标检测模型——DETR,摆脱了Anchor的限制,取得了和Faster-RCNN接近的性能,但是训练需要500epoch才能收敛到较好性能。
近期诸多工作尝试加速DETR的训练过程,有的认为DETR中的交叉注意力不够高效,做出了改进。比如Dai等人设计动态decoder使得可以聚焦于ROI区域,Sun等人则是直接移除了DETR的decoder部分,仅保留Encoder部分。里尼系列的工作则聚焦于decoder queries的优化。Zhu等人设计的注意力模块只采样几个参考点进行计算,Meng等人则是将decoder queries解耦成内容部分和位置部分,分别计算交叉注意力。Yao等人则是使用RPN来产生top_K个锚点。DAB-DETR使用4D 坐标作为queries,层次化的更新bbox的坐标。
如果cost matrix稍微变化就会导致优化过程的不稳定性。
本文将DETR的训练过程分成两步,分别是:学习good anchors和学习相对位移。decoder queires负责学习anchors,但是由于anchor更新的前后不一致性使得难以学习相对位移。因此本文将去噪任务作为一种训练的shortcut帮助学习相对位移,直接越过二分图匹配这一步。将每一个query看做4D anchor,noised query可以被看做good anchor,训练的不叫就变成了预测原始的bbox,这样就绕过了匈牙利匹配中的二义性带来的问题。
上述改进都没有考虑到,DETR中使用的匈牙利损失函数也是导致DETR收敛过慢的一大原因。Sun等人分析了使用匈牙利损失函数预训练DETR作为教师模型的实验,发现label assignment旨在训练早期有助于模型收敛,因此他们得到的结论是匈牙利损失并不是导致收敛过慢的主要原因,本文则从另一角度记性分析并且通过有效的方法得到不同的结论。
本文采用DAB-DETR作为检测框架,其中decoder部分替换为label embedding+indicator,与其他框架的主要不同在于训练方式上,本文在匈牙利损失之外增加了去噪损失来加速训练,提升检测性能。Chen等人的方法与我们完全不同,他们是直接将噪声分类为“噪声”类别,而不是属于任何GT类别,本文致力于让模型尽可能让带噪声的输入与GT的bbox接近。
Section III Why denoising accelaretes DETR training?
匈牙利算法常用于图的匹配问题。给定输入矩阵,算法会输出最优的匹配结果。DETR是首个将匈牙利匹配用于目标检测,将物体检测变成一个动态过程,这就引入了训练不稳定的问题 。
为了衡量二分图匹配的不稳定性,本文还提出一种评价指标。对于一张训练图像,Transformer预测的结果是:
![]()
N就是目标类别,GT表示为:
![]()
二分匹配的结果是:
![]()
那么不匹配程度的计算表述为:

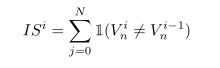
Fig 2展示了DN-DETR和DAB-DETR的不匹配程度,可以看到本文的DN-DETR有效改善了匹配的不稳定性。
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第2张图片](http://img.e-com-net.com/image/info8/a6e54793cd604301ae422f5c58b1c8c5.jpg)
Section IV DN-DETR
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第3张图片](http://img.e-com-net.com/image/info8/444429d6a07247768f17e9a9b55e62d9.jpg)
Part 1 Overview
Fig 3展示了DAB-DETR和DN-DETR交叉注意力部分的区别,DAB-SETR直接对锚框动态更新,DN-DETR会将decoder嵌入的结果作为label embedding并且增加一个indicator橡来区分是去噪还是匹配任务。
基准框架遵循DAB-DETR,因此会将decoder的queries显示编码成为bbox坐标,唯一不同之处在于decoder embedding部分,会有一个cls label帮助进行去噪。
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第4张图片](http://img.e-com-net.com/image/info8/b81616028c314e8c846355f31fc79093.jpg)
Fig4展示了DN-DETR的的详细结构。可以看到DN-DETR与DETR很接近,包含Transformer encoder和decoder部分。Encoder为一个CNN backbone负责提取图像特征然后进行位置嵌入后送入encoder获得更精炼的图像特征。decoder的输入是queries通过计算交叉注意力识别目标。
decoder的输入enqueries为:![]()
输出为:![]()
F表示经立案后的特征图,A表示attention mask,因此整个过程表述为:
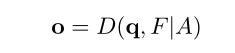

decoder queries包含两部分,一是匹配部分,输入的是可学习的anchors,这一部分和DETR一样,主要进行二分图匹配;另一部分则是去噪部分,输入的是加了噪声的GT box-label组-称之为GT Objects,输出是重建的GT objects, 为了提升去噪效率,本文提出使用多种噪声版本的GT Objects,并且使用attention mask来防止信息从去噪部分流入匹配部分。
Part 2 Intro to DAB-DETR
DAB-DETR输入的是4D Anchor(x,y,w,h),会逐层动态更新,decoder的输出则是偏移量四元组和更新后的锚框坐标。本文也是遵循DAB-DETR的框架,仅在decoder emnbedding部分进行了改动。
Part 3 Denoising
对于每一张图像,会统计GT Objects并且给cls和bbox增加随机噪声,并且增加了多种噪声。
考虑为box添加两种噪声:center shiftin+box scaling 分别会改变bbox中心点和bbox的大小
对于cls采用的是label flipping也就是会将标签换为其他种类的标签。并且去噪只在训练过程中使用,推理过程中就不适用了。
Part 4 Attention Mask
Attention Maks是本文很重要的一部分,如果没有注意力掩膜,去噪的训练效果就会有所下降。
首先将GT Objects分组,每一组施加一种噪声,从而输入变成了:
![]()
![]()
每一组包含M个queries,M对应就是图中的目标数目
注意力掩膜的目标是防止信息泄露。
有两种潜在的信息泄露,分别是匹配部分可能 会看见加了噪声的GT Objects从而用来预测GT类别;第二种是噪声版本可以看到其他噪声版本的输入。注意力掩膜就是防止些部分的信息泄露。
A表示为注意力掩膜,可以看到有一下关系:
W=PXM+N
PM分别代表组数和GT Objects,N则是queries的数目
注意力掩膜如下计算:

本文只允许去噪部分能看见匹配部分,这样才能让queries无法借鉴人格GT Objects的信息。这样操作带来的额外计算成本几乎可以忽略,GFLOPs从94.4增加到94.6(分组=5)
Part 5 Label Embedding
decoder embedding主要用来支持box denoising 和denoising,除了COCO数据集中80个目标类别还增加了一个未知类别,表征matching部分语义与去噪部分是一指的。本文还在queries后面追加了一个indicator项,如果属于denoising则indicator=1,否则indicator=0。
Section V Experiment
Part 1 Set up
Dataset:
COCO2017数据集 评价指标AP(Average Precision)
Implementation Details
主要检测对DAB-DETR使用去噪训练的有效性,网络包含一个CNN backbone,多层Transformer encoder-decoder层,此外采用了在Imagenet上预训练的ResNet-50,101以及对应16x-分辨率的DC5-R50,DC101-R50配置。
Transformer部分遵循DAB-DETR中的6层encoder-decoder,hidden-dim = 256.
超参数设置为:
优化器Adam Optimizer
训练卡 8块A100
batch_size = 16
DN-Deformable-DETR
为了说明去噪训练的有效性,本文也在其他DETR模型进行了测试,分成10组进行去噪,组成的称之为DN-Deformable-DETR
在epoch=50的设定中为了去除DN-Deformable-DETRquery部分可能的误导信息,本文还与DAB-DETR基线模型进行了对比,使用Deformable DETR的query但没有使用去噪训练。其他所有设置保持一致,严格遵循Deformable DETR的多尺度特征而不使用FPN。Deformable DETR使用了更多尺度(5 scale)和FPN,会使得性能进一步提升,但本文的DN-DETR仍然超过了它们的性能。
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第5张图片](http://img.e-com-net.com/image/info8/7d29c926f43341b39a336d08cf83fbb5.jpg)
Part 2 Denoising Training Improves Performance
Table 1展示了与DAB-DETR和其他单尺度DETR模型的性能对比。可以看到DN-DETR获得了最有益的检测性能,比如与DAB-DETR基线模型相比,提升了1.9AP,并且去噪引入的额外参数可以忽略不计。
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第6张图片](http://img.e-com-net.com/image/info8/66e53de84020482bb3be9d75a4f56983.jpg)
Part 3 1x Setting
Table 2显示了去噪训练的加速效果,主要与传统的detector、DETR类模型的训练时间进行了对比,在DC5-R50的基准框架下,DN-DETR比DAB-DETR在12epochs内提升3.7A。如果换成ResNet-101基线,在12epochs可以达到44.1AP,比Faster-RCNN训练108epoches还高。
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第7张图片](http://img.e-com-net.com/image/info8/e31b080c849c45f5bf030e75da9efe9b.jpg)
Part 4 Compared with SOTA
Table 3展示了与其他多尺度模型的对比结果,可以看到DN-Deformable-DETR以ResNet-40为基准达到了48.6AP的检测精度,其中去噪训练带来的提升为1.7AP。
DN-Deformable-DETR的性能提升也表明去噪训练可用于其他DETR类的模型,带来性能提升。与Dynamic DETR相比仍然有1.4AP的提升。Fig 5展示了单尺度和多尺度设定下的收敛曲线。
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第8张图片](http://img.e-com-net.com/image/info8/0770b62373cf4e37a16d90a9dbf66edd.jpg)
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第9张图片](http://img.e-com-net.com/image/info8/6de361985a244206bcd7987c25b7fa8f.jpg)
Part 5 Ablation Study
Table 4、Table 5主要展示了消融实验的结果。
以ResNet50为基准训练50epoches。Table 4的实验结果表明去噪训练的每一部分均对最终性能提升有贡献,可以看到没有attention mask会带来性能的显著下降,因为注意力掩膜有效防止了信息泄露,有助于防止模型退化。
Table 5显示的是不同去噪组数的性能对比,可以看到更多的去噪组数会进一步提升性能、加快收敛,但是提升的逐渐减少,因此最终网络设置5个去噪组。
Fig 6探索了noise scale的影响,可以看到center shifting和box scaling都会带来性能提升,但是如果噪声太大也会使得性能下降,最终设置noise scale=0.4.
![[Transformer]DN-DETR:Accelerate DETR Training by Introducing Query DeNoising_第10张图片](http://img.e-com-net.com/image/info8/09219dffdac44f44a99001e0082f7d74.jpg)
Section VI Conclusion
本文对DETR收敛过慢的问题进行了深入分析,对其二分图匹配不稳定问题提出新的去噪训练方法来提升DETR的训练收敛速度,称之为DN-DETR。 DN-DETR将decoder的输入加入了label embedding并且引入了噪声,实验结果显示明显加快了收敛速度,同时具有一定的通用性。以ResNet50和ResNet101为基准训练12epoch均取得了最优的检测性能。本研究表明去噪训练可以作为一种通用的训练方法集成到DETR类的训练过程中,可以显著提升检测性能和训练收敛时间。