基于EasyCV复现DETR和DAB-DETR,Object Query的正确打开方式
DETR 是最近几年最新的目标检测框架,第一个真正意义上的端到端检测算法,省去了繁琐的 RPN、anchor 和 NMS 等操作,直接输入图片输出检测框。DETR 的成功主要归功于 Transformer 强大的建模能力,还有匈牙利匹配算法解决了如何通过学习的方式 one-to-one 的匹配检测框和目标框。
虽然 DETR 可以达到跟 Mask R-CNN 相当的精度,但是训练 500 个 epoch、收敛速度慢,小目标精度低的问题都饱受诟病。后续一系列的工作都围绕着这几个问题展开,其中最精彩的要属 Deformable DETR,也是如今检测的刷榜必备,Deformable DETR 的贡献不单单只是将 Deformable Conv 推广到了 Transformer 上,更重要的是提供了很多训练好 DETR 检测框架的技巧,比如模仿 Mask R-CNN 框架的 two-stage 做法,如何将 query embed 拆分成 content 和 reference points 两部分组成,如何将 DETR 拓展到多尺度训练,还有通过 look forward once 进行 boxes 预测等技巧,在 Deformable DETR 之后,大家似乎找到了如何打开 DETR 框架的正确方式。其中对 object query 代表什么含义,以及如何更好的利用 object query 做检测,产生了许多有价值的工作,比如 Anchor DETR、Conditional DETR 等等,其中 DAB-DETR 做的尤为彻底。DAB-DETR 将 object query 看成是 content 和 reference points 两个部分,其中 reference points 显示的表示成 xywh 四维向量,然后通过 decoder 预测 xywh 的残差对检测框迭代更新,另外还通过 xywh 向量引入位置注意力,帮助 DETR 加快收敛速度,本文将基于 EasyCV 复现的 DETR 和 DAB-DETR 算法详细介绍一下如何正确的使用 object query 来提升 DETR 检测框架的性能。
DETR
DETR 使用 set loss function 作为监督信号来进行端到端训练,然后同时预测所有目标,其中 set loss function 使用 bipartite matching 算法将 pred 目标和 gt 目标匹配起来。直接将目标检测任务看成 set prediction 问题,使训练过程变的简洁,并且避免了 anchor、NMS 等复杂处理。
DETR 主要贡献有两个部分:architecture 和 set prediction loss。
1.Architecture
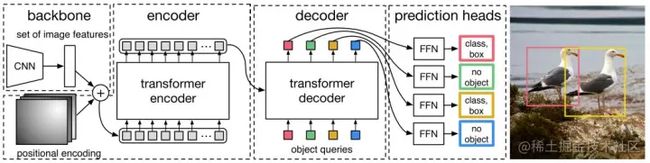
DETR 先用 CNN 将输入图像 embedding 成一个二维表征,然后将二维表征转换成一维表征并结合 positional encoding 一起送入 encoder,decoder 将少量固定数量的已学习的 object queries(可以理解为 positional embeddings)和 encoder 的输出作为输入。最后将 decoder 得到的每个 output embdding 传递到一个共享的前馈网络(FFN),该网络可以预测一个检测结果(包括类和边框)或着“没有目标”的类。
1.1 Transformer
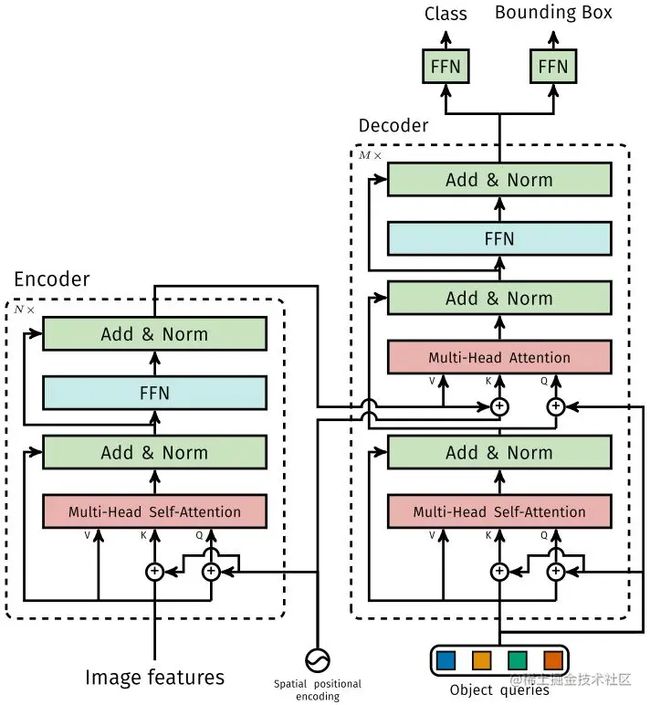
1.1.1 Encoder
将 Backbone 输出的 feature map 转换成一维表征,得到 特征图,然后结合 positional encoding 作为 Encoder 的输入。每个 Encoder 都由 Multi-Head Self-Attention 和 FFN 组成。和 Transformer Encoder 不同的是,因为 Encoder 具有位置不变性,DETR 将 positional encoding 添加到每一个 Multi-Head Self-Attention 中,来保证目标检测的位置敏感性。
# 一层encoder代码如下
class TransformerEncoderLayer(nn.Module):
def __init__(self,
d_model,
nhead,
dim_feedforward=2048,
dropout=0.1,
activation='relu',
normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(
q,
k,
value=src,
attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
1.1.2 Decoder
因为 Decoder 也具有位置不变性,Decoder 的 个 object query(可以理解为学习不同 object 的 positional embedding)必须是不同,以便生成不同 object 的 embedding,并且同时把它们添加到每一个 Multi-Head Attention 中。个 object queries 通过 Decoder 转换成一个 output embedding,然后 output embedding 通过 FFN 独立解码出个预测结果,包含 box 和 class。对输入 embedding 同时使用 Self-Attention 和 Encoder-Decoder Attention,模型可以利用目标的相互关系来进行全局推理。和 Transformer Decoder 不同的是,DETR 的每个 Decoder 并行输出个对象,Transformer Decoder 使用的是自回归模型,串行输出个对象,每次只能预测一个输出序列的一个元素。
个 object query(可以理解为学习不同 object 的 positional embedding)必须是不同,以便生成不同 object 的 embedding,并且同时把它们添加到每一个 Multi-Head Attention 中。个 object queries 通过 Decoder 转换成一个 output embedding,然后 output embedding 通过 FFN 独立解码出个预测结果,包含 box 和 class。对输入 embedding 同时使用 Self-Attention 和 Encoder-Decoder Attention,模型可以利用目标的相互关系来进行全局推理。和 Transformer Decoder 不同的是,DETR 的每个 Decoder 并行输出个对象,Transformer Decoder 使用的是自回归模型,串行输出个对象,每次只能预测一个输出序列的一个元素。
# 一层decoder代码如下
class TransformerDecoderLayer(nn.Module):
def __init__(self,
d_model,
nhead,
dim_feedforward=2048,
dropout=0.1,
activation='relu',
normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(
d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward(self,
tgt,
memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(
q,
k,
value=tgt,
attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(
query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory,
attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
1.1.3 FFNFFN
由 3 层 perceptron 和一层 linear projection 组成。FFN 预测出 box 的归一化中心坐标、长、宽和 class。DETR 预测的是固定数量的个 box 的集合,并且通常比实际目标数要大的(其中 DETR 默认设置为 100 个,而 DAB-DETR 设置为 300 个),并且使用一个额外的空类来表示预测得到的 box 不存在目标。
class MLP(nn.Module):
""" Very simple multi-layer perceptron (also called FFN)"""
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
return x
2.Set prediction loss
DETR 模型训练的主要困难是如何根据 gt 衡量预测结果(类别、位置、数量)。DETR 提出的 loss 函数可以产生 pred 和 gt 的最优双边匹配(确定 pred 和 gt 的一对一关系),然后优化 loss。将 表示为 gt 的集合, 表示为个预测结果的集合。假设N大于图片目标数,可以认为是用空类(无目标)填充的大小为的集合。搜索两个集合个元素
表示为 gt 的集合, 表示为个预测结果的集合。假设N大于图片目标数,可以认为是用空类(无目标)填充的大小为的集合。搜索两个集合个元素
![]()
的不同排列顺序,使得 loss 尽可能的小的排列顺序即为二分图最大匹配(Bipartite Matching),公式如下:
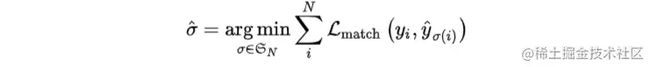
其中
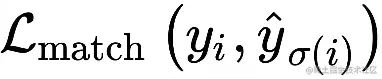
表示 pred 和 gt 关于![]() 元素i的匹配 loss。其中二分图匹配通过匈牙利算法(Hungarian algorithm)得到。匹配loss同时考虑了pred class和pred box的准确性。每个gt的元素iii可以看成
元素i的匹配 loss。其中二分图匹配通过匈牙利算法(Hungarian algorithm)得到。匹配loss同时考虑了pred class和pred box的准确性。每个gt的元素iii可以看成![]() ,
, 表示class label(可能是空类)
表示class label(可能是空类) 表示gt box,将元素
表示gt box,将元素 二分图匹配指定的pred class表示为
二分图匹配指定的pred class表示为
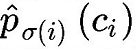
pred box 表示为
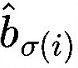
第一步先找到一对一匹配的 pred 和 gt,第二步再计算 hungarian loss。hungarian loss 公式如下:

其中 结合了 L1 loss 和 generalized IoU loss,公式如下:
![]()
# HungarianMatcher通过计算出cost_bbox,cost_class,cost_giou来一对一匹配预测框和gt框,然后返回匹配的索引对,最后通过索引对计算出loss值
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu()
sizes = [len(v['boxes']) for v in targets]
indices = [
linear_sum_assignment(c[i])
for i, c in enumerate(C.split(sizes, -1))
]
return [(torch.as_tensor(i, dtype=torch.int64),
torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
复制代码DAB-DETR
DAB-DETR 将 object query 看成是 content 和 reference points 两个部分,其中 reference points 显示的表示成 xywh 四维向量,然后通过 decoder 预测 xywh 的残差对检测框迭代更新,另外还通过 xywh 向量引入位置注意力,帮助 DETR 加快收敛速度。
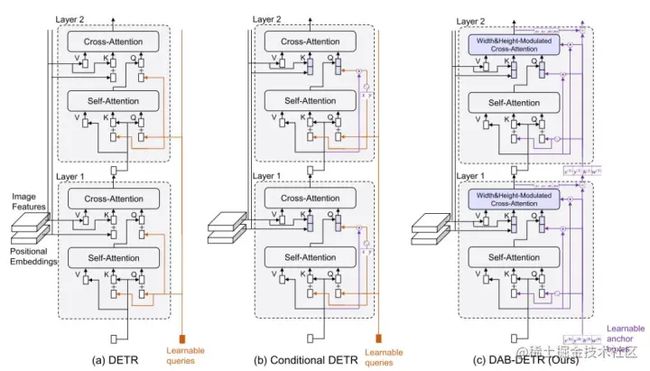

在 DAB-DETR 之前,有许多工作对如何设置 reference points 进行过深入的探索:Conditional DETR 通过 256 维的可学习向量学习得到 xy 参考点,然后将位置信息引入 transformer decoder 中;Anchor DETR 参考点看成是 xy,然后通过学习的方式得到 256 维的向量,将位置信息引入 transformer decoder 中,并且通过逐级迭代得到检测框的 xy;Defomable DETR 则是通过 256 维可学习向量得到 xywh 参考 anchor,通过逐级迭代得到检测框;DAB-DETR 则更为彻底,吸百家之长,通过 xywh 学习 256 维的向量,将位置信息引入 transformer decoder 中,并且通过逐级迭代得到检测框。至此,reference points 的使用方式逐渐明朗起来,显示的表示为 xywh,然后学习成 256 维向量,引入位置信息,每层 transformer decoder 学习 xywh 的残差,逐级叠加得到最后的检测框。
# DAB-DETR将object query显示的拆分为content和pos两种属性
# 将query_embed显示的表示为xywh,表示pos属性,通过MLP学习成256维的pos特征
self.query_embed = nn.Embedding(num_queries, query_dim)
# get sine embedding for the query vector
reference_points = self.query_embed.sigmoid()
obj_center = reference_points[..., :2]
query_sine_embed = gen_sineembed_for_position(obj_center)
query_pos = self.ref_point_head(query_sine_embed)
# content_embed初始化为全0的256维特征
tgt = torch.zeros(
self.num_queries,
bs,
self.embed_dims,
device=query_embed.device)
另外,DAB-DETR 为了更充分的利用 xywh 这种更为显示的 reference points 表示方式,进一步的引入了 Width & Height-Modulated Multi-Head Cross-Attention,其实简单来讲就是在 cross-attention 中引入位置 xywh 得到的位置注意力,这一点改进可以极大的加快 decoder 的收敛速度,因为原始的 DETR 相当于是在全图学习到位置注意力,DAB-DETR 可以直接关注到关键位置,这也是 Deformable DETR 为啥能加快收敛的原因,本质就是更关键的稀疏位置采样可以加快 decoder 收敛速度。
# 通过MLP的学习,调整query_sine_embed的attn位置,进一步加快收敛速度
# modulated HW attentions
if self.modulate_hw_attn:
refHW_cond = self.ref_anchor_head(
output).sigmoid() # nq, bs, 2
query_sine_embed[..., self.d_model //
2:] *= (refHW_cond[..., 0] /
obj_center[..., 2]).unsqueeze(-1)
query_sine_embed[..., :self.d_model //
2] *= (refHW_cond[..., 1] /
obj_center[..., 3]).unsqueeze(-1)复现结果
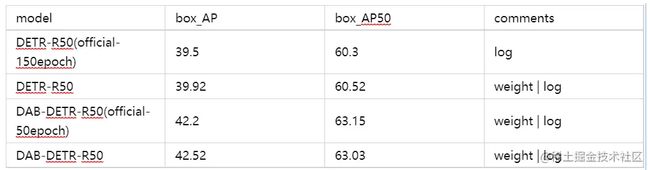
Tutorial
接下来,我们将通过一个实际的例子介绍如何基于 EasyCV 进行 DAB-DETR 算法的训练,也可以在该链接查看详细步骤。
一、安装依赖包
如果是在本地开发环境运行,可以参考该链接安装环境。若使用 PAI-DSW 进行实验则无需安装相关依赖,在 PAI-DSW docker 中已内置相关环境。二、数据准备
你可以下载COCO2017数据,也可以使用我们提供了示例 COCO 数据
wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/data/small_coco_demo/small_coco_demo.tar.gz && tar -zxf small_coco_demo.tar.gz
mkdir -p data/ && mv small_coco_demo data/cocodata/coco 格式如下:
data/coco/
├── annotations
│ ├── instances_train2017.json
│ └── instances_val2017.json
├── train2017
│ ├── 000000005802.jpg
│ ├── 000000060623.jpg
│ ├── 000000086408.jpg
│ ├── 000000118113.jpg
│ ├── 000000184613.jpg
│ ├── 000000193271.jpg
│ ├── 000000222564.jpg
│ ...
│ └── 000000574769.jpg
└── val2017
├── 000000006818.jpg
├── 000000017627.jpg
├── 000000037777.jpg
├── 000000087038.jpg
├── 000000174482.jpg
├── 000000181666.jpg
├── 000000184791.jpg
├── 000000252219.jpg
...
└── 000000522713.jpg二、模型训练和评估
以 vitdet-base 为示例。在 EasyCV 中,使用配置文件的形式来实现对模型参数、数据输入及增广方式、训练策略的配置,仅通过修改配置文件中的参数设置,就可以完成实验配置进行训练。可以直接下载示例配置文件。
查看 easycv 安装位置
# 查看easycv安装位置
import easycv
print(easycv.__file__)
export PYTHONPATH=$PYTHONPATH:root/EasyCV执行训练命令
单机8卡:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m
torch.distributed.launch --
nproc_per_node=8 --
master_port=29500 tools/train.py
configs/detection/dab-
detr/dab_detr_r50_8x2_50e_coco.p
y --work_dir easycv/dab_detr --
launcher pytorch执行评估命令
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5
,6,7 python -m
torch.distributed.launch --
nproc_per_node=8 --
master_port=29500 tools/eval.py
configs/detection/dab-
detr/dab_detr_r50_8x2_50e_coco.p
y easycv/dab_detr/epoch_50.pth -
-launcher pytorch --evalReference
代码实现:
DETR https://github.com/alibaba/EasyCV/tree/master/easycv/models/detection/detectors/detr
DAB-DETR
https://github.com/alibaba/EasyCV/tree/master/easycv/models/detection/detectors/dab_detr
EasyCV 往期分享
基于EasyCV复现ViTDet:单层特征超越FPN
MAE 自监督算法介绍和基于DETR是最近几年最新的目标检测框架,第一个真正意义上的端到端检测算法,省去了繁琐的RPN、anchor和NMS等操作,直接输入图片输出检测框。DETR的成功主要归功于Transformer强大的建模能力,还有匈牙利匹配算法解决了如何通过学习的方式one-to-one的匹配检测框和目标框。MAE 自监督算法介绍和基于
EasyCV 开源|开箱即用的视觉自监督+Transformer 算法库