Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker论文解读
Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker

code:RunxinXu/GIT: Source code for ACL-IJCNLP 2021 Long paper: Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker. (github.com)
paper:2105.14924.pdf (arxiv.org)
期刊/论文:ACL 2021
摘要
文档级事件提取旨在从整篇文章中识别事件信息。由于这项任务的两个挑战,现有的方法并不有效:a)目标事件论点分散在句子中;b) 文档中事件之间的相关性对于建模来说是非常重要的。在本文中,我们提出了基于异构图交互模型(带有跟踪器)(Graph-based
Interaction Model with a Tracker,GIT)来解决上述两个挑战。对于第一个挑战,GIT构建了一个异构图形交互网络,以捕捉不同句子和实体提及之间的全局交互。第二,GIT引入跟踪器模块来跟踪提取的事件,从而捕获事件之间的相关性。在大规模数据集上的实验显示,GIT在F1上表现比之前的方法好了2.8。进一步的分析表明,GIT可以有效地提取分散在文档中的多个相关事件和事件参数。
1、简介
事件抽取(EE)是信息提取(IE)中的关键和挑战性任务之一,其目的是检测事件并从文本中提取其参数。之前的大多数方法侧重于句子级事件抽取,从单个句子中提取事件。然而,句子级模型无法提取参数位于不同句子中的事件,这在现实场景中更为常见。因此,在文档级别提取事件至关重要,最近引起了广泛关注。

尽管前景光明,但文档级事件抽取仍面临两个关键挑战。首先,**事件记录的论点可能分散在句子中,这需要对跨句子上下文的全面理解。**图1显示了一个示例,即从财务文档中提取了一个股权不足(Equity UnderWeight,EU)和一个股权超重(Equity Overweight,EO)事件记录。提取EU事件的难度较小,因为所有相关论点都出现在同一句话中(第2句)。然而,对于EO记录的论点,2014年11月6日出现在第1和第2句中,而 吴晓婷 出现在第3和第4句中。在不考虑句子和实体提及之间的全局互动的情况下,识别此类事件将极具挑战性。其次,一个文档可以同时表达多个相关事件,认识到它们之间的相互依赖性是成功提取的基础。如图1所示,这两个事件是相互依赖的,因为它们对应于完全相同的事务,因此共享相同的StartDate。在这项任务中,对相关事件之间的这种相互依赖性进行有效建模仍然是一个关键挑战。
Yang等人从中心句子中提取事件,并查询相邻句子中缺少的论元,这忽略了扩增之间的跨句子对应关系。尽管Zheng等人迈出了通过Transformer融合句子和实体信息的第一步,但他们忽略了事件之间的相互依赖性。专注于单个事件提取,Du和Cardie等人连接多个句子,只考虑单个事件,这缺乏对分散在长文档中的多个事件建模的能力。
为了解决上述两个挑战,在本文中,我们提出了一种用于文档级事件抽取的基于异构图形的交互模型(带有跟踪器)(GIT)。为了处理句子间分散的论元,我们关注句子和实体提及之间的全局互动。具体而言,我们构建了一个具有实体提及节点和句子节点的异构图交互网络,并通过图神经网络中的四种类型的边(即句子-句子边、句子提及边、提及内提及边和提及间边)来建模它们之间的交互。通过这种方式,GIT从全局角度对文档中的实体和句子进行了联合建模。
为了促进多事件提取,我们针对相关事件之间的全局相互依赖性。具体地说,我们提出了一个跟踪器模块,用于使用全局存储器连续跟踪提取的事件记录。通过这种方式,鼓励模型在预测时结合与其他相关事件记录的相关性。
我们总结了以下贡献:
- 我们为文档级事件抽取构建了一个异构图形交互网络。通过不同的异构边缘,该模型可以捕捉不同句子中分散的事件参数的全局上下文。
- 我们引入了一个新的跟踪器模块来跟踪提取的事件记录。跟踪器减轻了提取相关事件的难度,因为将考虑事件之间的相互依赖性。
- 实验表明,GIT在大规模公共数据集上的表现优于先前的最先进模型,其文档数为32,040份,尤其是在跨句子事件和多事件场景上(F1的绝对增长分别为3.7和4.9)。
2、Preliminaries
我们首先澄清一些重要的概念。a) 实体提及:文档中引用实体对象的文本跨度;b) 事件论元:扮演特定事件角色的实体。为每个事件类型预定义事件角色;c) 事件记录:特定事件类型的条目,包含事件中不同角色的参数。为了简单起见,我们在以下几节中使用记录简称。
一个文档由多个句子组成, D = { s i } i = 1 ∣ D ∣ D=\{ s_i\}_{i=1}^{|D|} D={si}i=1∣D∣;一个句子由多个单词组成, s i = { w j } i = 1 ∣ s i ∣ s_i=\{ w_j\}_{i=1}^{|s_i|} si={wj}i=1∣si∣;这个任务的目的是去解决三个子任务:1) 实体抽取:从文档中提取实体 ε = { e i } i = 1 ∣ ε ∣ \varepsilon =\{e_i\}_{i=1}^{|\varepsilon|} ε={ei}i=1∣ε∣作为参数候选。一个实体可能在文档中有多次提及。2) 事件类型检测:检测文档表示的特定事件类型。3) 事件记录提取:从实体中为所表达的事件找到合适的论元,这是最具挑战性的,也是本文的重点。该任务不需要识别事件触发器,这减少了注释的人工工作量,应用场景变得更加广泛。
3、方法
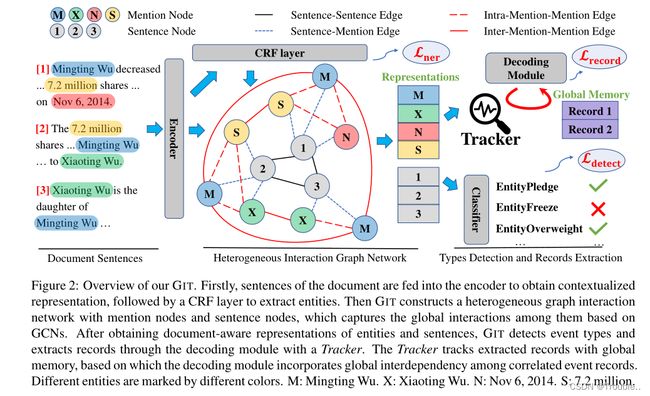
如图2所示,GIT首先通过句子级神经网络提取器提取候选实体(第3.1节)。然后,我们构建一个异构图来建模句子和实体提及之间的交互(第3.2节),并检测文档所表达的事件类型(第3.3节)。最后,我们引入了一个跟踪器模块,用全局内存连续跟踪所有记录,其中我们利用记录之间的全局相关性进行多事件提取(第3.4节)。
3.1 实体抽取
对于一个被给的句子 s = { w j } j = 1 ∣ S ∣ ∈ D s=\{w_j\}_{j=1}^{|S|} \in D s={wj}j=1∣S∣∈D,我们使用Transformer去编码 s s s转化为一个向量 { g j } j = 1 ∣ s i ∣ \{ g_j\}_{j=1}^{|s_i|} {gj}j=1∣si∣:
{ g 1 , . . . , g ∣ s ∣ } = T r a n s f o r m e r ( { w 1 , . . . , w ∣ s ∣ } ) \{ g_1,...,g_{|s|}\} =Transformer(\{w_1,...,w_{|s|}\}) {g1,...,g∣s∣}=Transformer({w1,...,w∣s∣})
这个字表征 w j w_j wj对应的是每个token的表征和位置嵌入的求和。
我们在句子级别提取实体,并将其表述为具有BIO(Begin,Inside,Other)模式的序列标注任务。我们利用条件随机场(CRF)层来识别实体。对于训练,我们将以下损失降至最低:
L n e r = − ∑ s ∈ D l o g P ( y s ∣ s ) L_{ner}=- \sum_{s \in D} logP(y_s|s) Lner=−s∈D∑logP(ys∣s)
其中, y s y_s ys是句子 s s s的正确标签序列。对于推理阶段,我们使用维特比算法以最大概率解码标签序列。
3.2 异构图交互网络
一个事件可能跨越文档中的多个句子,这意味着其对应的实体提及也可能分散在不同的句子中。在跨句子上下文中识别和建模这些实体提及是文档事件抽取的基础。因此,我们构建了一个异构图 G G G,其中包含文档 D D D中的实体提及节点和句子节点。在图 G G G中,可以显式地建模多个实体提及和句子之间的交互。对于每个实体提及结点 e e e,我们初始化节点嵌入 h e ( 0 ) = M e a n ( { g j } j ∈ e ) h_e^{(0)}=Mean(\{g_j\}_{j \in e}) he(0)=Mean({gj}j∈e) 通过对所包含单词的表征进行平均。对于每个句子节点 s s s,我们初始化节点嵌入 h s ( 0 ) = M a x ( { g i } j ∈ s ) + S e n t P o s ( s ) h_s^{(0)}=Max(\{ g_i \}_{j \in s})+SentPos(s) hs(0)=Max({gi}j∈s)+SentPos(s),通过最大池化句子中单词的所有表示加上句子位置嵌入。
为了捕捉句子和提及之间的互动,我们引入了四种类型的边缘。
Sentence-Sentence Edge (S-S) 句子节点通过S-S边彼此完全连接。通过这种方式,我们可以通过句子级交互轻松地捕获文档中的全局属性,例如,文档中任意两个单独句子之间的长距离依赖关系将通过S-S边缘有效地建模。
Sentence-Mention Edge (S-M) 我们用S-M边缘来建模特定句子中实体提及的局部上下文,特别是连接提及节点及其所属句子节点的边缘。
Intra-Mention-Mention Edge ( M − M i n t r a M-M_{intra} M−Mintra) 我们将同一句子中不同的实体提及与M-Mintra边连接起来。一个句子中同时出现的提及表明这些提及很可能涉及同一事件。我们通过M-Mintra边缘明确地对该指示进行建模。
Inter-Mention-Mention Edge (M-M i n t e r _{inter} inter) 对应于同一实体的实体提及通过M-Minter边彼此完全连接。正如在文档事件抽取中,一个实体通常对应于跨句子的多次提及,因此我们使用M-Minter边缘来跟踪特定实体的所有出现位置,这有助于从全局角度进行远距离事件提取。
在4.5节中我们的展现了四种边在事件抽取中发挥了巨大的作用,缺一不可。
在异构图构建之后,我们应用多层图卷积网络来建模全局交互。给定第 l l l层的节点 u u u,图卷积运算定义如下:
h u ( l + 1 ) = R e L U ( ∑ k ∈ K ∑ v ∈ N k ( u ) ∪ { u } 1 c u , k W k ( l ) h v ( l ) ) h_u^{(l+1)}=ReLU(\sum_{k \in K} \sum_{v \in N_k(u) \cup\{ u \} } \frac{1}{c_{u,k}}W_k^{(l)}h_v^{(l)}) hu(l+1)=ReLU(k∈K∑v∈Nk(u)∪{u}∑cu,k1Wk(l)hv(l))
其中 K K K表示不同类型的边, W k ( l ) ∈ R d m × d m W_k^{(l)} \in \R^{d_m \times d_m} Wk(l)∈Rdm×dm是可训练的参数。 N k ( w ) N_k(w) Nk(w)指的是结点 u u u的第 k k k种类型的的邻居节点, c u , k c_{u,k} cu,k代表的是归一化常数。结点 u u u的最终隐藏状态 h u h_u hu为:
h u = W a [ h u ( 0 ) ; h u ( 1 ) ; . . . , h u ( L ) ] h_u=W_a[h_u^{(0)};h_u^{(1)};...,h_u^{(L)}] hu=Wa[hu(0);hu(1);...,hu(L)]
h u ( 0 ) h_u^{(0)} hu(0)代表的是结点 u u u的初始结点嵌入, L L L代表GCN的层数。
最后,我们获得句子嵌入矩阵 S = [ h 1 T h 2 T . . . h ∣ D ∣ T ] ∈ R d m × ∣ D ∣ S=[h_1^T\ h_2^T\ ...\ h_{|D|}^T] \in \R^{d_m \times |D|} S=[h1T h2T ... h∣D∣T]∈Rdm×∣D∣,实体嵌入矩阵 E ∈ R d m × ∣ ε ∣ E \in \R^{d_m \times |\varepsilon|} E∈Rdm×∣ε∣第 i i i个实体可能有许多提及,其中我们简单地使用字符串匹配来检测之后的实体共现引用,并且实体嵌入 E i E_i Ei通过其提及实体节点嵌入的平均值来计算, E i = M e a n ( { h j } j ∈ M e n t i o n ( i ) ) E_i=Mean(\{ h_j\}_{j \in Mention(i)}) Ei=Mean({hj}j∈Mention(i))。这样,句子和实体以上下文感知的方式交互表示。
3.3 事件类型检测
由于文档可以表达不同类型的事件,因此我们将任务制定为多标签分类,并利用句子特征矩阵 S S S检测事件类型:
A = M u l t i H e a d ( Q , S , S ) ∈ R d m × T A=MultiHead(Q,S,S) \in \R^{d_m \times T} A=MultiHead(Q,S,S)∈Rdm×T
R = S i g m o i d ( A T W t ) ∈ R T R=Sigmoid(A^T W_t) \in \R^T R=Sigmoid(ATWt)∈RT
其中 Q ∈ R d m × T Q \in \R^{d_m \times T} Q∈Rdm×T, W t ∈ R d m W_t \in \R^{d_m} Wt∈Rdm是可训练参数, T T T指的是可能的事件类型数量。 M u l t i H e a d MultiHead MultiHead指的是标准的多头注意力机制,带有QKV。因此在这个事件类型检测损失函数为:
L d e t e c t = − ∑ t = 1 T Π ( R ^ t = 1 ) l o g P ( R t ∣ D ) + Π ( R ^ t = 0 ) l o g ( 1 − P ( R t ∣ D ) ) L_{detect}=-\sum_{t=1}^{T} \Pi (\hat R_t=1)logP(R_t|D)+\Pi(\hat R_t=0)log(1-P(R_t|D)) Ldetect=−t=1∑TΠ(R^t=1)logP(Rt∣D)+Π(R^t=0)log(1−P(Rt∣D))
正确的标注为 R ^ ∈ R T \hat R \in \R^T R^∈RT。
3.4 事件记录抽取
由于一个文档可能会表达多个事件记录,并且无法提前知道记录的数量,因此我们通过像以前的方法一样有序地扩展树来解码记录。然而,他们独立处理每个记录。相反,为了结合事件记录之间的相互依赖性,我们提出了一个跟踪器模块,它提高了模型性能。
为了独立,我们在本段中引入了有序树扩展。在每个步骤中,我们提取特定事件类型的事件记录。论元抽取的顺序是预定义的,以便将提取建模为受约束的树扩展任务。以股权冻结记录为例,如图3所示,我们首先提取EquityHolder,然后是FrozeShares等。从虚拟根节点开始,树通过按顺序预测论元来扩展。由于事件参数角色可能存在多个符合条件的实体,因此当前节点将在提取过程中展开多个分支,并将不同的实体分配给当前角色。该分支操作被制定为多标签分类任务。这样,从根节点到叶节点的每个路径都被标识为唯一的事件记录。
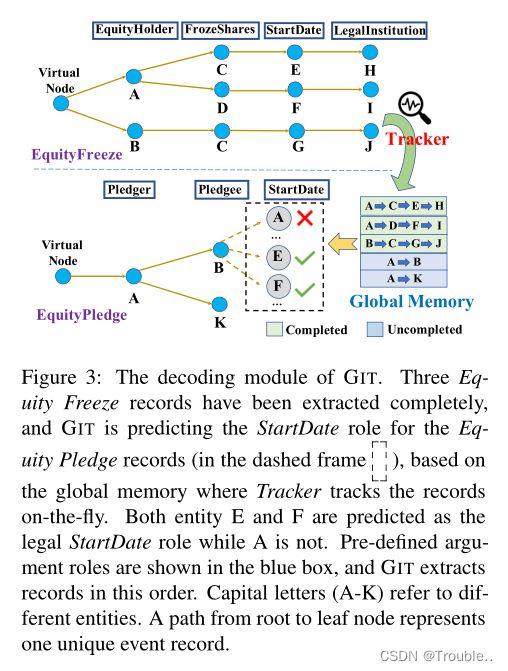
不同事件记录之间存在广泛的相互依赖性。例如,如图1所示,股权不足(Equity Underweight)事件记录与股权超重(Equity Overweight)事件记录密切相关,它们可能共享一些关键论点或提供有用的推理信息。为了利用这种相互依赖性,我们提出了一种受记忆网络启发的新型跟踪器模块。直观地说,跟踪器在飞行中不断跟踪提取的记录,并将信息存储到全局存储器中。当预测当前记录的参数时,模型将查询全局内存,从而利用其他记录的有用相关性信息。
具体而言,对于由实体序列组成的第 i i i条记录路径,跟踪器将对应的实体表示序列 U i = [ E i 1 , E i 2 , . . . ] U_i=[E_{i1},E_{i2},...] Ui=[Ei1,Ei2,...]编码为具有LSTM(最后隐藏状态)的向量 G i G_i Gi,并添加事件类型嵌入。然后,压缩的记录信息被存储在全局存储器 G G G中,它在不同的事件类型之间共享,如图3所示。对于抽取,给定一个记录路径 U i ∈ R d m × ( J − 1 ) U_i \in \R^{d_m \times (J-1)} Ui∈Rdm×(J−1)带有第一个 J − 1 J− 1 J−1个参数角色,我们通过将角色特定信息注入实体表示中来预测第 J J J个角色, E ‾ = E + R o l e J \overline E=E+Role_J E=E+RoleJ,其中 R o l e J Role_J RoleJ是第 J J J角色的角色嵌入。然后,我们将 E ‾ \overline E E、句子特征 S S S、当前实体路径 U i U_i Ui和全局存储器 G G G连接起来,然后使用transformer获得新的实体特征矩阵 E ~ ∈ R d m × ∣ ε ∣ \widetilde E \in \R^{d_m \times |\varepsilon|} E ∈Rdm×∣ε∣,它包含所有实体候选词的全局角色特定信息:
[ E ~ , S ~ , U ~ i , G ~ ] = T r a n s f o r m e r ( [ E ‾ ; S ; U i ; G ] ) [\widetilde E,\widetilde S,\widetilde U_i,\widetilde G]=Transformer([\overline E;S;U_i;G]) [E ,S ,U i,G ]=Transformer([E;S;Ui;G])
我们使用 E ‾ i \overline E_i Ei上的二分类器将路径扩展视为多标签分类问题,即预测第 i i i个实体是否是当前记录的下一个参数角色,并相应地扩展路径,如图3所示。
在训练过程中,我们最小化以下损失函数:
L r e c o r d = − ∑ n ∈ N D ∑ t = 1 ∣ ε ∣ l o g P ( y t n ∣ n ) L_{record}=-\sum_{n \in N_D} \sum_{t=1}^{|\varepsilon|} logP(y_t^n|n) Lrecord=−n∈ND∑t=1∑∣ε∣logP(ytn∣n)
其中, N D N_D ND是事件记录树的节点集合, y t n y_t^n ytn是正确的标注。如果第 t t t个实体对节点 n n n的下一个论元有效,则 y n t = 1 y_n^t=1 ynt=1,否则 y n t = 1 y_n^t=1 ynt=1。
3.5 训练
训练任务被分为三个子任务,总的损失函数将被优化为:
L a l l = λ 1 L n e r + λ 2 L d e t e c t + λ 3 L r e c o r d L_{all}=\lambda_1L_{ner}+\lambda_2L_{detect}+\lambda_3 L_{record} Lall=λ1Lner+λ2Ldetect+λ3Lrecord
4、实验
4.1 数据集
我们在Zheng等人提出的公共数据集上评估了我们的模型,该数据集由中国金融文件构建。它包含多达32000个文档,是迄今为止最大的文档级事件抽取数据集。它关注五种事件类型:股权冻结(Equity Freeze,EF)、股权回购(Equity Repurchase,ER)、股权减持(Equity Underweight,EU)、股权超重(Equity Overweight ,EO)和股权质押( Equity Pledge,EP),共有35种不同的论元角色。我们遵循数据集的标准分割,即training/dev/test集,分别有25632/3204/3204个文档。数据集非常具有挑战性,因为一个文档有20个句子,平均由912个token组成。此外,一个事件记录大约涉及6个句子,29%的文档表达多个事件。
4.2 实验设置
在GIT的实现中,我们分别在编码和解码模块中使用了8层和4层Transformer。隐藏层和前馈层中的维度与之前的工作相同,即768和1024。我们还使用 L = 3 L=3 L=3层GCN,并将dropout rate设置为0.1,batch_size大小设置为64。GIT使用Adam作为优化器进行训练 100个轮次,学习率为 1 e − 4 1e-4 1e−4。我们为损失函数设置 λ 1 = 0.05 \lambda_1=0.05 λ1=0.05, λ 2 = λ 3 = 1 \lambda_2=\lambda_3=1 λ2=λ3=1。
4.3 Baseline 和 评价指标
Baseline Model:
- DCFEE
- Doc2EDAG
- Greedy-Dec
metric:
- F-score
4.4 主要的结果
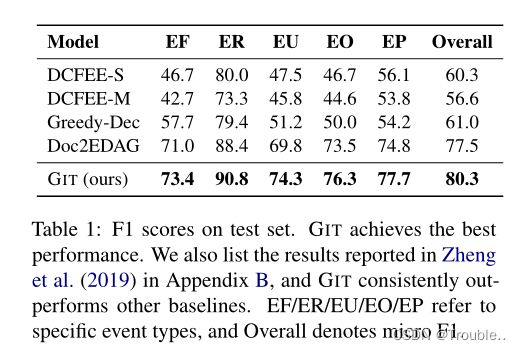
几种baseline模型在测试集上的结果。GIT的效果均好于其他的模型,并且在EU评测上,效果提升了4.5%F1。
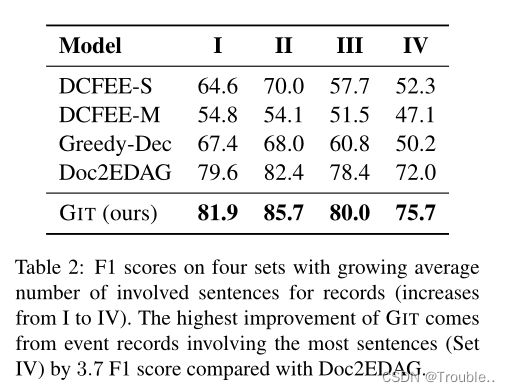
大多数事件可能存在多个句子中,按照事件的抽取难度进行划分,也就是按照每个事件记录的平均句子数进行划分为I/II/III/IV,其中IV难度最大,下面是各种模型在不同难度事件记录下的效果。
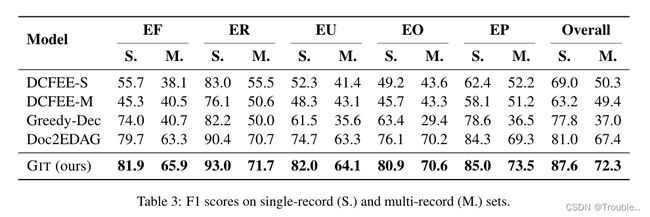
为了验证GIT引起的跟踪器能有效地利用事件间的全局相关信息,并且该信息在多事件案例中是非常重要的。为了证实GIT跟踪器的有效性,我们将测试集数据划分为单事件记录集(S.)和多事件记录集合(M.),划分的依据是文档中存在的事件记录数。下表4展示了结果。
4.5 分析(消融实验)
我们深入的分析了GIT的关键模块。
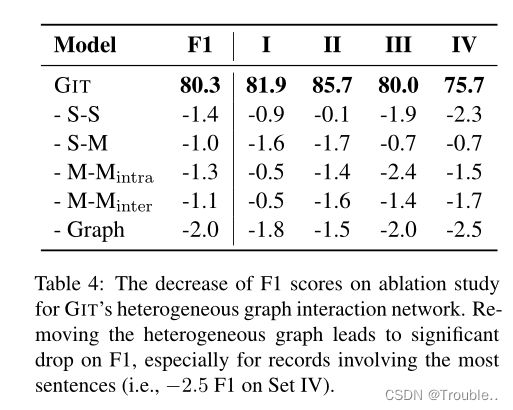
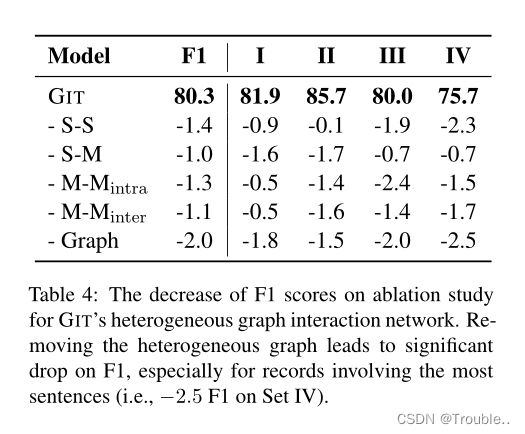
异构图交互网络的有效性。我们构建的异构图包含四种类型的边。为了探索它们的功能,我们一次删除一种类型的边,最后删除整个图网络。结果如表4所示,包括四个集合中的micro F1和F1,它们与我们之前所做的一样,被记录的相关句子的数量所划分。micro F1将减少1.0∼ 1.4没有确定类型的边缘。此外,删除整个图形会导致2.0 F1的显著下降,特别是对于数据集IV,下降2.5,这需要最多的句子来提取事件记录。它表明,图形交互网络有助于提高性能,尤其是在涉及多个句子的记录上,并且各种边缘在提取中起着重要作用。

跟踪器模块的有效性。GIT可以根据Tracker跟踪的其他事件记录的信息,利用记录之间的相互依赖性。为了探究其影响,首先,我们通过在提取另一个新事件类型的事件时清除全局内存,来删除不同事件类型的记录之间的全局相关性信息。接下来,我们删除记录自身路径之外的所有跟踪信息,以探究其他记录的跟踪是否确实有效(GIT-Own Path)。最后,我们删除了整个跟踪器模块(GIT No Tracker)。如表5所示,GIT-OT/GIT-OP中的F1减少了0.5/1.2,这表明相同和不同事件类型的记录之间的相互依赖性确实发挥了重要作用。此外,M.的F1下降0.7/1.5比S.的F1下降0.8/1.0,验证了跟踪器在多事件场景中的有效性。此外,GIT-OP和GIT-NT的表现相似,这也提供了其他记录确实有帮助的证据。我们还在图4中显示了具有不同记录数的文档上的F1。随着记录数的增加,具有或不具有Tracker的模型之间的差距会增大,这验证了Tracker的有效性。
4.6 案例研究
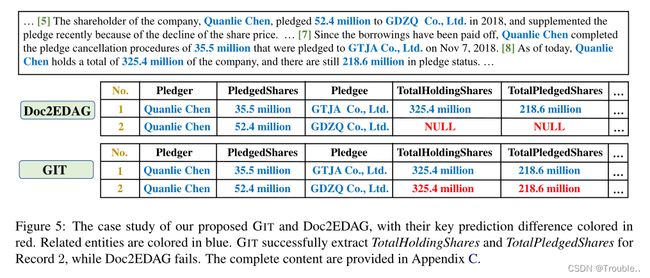
图5展示了Doc2EDAG和GIT对股权质押(Equity Pledge,EP)事件类型的预测案例。TotalHoldingShares和TotalPledgedShares信息位于第8句,而记录2的质押股份和质押人信息位于第5句。虽然Doc2EDAG未能提取记录2中的这些参数(红色),但GIT成功了,因为它可以捕获长距离句子之间的交互,并利用记录1的信息(3.254亿和2.186亿)。
5、相关工作
句子级事件抽取。以往的方法主要集中于句子级事件提取。Chen等人提出了一种神经网络管道模型,该模型首先识别触发器,然后提取论点角色。Nguyen等人使用联合模型同时提取触发器和论证角色。一些研究还利用了依赖树信息。为了利用更多的知识,一些研究利用了文档上下文、预训练语言模型和显性外部知识,如WordNet。Du和Cardie也尝试以问答方式提取事件。这些研究通常在句子级事件提取数据集ACE05上进行实验。然而,句子级模型很难提取跨句子的多个限定事件片段,这在现实场景中更为常见。
文档级事件抽取。文档级事件抽取最近受到越来越多的关注。Yang和Mitchell使用定义明确的特征来处理跨句子的事件论元关系,不幸的是,这非常重要。Yang等人从中心句子中提取事件,并分别从相邻句子中找到其他论点。尽管Zheng等人使用Transformer来融合句子和实体,但忽略了事件之间的相互依赖性。Du和Cardie试图以多粒度的方式对句子进行编码,Du等人利用seq2seq模型。他们在MUC-4数据集上进行了实验,该数据集包含1700个文档和5种基于实体的参数,并将其制定为表格填充任务,以处理单个事件类型的单个事件记录。然而,我们的工作与这些研究的不同之处在于:a)我们利用异构图来建模句子和提及之间的全局交互,以捕获跨句子上下文;b)我们通过跟踪器利用全局相关性来提取多个事件类型的多个事件记录。
6、总结
尽管在实际应用中很有前景,但文档级事件抽取仍面临一些挑战,如参数分散现象和单个文档所表达的多个相关事件。为了应对这些挑战,我们引入了基于异构图的交互模型(带有跟踪器)(GIT)。GIT使用异构图形交互网络来建模句子和实体提及之间的全局交互。GIT还使用跟踪器跟踪提取的记录,以考虑提取过程中的全局相关性。在大规模公共数据集上的实验显示,GIT比先前的技术水平高出了2.8 F1。进一步的分析验证了GIT的有效性,尤其是在跨句子事件提取和多事件场景中。
单个文档所表达的多个相关事件*。为了应对这些挑战,我们引入了基于异构图的交互模型(带有跟踪器)(GIT)。GIT使用异构图形交互网络来建模句子和实体提及之间的全局交互。GIT还使用跟踪器跟踪提取的记录,以考虑提取过程中的全局相关性。在大规模公共数据集上的实验显示,GIT比先前的技术水平高出了2.8 F1。进一步的分析验证了GIT的有效性,尤其是在跨句子事件提取和多事件场景中。