李沐老师 PyTorch版——线性回归 + 基础优化算法(1)
文章目录
- 前言
- 08 线性回归 + 基础优化算法
-
- torch.normal 正太分布
- torch.arange
- torch.randn
- torch.matmul
- plt.scatter
- linear-regression-scratch.ipynb
-
- 生成随机样本
- 定义模型
- 定义损失函数
- 定义优化算法
- 定义训练
前言
在李老师的《动手学深度学习》系列课程的学习过程中,李老师深入浅出地介绍了不少实打实的知识点。不过在李老师代码实现的过程中,确确实实地暴露出了自己许多知识点上的缺失。例如对 Python 高级索引的不了解、PyTorch 许多包的不了解。自己经常在 jupyter 的课件中做出一些注释,不过还是想着把一些比较重要的内容拿出来,做认真总结和深化。有的时候我不一定会把 jupyter 拿出来反复看,但是可以在这里记录自己的学习和成长。
08 线性回归 + 基础优化算法
- chapter_linear-networks
- linear-regression-scratch.ipynb
- linear-regression-concise.ipynb
由于李老师给的课件是 ipynb 的文件,针对一些函数我自己决定模仿实现,其实可以选择在 ipynb 文件中仿写,但是不方便放在一起的总结回顾,所以我选择在 pycharm 中进行总结。在 pycharm 中如何添加一个 anaconda 已创建好的环境呢?可以参考这个链接。
torch.normal 正太分布
torch.normal文档
torch.normal(mean, std, size, *, out=None) → Tensor.
我们往往需要指定 mean 和 std 以及输出张量的形状 size。
>>> torch.normal(2, 3, size=(1, 4)) # size 传入一个元组
tensor([[-1.3987, -1.9544, 3.6048, 0.7909]])
torch.arange
torch.arange文档
torch.arange(start=0, end, step=1, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
返回一个 1-D tensor 数组,大小是 ⌈ end-start step ⌉ \left\lceil\frac{\text { end-start }}{\text { step }}\right\rceil ⌈ step end-start ⌉,取值区间是 [ s t a r t , e n d ) [start, end) [start,end),区间内离散取值的步长由 step 决定。
>>> torch.arange(5) # start=0
tensor([ 0, 1, 2, 3, 4])
>>> torch.arange(1, 4) # step=1
tensor([ 1, 2, 3])
>>> torch.arange(1, 2.5, 0.5)
tensor([ 1.0000, 1.5000, 2.0000])
torch.randn
torch.randn文档
torch.randn(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
返回来自标准正太分布的随机数张量。由 size 指定返回的张量形状,size 可以是列表或者元素。
>>> torch.randn(2,3)
tensor([[ 1.0009, 2.1924, -0.6118],
[ 1.3229, 0.7500, 1.9034]])
>>> torch.randn([2,3])
tensor([[ 0.9694, -0.3568, 0.3278],
[-1.1396, 0.2060, -0.4477]])
>>> torch.randn((2,3))
tensor([[ 1.4538, 1.4367, 1.6953],
[ 0.1987, 0.4661, -1.6386]])
torch.matmul
torch.matmul文档
torch.matmul(input, other, *, out=None) → Tensor
在文档中介绍的情况比较复杂,这里仅简单的探讨两种情况。
第一,两个 1-D tensor 参与运算,结果是两个向量的点乘 dot product 结果,也就是 0-D 一个数字。
>>> a = torch.randn(3)
>>> b = torch.randn(3)
>>> torch.matmul(a,b)
tensor(0.8469)
>>> torch.matmul(a,b).size()
torch.Size([])
第二,两个 2-D tensor 参与运算,两个矩阵乘法 matrix-matrix product。
>>> tensor1 = torch.randn(3, 4)
>>> tensor2 = torch.randn(4, 5)
>>> torch.matmul(tensor1, tensor2).shape
torch.Size([3, 5])
plt.scatter
scatter文档
Axes.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, *, edgecolors=None, plotnonfinite=False, data=None, **kwargs)
x, y → 散点的坐标
s → 散点的面积
c → 散点的颜色(默认值为蓝色,‘b’,其余颜色同plt.plot( ))
marker → 散点样式(默认值为实心圆,‘o’,其余样式同plt.plot( ))
alpha → 散点透明度([0, 1]之间的数,0表示完全透明,1则表示完全不透明)
linewidths →散点的边缘线宽
edgecolors → 散点的边缘颜色
关于散点的具体样式可以参考知乎文章
linear-regression-scratch.ipynb
生成随机样本
根据带有噪声的线性模型构造一个人造数据集。 我们使用线性模型参数 w = [ 2 , − 3.4 ] ⊤ 、 b = 4.2 \mathbf{w}=[2,-3.4]^{\top} 、 b=4.2 w=[2,−3.4]⊤、b=4.2 和噪声项 生成数据集及其标签: y = X w + b + ϵ \mathbf{y}=\mathbf{X} \mathbf{w}+b+\epsilon y=Xw+b+ϵ
# 根据 w b 生成数据集
def synthetic_data(w, b, num_examples):
x = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(x, w) + b
y += torch.normal(0, 0.01, y.shape)
return x, y
true_w = torch.tensor([2, -3.4])
true_b = 4.2
batch_size = 10
features, labels = synthetic_data(true_w, true_b, 1000)
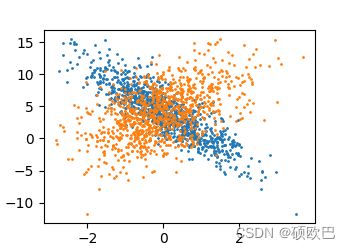
我们可以画出生成的样本数据。
# 设置绘图的边框大小,不必完全展示所有的点
d2l.set_figsize()
# 第1列的数据因为 w 为负,所以数据是负相关
# s 代表着散点的面积
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), s=1)
d2l.plt.scatter(features[:, 0].detach().numpy(), labels.detach().numpy(), s=1)
d2l.plt.show()
定义一个样本数据的迭代函数,以实现小批量随机梯度下降优化我们的模型参数。该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。
# 根据批量大小,返回特征样本和对应的标签
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = indices[i:min(num_examples, i + batch_size)]
# print(batch_indices)
yield features[batch_indices], labels[batch_indices]
定义模型
# 定义模型,将模型的输入和参数同模型的输出关联起来
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
定义损失函数
# 定义损失函数,这里之前有点问题,因为 y.shape = torch.tensor([10])
# y_hat.shape = torch.tensor([10,1])
def squared_loss(y_hat, y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
定义优化算法
# 定义优化算法
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
# 我们对 batch_size 个样本使用损失函数计算自动求导得到的梯度是累计效果,在此我们求平均值
param -= param.grad * lr / batch_size
# pytorch会不断的累加变量的梯度,所以每更新一次参数,都要使对应的梯度清零
param.grad.zero_()
定义训练
lr = 0.03
epochs = 10
net = linreg
loss = squared_loss
for epoch in range(epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y)
# print(l.shape)
l.sum().backward()
sgd([w, b], lr, batch_size)
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
# python 的 format 用法
print(f'epoch{epoch + 1},loss{float(train_l.mean()):.7f}')