【学习笔记】模糊控制算法
本文目录
-
- 0. 前言
- 1. 概述
- 2. 模糊集合
-
- 2.1 集合和论域
- 2.2 模糊集合的概念
- 2.3 模糊集合的表示方式
- 2.4 模糊集合的运算
- 3. 模糊关系与模糊关系合成
-
- 3.1 笛卡尔积
- 3.2 关系与模糊关系
- 3.3 模糊关系的运算
- 3.4 模糊关系合成
- 3.5 模糊变换
- 4. 模糊推理
-
- 4.1 模糊推理规则【重要!】
- 4.2 模糊推理合成
- 5. 模糊控制
-
- 5.1 基本思路
- 5.2 输入模糊化
- 5.3 模糊决策
-
- 5.3.1 综合法
- 5.3.2 并行法
- 5.4 输出逆模糊化(清晰化)
0. 前言
课程《智能控制基础》学习了模糊控制算法,写篇博客整理一下思路。
1. 概述
模糊性来源于事物的复杂性和发展变化性(不确定性)。 所谓模糊,即是对一些常用的概念无法量化,如生活中的冷和热,高个子,青年人等概念,对于这样的概念,传统的集合论无能为力,因此美国的控制论专家 L . A . Z a d e h L.A.Zadeh L.A.Zadeh 于 1965 年提出了模糊集合用以描述模糊概念。
所谓模糊,即不再是传统的二值逻辑,非此即彼,而是用一个隶属函数 μ A ( x ) \mu _A\left( x \right) μA(x) 来表示 x x x属于 A A A的程度, μ A ( x ) \mu _A\left( x \right) μA(x)的取值在0到1之间。

此外,还需要注意模糊性和随机性的区别,这个在之后可能会时常遇到。
- 模糊性是由于对象无精确定义造成的,因此,描述它需要使用到隶属函数。
- 随机性是在事件是否发生的不确定性中表现出来的不确定性,而事件本身的状态和类属是确定的。
2. 模糊集合
2.1 集合和论域
所谓集合,是指具有某种属性的、确定的、彼此间可以区别的事物的全体。比如全班同学的年龄,集合为{20,21,22}。
在这些被考虑对象的所有元素的全体称为论域,即全班同学的年龄;每个对象称为元素或元,即每个同学的年龄。
2.2 模糊集合的概念
设 X X X是论域, A A A是定义在 X X X上的一个模糊集合,对于 ∀ x ∈ X \forall x\in X ∀x∈X,定义实值函数 μ A ( x ) ∈ [ 0, 1 ] \mu _A\left( x \right) \in \left[ \text{0, }1 \right] μA(x)∈[0, 1]为 x x x属于集合 A A A的隶属度。 μ A ( x ) \mu _A\left( x \right) μA(x)也称为隶属函数。
举个例子,下图是成年人(非法定定义)这个模糊集合对应的隶属度函数曲线,可以看到,当年龄小于18时,隶属度小于0.5,“不怎么属于”,大于18岁时,隶属度大于0.5且在逐渐增长,符合一般规律。
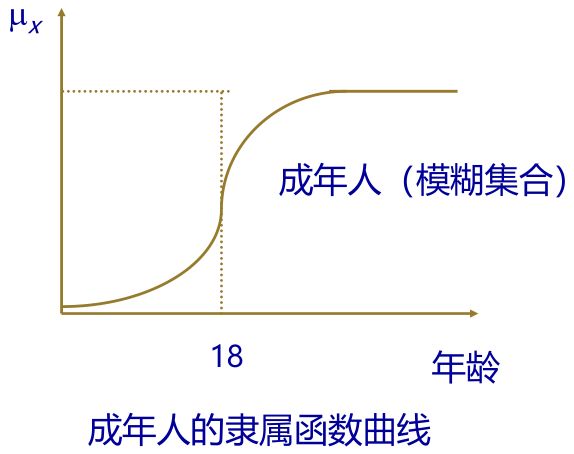
-
常见的隶属度函数曲线
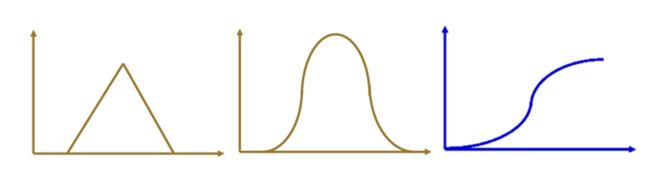
上图只是一个例子,在实际计算时,往往会根据实际情况设定隶属度,常见的隶属函数(Membership Function)有三角形、钟形、S形等。
-
模糊集合关系
-
相等

-
包含于

-
2.3 模糊集合的表示方式
- 向量表示法

- Zadeh表示法

- 序偶表示法

举个例子:


2.4 模糊集合的运算

举个例子:

3. 模糊关系与模糊关系合成
3.1 笛卡尔积
对于集合的笛卡尔积,是指给定两个集合X和Y,由全体(x, y)组成的集合( x ∈ X , y ∈ Y x\in X, y\in Y x∈X,y∈Y),叫做X与Y的笛卡尔积(或称直积)。记作 X × Y X\times Y X×Y
X × Y = { ( x , y ) ∣ x ∈ X , y ∈ Y } X\times Y=\left\{ \left( x, y \right) |x\in X, y\in Y \right\} X×Y={(x,y)∣x∈X,y∈Y}
这样直接看定义可能会有点懵,简单理解就是X中的每个元素和Y的每个元素一一配对,比如X={1,2}, Y={3, 4},那么 X × Y X\times Y X×Y={(1,3), (1,4), (2,3), (2,4)}。
笛卡尔积在很多场合都有使用,比如多重循环,多自变量函数图形的绘制等。
3.2 关系与模糊关系
所谓关系,是基于笛卡尔积提出的:存在两个集合X和Y,它们的笛卡尔积 X × Y X\times Y X×Y的一个子集R叫做X到Y的二元关系,简称关系 R ⊆ X × Y R\subseteq X\times Y R⊆X×Y。
怎么理解这个概念呢? 可以把X和Y想象成一个直角坐标系的横纵坐标,那么 X × Y X\times Y X×Y实际上就是形成的一个个网格点的坐标(或许这就是直角坐标系也叫笛卡尔坐标系的原因吧~),由于R为 X × Y X\times Y X×Y的子集,所以就相当于取了其中的一些点——类比线性规划,画一条直线(或曲线),那么平面上的点就被分为三部分:曲线内(左)、曲线上、曲线外(右),而R就相当于取其中的某部分。
如果令属于关系R的点取1,不属于R的点取0,那么R将是 一个 m × n m\times n m×n,且全部由0或1构成的矩阵。
举个例子:

理解了关系,那模糊关系自然也能理解了,从上文得知,关系矩阵R中的元素都是0或1,那么模糊关系矩阵中元素的取值就是[0, 1],其大小反应了这个元素隶属于R的程度。
同样以上述例子为例,定义关系:“中心点”,用各点离中心点的距离来表示,那模糊关系矩阵R可以表示为:
R = [ 0 0.1 0.3 0.1 0 0.1 0.5 0.7 0.5 0.1 0.3 0.7 1 0.7 0.3 0.1 0.5 0.7 0.5 0.1 0 0.1 0.3 0.1 0 ] R=\left[ \begin{matrix} 0& 0.1& 0.3& 0.1& 0\\ 0.1& 0.5& 0.7& 0.5& 0.1\\ 0.3& 0.7& 1& 0.7& 0.3\\ 0.1& 0.5& 0.7& 0.5& 0.1\\ 0& 0.1& 0.3& 0.1& 0\\ \end{matrix} \right] R=⎣ ⎡00.10.30.100.10.50.70.50.10.30.710.70.30.10.50.70.50.100.10.30.10⎦ ⎤
再举个例子:


3.3 模糊关系的运算
得到模糊关系之后,可能会需要对多个模糊关系进行运算,即对模糊矩阵取交、并、补的运算。但是需要注意:进行运算的模糊关系矩阵一定是同型矩阵! 否则无法进行运算。

3.4 模糊关系合成
所谓模糊关系的合成,是指由第一个集合和第二个集合之间的模糊关系,及第二个集合和第三个集合之间的模糊关系,得到第一个集合和第三个集合之间的模糊关系的一种运算。
其运算规律为

这样看会很懵,所以来看个例子。


从这个例子当中,我们可以看出很多东西:
- 首先是矩阵的型,要求两个合成的矩阵的型要满足矩阵乘法的形式,即前一个矩阵的列数等于后一个矩阵的行数;
- 其次是计算规律,感觉可以和矩阵乘法类比:同一行乘以同一列,每一行中的每个元素相乘之后再相加,得到对应行和列的一个元素,那么在这个运算中,相乘相当于取与,相加相当于取或。
3.5 模糊变换
已知两个集合之间的模糊关系,由一个集合上的模糊子集经过运算得到另一个集合上的模糊子集。从输入的模糊量求输出的模糊量。此即模糊变换。
设有限集 X = { x 1 , x 2 , . . . , x m } X=\left\{ x_1,x_2,...,x_m \right\} X={x1,x2,...,xm} Y = { y 1 , y 2 , . . . , y n } \,\,Y=\left\{ y_1,y_2,...,y_n \right\} Y={y1,y2,...,yn},R是 X × Y X\times Y X×Y上的模糊关系,A和B分别为X和Y上的模糊集,且满足
![]()
则称B是A的象,A是B的原象,上式称为X到Y上的一个模糊变换。
举个例子:

这个例子有点抽象,个人觉得可以先掌握这种运算方式,然后在实际问题中去理解。
4. 模糊推理
4.1 模糊推理规则【重要!】
模糊推理的规则实际上是根据前面的理论基础总结出来的一些可以直接使用的结论。
- (i)设 A ∈ F ( U ) , B ∈ F ( V ) A\in F\left( U \right) , B\in F\left( V \right) A∈F(U),B∈F(V),模糊条件语句为 “如果A,则B”。
这个推理规则用模糊关系R表示为:
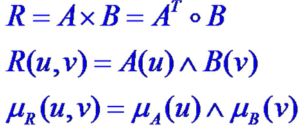
此即Mamdani推理。上式中,A和B都是行向量,这样得到的R为 m × n m\times n m×n的矩阵, m m m是A的长度, n n n是B的长度。
第二个式子则是R矩阵的计算方式,因为A和B一行(列)只有一个元素,所以只有“^”号,没有或运算。 - (ii)设 A ∈ F ( U ) , B ∈ F ( V ) , C ∈ F ( V ) A\in F\left( U \right) , B\in F\left( V \right),C\in F\left(V \right) A∈F(U),B∈F(V),C∈F(V),模糊条件语句为 “如果A,则B,否则C”。用模糊关系 R 1 R_1 R1或 R 2 R_2 R2表示为:

- (iii)设 A ∈ F ( U ) , D ∈ F ( U ) , B ∈ F ( V ) A\in F\left( U \right) , D\in F\left( U \right),B\in F\left(V \right) A∈F(U),D∈F(U),B∈F(V),模糊条件语句为 “如果A或D,则B”。
用模糊关系R表示为:
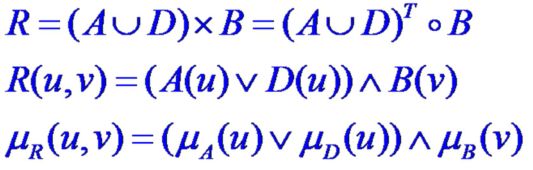
- (iv)设 A ∈ F ( U ) , E ∈ F ( W ) , B ∈ F ( V ) A\in F\left( U \right) , E\in F\left( W \right),B\in F\left(V \right) A∈F(U),E∈F(W),B∈F(V),模糊条件语句为 “如果A且E,则B”。
用模糊关系R表示为:
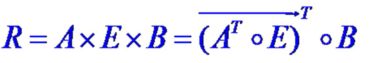

以上这最后一种称为多维模糊条件语句,最为复杂,下面看一个例子,就能理解其中的关键:将元素排为一行变成行向量。



那如果是多个语句,且每个语句都是多维模糊条件语句呢?这就是所谓的多重多维模糊条件语句。
- 多重多维模糊条件语句


4.2 模糊推理合成
从上文中模糊推理规则的表述来看,其实模糊推理规则本质上就是一种模糊变换,它将一个论域的模糊集变换到另一个论域的模糊集。
即:


因此,一般来说模糊控制要先根据模糊推理规则来综合已知数据建立一个规则库,然后给定一个模糊输入,再求其在规则库下对应的模糊输出。
所以,给定输入,并根据得到的模糊关系矩阵R求出其输出的过程就是模糊推理合成。这里需要注意的是:给定的输入和得到的输出都用“*”表示,不带“*”的量表示已知数据,用来推导模糊关系矩阵。
先来看个例子。
已知 A = 1 e 1 + 0.5 e 2 , B = 0.1 e c 1 + 0.6 e c 2 + 1 e c 3 ,如果 A ,则 B 。 当 A ∗ = 0.8 e 1 + 0.4 e 2 ,求 B ∗ \text{已知}A=\frac{1}{e_1}+\frac{0.5}{e_2}, B=\frac{0.1}{ec_1}+\frac{0.6}{ec_2}+\frac{1}{ec_3}\text{,如果}A\text{,则}B\text{。} \\ \text{当}A^*=\frac{0.8}{e_1}+\frac{0.4}{e_2}\text{,求}B^* 已知A=e11+e20.5,B=ec10.1+ec20.6+ec31,如果A,则B。当A∗=e10.8+e20.4,求B∗
对于这个问题,首先要根据已知的A和B,求出模糊关系矩阵R,然后代入 A ∗ A^* A∗,即可得到其输出 B ∗ B^* B∗。
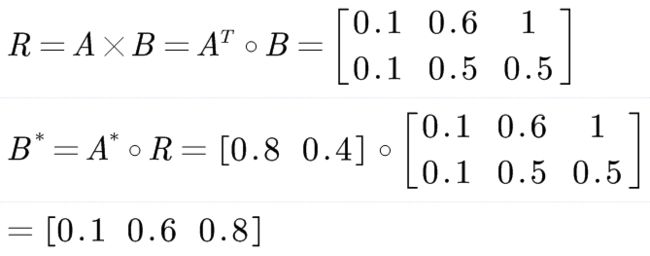
当然,这是按照一般思路来计算的流程,我们不妨代入模糊推理规则的知识,从原理上再来推导一次。首先假设规则库只有一条规则,即由已知的A和B推导出来的。那么:
根据Mamdani推理,有:
当输入一个模糊向量 A ∗ A^* A∗时,有:
![]()
联立上面两式,得到:

其中, α = ⋁ x ∈ X { μ A ∗ ( x ) ∧ μ A ( x ) } \boldsymbol{\alpha }=\bigvee_{\boldsymbol{x}\in \boldsymbol{X}}{\left\{ \boldsymbol{\mu }_{\boldsymbol{A}^*}\left( \boldsymbol{x} \right) \land \boldsymbol{\mu }_{\boldsymbol{A}}\left( \boldsymbol{x} \right) \right\}} α=⋁x∈X{μA∗(x)∧μA(x)},相当于是一个行向量和一个列向量相乘,得到的是一个数,在这里叫 A ∗ A^* A∗和 A A A的适配度。是 A ∗ A^* A∗和 A A A交集的高度。
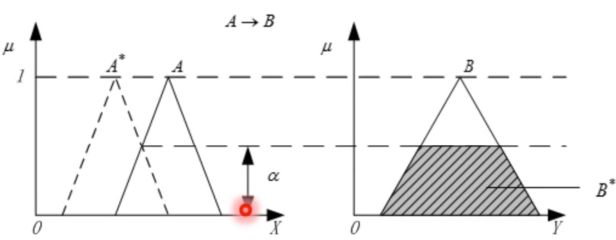
因此,这个问题还可以理解为先计算出输入量和原输入量之间的相似度,然后将其与原输出量相乘,就得到了实际的输出量。
不得不说,这种方式要比第一种方式要简单很多,但是它也有局限性,那就是只适用于单规则问题。
说到单规则,就得先了解模糊合成问题的类型:
- 单输入单规则:模糊推理规则只有一个,且只有一个输入量,即上面那种例子;
- 多输入单规则:模糊推理规则仍只有一个,但是输入量变成多个,这个其实是和推理规则有关,比如:“如果A且B,则C”这类推理规则,它的输入量必须要有两个,这种其实和第一种问题本质上是一样的,只需要把多个输入先转换成一个输入即可,不再赘述。
- 单输入多规则:多规则意味着不再是一个规则,而是变成了规则库:“如果A1,则B1;如果A2,则B2;…;如果An,则Bn”
- 多输入多规则:和单输入的差别只在于规则表述方式不同:“如果A1且B1,则C1;如果A2且B2,则C2;…;如果Am且Bm,则Cm”
因此,对于多规则问题,还是得按照原始思路来算,即先算出模糊关系矩阵R,再代入输入,得到其输出。
5. 模糊控制
5.1 基本思路
所谓模糊控制,一般是用模糊的概念来描述偏差,并通过模糊推测得到模糊的给定量。比如,对偏差的描述常用“正大”,“正小”,“零”,“负小”,“负大”等模糊概念,当偏差为“正大”,偏差变化为“正大”,则阀门开度为“正大”;当偏差为“正小”,偏差变化为“负小”,则阀门开度为“零”。
总结来说,模糊控制一般可以分为下面几个过程:
- 精确的测量值经过输入模糊化过程变成模糊集;
- 利用控制规则进行推理,即模糊决策,得到控制作用的模糊集;
- 将控制作用的模糊集按照一定的规则转化成精确值,此为逆模糊化。
其原理图如下所示:
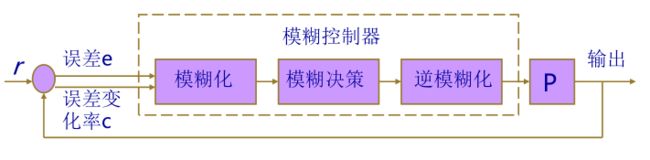
5.2 输入模糊化
输入模糊化,是指将一个精确值化成一个或几个模糊值的单点,即定义为从观察空间到控制输入论域中若干模糊值的映射。
模糊集的个数随被控对象的不同而不同,常用的如下:
- PL/PB —— 正大
- PM —— 正中
- PS —— 正小
- ZE —— 零
- NS —— 负小
- NM —— 负中
- NL/NB —— 负大
输入模糊化一般分为两步:①范围映射,②隶属函数分布。
①范围映射:通常将偏差e与偏差变化率ec的值取在[-6, +6]之间,因此,论域[a, b]转化为论域[-6, +6]的变换公式为:
y = 12 b − a [ x − a + b 2 ] y=\frac{12}{b-a}\left[ x-\frac{a+b}{2} \right] y=b−a12[x−2a+b]
②隶属函数分布:确定映射范围之后,接下来就是确定隶属函数的分布。在这一步常用的有两种方式:函数法和数值法。
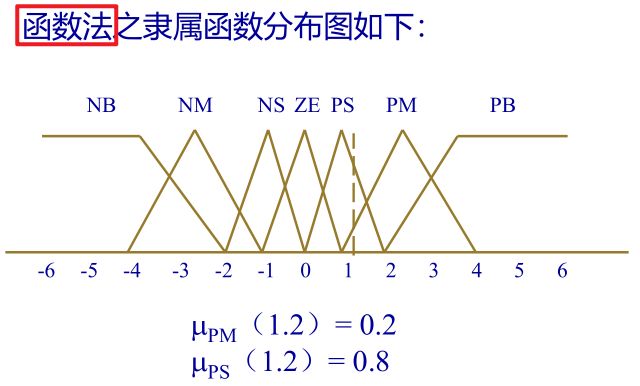
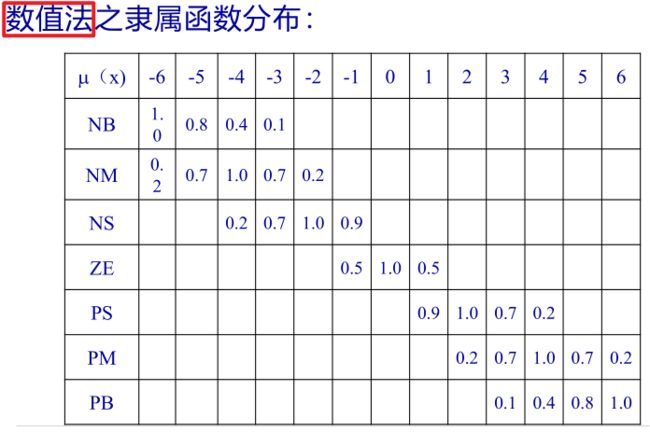
5.3 模糊决策
所谓模糊决策,实质上就是前面提到的模糊推理,模糊变换等操作的组合。其目的在于根据已有数据推出模糊关系,并根据模糊输入得到模糊输出。但是这个考虑的前提一般是多规则问题。也因此衍生出了两种方法,或者说两种理念——综合法和并行法。
5.3.1 综合法
所谓综合法,是指先求出所有模糊规则的模糊集,再根据输入求模糊输出。这个在前面已有类似表述。
5.3.2 并行法
并行法先不求模糊规则对应的模糊集(模糊关系表示),而是利用输入与每条规则的前件进行匹配,确定规则的激励强度。这种方式的好处在于能清楚知道输出模糊集中每条规则所起到的作用的多少以及能够方便地添加、删除和修改规则。
因此,并行法会涉及到一个参数:规则的激励强度 α \alpha α,即前面提到的匹配度参数。
α = ⋁ x ∈ X { μ A ∗ ( x ) ∧ μ A ( x ) } \boldsymbol{\alpha }=\bigvee_{\boldsymbol{x}\in \boldsymbol{X}}{\left\{ \boldsymbol{\mu }_{\boldsymbol{A}^*}\left( \boldsymbol{x} \right) \land \boldsymbol{\mu }_{\boldsymbol{A}}\left( \boldsymbol{x} \right) \right\}} α=x∈X⋁{μA∗(x)∧μA(x)}
在并行法中,也可以分为三种类型的模糊决策。
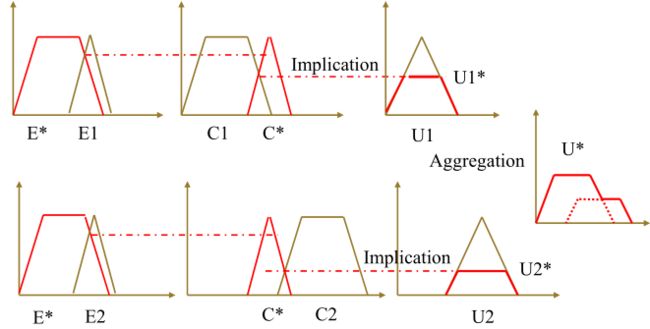
-
最小运算规则型
单个规则输出值与激励强度相与,然后再取所有规则输出值的最大值。【或者说相或值】
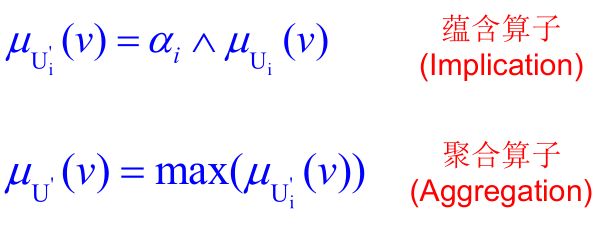
-
乘积运算规则型
单个规则输出值与激励强度相乘,然后再取所有规则输出值的最大值。【或者说相或值】
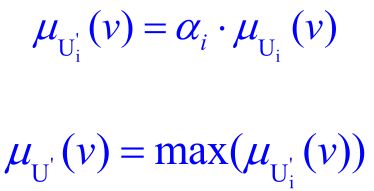

-
状态评价函数型
这种方式和规则表达方式有很大关系。

5.4 输出逆模糊化(清晰化)
通过模糊决策得到模糊输出之后,最后还要对输出值进行逆模糊化,这样得到确切的输出值。常用的逆模糊化的方法有以下几种:
- 最大隶属度法
模糊决策得出的模糊集U的隶属度最大的元素作为控制输出的精确值。 - 加权平均法【也叫重心法】
u = ∑ i = 1 N μ ( u i ) ⋅ u i ∑ i = 1 N μ ( u i ) u=\frac{\sum_{i=1}^N{\mu \left( u_i \right) \cdot u_i}}{\sum_{i=1}^N{\mu \left( u_i \right)}} u=∑i=1Nμ(ui)∑i=1Nμ(ui)⋅ui - 取中位法
将模糊集隶属函数曲线与横坐标之间的面积平分为两等份的数。 - 左取大法、右取大法
左取大:取输出隶属度函数左边达到最大值时对应的变量值作为清晰值;
右取大:取输出隶属度函数右边达到最大值时对应的变量值作为清晰值。
最为常用的还是重心法。