Python数据分析与可视化(3)——NumPy数值计算基础
文章目录
-
- NumPy多维数组
-
- 创建数组对象
- ndarray对象属性和数据转换
- 生成随机数
- 数组变换
- 数组的索引和切片
-
- 一维数组的索引和切片
- 多维数组的索引和切片
- 数值的运算
-
- 数组和标量间的运算
- ufunc函数
- ufunc的广播机制
- 条件逻辑运算
- 数组读写
-
- 读写二进制文件
- 读写文本文件
- 读取csv文件
- NumPy中的数据统计与分析
-
- 排序
- 重复数据与去重
- 常用统计函数
NumPy是在1995年诞生的Python库Numeric的基础上建立起来的,但真正促使NumPy的发行的是Python的SciPy库。但SciPy中并没有合适的类似于Numeric中的对于基础数据对象处理的功能。于是,SciPy的开发者将SciPy中的一部分和Numeric的设计思想结合,在2005年发行了NumPy。
NumPy是Python的一种开源的数值计算扩展库。它包含很多功能,如创建n维数组(矩阵)、对数组进行函数运算、数值积分等。 NumPy的诞生弥补了这些缺陷,它提供了两种基本的对象:
ndarray:是储存单一数据类型的多维数组。
ufunc:是一种能够对数组进行处理的函数。
NumPy常用的导入格式:import numpy as np
NumPy多维数组
创建数组对象
通常来说,ndarray是一个通用的同构数据容器,即其中的所有元素都需要相同的类型。利用array函数可创建ndarray数组。
- 利用array函数创建数组对象
array函数的格式:np.array(object, dtype,ndmin)

import numpy as np
data1 = [1,3,5,7] #列表
w1 = np.array(data1)
print('w1:',w1)
data2 = (2,4,6,8) #元组
w2 = np.array(data2)
print('w2:',w2)
data3 = [[1,2,3,4],[5,6,7,8]] #多维数组
w3 = np.array(data3)
print('w3:',w3)

- 专门创建数组的函数
arange函数:创建等差一维数组
格式:np.arange([start, ]stop, [step, ]dtype)

例:


linspace 函数:创建等差一维数组,接收元素数量作为参数。
格式:np.linspace(start, stop, num, endpoint, retstep=False, dtype=None)

例:

logspace函数:创建等比一维数组
格式:np.logspace(start, stop, num, endpoint=True,
base=10.0, dtype=None))
logspace的参数中,start, stop代表的是10的幂,默认基数base为10,第三个参数元素个数。

zeros函数:创建指定长度或形状的全0数组
格式:np.zeros(shape, dtype=float, order=‘C’)
ones函数:创建指定长度或形状的全1数组
格式:np. ones(shape, dtype=None, order=‘C’)
diag函数:创建一个对角阵。
格式:np.diag(v, k=0)
ndarray对象属性和数据转换
ndarray对象属性及其说明




生成随机数
在NumPy.random模块中,提供了多种随机数的生成函数。如randint函数生成指定范围的随机整数来构成指定形状的数组。
用法:
np.random.randint(low, high = None, size = None)

random模块的常用随机数生成函数

数组变换
- 数组重塑
对于定义好的数组,可以通过reshape方法改变其数据维度。
格式:np.reshape(a, newshape, order=‘C’)
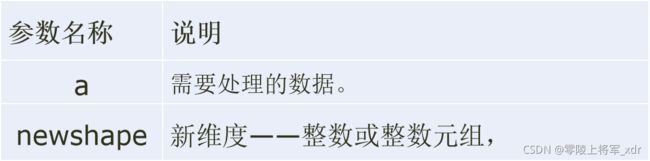

reshape的参数中的其中一个可以设置为-1,表示数组的维度可以通过数据本身来推断。

与reshape相反的方法是数据散开(ravel)或数据扁平化(flatten)。

- 数组合并
hstack函数:实现横向合并
vstack函数:实现纵向组合是利用vstack将数组纵向合并;
concatenate函数:可以实现数组的横向或纵向合并,参数axis=1时进行横向合并,axis=0时进行纵向合并。
arr1 = np.arange(6).reshape(3,2)
arr2 = arr1*2
arr3 = np.hstack((arr1,arr2))
print(arr3)

- 数组分割
与数组合并相反,hsplit函数、vsplit函数和split函数分别实现数组的横向、纵向和指定方向的分割。
arr = np.arange(16).reshape(4,4)
print('横向分割为:\n',np.hsplit(arr,2))
print('纵向组合为:\n',np.vsplit(arr,2))
- 数组转置和轴对换
数组转置是数组重塑的一种特殊形式,可以通过transpose方法进行转置。

除了使用transpose外,可以直接利用数组的T属性进行数组转置。
数组的索引和切片
一维数组的索引和切片
一维数组的索引类似Python中的列表。

数组的切片返回的是原始数组的视图,不会产生新的数据,如果需要的并非视图而是要复制数据,则可以通过copy方法实现。

多维数组的索引和切片
对于多维数组,它的每一个维度都有一个索引,各个维度的索引之间用逗号分隔。
也可以使用整数函数和布尔值索引访问多维数组。
arr = np.arange(12).reshape(3,4)
print(arr)
print(arr[0,1:3]) #索引第0行中第1列到第2列的元素
print(arr[:,2]) #索引第2列元素
print(arr[:1,:1]) #第0行第0列元素

数值的运算
数组和标量间的运算
数组之所以很强大是因为不需要通过循环就可以完成批量计算。

ufunc函数
ufunc函数全称为通用函数,是一种能够对数组中的所有元素进行操作的函数。对一个数组进行重复运算时,使用ufunc函数比使用math库中的函数效率要高很多。
-
常用的ufunc函数运算
常用的ufunc函数运算有四则运算、比较运算和逻辑运算。
1)四则运算:
加(+)、减(-)、乘(*)、除(/)、幂(**)。数组间的四则运算表示对每个数组中的元素分别进行四则运算,所以形状必须相同。
2)比较运算:==、 > 、<、>=、<=、!=。比较运算返回的结果是一个布尔数组,每个元素为每个数组对应元素的比较结果。
3)逻辑运算:
np.any函数表示逻辑“or”,np.all函数表示逻辑“and”, 运算结果返回布尔值。



ufunc的广播机制
广播(broadcasting)是指不同形状的数组之间执行算术运算的方式。需要遵循4个原则:
1)让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在左边加1补齐。
2)如果两个数组的形状在任何一个维度上都不匹配,那么数组的形状会沿着维度为1的维度进行扩展,以匹配另一个数组的形状。
3)输出数组的shape是输入数组shape的各个轴上的最大值。
4)如果两个数组的形状在任何一个维度上都不匹配,并且没有任何一个维度等于1,则引发异常


条件逻辑运算
在NumPy中可以利用基本的逻辑运算就可以实现数组的条件运算。

这种方法对大规模数组处理效率不高,也无法用于多维数组。NumPy提供的where方法可以克服这些问题。
where的用法:
np.where(condition, x, y)
满足条件(condition),输出x,不满足则输出y。

条件为[[True,False], [True,False]],分别对应最后输出结果的四个值,运算时第一个值从[1,9]中选,因为条件为True,所以是选1。第二个值从[2,8]中选,因为条件为False,所以选8,后面以此类推。
 where中若只有条件 (condition),没有x和y,则输出满足条件元素的坐标。这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
where中若只有条件 (condition),没有x和y,则输出满足条件元素的坐标。这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
数组读写
读写二进制文件
NumPy提供了多种文件操作函数存取数组内容。
文件存取的格式分为两类:二进制和文本。而二进制格式的文件又分为NumPy专用的格式化二进制类型和无格式类型。
NumPy中读写二进制文件的方法有:
- np.load(“文件名.npy")是从二进制文件中读取数据;
- np.save(“文件名[.npy]", arr) 是以二进制格式保存数据。
读写文本文件
NumPy中读写文本文件的主要方法有:
- np.loadtxt("…/tmp/arr.txt",delimiter = “,”)把文件加载到一个二维数组中;
- np.savetxt("…/tmp/arr.txt", arr, fmt = “%d”, delimiter = “,”)是将数组写到某种分隔符隔开的文本文件中;
- np.genfromtxt("…/tmp/arr.txt", delimiter = “,”)是结构化数组和缺失数据。
读取csv文件
np.loadtxt(fname, dtype=, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding=‘bytes’)

NumPy中的数据统计与分析
排序
Sort函数对数据直接进行排序,调用改变原始数组,无返回值。
格式:numpy.sort(a, axis, kind, order)
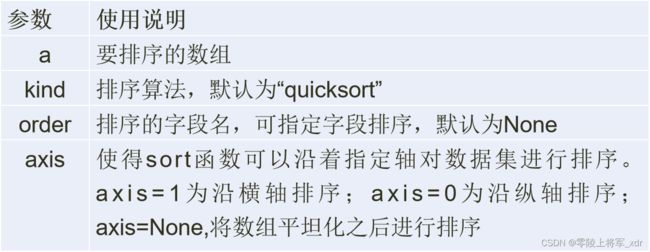

np.argsort函数和np.lexsort函数根据一个或多个键值对数据集进行排序。
np.argsort(): 返回的是数组值从小到大的索引值;
np.lexsort(): 返回值是按照最后一个传入数据排序的结果。
重复数据与去重
在NumPy中,对于一维数组或者列表,unique函数去除其中重复的元素,并按元素由大到小返回一个新的元组或者列表。

统计分析中有时也需要把一个数据重复若干次,使用tile和repeat函数即可实现此功能。
tile函数的格式:np.tile(A, reps)
其中,参数A表示要重复的数组,reps表示重复次数。
repeat函数的格式:np.repeat(A, reps, axis = None)
“a”: 是需要重复的数组元素,
“repeats”: 是重复次数,
“axis”: 指定沿着哪个轴进行重复,axis = 0表示按行进行元素重复;axis = 1表示按列进行元素重复。


常用统计函数
NumPy中提供了很多用于统计分析的函数,常见的有sum、mean、std、var、min和max等。
几乎所有的统计函数在针对二维数组的时候需要注意轴的概念。
axis=0时表示沿着纵轴进行计算,axis=1时沿横轴进行计算。
