简单的 PyTorch CNN 二分类器示例
学完了CNN的基本构件,看完了用TensorFlow实现的CNN,让我们再用PyTorch来搭建一个CNN,并用这个网络完成之前那个简单的猫狗分类任务。
这份PyTorch实现会尽量和TensorFlow实现等价。同时,我也会分享编写此项目过程中发现的PyTorch与TensorFlow的区别。
项目网址:https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/BasicCNN
获取数据集
和之前几次的代码实战任务一样,我们这次还用的是Kaggle上的猫狗数据集。我已经写好了数据预处理的函数。使用如下的接口即可获取数据集:
train_X, train_Y, test_X, test_Y = get_cat_set(
'dldemos/LogisticRegression/data/archive/dataset',
train_size=1500,
format='nchw')
print(train_X.shape) # (m, 3, 224, 224)
print(train_Y.shape) # (m, 1)
这次的数据格式和之前项目中的有一些区别。
在使用全连接网络时,每一个输入样本都是一个一维向量。之前在预处理数据集时,我做了一个flatten操作,把图片的所有颜色值塞进了一维向量中。而在CNN中,对于卷积操作,每一个输入样本都是一个三维张量。用OpenCV读取完图片后,不用对图片Resize,直接拿过来用就可以了。
另外,在用NumPy实现时,我们把数据集大小N当作了最后一个参数;在用TensorFlow时,张量格式是"NHWC(数量-高度-宽度-通道数)“。而PyTorch中默认的张量格式是"NCHW(数量-通道数-高度-宽度)”。因此,在预处理数据集时,我令format='nchw'。
初始化模型
根据课堂里讲的CNN构建思路,我搭了一个这样的网络。
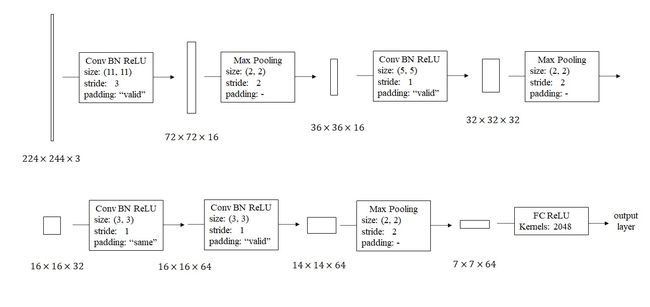
由于这个二分类任务比较简单,我在设计时尽可能让可训练参数更少。刚开始用一个大步幅、大卷积核的卷积快速缩小图片边长,之后逐步让图片边长减半、深度翻倍。
这样一个网络用PyTorch实现如下:
def init_model(device='cpu'):
model = nn.Sequential(nn.Conv2d(3, 16, 11, 3), nn.BatchNorm2d(16),
nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 5), nn.BatchNorm2d(32),
nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 3, padding=1), nn.BatchNorm2d(64),
nn.ReLU(True), nn.Conv2d(64, 64, 3),
nn.BatchNorm2d(64), nn.ReLU(True),
nn.MaxPool2d(2, 2), nn.Flatten(),
nn.Linear(3136, 2048), nn.ReLU(True),
nn.Linear(2048, 1), nn.Sigmoid()).to(device)
def weights_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight)
m.bias.data.fill_(0)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
elif isinstance(m, nn.Linear):
torch.nn.init.xavier_normal_(m.weight)
m.bias.data.fill_(0)
model.apply(weights_init)
print(model)
return model
让我们从函数定义开始一点一点看起。
def init_model(device='cpu'):
在PyTorch中,所有张量所在的运算设备需要显式指定。我们的模型中带有可学习参数,这些参数都是张量。因此,在初始化模型时,我们要决定参数所在设备。最常见的设备是'cpu'和'cuda:0'。对于模块或者张量,使用x.to(device)即可让对象x中的数据迁移到设备device上。
接着,是初始化模型结构。
model = nn.Sequential(nn.Conv2d(3, 16, 11, 3), nn.BatchNorm2d(16),
nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 5), nn.BatchNorm2d(32),
nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 3, padding=1), nn.BatchNorm2d(64),
nn.ReLU(True), nn.Conv2d(64, 64, 3),
nn.BatchNorm2d(64), nn.ReLU(True),
nn.MaxPool2d(2, 2), nn.Flatten(),
nn.Linear(3136, 2048), nn.ReLU(True),
nn.Linear(2048, 1), nn.Sigmoid()).to(device)
torch.nn.Sequential()用于创建一个串行的网络(前一个模块的输出就是后一个模块的输入)。网络各模块用到的初始化参数的介绍如下:
Conv2d: 输入通道数、输出通道数、卷积核边长、步幅、填充个数padding。BatchNormalization: 输入通道数。ReLU: 一个bool值inplace。是否使用inplace,就和用a += 1还是a + 1一样,后者会多花一个中间变量来存结果。MaxPool2d: 卷积核边长、步幅。Linear(全连接层):输入通道数、输出通道数。
相比TensorFlow,PyTorch里的模块更独立一些,不能附加激活函数,不能直接直接写上初始化方法。
TensorFlow是静态图(会有一个类似“编译”的过程,把模块串起来),除了第一个模块外,后续模块都可以不指定输入通道数。而PyTorch是动态图,需要指定某些模块的输入通道数。
根据之前的设计,把参数填入这些模块即可。
由于PyTorch在初始化模块时不能自动初始化参数,我们要手动写上初始化参数的逻辑。
在此之前,要先认识一下torch.nn.Module的apply函数。
model.apply(weights_init)
PyTorch的模型模块torch.nn.Module是自我嵌套的。一个torch.nn.Module的实例可能由多个torch.nn.Module的实例组成。model.apply(func)可以对某torch.nn.Module实例的所有某子模块执行func函数。我们使用的参数初始化函数叫做weights_init,所以用上面那行代码就可以初始化所有模块。
初始化参数函数是这样写的:
def weights_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight)
m.bias.data.fill_(0)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
elif isinstance(m, nn.Linear):
torch.nn.init.xavier_normal_(m.weight)
m.bias.data.fill_(0)
其中,m就是子模块的示例。通过对其进行类型判断,我们可以对不同的模块执行不同的初始化方式。初始化的函数都在torch.nn.init,我这里用的是torch.nn.init.xavier_normal_。
理论上写了batch normalization的话前一个模块就不用加bias。为了让代码稍微简单一点,我没有做这个优化。
模型初始化完后,调用print(model)可以查看网络各层的参数信息。
Sequential(
(0): Conv2d(3, 16, kernel_size=(11, 11), stride=(3, 3))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
......
(18): Linear(in_features=2048, out_features=1, bias=True)
(19): Sigmoid()
准备优化器和loss
初始化完模型后,可以用下面的代码初始化优化器与loss。
model = init_model(device)
optimizer = torch.optim.Adam(model.parameters(), 5e-4)
loss_fn = torch.nn.BCELoss()
torch.optim.Adam可以初始化一个Adam优化器。它的第一个参数是所有可训练参数,直接对一个torch.nn.Module调用.parameters()即可一键获取参数。它的第二个参数是学习率,这个可以根据实验情况自行调整。
torch.nn.BCELoss是二分类用到的交叉熵误差。这里只是对它进行了初始化。在调用时,使用方法是loss(input, target)。input是用于比较的结果,target是被比较的标签。
训练与推理
接下来,我们来编写模型训练和推理(准确来说是评估)的代码。
先看训练函数。
def train(model: nn.Module,
train_X: np.ndarray,
train_Y: np.ndarray,
optimizer: torch.optim.Optimizer,
loss_fn: nn.Module,
batch_size: int,
num_epoch: int,
device: str = 'cpu'):
在训练时,我们采用mini-batch策略。因此,开始迭代前,我们要编写预处理mini-batch的代码。
这部分的代码讲解请参考我之前有关优化算法的文章。
m = train_X.shape[0]
indices = np.random.permutation(m)
shuffle_X = train_X[indices, ...]
shuffle_Y = train_Y[indices, ...]
num_mini_batch = math.ceil(m / batch_size)
mini_batch_XYs = []
for i in range(num_mini_batch):
if i == num_mini_batch - 1:
mini_batch_X = shuffle_X[i * batch_size:, ...]
mini_batch_Y = shuffle_Y[i * batch_size:, ...]
else:
mini_batch_X = shuffle_X[i * batch_size:(i + 1) * batch_size, ...]
mini_batch_Y = shuffle_Y[i * batch_size:(i + 1) * batch_size, ...]
mini_batch_X = torch.from_numpy(mini_batch_X)
mini_batch_Y = torch.from_numpy(mini_batch_Y).float()
mini_batch_XYs.append((mini_batch_X, mini_batch_Y))
print(f'Num mini-batch: {num_mini_batch}')
PyTorch有更方便的实现mini-batch的方法。但为了少引入一些新知识,我这里没有使用。后续文章中会对这部分内容进行介绍。
这里还有一些有关PyTorch的知识需要讲解。torch.from_numpy可以把一个NumPy数组转换成torch.Tensor。由于标签Y是个整形张量,而PyTorch算loss时又要求标签是个float,这里要调用.float()把张量强制类型转换到float型。同理,其他类型也可以用类似的方法进行转换。
分配好了mini-batch后,就可以开心地调用框架进行训练了。
for e in range(num_epoch):
for mini_batch_X, mini_batch_Y in mini_batch_XYs:
mini_batch_X = mini_batch_X.to(device)
mini_batch_Y = mini_batch_Y.to(device)
mini_batch_Y_hat = model(mini_batch_X)
loss: torch.Tensor = loss_fn(mini_batch_Y_hat, mini_batch_Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {e}. loss: {loss}')
由于GPU计算资源有限,只有当我们需要计算某数据时,才把数据用to(device)放到对应设备上。
直接用model(x)即可让模型model执行输入x的前向传播。
之后几行代码就属于训练的常规操作了。先计算loss,再清空优化器的梯度,做反向传播,最后调用优化器更新所有参数。
推理并评估的函数定义如下:
def evaluate(model: nn.Module,
test_X: np.ndarray,
test_Y: np.ndarray,
device='cpu'):
它的实现和之前的NumPy版本极为类似,这里不再重复讲解了。
test_X = torch.from_numpy(test_X).to(device)
test_Y = torch.from_numpy(test_Y).to(device)
test_Y_hat = model(test_X)
predicts = torch.where(test_Y_hat > 0.5, 1, 0)
score = torch.where(predicts == test_Y, 1.0, 0.0)
acc = torch.mean(score)
print(f'Accuracy: {acc}')
main函数
做好了所有准备,现在可以把所有的流程串起来了。让我们看看main函数的所有代码:
def main():
train_X, train_Y, test_X, test_Y = get_cat_set(
'dldemos/LogisticRegression/data/archive/dataset',
train_size=1500,
format='nchw')
print(train_X.shape) # (m, 3, 224, 224)
print(train_Y.shape) # (m, 1)
device = 'cuda:0'
num_epoch = 20
batch_size = 16
model = init_model(device)
optimizer = torch.optim.Adam(model.parameters(), 5e-4)
loss_fn = torch.nn.BCELoss()
train(model, train_X, train_Y, optimizer, loss_fn, batch_size, num_epoch,
device)
evaluate(model, test_X, test_Y, device)
这里,我们先准备好了数据集,再初始化好了模型、优化器、loss,之后训练,最后评估。
这里的cuda:0可以改成cpu,这样所有运算都会在CPU上完成。
实验结果
由于数据量较少,我只执行了20个epoch。loss已经降到很低了。
poch 19. loss: 0.0308767631649971
但是,测试集上的精度非常低。
Accuracy: 0.5824999809265137
在完成本项目时,我本来想让这次的PyTorch实现和上次的TensorFlow实现完全等价。但是,上次的loss大概是0.06,准确率是0.74。可以看出,在训练误差上PyTorch模型没什么问题,而准确率却差了很多。我猜测是TensorFlow的代码过于“高级”,隐藏了很多细节。也许它默认的配置里使用了某些正则化手段。而在今天这份PyTorch实现中,我们没有使用任何正则化的方法。
不管怎么说,从训练的角度来看,相比前几周用的全连接网络,CNN的效果出彩很多。相信加入更多训练数据,并使用一些正则化方法的话,模型在测试集上的表现会更好。
PyTorch和TensorFlow在使用体验和性能上更有优劣。相比TensorFlow的高度封装的函数,PyTorch要手写的地方会多一点。不过,在项目逐渐复杂起来,高度封装的函数用不了了之后,还是PyTorch写起来会更方便一点。毕竟PyTorch是动态图,可以随心所欲地写前向推理的过程。也正因为如此,PyTorch的性能会略逊一些。
使用编程框架是不是很爽?可不要得意忘形哦。在之后的文章中,我还会介绍卷积的等价NumPy实现,让我们重温一下“难用”的NumPy,打下坚实的编程基础。