目标检测中的常见指标
目标检测中的常见指标
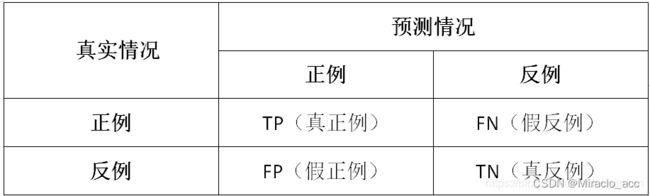
1、TP、FP、TN、FN基本概念
- TP:被模型预测为正类的正样本
- TN:被模型预测为负类的负样本
- FP:被模型预测为正类的负样本
- FN:被模型预测为负类的正样本
- 记忆方法,前边TF是分类正确或者错误,后面的PN是预测结果是正例或负例
以西瓜数据集为例,我们来通俗理解一下什么是TP、TN、FP、FN。
- TP:被模型预测为好瓜的好瓜(是真正的好瓜,而且也被模型预测为好瓜)
- TN:被模型预测为坏瓜的坏瓜(是真正的坏瓜,而且也被模型预测为坏瓜)
- FP:被模型预测为好瓜的坏瓜(瓜是真正的坏瓜,但是被模型预测为了好瓜)
- FN:被模型预测为坏瓜的好瓜(瓜是真正的好瓜,但是被模型预测为了坏瓜)
2、查准率P、查全率R
- 查准率(Precision):模型预测的所有目标中,预测正确的比例
- 查全率(Recall):在所有真实目标中,模型预测正确的目标比例
查准率用P来表示:
P r e c i s i o n = T P T P + F P = T P N Precision = \frac{TP}{TP+FP}=\frac{TP}{N} Precision=TP+FPTP=NTP
其中 N 为模型预测此类(Class)的样本数
查全率用R来表示:
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP
通俗理解:
- 查准率(Precision):模型挑出来的西瓜中有多少比例是好瓜
- 查全率(Recall):所有的好瓜中有多少比例是被模型挑出来的
TP(true positive):IoU > 0.5(并不一定是0.5,根据情况设定) 的边界框数量(同一Ground Truth只计算一次) ;

- 例如图中绿色框为人为标注的真实框,0.9的红色框则可视为检测成功的。
FP(False Positive,假阳性):IoU <= 0.5 的边界框数量(或者是检测到同一个GT的多余检测框的数量),上图中0.3的红色框即可视为假阳性
FN(False Negative):漏检的GT的数量。右下角的猫即为漏检的对象
Precision = TP/(TP+FP),即模型预测的所有目标中,预测正确的比例。(查准率)
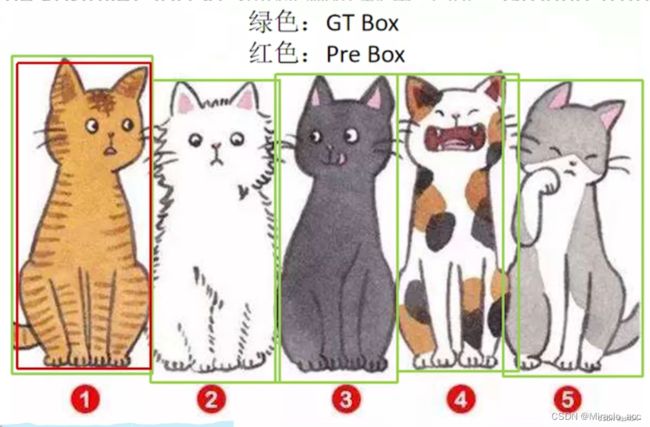
但是仅凭此并不能准确评判网络的好坏,例如上图,FP=0,那么套入公式Precision就等于1了,查准率为100%,但是实际还有未检测的对象,所以仅凭此不能评判网络的好坏。
Recall = TP/(TP+FN),即所有真实目标中,预测到且预测正确的比例。(召回率、查全率)
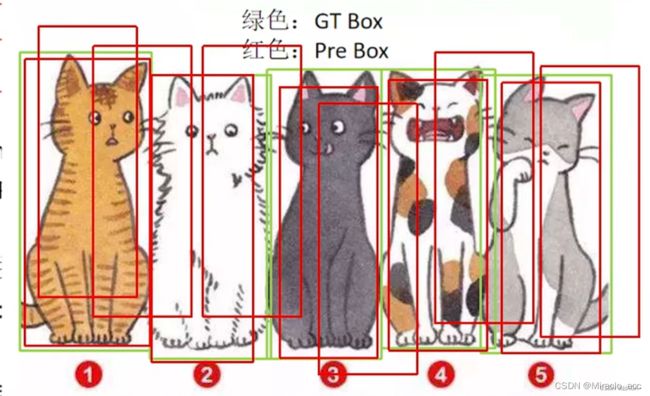
同样如上图所示,当检测框的数量很多时,把所有对象都包含,且此时FN=0,没有漏检,此时recall是等于100%的,但是实际图中还有很多FP,所以仅凭此也不能表达网络的好坏。
所以据此有了如下评判标准:
AP: P-R曲线下面积
P-R曲线: Precision-Recall曲线
mAP: mean Average Precision, 即各类别AP的平均值
3、P-R曲线、AP、mAP
如何按照模型置信度对候选框进行排序?
举例:下图中,逐渐降低置信度Confidence到0.66,此时左边五个都是满足的,TP=4,FP=1,FN=3(漏检3个 7-4=3),计算此时的PR值,加入排序中
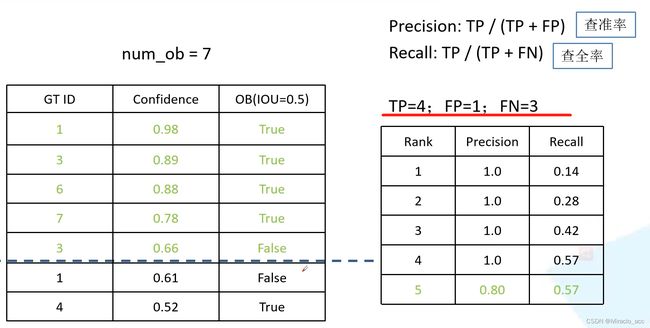
在介绍AP之前,首先理解PR曲线,**以检测为例,假设数据集中共有1个待检测物体,模型预测出7个候选框,**按照模型置信度对候选框进行排序:
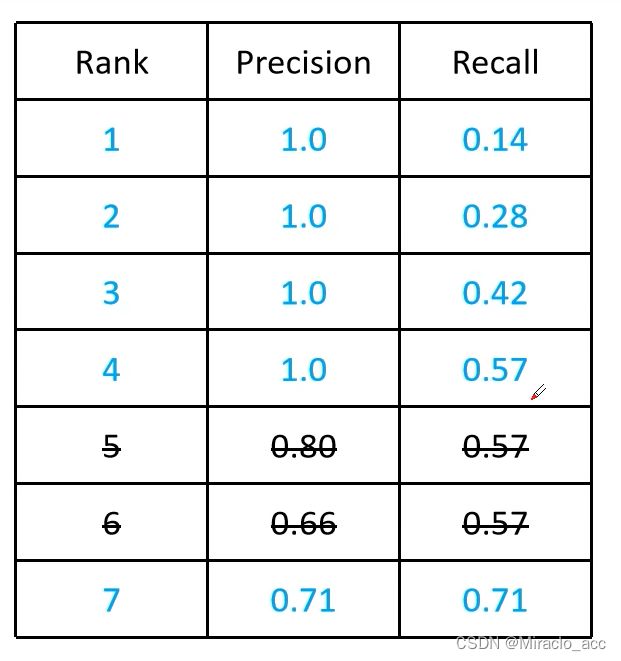
以Recall值为横轴,Precision值为纵轴,我们可以得到PR曲线:
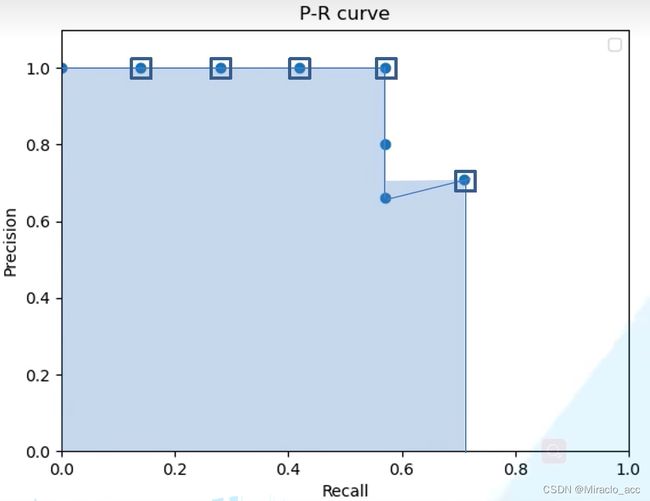
AP(Average Precision)
AP就是对PR曲线求积分:
实际上,需要对PR平滑处理,对其每个点Precision对值取右侧最大的Precision:
- 计算方式:对于第
i个点寻找第i个点及其以下点最大的P值,然后乘上当前区间
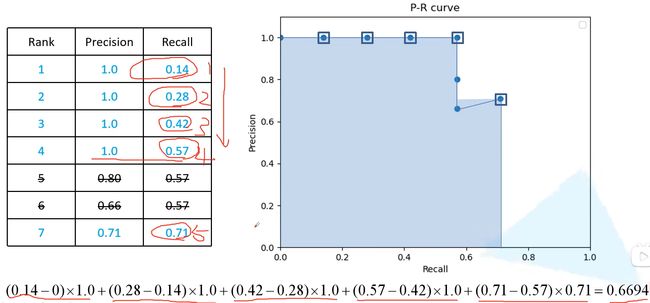
在COCO数据集中,在PR曲线中采样100个点进行计算,即:
- A P = 1 100 ∑ r 1 , r 2 , ⋯ , r 100 P s m o o t h ( i ) AP=\frac{1}{100}\sum_{r_{1},r_{2},\cdots,r_{100}}P_{smooth}( i) AP=1001∑r1,r2,⋯,r100Psmooth(i)
mAP所有类别的平均AP值:
- m A P = 1 k ∑ i = 1 k A P i mAP=\frac{1}{k}\sum_{i=1}^{k}AP_{i} mAP=k1∑i=1kAPi
4、IOU
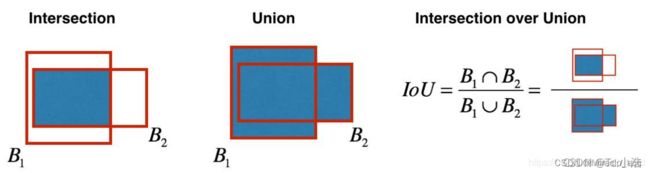
IOU的全称为交并比(Intersection over Union),是目标检测中使用的一个概念,IoU计算的是“预测的边框”和“真实的边框”的交叠率,即它们的交集和并集的比值。最理想情况是完全重叠,即比值为1。
IoU等于“预测的边框”和“真实的边框”之间交集和并集的比值。IoU计算如下图,B1为真实边框,B2为预测边框。
一般约定,在计算机检测任务中,如果loU≥0.5,就说检测正确,如果预测器和实际边界框完美重叠,loU就是1,因为交集就等于并集。但一般来说只要loU≥0.5,那么结果是可以接受的,看起来还可以。一般约定,0.5是阈值,用来判断预测的边界框是否正确。一般是这么约定,但如果你希望更严格一点,你可以将loU定得更高,比如说大于0.6或者更大的数字,但loU越高,边界框越精确。
IOU计算的Python实现
def iou(box1, box2):
'''
两个框(二维)的 iou 计算
注意:边框以左上为原点
box:[x1,y1,x2,y2],依次为左上右下坐标
'''
h = max(0, min(box1[2], box2[2]) - max(box1[0], box2[0]))
w = max(0, min(box1[3], box2[3]) - max(box1[1], box2[1]))
area_box1 = ((box1[2] - box1[0]) * (box1[3] - box1[1]))
area_box2 = ((box2[2] - box2[0]) * (box2[3] - box2[1]))
inter = w * h
union = area_box1 + area_box2 - inter
iou = inter / union
return iou
box1 = [0,0,2,2]
box2 = [1,1,3,3]
IoU = iou(box1,box2)
print(IoU)
COCO评价数据中每条数据的含义
拓展:通过pycocotools获取每个类别的COCO指标
在目标检测任务中,我们常用的评价指标一般有两种,一种是使用Pascal VOC的评价指标,一种是更加严格的COCO评价指标,一般后者会更常用点。在计算COCO评价指标时,最常用的就是Python中的pycocotools包,但一般计算得到的结果是针对所有类别的,例如:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.512
# !!
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.798
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.573
# 检测small medium large目标时的AP
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.191
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.397
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.565
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.443
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.625
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.632
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.319
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.531
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.677
COCO官网上含义解释:https://cocodataset.org/#detection-eval
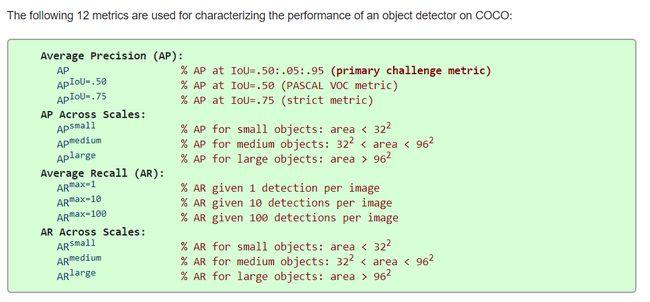
比较重要的指标:
(AP) @[ IoU=0.50 标准
(AP) @[ IoU=0.50:0.95是对coco数据集的评价指标