【mongoDB】mongoDB的多健索引及查询优化
文章目录
- 索引
-
- 多键索引
- 多键索引的查询
- 执行计划
-
- 执行计划的评估和选择
- Plan cache中的计划如何保证有效
最近做了一些mongoDB的慢查询工作。完成该工作后照例对mongoDB查询优化的内容进行总结,其中包括索引、执行计划、优化器等内容。
索引
数据库组织数据的形式是由存储引擎决定的,mongoDB从3.2版本开始采用wiredTiger作为默认的存储引擎。wireTiger支持B+树和LSM树,默认是采用B+树。
![]()
mysql的InnoDB同样是采用B+树来组织数据,区别在于mongoDB中的B+树是非聚簇的。因为底层的数据结构相同,所以mongoDB的索引和mysql的索引具有非常多的相似之处,比如都支持单值索引、复合索引,比如一些类似最左前缀匹配、索引覆盖等等的索引策略都是通用的,针对这些内容,本文不打算再多废笔墨。
虽然具有相同的数据结构,但是mongoDB的索引和mysql的索引还是有些不同的,不同之处主要来自数据模型的不同。mongoDB是文档型的数据库,区别于关系型的数据模型,这种特殊的结构使mongoDB有种独特的索引——多键索引。本文的索引部分主要介绍多键索引。
多键索引
当我们对一个数组字段建立索引的时候,mongo会自动建立多键索引,其效果如下。
// collection里有下面两条文档
{
"name": "xiaoming",
"multiKey": [20, 15]
}
{
"name": "xiaohong",
"multiKey": [3, 500]
}
// 运行命令
db.collection.CreateIndex({"multiKey": 1})

对于复合索引,其限制最多包含一个多键索引,即复合索引中最多包含一个数组字段。
// collection里有下面两条文档
{
"name": "xiaoming",
"multiKey1": [20, 15],
"multiKey2": ["a", "c"]
}
{
"name": "xiaohong",
"multiKey": [3, 500],
"multiKey2": ["b", "d"]
}
// 运行命令会失败
db.collection.CreateIndex({"multiKey1": 1, "multiKey2": 1})
对于元素为嵌套文档的数组字段,可以在其嵌套文档的字段上建立复合索引。
// collection里有下面两条文档
{
"name": "xiaoming",
"multiKey1": [{"A":12, "B":13}, {"A":15, "B":16}]
}
{
"name": "xiaohong",
"multiKey1": [{"A":17, "B":18}, {"A":19, "B":20}]
}
// 可以建立复合索引
db.collection.CreateIndex({"multiKey1.A": 1, "multiKey1.B": 1})
关于mongo如何处理多键索引以及复合索引中只能包含一个数组字段的思考:
当所构建的索引字段中涉及到嵌套的数组时,mongo会做类似下图的转换拆分,然后再构建B+树。
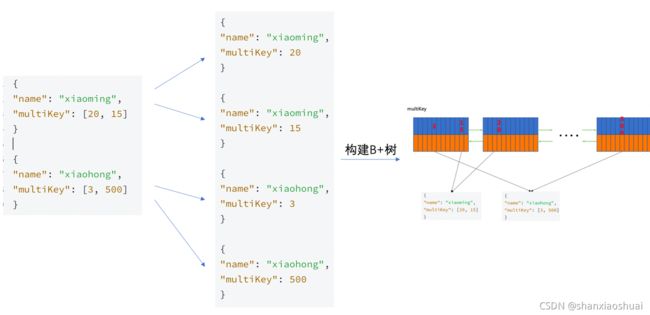
对于数组元素为嵌套文档的,做如下转换。

相似的,如果可以对多个数组字段建立复合索引,那么转换时会造成数据的爆炸。所以限制一个索引中最多有一个数组字段。
多键索引的查询
对多键索引的查询,问题主要出在多filter条件下,如果只有一个filter条件,不会出现歧义。
db.collection.find({"multiKey": condition1})
对于多filter条件,有两种查询方法:
// 写法1
db.collection.find({"multiKey":[condition1, condition2]})
// 写法2
db.collection.find({"multiKey":{$elemMatch: [condition1, condition2]}})
写法1的语义为:对于multiKey字段,其至少有一个元素a满足condition1并且至少有一个元素b满足condition2,a和b不要求为同一个元素;
写法2的语义为:对于multiKey字段,其至少有一个元素c同时满足condition1和condition2;
大多数情况下,写法2的语义可能更符合我们实际业务的需求。
接下来以下面的示例来说明这两种查询下mongoDB的行为会有哪些区别。
// collection里有下面两条文档
{
"name": "xiaoming",
"multiKey1": [{"A":12, "B":13}, {"A":13, "B":66}]
}
{
"name": "xiaohong",
"multiKey1": [{"A":12, "B":78}, {"A":13, "B":20}]
}
// 可以建立复合索引
db.collection.CreateIndex({"multiKey1.A": 1, "multiKey1.B": 1})
首先执行
db.collection.find({"multiKey1.A":12, "multiKey1.B": {$gt:50}})
下面是截取explain结果的一些关键信息。

可以看到第一步先用多键索引进行搜索,但只用到了{“multiKey1.A”: 1}的条件,将所有符合{“multiKey1.A”: 1}的文档找到后,再遍历multiKey1.B筛选出大于50的文档,最终结果是两条文档都有。
然后执行
db.collection.find({"multiKey1":{$elemMatch:{"A":12, "B": {$gt:50}}}})
截取的explain结果如下。

这里可以看到确实实现了相应的语义,但是走的索引情况不是很符合预期。预期是能通过multiKey1.A_1_multiKey1.B_1的复合索引直接拿到最后的结果,这样明显效率更高。
继续研究。
// 建立下面复合索引
db.collection.CreateIndex({"name": 1, "multiKey1.A": 1, "multiKey1.B": 1})
// 执行查询
db.collection.find({"name": "xiaohong","multiKey1":{$elemMatch:{"A":12, "B": {$gt:50}}}})

这次结果相对符合预期一点。走了multiKey1.A_1_multiKey1.B_1的复合索引。
执行计划
对于一个查询语句,mongoDB会找出所有可用的索引,对每个可用的索引都生成相应的解决方案,然后判断works最低的执行计划作为最终的执行计划,同时把该计划缓存到plan cache中。
在详细讲执行计划的选择之前,先介绍几个概念:
query shape:这个翻译过来叫做指纹,将查询语句中的参数处理掉,只留下查询逻辑部分,能够标识一类查询语句。
queryHash:对query shape哈希得到,能够唯一标识一个query shape。
planCacheKey:planCacheKey除了与query shape有关外,还和生成planCacheKey时相应query shape的可用索引有关。
queryHash和planCacheKey都是4.2版本以后才有的。

mongo选择执行计划的整个流程如下,其中的关键点有两个:
- 对于候选计划,mongo是如何评估和选择最有效的计划;
- 对于plan cache中匹配得到执行计划,mongo如何确保其仍然有效;
下面将分开来介绍这两块内容。

执行计划的评估和选择
前面提到过,对一个查询语句,mongoDB会找到该语句所有可用的索引,每个索引生成一个解决方案。那对一个具体的解决方案,mongoDB是如何评估其性能的呢?
可以看到mongoDB是通过work units的数量来判断其性能,这其实和mysql基于成本选择执行计划一样。关于work unit官方文档中有简略的说明。


对于每个解决方案,mongo都会进行一定次数的扫描,扫描的次数为10000和0.29*collection记录数的最小值。
numWorks = std::max(static_cast<size_t>(internalQueryPlanEvaluationWorks),
static_cast<size_t>(fraction * collection->numRecords(txn)));
internalQueryPlanEvaluationWorks=10000
fraction=0.29
collection->numRecords(txn) 则为collection的总记录数
然后mongo会根据扫描的结果计算score,score的计算如下:
double baseScore = 1;
size_t workUnits = stats->common.works;
double productivity =
static_cast<double>(stats->common.advanced) / static_cast<double>(workUnits);
const double epsilon = std::min(1.0 / static_cast<double>(10 * workUnits), 1e-4);
double noFetchBonus = epsilon;
if (hasStage(STAGE_PROJECTION, stats) && hasStage(STAGE_FETCH, stats)) {
noFetchBonus = 0;
}
double noSortBonus = epsilon;
if (hasStage(STAGE_SORT, stats)) {
noSortBonus = 0;
}
double noIxisectBonus = epsilon;
if (hasStage(STAGE_AND_HASH, stats) || hasStage(STAGE_AND_SORTED, stats)) {
noIxisectBonus = 0;
}
double tieBreakers = noFetchBonus + noSortBonus + noIxisectBonus;
double score = baseScore + productivity + tieBreakers;
可以看到score是由baseScore、productivity、tieBreakers三部分组成的:
- baseScore是写死的,固定值为1;
- productivity是由advanced/workUnits的比值得到,workUnit是进行扫描的次数,advanced为返回的结果的次数,所以productivity可以理解为利用某个索引进行扫描的效率;
- tieBreakers是由noFetchBonus、noSortBonus、noIxisectBonus组成:Fetch表示根据索引的key从collection中取记录的过程,noFetchBonus是类似mysql中索引覆盖带来的性能优化;noSortBonus是和排序有关,这个不用多说;noIxisectBonus是和交叉索引有关;
综上,得分最大的执行计划会被选为最终的执行计划,然后放进plan cache中。
Plan cache中的计划如何保证有效
在流程图中,当从plan cache中匹配拿到执行计划后,需要评估其性能:
- 以Cache中执行计划的索引命中数量(works)*10=需要扫描的数量(B次)
- 继续用该索引扫描B次,扫描的过程中有如下几种情况:
- 索引每次扫描出来会去扫描collection,collection根据筛选条件如果能拿到记录,则返返回advanced,如果返回的advanced累积次数超过101次,则继续用该执行计划;
- 索引扫描该字段的命中数量少于B次,则最终肯定会达到IS_EOF状态,这个时候还是继续用缓存中的执行计划;
- 如果扫描完了B次,但是发现返回advanced累积次数没有达到101次,则会重新生成执行计划;
- 如果在扫描过程遇见错误,则会返回FAILURE,也会触发重新生成执行计划;
但是上面的过程其实是有漏洞的,因为这里只能保证plan cache中匹配到的计划具有一定效率,但无法保证该计划是最优的。所以在4.2版本以后,mongoDB对plan cache中的计划增加了状态来对该问题进行优化。但是感觉还是很难完全解决上面的漏洞。
参考文档:
https://docs.mongodb.com/manual/core/query-plans/
https://stackoverflow.com/questions/7396219/mongodb-multikey-indexing-structure
https://medium.com/@zhaoyi0113/mongodb-explain-multi-key-index-analysis-b272cd569ecf
https://mongoing.com/archives/5624