图神经网络框架DGL学习 104——图分类模型(Graph Classification Tutorial)
学习利用DGL进行批次化训练图分类模型。这是一个图层面的任务。
图形分类是生物信息学,化学信息学,社会网络分析,城市计算和网络安全等许多领域应用的重要问题。 将图神经网络应用于此问题是最近流行的方法。
一、数据集
已知有一以下几种类型的形状及其类型,需训练一个相应的分类模型。
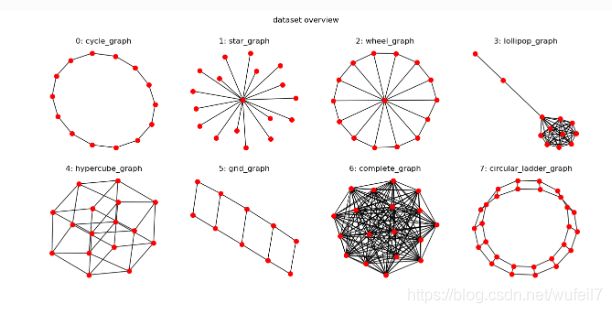
该数据集为DGL的MiniGCDataset。首先,导入所有要使用的模块。
import dgl
from dgl.data import MiniGCDataset
from dgl.nn.pytorch import GraphConv
import matplotlib.pyplot as plt
import networkx as nx
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
检查数据集情况
dataset= MiniGCDataset(80, 10, 20) #80个样本,每个图的尺寸是10~20各节点
graph, label = dataset[3]
nx.draw(graph.to_networkx(), with_labels=True)
# plt.show()
plt.clf()
plt.close()
二、构建批次
为了更高效的训练神经网络,常用的方法就是构建批次。例如,两张2828的图片可以构建成228*28的批次,但是对于图神经网络而言,存在两个困难:
1. 图是稀疏矩阵
2. 由于图有不同的节点和边的数量,所以图的大小不一。
DGL提供了dgl.batch() API,以解决该问题。它利用了这样的思想,即可以将一批图形视为具有许多不相连的连接组件的大型图形。 以下是给出总体思路的可视化视图。

定义以下collate函数,从给定的图形和标签对列表中形成一个mini批处理。
def collate(samples):
'''
将多个小图生成批次
:param samples: 由图和标签的list组成( graphs, labels)
:return: batch_graph 也是一个图。
这意味着任何适用于一个图的代码都可立即用于一批图。
更重要的是,由于DGL并行处理所有节点和边缘上的消息,因此大大提高了效率。
'''
graphs, labels = map(list, zip(*samples))
batch_graph = dgl.batch(graphs)
return batch_graph, torch.tensor(labels)
三、图分类器
图分类的具体流程如下:
从一批图形中,执行消息传递和图形卷积,以使节点与其他节点进行通信。 消息传递后,根据节点(和边)属性为图表表示计算张量。 此步骤可能称为读出或汇总。 最后,将图形表示输入到分类器g中以预测图形标签。值得注意的是,这里使用节点平均值代表图的输出,这是一个读出机制。
#定义一个图的分类器
class Classifier(nn.Module):
def __init__(self, in_dim, hidden_dim, n_classes):
'''
定义图神经分类模型的结构
:param in_dim: 输入的特征维数, 与forward中的第一层的输入特征数相对应
:param hidden_dim: 隐藏层单元数
:param n_classes: 分类数
'''
super(Classifier, self).__init__()
self.conv1 = GraphConv(in_dim, hidden_dim)
self.conv2 = GraphConv(hidden_dim, hidden_dim)
self.classify = nn.Linear(hidden_dim, n_classes)
def forward(self, g):
'''
向前传播
:param g: 图
:return:
'''
h = g.in_degrees().view(-1, 1).float() #使用节点的度作为节点初始特征, 对于无向图来说,输入度等于输出度
#卷积层以及激活函数
h = F.relu(self.conv1(g, h))
h = F.relu(self.conv2(g, h))
g.ndata['h'] = h
#以平均值来代表图
hg = dgl.mean_nodes(g, 'h')
return self.classify(hg)
四、训练模型
#创建训练集和测试集
trainset = MiniGCDataset(320, 10, 20)
testset = MiniGCDataset(80, 10, 20)
print(trainset[0])
#利用DataLoader和collate函数创建批量数据
data_loader = DataLoader(trainset, batch_size=32, shuffle=True,
collate_fn=collate)#数据加载器,返回一个可以叠迭代的对象
#使用collate_fn对应的函数
#创建模型
model = Classifier(1, 256, trainset.num_classes)
loss_func = nn.CrossEntropyLoss()
optimier = optim.Adam(model.parameters(), lr=0.001)
model.train()
epoch_losses = []
for epoch in range(80):
epoch_loss = 0
for iter, (bg, label) in enumerate(data_loader):
prediction = model(bg)
loss = loss_func(prediction, label)
optimier.zero_grad()
loss.backward()
optimier.step()
epoch_loss += loss.detach().item() #每一个批次的损失
epoch_loss /= (iter+1)
print('Epoch {}, loss {:.4f}'.format(epoch, epoch_loss))
epoch_losses.append(epoch_loss)

五、模型评估
model.eval()
# Convert a list of tuples to two lists
test_X, test_Y = map(list, zip(*testset))
test_bg = dgl.batch(test_X)
test_Y = torch.tensor(test_Y).float().view(-1, 1)
probs_Y = torch.softmax(model(test_bg), 1)
sampled_Y = torch.multinomial(probs_Y, 1)
print(sampled_Y)
argmax_Y = torch.max(probs_Y, 1)[1].view(-1, 1)
print(argmax_Y)
print('Accuracy of sampled predictions on the test set: {:.4f}%'.format(
(test_Y == sampled_Y.float()).sum().item() / len(test_Y) * 100))
print('Accuracy of argmax predictions on the test set: {:4f}%'.format(
(test_Y == argmax_Y.float()).sum().item() / len(test_Y) * 100))
Accuracy of sampled predictions on the test set: 58.7500%
Accuracy of argmax predictions on the test set: 72.500000%