多尺度特征提取模块 Multi-Scale Module及代码
即插即用的多尺度特征提取模块及代码小结
- Inception Module[2014]
- SPP[2014]
- PPM[2017]
- ASPP[2017]
- DCN[2017、2018]
- RFB[2018]
- GPM[2019]
- Big-Little Module(BLM)[2019]
- PAFEM[2020]
- FoldConv_ASPP[2020]
现在很多的网络都有多尺度特征提取模块来提升网络性能,这里简单总结一下那些即插即用的小模块。
禁止抄袭或转载!!!
Inception Module[2014]
最早的应该算是在ILSVRC2014比赛分类项目获得第一名的GoogLeNet(Incepetion V1),该网络设计了Inception module。
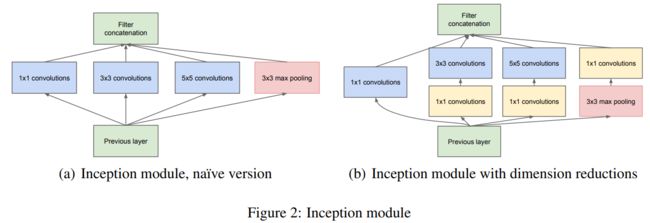
后来出现了很多进化版本:Incepetion V1-V3、Inception-v4,Inception-ResNet
SPP[2014]
SPP:何恺明ECCV 2014提出Spatial Pyramid Pooling(空间金字塔池化结构),用多个size的池化层来提取特征。
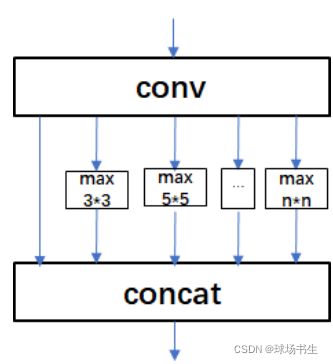
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
还有一种等价的形式,利用小尺度的多次池化,等价得到大尺度的池化(类似于VGG多个小卷积替换大卷积层):
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
PPM[2017]
CVPR2017 Pyramid Scene Parsing Network
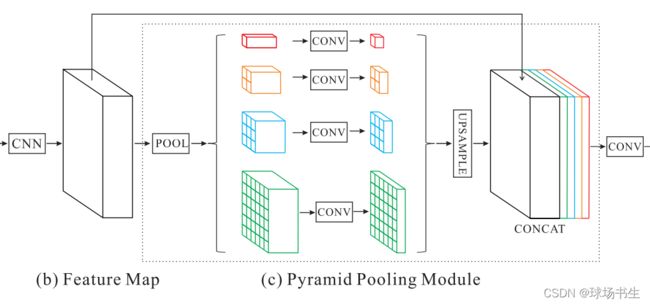
该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×1的卷积将对于级别通道降为原本的1/N。再通过双线性插值获得未池化前的图像大小,最终concat到一起。金字塔等级的池化核大小是可以设定的,这与送到金字塔的输入有关。论文中使用的4个等级,核大小分别为1×1,2×2,3×3,6×6。
class PPM(nn.Module): # pspnet
def __init__(self, down_dim):
super(PPM, self).__init__()
self.down_conv = nn.Sequential(nn.Conv2d(2048,down_dim , 3,padding=1),nn.BatchNorm2d(down_dim),
nn.PReLU())
self.conv1 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(1, 1)),nn.Conv2d(down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv2 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(2, 2)), nn.Conv2d(down_dim, down_dim, kernel_size=1),
nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv3 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(3, 3)),nn.Conv2d(down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv4 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(6, 6)), nn.Conv2d(down_dim, down_dim, kernel_size=1),
nn.BatchNorm2d(down_dim), nn.PReLU())
self.fuse = nn.Sequential(nn.Conv2d(4 * down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU())
def forward(self, x):
x = self.down_conv(x)
conv1 = self.conv1(x)
conv2 = self.conv2(x)
conv3 = self.conv3(x)
conv4 = self.conv4(x)
conv1_up = F.upsample(conv1, size=x.size()[2:], mode='bilinear')
conv2_up = F.upsample(conv2, size=x.size()[2:], mode='bilinear')
conv3_up = F.upsample(conv3, size=x.size()[2:], mode='bilinear')
conv4_up = F.upsample(conv4, size=x.size()[2:], mode='bilinear')
return self.fuse(torch.cat((conv1_up, conv2_up, conv3_up, conv4_up), 1))
ASPP[2017]
TPAMI2017 Deeplabv2,核心就是并行使用多个空洞卷积。空洞卷积是是为了解决输出图像的size要求和输入图像的size一致而需要upsample,但由于使用pooling操作来增大感受野同时降低分辨率,导致upsample无法还原由于pooling导致的一些细节信息的损失的问题而提出的。为了减小这种损失,自然需要移除pooling层,因此空洞卷积应运而生。
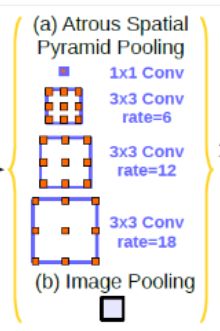
class ASPP(nn.Module): # deeplab
def __init__(self, dim,in_dim):
super(ASPP, self).__init__()
self.down_conv = nn.Sequential(nn.Conv2d(dim,in_dim , 3,padding=1),nn.BatchNorm2d(in_dim),
nn.PReLU())
down_dim = in_dim // 2
self.conv1 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv2 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=2, padding=2), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv3 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=4, padding=4), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv4 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=6, padding=6), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv5 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=1),nn.BatchNorm2d(down_dim), nn.PReLU())
self.fuse = nn.Sequential(nn.Conv2d(5 * down_dim, in_dim, kernel_size=1), nn.BatchNorm2d(in_dim), nn.PReLU())
def forward(self, x):
x = self.down_conv(x)
conv1 = self.conv1(x)
conv2 = self.conv2(x)
conv3 = self.conv3(x)
conv4 = self.conv4(x)
conv5 = F.upsample(self.conv5(F.adaptive_avg_pool2d(x, 1)), size=x.size()[2:], mode='bilinear')
return self.fuse(torch.cat((conv1, conv2, conv3,conv4, conv5), 1))
DCN[2017、2018]
可变形卷积可以参照我的另一篇博客:Deformable Convolutional Networks
以前的卷积核都是固定的矩形,而可变形卷积确可以基于原来的位置进行偏移。
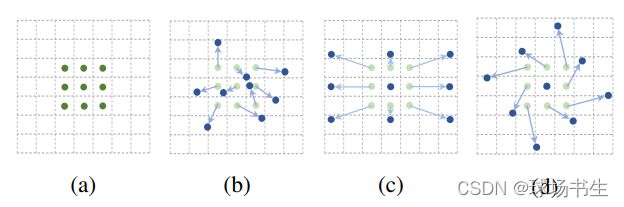
通过一个卷积来学习每个点的x,y偏移量:
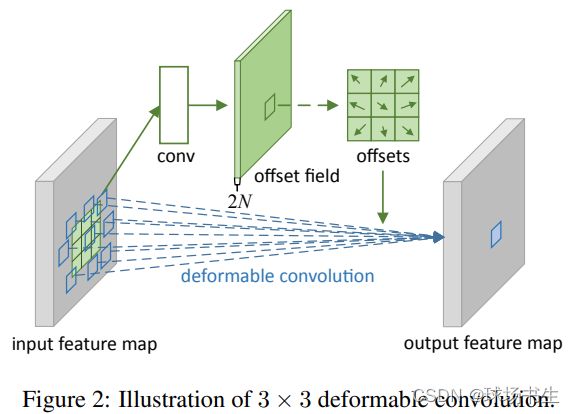
当然在V2的版本中还加入了每个点的幅度。
RFB[2018]
Receptive Field Block Net for Accurate and Fast Object Detection
结构上RFB借鉴了Inception的思想,主要是在Inception的基础上加入了空洞卷积。可以理解为Inception Module+ASPP。
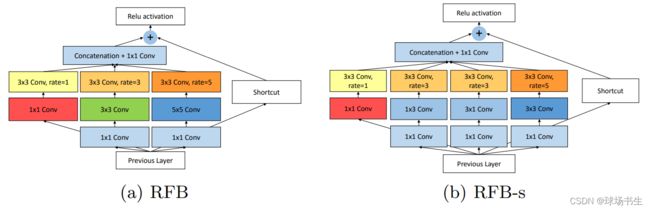
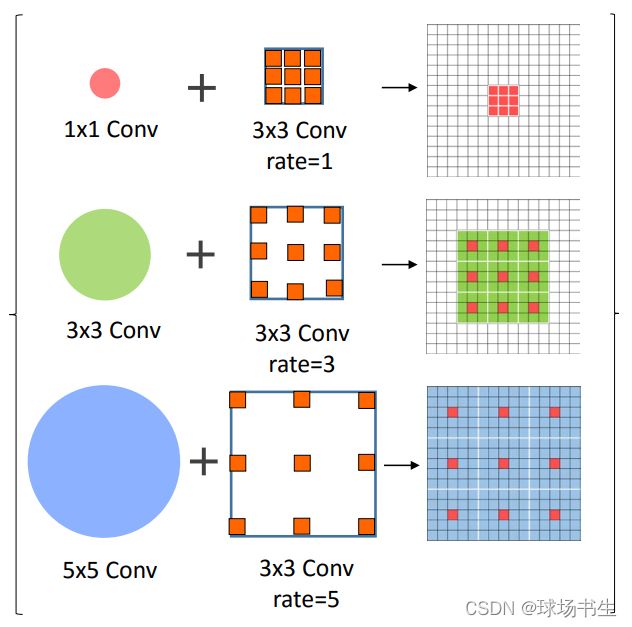
不过,本文借鉴人类视觉中不同的感受野应该具备不同的离心率的概念,使用dilated卷积核,就像图中的不同kernel_size对应不同尺寸的空洞,kernel_size越大,空洞尺寸越大,采样点离中心点越远。
GPM[2019]
CVPR2019 AFNet: Attentive Feedback Network for Boundary-aware Salient Object Detection
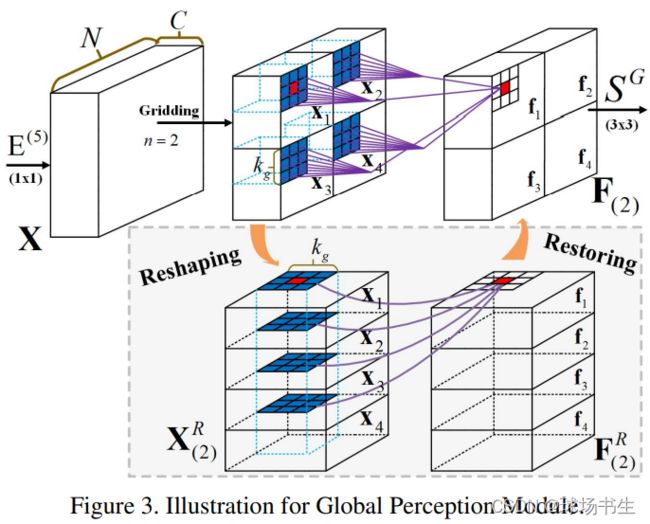
充分利用局部和全局信息。从图中可以看出来,这里考虑了局部的邻居。通过这种方式,可以同时保证局部模式和全局信息。最终整个模块使用了多个尺度的划分,包括n=2/4/7,也就是划分成2x2/4x4/7x7三个不同的分支,进行堆叠重组后进行kgxkg的卷积,最终使用一个3x3卷积处理恢复后的特征。
class GPM(nn.Module): # cvpr19 AFNet
def __init__(self, in_dim):
super(GPM, self).__init__()
down_dim = 512
n1, n2, n3 = 2, 4, 6
self.conv1 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv2 = nn.Sequential(nn.Conv2d(down_dim * n1 * n1, down_dim * n1 * n1, kernel_size=3, padding=1),
nn.BatchNorm2d(down_dim * n1 * n1), nn.PReLU())
self.conv3 = nn.Sequential(nn.Conv2d(down_dim * n2 * n2, down_dim * n2 * n2, kernel_size=3, padding=1),
nn.BatchNorm2d(down_dim * n2 * n2), nn.PReLU())
self.conv4 = nn.Sequential(nn.Conv2d(down_dim * n3 * n3, down_dim * n3 * n3, kernel_size=3, padding=1),
nn.BatchNorm2d(down_dim * n3 * n3), nn.PReLU())
self.fuse = nn.Sequential(nn.Conv2d(3 * down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU())
def forward(self, x):
conv1 = self.conv1(x)
###########################################################################
gm_2_a = torch.chunk(conv1, 2, 2)
c = []
for i in range(len(gm_2_a)):
b = torch.chunk(gm_2_a[i], 2, 3)
c.append(torch.cat((b[0], b[1]), 1))
gm1 = torch.cat((c[0], c[1]), 1)
gm1 = self.conv2(gm1)
gm1 = torch.chunk(gm1, 2 * 2, 1)
d = []
for i in range(2):
d.append(torch.cat((gm1[2 * i], gm1[2 * i + 1]), 3))
gm1 = torch.cat((d[0], d[1]), 2)
###########################################################################
gm_4_a = torch.chunk(conv1, 4, 2)
e = []
for i in range(len(gm_4_a)):
f = torch.chunk(gm_4_a[i], 4, 3)
e.append(torch.cat((f[0], f[1], f[2], f[3]), 1))
gm2 = torch.cat((e[0], e[1], e[2], e[3]), 1)
gm2 = self.conv3(gm2)
gm2 = torch.chunk(gm2, 4 * 4, 1)
g = []
for i in range(4):
g.append(torch.cat((gm2[4 * i], gm2[4 * i + 1], gm2[4 * i + 2], gm2[4 * i + 3]), 3))
gm2 = torch.cat((g[0], g[1], g[2], g[3]), 2)
###########################################################################
gm_6_a = torch.chunk(conv1, 6, 2)
h = []
for i in range(len(gm_6_a)):
k = torch.chunk(gm_6_a[i], 6, 3)
h.append(torch.cat((k[0], k[1], k[2], k[3], k[4], k[5]), 1))
gm3 = torch.cat((h[0], h[1], h[2], h[3], h[4], h[5]), 1)
gm3 = self.conv4(gm3)
gm3 = torch.chunk(gm3, 6 * 6, 1)
j = []
for i in range(6):
j.append(
torch.cat((gm3[6 * i], gm3[6 * i + 1], gm3[6 * i + 2], gm3[6 * i + 3], gm3[6 * i + 4], gm3[6 * i + 5]),
3))
gm3 = torch.cat((j[0], j[1], j[2], j[3], j[4], j[5]), 2)
###########################################################################
return self.fuse(torch.cat((gm1, gm2, gm3), 1))
Big-Little Module(BLM)[2019]
ICLR2019 《Big-Little Net: An Efficient Multi-Scale Feature Representation for Visual and Speech Recognition》
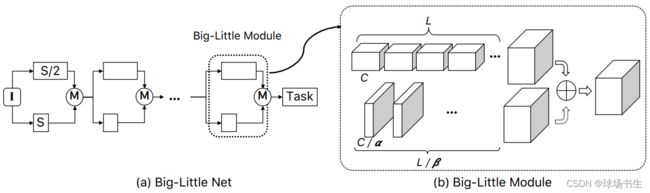
对于分辨率大的分支,使用更少的卷积通道,对于分辨率小的分支,使用更多的卷积通道,这样的方案能够更加充分地使用通道信息。分支融合前,低分辨率的特征图通过双线性插值上采样到更高分辨率的空间大小,高分辨率的特征图通过一个1x1卷积将通道数增加。
PAFEM[2020]
ECCV2020 Pyramidally Attended Feature Extraction(PAFE)

class PAFEM(nn.Module):
def __init__(self, dim,in_dim):
super(PAFEM, self).__init__()
self.down_conv = nn.Sequential(nn.Conv2d(dim,in_dim , 3,padding=1),nn.BatchNorm2d(in_dim),
nn.PReLU())
down_dim = in_dim // 2
self.conv1 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=2, padding=2), nn.BatchNorm2d(down_dim), nn.PReLU()
)
self.query_conv2 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.key_conv2 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.value_conv2 = Conv2d(in_channels=down_dim, out_channels=down_dim, kernel_size=1)
self.gamma2 = Parameter(torch.zeros(1))
self.conv3 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=4, padding=4), nn.BatchNorm2d(down_dim), nn.PReLU()
)
self.query_conv3 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.key_conv3 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.value_conv3 = Conv2d(in_channels=down_dim, out_channels=down_dim, kernel_size=1)
self.gamma3 = Parameter(torch.zeros(1))
self.conv4 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=6, padding=6), nn.BatchNorm2d(down_dim), nn.PReLU()
)
self.query_conv4 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.key_conv4 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.value_conv4 = Conv2d(in_channels=down_dim, out_channels=down_dim, kernel_size=1)
self.gamma4 = Parameter(torch.zeros(1))
self.conv5 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=1),nn.BatchNorm2d(down_dim), nn.PReLU() #如果batch=1 ,进行batchnorm会有问题
)
self.fuse = nn.Sequential(
nn.Conv2d(5 * down_dim, in_dim, kernel_size=1), nn.BatchNorm2d(in_dim), nn.PReLU()
)
self.softmax = Softmax(dim=-1)
def forward(self, x):
x = self.down_conv(x)
conv1 = self.conv1(x)
conv2 = self.conv2(x)
m_batchsize, C, height, width = conv2.size()
proj_query2 = self.query_conv2(conv2).view(m_batchsize, -1, width * height).permute(0, 2, 1)
proj_key2 = self.key_conv2(conv2).view(m_batchsize, -1, width * height)
energy2 = torch.bmm(proj_query2, proj_key2)
attention2 = self.softmax(energy2)
proj_value2 = self.value_conv2(conv2).view(m_batchsize, -1, width * height)
out2 = torch.bmm(proj_value2, attention2.permute(0, 2, 1))
out2 = out2.view(m_batchsize, C, height, width)
out2 = self.gamma2* out2 + conv2
conv3 = self.conv3(x)
m_batchsize, C, height, width = conv3.size()
proj_query3 = self.query_conv3(conv3).view(m_batchsize, -1, width * height).permute(0, 2, 1)
proj_key3 = self.key_conv3(conv3).view(m_batchsize, -1, width * height)
energy3 = torch.bmm(proj_query3, proj_key3)
attention3 = self.softmax(energy3)
proj_value3 = self.value_conv3(conv3).view(m_batchsize, -1, width * height)
out3 = torch.bmm(proj_value3, attention3.permute(0, 2, 1))
out3 = out3.view(m_batchsize, C, height, width)
out3 = self.gamma3 * out3 + conv3
conv4 = self.conv4(x)
m_batchsize, C, height, width = conv4.size()
proj_query4 = self.query_conv4(conv4).view(m_batchsize, -1, width * height).permute(0, 2, 1)
proj_key4 = self.key_conv4(conv4).view(m_batchsize, -1, width * height)
energy4 = torch.bmm(proj_query4, proj_key4)
attention4 = self.softmax(energy4)
proj_value4 = self.value_conv4(conv4).view(m_batchsize, -1, width * height)
out4 = torch.bmm(proj_value4, attention4.permute(0, 2, 1))
out4 = out4.view(m_batchsize, C, height, width)
out4 = self.gamma4 * out4 + conv4
conv5 = F.upsample(self.conv5(F.adaptive_avg_pool2d(x, 1)), size=x.size()[2:], mode='bilinear') # 如果batch设为1,这里就会有问题。
return self.fuse(torch.cat((conv1, out2, out3,out4, conv5), 1))
FoldConv_ASPP[2020]
ECCV2020 Suppress and Balance: A Simple Gated Network for Salient Object Detection
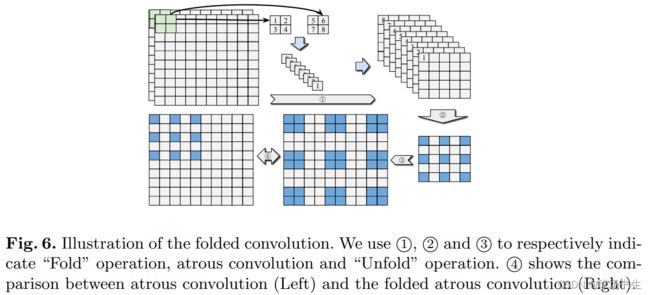
ASPP中空洞卷积只能聚合9个单点像素,而为了获得9个成块的特征,FoldConv先将特征图Fold之后实施空洞卷积最后再Unflod回去。参数量会增大很多,因为这里通道数增加了,Dconv的参数也增加四倍。
class FoldConv_aspp(nn.Module):
def __init__(self, in_channel, out_channel, out_size,
kernel_size=3, stride=1, padding=0, dilation=1, groups=1,
win_size=3, win_dilation=1, win_padding=0):
super(FoldConv_aspp, self).__init__()
#down_C = in_channel // 8
self.down_conv = nn.Sequential(nn.Conv2d(in_channel, out_channel, 3,padding=1),nn.BatchNorm2d(out_channel),
nn.PReLU())
self.win_size = win_size
self.unfold = nn.Unfold(win_size, win_dilation, win_padding, win_size)
fold_C = out_channel * win_size * win_size
down_dim = fold_C // 2
self.conv1 = nn.Sequential(nn.Conv2d(fold_C, down_dim,kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv2 = nn.Sequential(nn.Conv2d(fold_C, down_dim, kernel_size, stride, padding, dilation, groups),
nn.BatchNorm2d(down_dim),
nn.PReLU())
self.conv3 = nn.Sequential(nn.Conv2d(fold_C, down_dim, kernel_size=3, dilation=4, padding=4), nn.BatchNorm2d(down_dim), nn.PReLU())
self.conv4 = nn.Sequential(nn.Conv2d(fold_C, down_dim, kernel_size=3, dilation=6, padding=6), nn.BatchNorm2d( down_dim), nn.PReLU())
self.conv5 = nn.Sequential(nn.Conv2d(fold_C, down_dim, kernel_size=1),nn.BatchNorm2d(down_dim), nn.PReLU() #如果batch=1 ,进行batchnorm会有问题
)
self.fuse = nn.Sequential(nn.Conv2d(5 * down_dim, fold_C, kernel_size=1), nn.BatchNorm2d(fold_C), nn.PReLU())
# self.fold = nn.Fold(out_size, win_size, win_dilation, win_padding, win_size)
self.up_conv = nn.Conv2d(out_channel, out_channel, 1)
def forward(self, in_feature):
N, C, H, W = in_feature.size()
in_feature = self.down_conv(in_feature) #降维减少通道数
in_feature = self.unfold(in_feature) #滑窗 [B, C* kH * kW, L]
in_feature = in_feature.view(in_feature.size(0), in_feature.size(1),
H // self.win_size, W // self.win_size)
in_feature1 = self.conv1(in_feature)
in_feature2 = self.conv2(in_feature)
in_feature3 = self.conv3(in_feature)
in_feature4 = self.conv4(in_feature)
in_feature5 = F.upsample(self.conv5(F.adaptive_avg_pool2d(in_feature, 1)), size=in_feature.size()[2:], mode='bilinear')
in_feature = self.fuse(torch.cat((in_feature1, in_feature2, in_feature3,in_feature4,in_feature5), 1))
in_feature = in_feature.reshape(in_feature.size(0), in_feature.size(1), -1)
in_feature = F.fold(input=in_feature, output_size=H, kernel_size=2, dilation=1, padding=0, stride=2)
in_feature = self.up_conv(in_feature)
return in_feature