协同过滤算法详解
一、协同过滤算法简介
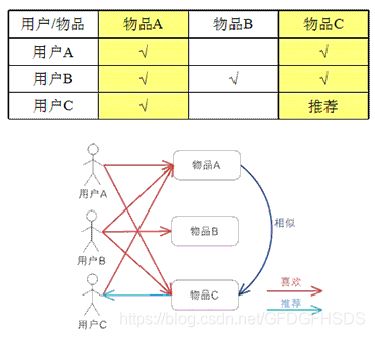
协同过滤算法是一种较为著名和常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。也就是常见的“猜你喜欢”,和“购买了该商品的人也喜欢”等功能。它的主要实现由:
●根据和你有共同喜好的人给你推荐
●根据你喜欢的物品给你推荐相似物品
●根据以上条件综合推荐
因此可以得出常用的协同过滤算法分为两种,基于用户的协同过滤算法(user-based collaboratIve filtering),以及基于物品的协同过滤算法(item-based collaborative filtering)。特点可以概括为“人以类聚,物以群分”,并据此进行预测和推荐。
二、协同过滤算法的关键问题
实现协同过滤算法,可以概括为几个关键步骤:
1:根据历史数据收集用户偏好
2:找到相似的用户(基于用户)或物品(基于物品)
三、基于用户的协同过滤算法描述
基于用户的协同过滤算法的实现主要需要解决两个问题,一是如何找到和你有相似爱好的人,也就是要计算数据的相似度:
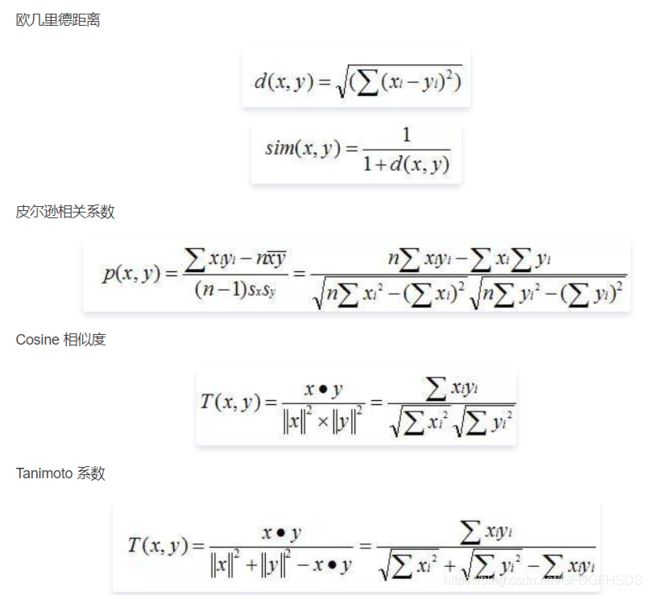
计算相似度需要根据数据特点的不同选择不同的相似度计算方法,有几个常用的计算方法:
(1)杰卡德相似系数(Jaccard similarity coefficient)
其实就是集合的交集除并集
![]()
(2)夹角余弦(Cosine)
在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
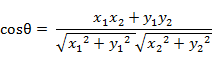
两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦:
![]()
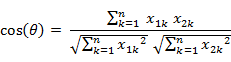
即
(3)其余方法,例如欧式距离、曼哈顿距离等相似性度量方法可以点此了解
找到与目标用户最相邻的K个用户
我们在寻找有有相同爱好的人的时候,可能会找到许多个,例如几百个人都喜欢A商品,但是这几百个人里,可能还有几十个人与你同时还喜欢B商品,他们的相似度就更高,我们通常设定一个数K,取计算相似度最高的K个人称为最相邻的K个用户,作为推荐的来源群体。
这里存在一个小问题,就是当用户数据量十分巨大的时候,在所有人之中找到K个基友花的时间可能会比较长,而且实际中大部分的用户是和你没有什么关系的,所以在这里需要用到反查表
所谓反查表,就是比如你喜欢的商品有A、B、C,那就分别以ABC为行名,列出喜欢这些商品的人都有哪些,其他的人就必定与你没有什么相似度了,从这些人里计算相似度,找到K个人
通过这K个人推荐商品
我们假设找到的人的喜好程度如下
User-Based CF
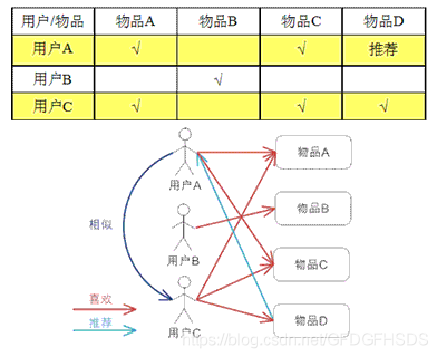
先看公式
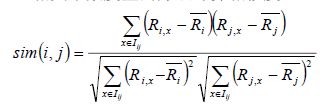
该公式要计算用户i和用户j之间的相似度, I(ij)是代表用户i和用户j共同评价过的物品, R(i,x)代表用户i对物品x的评分, R(i)头上有一杠的代表用户i所有评分的平均分, 之所以要减去平均分是因为有的用户打分严有的松, 归一化用户打分避免相互影响。
该公式没有考虑到热门商品可能会被很多用户所喜欢, 所以还可以优化加一下权重, 这儿就不演示公式了。
在实际生产环境中, 经常用到另外一个类似的算法Slope One, 该公式是计算评分偏差, 即将共同评价过的物品, 将各自的打分相减再求平均。
Item-Based CF
先看公式:
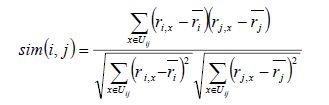
这类算法会面临两个典型的问题:
矩阵稀疏问题
计算资源有限导致的扩展性问题
基于此, 专家学者们又提出了系列基于模型的协同过滤算法。
基于模型的协同过滤算法
常见的有:
基于矩阵分解和潜在语义的
基于贝叶斯网络的
基于SVM的
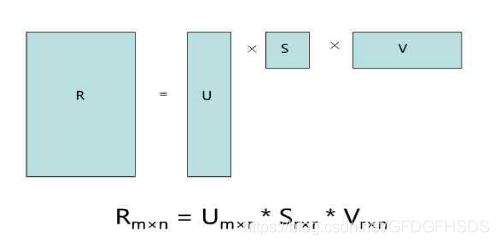
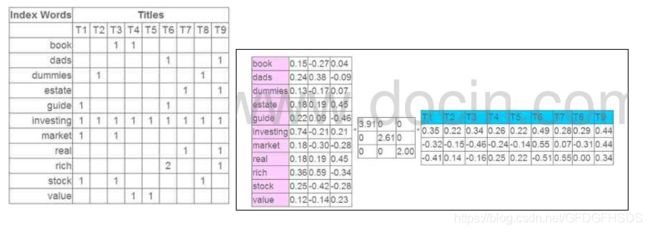
这儿只简单介绍一下基于矩阵分解的潜在语义模型的推荐算法。该算法首先将稀疏矩阵用均值填满, 然后利用矩阵分解将其分解为两个矩阵相乘, 如下图:
Item-CF和User-CF选择
user和item数量分布以及变化频率
如果user数量远远大于item数量, 采用Item-CF效果会更好, 因为同一个item对应的打分会比较多, 而且计算量会相对较少
如果item数量远远大于user数量, 则采用User-CF效果会更好, 原因同上
在实际生产环境中, 有可能因为用户无登陆, 而cookie信息又极不稳定, 导致只能使用item-cf
如果用户行为变化频率很慢(比如小说), 用User-CF结果会比较稳定
如果用户行为变化频率很快(比如新闻, 音乐, 电影等), 用Item-CF结果会比较稳定
相关和惊喜的权衡
item-based出的更偏相关结果, 出的可能都是看起来比较类似的结果
user-based出的更有可能有惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜
数据更新频率和时效性要求
对于item更新时效性较高的产品, 比如新闻, 就无法直接采用item-based的CF, 因为CF是需要批量计算的, 在计算结果出来之前新的item是无法被推荐出来的, 导致数据时效性偏低;
但是可以采用user-cf, 再记录一个在线的用户item行为对, 就可以根据用户最近类似的用户的行为进行时效性item推荐;
对于像影视, 音乐之类的还是可以采用item-cf的
组合推荐技术
其实从实践中来看, 没有哪种推荐技术敢说自己没有弊端, 往往一个好的推荐系统也不是只用一种推荐技术就解决问题, 往往都是相互结合来弥补彼此的不足, 常见的组合方式如下:
混合推荐技术: 同时使用多种推荐技术再加权取最优;
切换推荐技术: 根据用户场景使用不同的推荐技术;
特征组合推荐技术: 将一种推荐技术的输出作为特征放到另一个推荐技术当中;
层叠推荐技术: 一个推荐模块过程中从另一个推荐模块中获取结果用于自己产出结果;
相似度计算:
收集用户偏好

矩阵分解
Spark推荐模型库当前只包含基于矩阵分解(matrix factorization)的实现,由此我们也将重点关注这类模型。它们有吸引人的地方。首先,这些模型在协同过滤中的表现十分出色。而在Netflix Prize等知名比赛中的表现也很拔尖
1,显式矩阵分解
要找到和“用户物品”矩阵近似的k维(低阶)矩阵,最终要求出如下两个矩阵:一个用于表示用户的U × k维矩阵,以及一个表征物品的I × k维矩阵。
这两个矩阵也称作因子矩阵。它们的乘积便是原始评级矩阵的一个近似。值得注意的是,原始评级矩阵通常很稀疏,但因子矩阵却是稠密的。
特点:因子分解类模型的好处在于,一旦建立了模型,对推荐的求解便相对容易。但也有弊端,即当用户和物品的数量很多时,其对应的物品或是用户的因子向量可能达到数以百万计。
这将在存储和计算能力上带来挑战。另一个好处是,这类模型的表现通常都很出色。
2,隐式矩阵分解(关联因子分确定,可能随时会变化)
隐式模型仍然会创建一个用户因子矩阵和一个物品因子矩阵。但是,模型所求解的是偏好矩阵而非评级矩阵的近似。类似地,此时用户因子向量和物品因子向量的点积所得到的分数
也不再是一个对评级的估值,而是对某个用户对某一物品偏好的估值(该值的取值虽并不严格地处于0到1之间,但十分趋近于这个区间)
3,最小二乘法(Alternating Least Squares ALS):解决矩阵分解的最优化方法
ALS的实现原理是迭代式求解一系列最小二乘回归问题。在每一次迭代时,固定用户因子矩阵或是物品因子矩阵中的一个,然后用固定的这个矩阵以及评级数据来更新另一个矩阵。
之后,被更新的矩阵被固定住,再更新另外一个矩阵。如此迭代,直到模型收敛(或是迭代了预设好的次数)。