协同过滤(Collaborative Filtering)
协同过滤,顾名思义就是协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。
协同过滤是推荐系统的重要模型之一,推荐系统是用来向用户推荐物品的。协同过滤分为两种:
1.基于用户的协同过滤。
2. 基于物品的协同过滤。
无论是基于用户还是基于物品都是为了找到用户可能喜欢的物品把它给过滤出来,推荐给用户。
1.基于用户的协同过滤
思想:找到和目标用户相似的用户,推荐该相似用户使用过但该用户没见过的物品。
主要有两个步骤:
1.计算每个用户和目标用户的相似度,并选出n个最相似的(n为一个超参数)
2.根据相似用户对某一物品的评价计算出目标用户对这个物品的评价,设定一个阈值判断是否推荐。
示例:
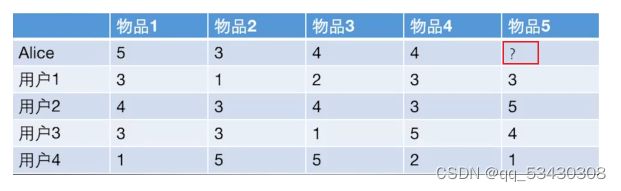
图1.评分矩阵
这是一个不同用户对于不同物品的评分矩阵,现在要决定是否对Alice推荐物品5,也就是要计算出Alice对物品5的评分。
首先,计算每个用户与Alice的相似度,计算相似度主要有以下几种方式。
1.余弦相似度公式,衡量了用户向量i和用户向量j之间的向量夹角的大小,显然夹角越小,余弦相似度越大,用户相似度越大。
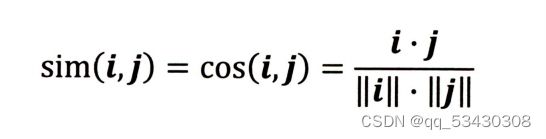
本例中,i和j向量表示两个用户对物品的评分矩阵,||i||和||j||表示向量i和j的长度。
2.皮尔逊相关系数,相比余弦相似度公式皮尔逊相关系数通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置的影响。
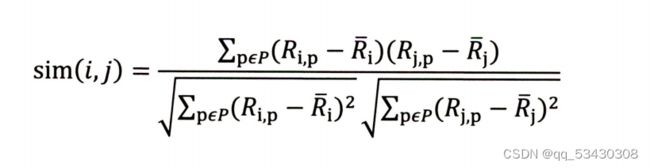
其中,Ri,p代表用户i对物品p的评分。R_i代表用户i对所有物品的平均评分,p代表所有物品的集合。
然后根据相似度就能找到与目标用户最相似的n个用户了,之后我们就要计算用户对某个物品的具体评分了。
通常使用加权平均的方法
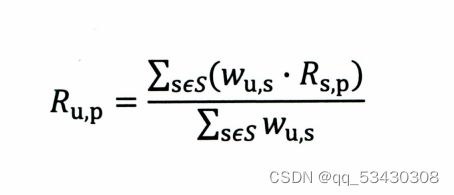
其中权重Wu,s是用户u和用户s的相似度,Rs,p是用户s对物品p的评分。
至此,计算完目标用户对物品的评分之后就可以根据阈值选择是否向目标用户推荐了,整个协同过滤算法也结束了。
以上介绍的是基于用户的协同过滤,他的缺点有:
1.维护用户的相似度矩阵的成本较高,因为在互联网中用户的数量是远远多于物品的数量的,而且用户的数量增长的飞快,这会使相似度矩阵的空间复杂度以n^2的速度快速增长,这是在线存储系统难以承受的扩展速度。
2.在正反馈获取较难的场景(酒店预订,大件商品的购买等)适用效果不好。例如说一个平台售卖大件商品那么这个商品的历史购买用户一定是较少的,因此找到相似的用户就十分困难。
2.基于物品的协同过滤
思想:找到和历史上用户感兴趣的物品相似的物品进行推荐。
也有两个步骤:
1.计算各个物品之间的相似度,计算方式和用户相似度类似。
2.对于一个用户找出其历史上做出过正反馈的物品(也就是其评价过并且表示喜欢的物品),看正反馈的物品和未作出评价物品之间的相似度并且计算出其评价得分并进行排序,选择得分最大的n个物品进行推荐。
如果在计算最终得分时,未作出评价的物品和正反馈物品中的多个都有相似度那么其最终得分应该是这些物品的累加。

3.总结
协同过滤模型是一个非常直观,可解释性很强的模型,但是其不具备较强泛化能力,它无法将两个物品相似这一信息推广到其它物品相似性的计算上。这会导致热门的物品具有很强的头部效应,容易和大量物品产生相似,而尾部的物品很少和其他物品产生相似导致很少被推荐。
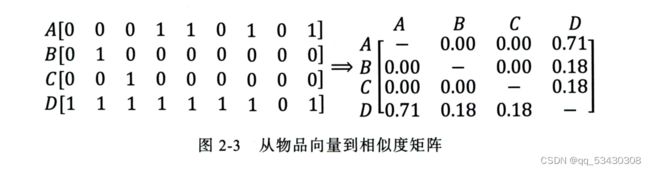 例如说这是一个物品之间的相似度矩阵,我们可以看出A,B,C之间的相似度为0,与A,B,C最相似的物品为D,在基于物品的协同过滤中物品D将会被推荐给所有对A,B,C,有过正反馈的用户。
例如说这是一个物品之间的相似度矩阵,我们可以看出A,B,C之间的相似度为0,与A,B,C最相似的物品为D,在基于物品的协同过滤中物品D将会被推荐给所有对A,B,C,有过正反馈的用户。
但其实物品D被推荐,只是因为他是一件热门商品,而A,B,C之间因为缺少相似性计算的直接数据,导致他们之间很难产生相似度,因而被忽略,这是协同过滤的一种天然缺陷。
为了解决这一问题,矩阵分解被提出了。