Spark 3.0 - 3.ML 基本流程与 LR 参数详解、实战
目录
一.引言
二.ML 基本流程
1.常见概念
2.ML 基本流程示例 - LR
2.1 LR 参数
2.2 训练
2.3 预测
2.4 模型参数获取
2.5 基于参数手动推理
三.总结
一.引言
DataFrame 即 DataSet[Row],是 ML 专用的数据格式。ML 支持较多的数据格式,从最基本的 Spark 数据集 DataFrame 到部署在集群中的向量与矩阵,同时还支持在本地计算机中的本地化格式。
| Type | 释义 |
| Local Vector | 本地向量集,向 Spark 提供可操作的数据集合 |
| Labeled Point | 向量标签,用于区分不同的数据集合 |
| Local Matrix | 本地矩阵,将数据集合以矩阵形式存储于本地 |
| Distributed Matrix | 分布式矩阵,将数据集合与矩阵形式存储于分布式计算机中 |
二.ML 基本流程
1.常见概念
- DataFrame
数据源,也是 Spark Sql 中的概念,可以容纳多种数据类型用来保存数据。例如,一个 DataFrame 可以存储文本、标签、特征向量等不同列。可以说 ML 的所有基本 API 最终都需要以源头的 DataFrame 数据为主。
- Transformer
转换器,和 Spark、Flink 里的 Transformer 类似,例如 RDD -> RDD、DataStream -> DataStream,这里 Transformer 负责将 DataFrame 转换为 DataFrame。每个 Tansformer 都有一个 transform 方法,负责在原有 DataFrame 的基础上添加一个或者多个列得到新的 DataFrame。例如将原始数据转换,并增加一列新的特征向量。
- Estimator
Estimator 负责根据样本 fit 训练得到一个模型,模型的本质也是 Transformer,因为给定一个 DataFrame 数据集,模型可以转化得到一个新的预测标签列,所以 Estimator 就是调用 fit 方法并最终得到一个 Transformer。LR、SVM、PCA 等都可以看做是 Estimator。
Tips:
一般来说,fit 需要 DataFrame 中存在名为 label 与 features 的 Column 列。
基于上述三个概念,即可实现 ML 的基本流程:
通过 DataFrame 存储原始数据,再通过一个或多个 Transformer.transform 将 DataFrame 的数据处理为可供 Estimator 处理的数据类型,随后调用 Estimator.fit 得到 Model 即 Transform,此时训练流程结束。后续可以基于 Model 进行预测或者保存模型参数等。
2.ML 基本流程示例 - LR
下面通过最基础的 LR 线性回归示例 ML 基本流程。
2.1 LR 参数
首先熟一下 Spark ML 下 LogisticRegression 模型的参数:
| 参数 | 含义 | 默认值 |
| aggregationDepth | 建议的树聚合深度(>=2) | 2 |
| elasticNetParam | ElasticNet混合参数,范围为[0,1]。0-L2 惩罚、1-L1 惩罚 | 0.0 - L2 惩罚 |
| family | 族的名称,模型中使用的标签分布的描述。自动、二项、多项 | 自动 |
| featuresCol | 特征列,一般为 features | features |
| fitIntercept | 是否设置偏置项 ,即 wTx + b 的 bias | true |
| labelCol | 标签列 | label |
| lowerBoundsOnefficients | 如果在约束优化下拟合,系数 w 的下限 | 无 |
| lowerBoundsOnIntercepts | 如果符合下界约束优化,则截取 b 的下限 | 无 |
| maxIter | 最大迭代次数 >= 0 | 100 |
| predictionCol | 预测列名 | prediction |
| probabilityCol | 预测类条件概率的列名 | probability |
| rawPredictionCol | 预测概率值列名 | rawPrecision |
| regParam | 正则化系数 >= 0 | 0.0 |
| standardization | 是否在拟合模型之前标准化训练特征 | true |
| threshold | 二进制分类预测中的阈值,范围[0,1] | 0.5 |
| thresholds | 多类分类中的阈值,用于调整预测每个类的概率。数组的长度必须等于类的数量,值大于0,但最多有一个值可能为0。 | 无 |
| tol | 迭代算法的收敛公差(>=0) | 1.0E-6 |
| upperBoundsOnCoefficients | 在约束优化条件下拟合系数的上界 | 无 |
| upperBoundsOnIntercepts | 如在约束优化条件下截距的上界 | 无 |
| weightCol | 权重列名,未设置默认均为 1.0 | 无 |
相比之前 2.x 版本的 LR,这里参数的丰富度也有所改善,一般情况下微调 MaxIter、RegParam 即可完成简易 LR 模型的训练。
2.2 训练
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder //创建spark会话
.master("local") //设置本地模式
.appName("EstimatorTransformerParamExample") //设置名称
.getOrCreate() //创建会话变量
// 通过 DenseVector 转化得到含有 label 与 features 的 DataFrame
val training = spark.createDataFrame(Seq(
(1.0, Vectors.dense(0.0, 1.1, 0.1)),
(0.0, Vectors.dense(2.0, 1.0, -1.0)),
(0.0, Vectors.dense(2.0, 1.3, 1.0)),
(1.0, Vectors.dense(0.0, 1.2, -0.5))
)).toDF("label", "features")
// 创建一个 LR 模型作为 Estimator
val lr = new LogisticRegression()
// 设置最大迭代次数与正则化稀疏
lr.setMaxIter(10)
.setRegParam(0.01)
// fit 生成 Model-Transform
val model1 = lr.fit(training)
println(s"Model 1 was fit using parameters: ${model1.parent.extractParamMap}")这里数据通过 DenseVector 模拟生成,每一个样本包含三个数字列视为 features 特征列,以及一个 0-1 标签视为 label 标签列。初始化 LR 模型并设置相关参数视为 Estimator,通过 model.fit 即可训练得到 LR 模型即一个 Transform。通过 extracParamMap 可以获取 Estimator 的配置参数:
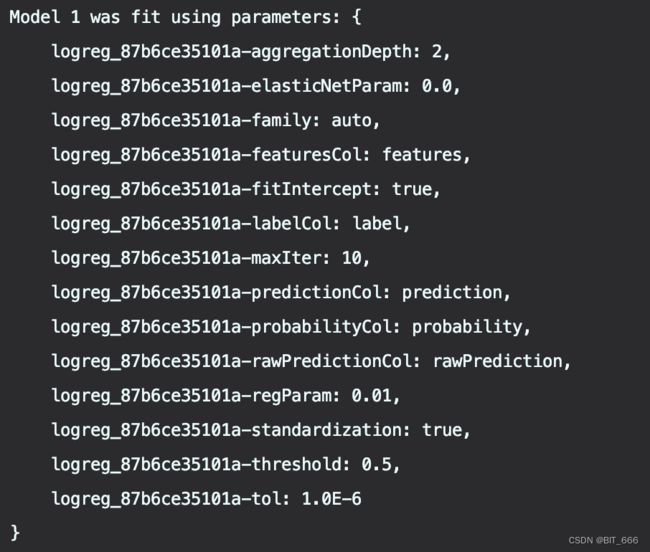
运行上述代码即可开始 LR 训练流程,出现下述日志代表训练开始:

其中 Stage uid 为当前流程的唯一 Id,后续会在 Pipeline 中介绍该概念。
2.3 预测
// 初始化测试数据
val test = spark.createDataFrame(Seq(
(1.0, Vectors.dense(-1.0, 1.5, 1.3)),
(0.0, Vectors.dense(3.0, 2.0, -0.1)),
(1.0, Vectors.dense(0.0, 2.2, -1.5))
)).toDF("label", "features")
// 调用 transform 方法获取预测概率 Prob 与预测标签 pre
model1.transform(test)
.select("features", "label", "probability", "prediction")
.collect()
.foreach { case Row(features: Vector, label: Double, prob: Vector, prediction: Double) =>
println(s"($features, $label) -> prob=$prob, prediction=$prediction")
}调用 model.transform 生成带有对应数据的 probability 预测概率列与 prediction 预测标签列的 DataFrame,随后使用 select + collect 将数据获取至本地并打印:
([-1.0,1.5,1.3], 1.0) -> prob=[0.0013759947069214356,0.9986240052930786], prediction=1.0
([3.0,2.0,-0.1], 0.0) -> prob=[0.9816604009374171,0.01833959906258293], prediction=0.0
([0.0,2.2,-1.5], 1.0) -> prob=[0.0016981475578358176,0.9983018524421641], prediction=1.0可以看到原始数据与其对应的新的预测 prob 与 predict P值,由于是二分类任务,所以 prob 是二维数组,分别代表预测为 0 与预测为 1 的 prob,同时 predict 为最终标签。
2.4 模型参数获取
一般情况下,完成 Train + Test 即可满足常规需求,但是还有一些同学希望获取模型参数,获取 LR 参数 weights 与 截距项 bias:
val weights = model1.coefficientMatrix
val bias = model1.interceptVector.toDense
println(s"Model Weights: $weights\nBias: $bias")Model Weights: -3.1009356010205327 2.60821473832145 -0.3801791225430309
Bias: [0.06817659473873576]由于原始特征列共 3 维,所以训练得到的参数 w 也是 3 维,bias 截距项为 1 维。
2.5 基于参数手动推理
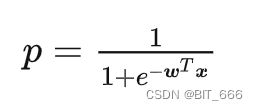
LR 预测公式如上,其中 w 为多维数组对应上述 coefficientMatrix 获取的三维矩阵,x 为原始特征对应 DenseVector 数据,可以通过 mutiply 得到乘积再加上 bias 再套用 p(x) 即可得到 prob,下面通过代码实现下:
// 测试数据
val testData = Array(Vectors.dense(-1.0, 1.5, 1.3),
Vectors.dense(3.0, 2.0, -0.1),
Vectors.dense(0.0, 2.2, -1.5))
// 根据 weight、bias 与 P(x) 获取概率值
testData.foreach(vector => {
val mul = weights.multiply(vector)
val sumValue = mul.values.head + bias.values.head
val fx = 1 / (1 + math.exp(-1 * sumValue))
println(1 - fx, fx)
})(0.0013759947069214018,0.9986240052930786)
(0.981660400937417,0.01833959906258293)
(0.0016981475578359273,0.9983018524421641)与上面得到的结果一致 [结尾可能存在精度误差] :

三.总结
上面通过 Spark + DataFrame + LR 实现了 ML 的基本流程,可以看到在不感知内部计算的情况下,整体的代码量非常少且清晰,下一篇文章将介绍 ML Pipeline 管道,实现更统一化的一致性处理流程。