深度学习图像处理目标检测图像分割计算机视觉 09--目标检测
深度学习图像处理目标检测图像分割计算机视觉 09--目标检测
- 摘要
- 一、目标检测
-
- 1.1 R-FCN
- 1.2 YOLO
-
- 1.2.1 YOLO V1
- 1.2.2 YOLO V2
- 1.2.3 YOLO V3
- 二、MNIST训练
- 三、基于深度学习的医学图像分割技术研究
-
- 3.1 FCN
- 3.2 U-NET
- 四、毕设
- 总结
摘要
本周计划完成目标检测的下半部分网络学习,运行一个手写数字识别的代码。了解深度学习医学图像处理中常用的网络结构,以及这些结构的优缺点。本科毕设顺利完成开题报告答辩部分。
一、目标检测
1.1 R-FCN




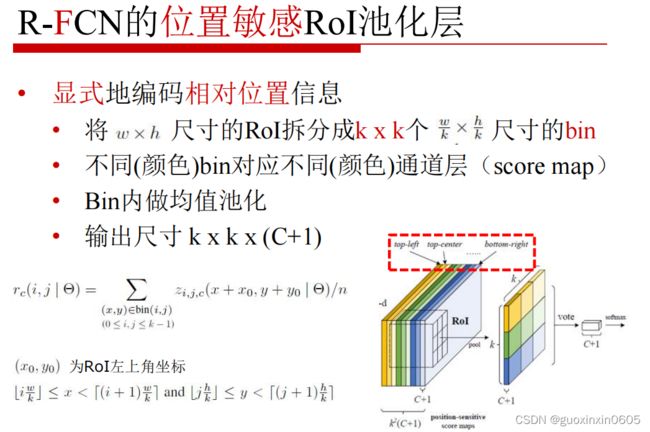





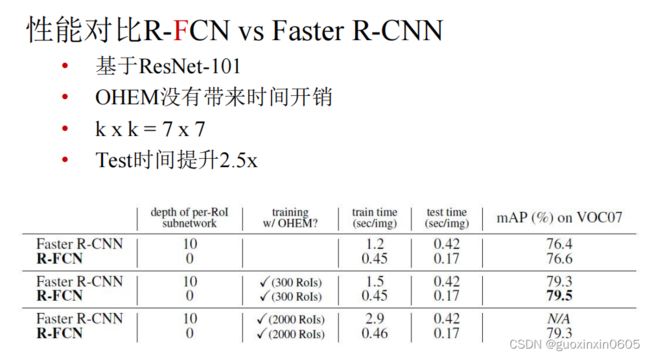
1.2 YOLO
1.2.1 YOLO V1
YOLO分为三个版本,V1、V2和V3,版本逐渐优化。

在这里插入图片描述




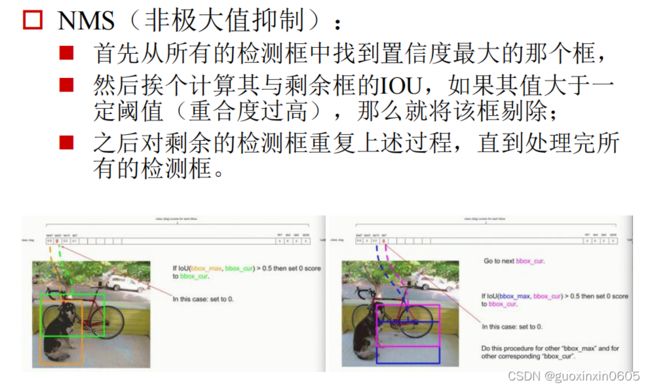


1.2.2 YOLO V2





1.2.3 YOLO V3


二、MNIST训练
运行这个代码可以先去网上下载这几个数据集,作为训练和测试集。
下述代码运行在的jupyter notebook中,安装好自己需要的库。
from __future__ import division, print_function, absolute_import
# Import MNIST data,MNIST数据集导入
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=False)
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# Training Parameters,超参数
learning_rate = 0.001 #学习率
num_steps = 2000 # 训练步数
batch_size = 128 # 训练数据批的大小
# Network Parameters,网络参数
num_input = 784 # MNIST数据输入 (img shape: 28*28)
num_classes = 10 # MNIST所有类别 (0-9 digits)
dropout = 0.75 # Dropout, probability to keep units = (1-p),保留神经元相应的概率为(1-p)=(1-0.75)=0.25
# Create the neural network,创建深度神经网络
def conv_net(x_dict, n_classes, dropout, reuse, is_training):
# Define a scope for reusing the variables,确定命名空间
with tf.variable_scope('ConvNet', reuse=reuse):
# TF Estimator类型的输入为像素
x = x_dict['images']
# MNIST数据输入格式为一位向量,包含784个特征 (28*28像素)
# 用reshape函数改变形状以匹配图像的尺寸 [高 x 宽 x 通道数]
# 输入张量的尺度为四维: [(每一)批数据的数目, 高,宽,通道数]
x = tf.reshape(x, shape=[-1, 28, 28, 1])
# 卷积层,32个卷积核,尺寸为5x5
conv1 = tf.layers.conv2d(x, 32, 5, activation=tf.nn.relu)
# 最大池化层,步长为2,无需学习任何参量
conv1 = tf.layers.max_pooling2d(conv1, 2, 2)
# 卷积层,64个卷积核,尺寸为3x3
conv2 = tf.layers.conv2d(conv1, 64, 3, activation=tf.nn.relu)
# 最大池化层,步长为2,无需学习任何参量
conv2 = tf.layers.max_pooling2d(conv2, 2, 2)
# 展开特征为一维向量,以输入全连接层
fc1 = tf.contrib.layers.flatten(conv2)
# 全连接层
fc1 = tf.layers.dense(fc1, 1024)
# 应用Dropout (训练时打开,测试时关闭)
fc1 = tf.layers.dropout(fc1, rate=dropout, training=is_training)
# 输出层,预测类别
out = tf.layers.dense(fc1, n_classes)
return out
# 确定模型功能 (参照TF Estimator模版)
def model_fn(features, labels, mode):
# 构建神经网络
# 因为dropout在训练与测试时的特性不一,我们此处为训练和测试过程创建两个独立但共享权值的计算图
logits_train = conv_net(features, num_classes, dropout, reuse=False, is_training=True)
logits_test = conv_net(features, num_classes, dropout, reuse=True, is_training=False)
# 预测
pred_classes = tf.argmax(logits_test, axis=1)
pred_probas = tf.nn.softmax(logits_test)
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode, predictions=pred_classes)
# 确定误差函数与优化器
loss_op = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=logits_train, labels=tf.cast(labels, dtype=tf.int32)))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op, global_step=tf.train.get_global_step())
# 评估模型精确度
acc_op = tf.metrics.accuracy(labels=labels, predictions=pred_classes)
# TF Estimators需要返回EstimatorSpec
estim_specs = tf.estimator.EstimatorSpec(
mode=mode,
predictions=pred_classes,
loss=loss_op,
train_op=train_op,
eval_metric_ops={'accuracy': acc_op})
return estim_specs
# 构建Estimator
model = tf.estimator.Estimator(model_fn)
# 确定训练输入函数
input_fn = tf.estimator.inputs.numpy_input_fn(
x={'images': mnist.train.images}, y=mnist.train.labels,
batch_size=batch_size, num_epochs=None, shuffle=True)
# 开始训练模型
model.train(input_fn, steps=num_steps)
# 评判模型
# 确定评判用输入函数
input_fn = tf.estimator.inputs.numpy_input_fn(
x={'images': mnist.test.images}, y=mnist.test.labels,
batch_size=batch_size, shuffle=False)
model.evaluate(input_fn)
# 预测单个图像
n_images = 6
# 从数据集得到测试图像
test_images = mnist.test.images[:n_images]
# 准备输入数据
input_fn = tf.estimator.inputs.numpy_input_fn(
x={'images': test_images}, shuffle=False)
# 用训练好的模型预测图片类别
preds = list(model.predict(input_fn))
# 可视化显示
for i in range(n_images):
plt.imshow(np.reshape(test_images[i], [28, 28]), cmap='gray')
plt.show()
print("Model prediction:", preds[i])
三、基于深度学习的医学图像分割技术研究
随着医疗科学技术的快速发展,医学影像已成为医生了解、分析病情的重要参考信息,在诊断疾病、评估治疗等方面发挥着重要作用。医学图像分割是从医学影像中识别病变器官的像素点,旨在获取这些病
变部位的信息特征,在医学图像分析任务中具有一定的技术难度。医学图像分割方法在发展的过程中形成了不同的分割算法,包括: 基于灰度阈值的分割算法、基于边缘检测的分割算法、基于区域的分水岭分割算法以及结合特定理论的分割算法等。
随着计算机硬件性能的迅速提高,深度学习方法应运而生,在图像处理任务中展现出强大能力。深度
学习的本质是将大量数据样本输入构建的多层机器学习模型之中,学习对象的特征信息,最终提高分类精度。残差网络架构有效地解决了神经网络梯度弥散的问题;融合多种网络结构而构造出的深度残差全卷积网络( Fully Convolutional Residual Network,FCRN) ,在皮肤镜图像中自动分割黑色素瘤效果显著。
超声成像的工作原理是通过超声束对人体进行照射扫描,利用扫描之后产生的信号重现人体器官组织影像。三维成像、超声生物显微镜、穿透式超声成像等进一步丰富了超声成像技术。超声成像可确定人体器官组织的位置、大小、形态以及病灶的范围和物理性质; 超声成像还可以提供身体组织的解剖图像,鉴别胎儿发育是否正常,被广泛地应用于消化系统、泌尿系统、心血管系统疾病的诊断中,已成为一种非常重要的医学成像技术。
传统神经网络进行图像分割的策略为将逐个像素及其邻域输入到卷积神经网络中进行训练和预测。
种方式的弊端在于需要很大的存储开销,不仅计算量大、效率低下,而且邻域的大小限制了感受野的范围,降低了特征提取能力。
3.1 FCN
全卷积网络( Fully Convolu- tional Network,FCN) 用 于 图 像 分 割可解决这个问题。该 网 络 以
AlexNet网络结构为基础,将全连接层全部转化为卷积层,通过上采样的方式增加特征图的维度。全卷积网络的创新在于样本图片尺寸不再受到限制,适用性更加广泛,减少了冗余结构,运行效率更加高效。。但是该方法的缺点在于图像细节信息会有所丢失,分割精度有待进一步提高。

3.2 U-NET
在 FCN 思想的基础上,提出 U - net 网络架构。该网络结构由编码阶段和解码阶段组成,在编码过程中,下采样图像提取图片特征; 解码过程中,对图片进行上采样,以便逐步恢复图片的大小。编码阶段连续的卷积核和池化操作丢失了图片的部分特征信息,但是在解码阶段上采样之后的特征图与跳跃连接的前端信息相融合,丰富了图像的细节特征,已应用在对神经元、细胞瘤和 HeLa细胞的医学图像分割任务中。

网络结构对比:

在脑组织分割,肺部分割和血管分割任务中,由于采集信息时的技术以及采集时间等等原因,会对原始图像有一些影响,那么针对不同的图像,提出一些不同的方法,大多数采用监督深度学习的方法提取特征,再结合其他已有技术和分类器来保证分割的准确性。
四、毕设
已顺利完成开题答辩。
总结
本周完成了目标检测的所有网络模块的学习。总结一下前面学过的模型,R-CNN最初提出,但是这个模型把所有的候选区域都单独的进行卷积,时间开销很大,进化到SOO-NET,这个模型实现了卷积层共享,但是卷积层不能进行微调fine-tuning,进化到Fast R-CNN,它可以进行微调,并且引入了ROI
池化,既然所有的网络都已经变成了卷积模块,那么,索性将选择模块也变成了卷积网络RPN。但是这所有的网络里面都有基层全连接层,全连接层的参数多,并且会丢失很多位置信息,所以进一步进化模型,使得网络结构中只有一层全连接层,剩下的是全卷积层。那么在此基础上,yolo将物体检测任务当作一个分类问题来做,通过yolo,每张图像只需要看一眼就能得出图像中都有哪些物体和这些物体的位置。