【Neo4j】第 11 章 :在您的 Web 应用程序中使用 Neo4j
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
使用 Python 和图形对象映射器创建全栈 Web 应用程序
玩弄新模特
定义结构化节点的属性
创建节点
查询节点
整合关系知识
使用 Flask 和 neomodel 构建由 Neo4j 支持的 Web 应用程序
创建玩具数据
登录页面
读取数据——列出拥有的存储库
改变图表——添加贡献
通过示例了解 GraphQL API – GitHub API v4
端点
返回的属性
查询参数
Mutations
使用 GRANDstack 开发 React 应用程序
GRANDstack – GraphQL、React、Apollo 和 Neo4j 数据库
创建 API
编写 GraphQL 架构
启动应用程序
Mutations
构建用户界面
创建一个简单的组件
添加导航
Mutation
概括
在本书中,我们学到了很多关于 Neo4j 功能的知识,包括图数据建模、Cypher 和使用 Graph Data Science Library 的链接预测。我们所做的几乎所有事情都需要编写 Cypher 查询来提取数据和/或将结果存储在 Neo4j 中。在本章中,我们将讨论如何在真实世界的 Web 应用程序中使用 Neo4j,使用 Python 和 Flask 框架或 React JavaScript 框架。本章还将让您有机会使用 GraphQL 来构建灵活的 Web API。
本章将涵盖以下主题:
- 使用 Python 和图形对象映射器创建全栈 Web 应用程序
- 通过示例了解 GraphQL API – GitHub API v4
- 使用 GRANDstack 开发 React 应用程序
让我们开始吧!
技术要求
在本章中,您将需要以下技术工具:
- Neo4j ≥ 3.5
- Python:
- Flask: 用于构建 Web 应用程序的轻量级但功能强大的框架。
- neomodel:与 Neo4j 兼容的 Python 图形对象映射器。
- requests:用于发出 HTTP 请求的小型 Python 包。我们将使用它来测试基于 GraphQL 的 API。
- JavaScript 和npm
使用 Python 和图形对象映射器创建全栈 Web 应用程序
以编程方式与 Neo4j 交互有多种方式。在前面的章节中,我们使用了 Neo4j Python 驱动程序,我们可以从中执行 Cypher 查询并检索结果,尤其是在数据科学上下文中创建 DataFrames 时。在 Web 应用程序的上下文中,每次我们希望程序对图执行操作时手动编写 Cypher 查询将是一项非常耗时且费力的任务,涉及重复代码。幸运的是,已经创建了图形对象映射器( GOM ) 来将 Python 代码连接到 Neo4j,而无需我们编写单个 Cypher 查询。在本节中,我们将使用该neomodel包并与它一起使用Flask来构建一个显示来自 Neo4j 的信息的 Web 应用程序。
我们的上下文类似于 GitHub:我们的用户可以拥有和/或为存储库做出贡献。
玩弄新模特
neomodel是 Python 的图形对象映射器,其语法非常接近 Django 的对象关系映射( ORM )。例如,为了从User表 (SQL) 中检索 ID 为 1 的用户,在 Django 中,您将编写以下代码:
User.objects.get(id=1)使用以下代码检索具有标签(其属性为)neomodel的节点可以实现相同的目标 :Userid1
User.nodes.get(id=1)在这两种情况下,此语句都返回一个User对象,其id为1. 在 Neo4j 的情况下,我们如何定义这个对象是即将到来的小节的主题。
前面的语句等效于以下 Cypher 查询:
MATCH (u:User {id: 1}) RETURN u通过使用这个包,你还可以遍历关系,这就是图的用途!
定义结构化节点的属性
Neo4j 没有节点属性的模式。您基本上可以添加任何您想要的作为具有任何标签的节点的属性。但是,在大多数情况下,您知道您的数据必须是什么样子,并且至少有一些字段是强制性的。在这种情况下,您需要定义一个StructuredNode. 相反,如果您的节点没有任何常量属性,那么 aSemiStructuredNode将满足您的要求。
StructuredNode 与 SemiStructuredNode
在neomodel中,我们将为图中的每个节点标签创建一个模型。模型是一个类,它将声明附加到给定节点标签的属性。
我们可以选择创建StructuredNode或SemiStructuredNode. AStructuredNode必须声明所有可以附加到它的属性。如果这些属性尚未声明,您将无法向节点添加属性。另一方面,SemiStructuredNode提供更大的灵活性。
在本章中,我们将始终使用,StructuredNode因为图形模式从一开始就很清楚。创建User模型的最少代码如下:
from neomodel import StructuredNode
class User(StructuredNode):
pass下一步是声明此模型的属性。
添加属性
属性有类型。在neomodel中,所有基本类型均可用:
- String
- Integer
- Float
- Boolean
- Date, DateTime
- UniqueID
除此之外,还存在其他额外的类型,如下所示:
- JSON
- Email(一个对其格式进行额外检查的字符串)
- Point(Neo4j 空间类型)
这些属性中的每一个都是使用一些可选参数来定义的;例如,它们是否需要。
出于我们的目的,让我们创建一个User具有以下属性的模型:
- login(字符串):必需和主键
- password(字符串):必需
- email(电子邮件):可选
- birth_date(日期):可选
该User模型应如下所示:
class User(StructuredNode):
login = StringProperty(required=True, primary=True)
password = StringProperty(required=True)
email = EmailProperty()
birth_date = DateProperty()现在我们的模型已经存在,我们可以使用它来创建和检索节点,而无需编写任何 Cypher 查询。
创建节点
创建用户的最简单方法是创建User类的实例:
u = User(login="me", password="12345")要保存对象,或在 Neo4j 中创建它,您只需调用该save实例上的方法:
u.save()如果要改用MERGE语句,则必须使用稍微不同的方法:
users = User.get_or_create(
dict(
login="me",
password="<3Graphs",
email="[email protected]",
birth_date=date(2000, 1, 1),
),
)现在,继续往图表中添加更多用户。一旦我们在图表中有一些用户,我们就可以检索它们。
查询节点
如果要查看图中的所有节点,可以使用以下代码:
users = Users.nodes.all()这等效于以下内容:
MATCH (u:User) RETURN uusers是一个User对象列表。我们可以遍历它并打印用户属性:
for u in users:
print(u.login, u.email, u.birth_date)接下来,我们将看看过滤节点。
过滤节点
GOM 还允许您根据节点的属性过滤节点:
- User.nodes.get:这是指单个节点应符合要求的情况。如果没有找到节点,neomodel.core.UserDoesNotExist则会引发异常。
- User.nodes.filter:这是您期望多个节点满足要求的时候。与方法类似User.nodes.all(),该filter()方法返回一个列表User。
当它们的属性匹配时,可以过滤节点。例如,您可以使用以下内容过滤出生日期为 2000 年 1 月 1 日的所有用户:
users = User.nodes.filter(birth_date=date(2000, 1, 1))此语句的等效 Cypher 如下:
MATCH (u:User)
WHERE u.birth_date = "2000-01-01"
RETURN u但是,您也可以通过__
users = User.nodes.filter(birth_date__gt=date(2000, 1, 1))您现在可以从 Neo4j 创建(检查上一节)和检索节点。但是,GOM 并不止于此,它还允许您对节点之间的关系进行建模。
整合关系知识
首先,让我们创建另一个StructuredNode来表示存储库。在本练习中,存储库仅以其名称为特征,因此Repository该类仅包含一个属性:
class Repository(StructuredNode):
name = StringProperty()接下来,我们将neomodel介绍用户和存储库之间的关系。这样做是为了根据用户或存储库之间是否存在关系来过滤用户或存储库。
我们希望跟踪存储库所有权和存储库贡献。关于贡献,我们想知道用户何时对该存储库做出贡献。因此,我们将创建两种关系类型:OWNS和CONTRIBUTED_TO。
简单的关系
让我们从所有权关系开始。为了在我们的用户中实现它,我们需要添加以下行:
class User(StructuredNode):
# ... same as above
owned_repositories = RelationshipTo("Repository", "OWNS")这允许我们从用户那里查询存储库:
User.nodes.get(login="me").owned_repositories.all()
# [] 如果我们还需要以相反的方式执行操作——即从存储库到用户——我们还需要在Repository模型中添加相反的关系:
class Repository(StructuredNode):
# ... same as above
owner = RelationshipFrom(User, "OWNS")我们还可以从存储库中获取所有者:
Repository.nodes.get(name="hogan").owner.get()
# 该OWNS关系没有任何附加属性。如果我们想为关系添加属性,我们还必须为关系创建模型。
与属性的关系
对于贡献关系,我们想添加一个属性,当这些贡献发生时将保存关系;让我们称之为contribution_date。这也可以通过neomodel使用来实现StructuredRel:
class ContributedTo(StructuredRel):
contribution_date = DateTimeField(required=True)该类可用于在模型类中创建所需的关系:
class User(StructuredNode):
# ... same as above
contributed_repositories = RelationshipTo("Repository", "CONTRIBUTED_TO", model=ContributedTo)
class Repository(StructuredNode):
# ... same as above
contributors = RelationshipFrom(User, "CONTRIBUTED_TO", model=ContributedTo使用关系模型,我们可以使用该math方法按关系属性过滤模式。例如,以下查询返回hogan2020 年 5 月 5 日下午 3 点之后对存储库做出贡献的用户:
Repository.nodes.get().contributors.match(
contribution_date__gt=datetime(2020, 5, 31, 15, 0)
).all()上述代码等价于以下 Cypher 查询:
MATCH (u:User)-[r:CONTRIBUTED_TO]->(:Repository {name: "hogan"})
WITH u, DATETIME({epochSeconds: toInteger(r.contribution_date)}) as dt
WHERE dt >= DATETIME("2020-08-10T15:00:00")
RETURN u您现在可以使用neomodelNeo4j 图形来建模。
在下一节中,我们将使用我们在本节中创建的模型从 Neo4j 中检索数据,并通过使用Flask.
使用 Flask 和 neomodel 构建由 Neo4j 支持的 Web 应用程序
在本节中,我们将使用 Python 的流行 Web 框架之一,Flask以便使用neomodel我们之前创建的模型构建功能齐全的 Web 应用程序。
创建玩具数据
首先,让我们将前面的代码复制到一个models.py文件中。Packt GitHub 中的等效文件https://github.com/PacktPublishing/Hands-On-Graph-Analytics-with-Neo4j/blob/master/ch11/Flask-app/models.py包含一些额外的行。它们包含一些说明,我们可以使用这些说明来创建我们将在下一节中使用的示例数据。要执行它,只需从根目录运行以下命令:
python models.py创建的节点和关系如下图所示:
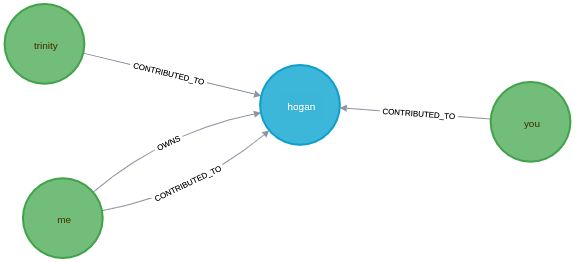
我们有一个名为 的存储库hogan,由名为 的用户拥有me。用户me也为此存储库做出了贡献。另外两个用户you和trinity也为同一个存储库做出了贡献。
让我们开始编写我们的第一个网页。
登录页面
首先,我们将在我们的应用程序中创建一个登录页面,以便我们可以对用户进行身份验证。为此,我们将依赖Flask-login包,例如,它将负责将用户数据保存在浏览器会话中。但是,我们仍然需要创建表单并将其链接到我们的User模型。
创建 Flask 应用程序
让我们继续在一个新app.py文件中创建 Flask 应用程序:
app = Flask(__name__)由于我们的应用程序将使用各种变量forms,POST我们需要添加跨站点请求伪造(CSRF)保护:
csrf = CSRFProtect(app)要使用该Flask-login插件,我们还需要定义一个SECRET变量并实例化登录管理器:
app.config['SECRET_KEY'] = "THE SECRET"
login_manager = Flask_login.LoginManager()
login_manager.init_app(app)这样,我们的Flask应用程序就创建好了,我们可以使用以下代码运行它:
Flask run但是,我们还没有创建任何路由,所以现在,我们所有的 URL 都会导致404, Not found错误。我们将/login在以下段落中添加路线。
调整模型
为了使用我们的User类Flask-login,我们需要向它添加一些方法:
- is_authenticated:判断用户认证是否成功。
- is_active:可用于停用用户(电子邮件地址未验证、订阅已过期等)。
- is_anonymous:这是检测未经身份验证的用户的另一种方法。
- get_id:定义每个用户的唯一标识符。
由于这些方法对几乎所有 Web 应用程序都是通用的,因此它们已在 a 中实现UserMixin,我们可以将其添加到我们的User类中以访问这些方法。我们需要自定义行为的唯一方法是get_id方法,因为我们的模型没有id字段;在这里,主键角色由login字段承担:
class User(StructuredNode, Flask_login.UserMixin):
# ... same as above
def get_id(self):
return self.login登录表单
为了管理表单渲染和验证,我们将使用另一个名为wtforms. 这个插件需要在一个专门的类中定义表单,所以让我们去创建一个登录表单。此表格需要以下内容:
- 用户名/登录名:这是一个必需的文本输入,可以使用以下行创建:
login = StringField('Login', validators=[DataRequired()])- 一个密码:这也是一个带有隐藏值的必需文本输入(我们不希望我们的邻居读取屏幕上的密码)。除了验证StringField器DataRequired之外,我们还将为此字段指定一个自定义小部件:
password = StringField('Password', validators=[DataRequired()],
widget=PasswordInput(hide_value=False)
)- 提交按钮:
submit = SubmitField('Submit')登录表单的完整代码如下:
class LoginForm(FlaskForm):
login = StringField('Login', validators=[DataRequired()])
password = StringField('Password', validators=[DataRequired()],
widget=PasswordInput(hide_value=False)
)
submit = SubmitField('Submit')让我们继续我们的实现并创建将呈现此表单的登录模板。
登录模板
在可通过/loginURL 访问的登录页面上,我们要显示登录表单;即登录和密码输入字段以及提交按钮。Flask 和许多 Web 框架一样,使用模板生成器,允许我们在页面上动态显示变量。Flask 使用的模板生成器称为Jinja2. 以下Jinja2模板允许我们显示一个简单的登录表单,其中包含两个文本输入(登录名和密码)和一个提交按钮:
templates/login.html在我们添加了基本的 HTML 标签后,可以将此模板添加到文件中(请参阅https://github.com/PacktPublishing/Hands-On-Graph-Analytics-with-Neo4j/blob/master/ch11/Flask-应用程序/模板/login.html)。你会注意到我使用了 Jinja2 的另一个有趣的特性:模板继承。该base.html模板包含跨页面的所有常量部分。在我们的例子中,我只包含了一个页眉,但您也可以放置页脚或导航侧边栏。它还包含一个空的block:
{% block content %}
{% endblock %}这个块可以看作是一个占位符,来自派生模板的代码将被写入其中。
在login.html模板中,我们告诉Jinja2它需要包含在基本模板中,指令如下:
{% extends "base.html" %}我们还Jinja2通过使用以下说明围绕我们的表单来告诉在基本模板中放置表单的位置:
{% block content %}
/// FORM GOES HERE
{% endblock %}在表单模板中,我们假设页面上下文包含一个由实例form组成的变量。LoginForm我们现在要将这个变量注入到上下文中,以便能够看到登录页面。
登录视图
所以,让我们创建一个简单的/login路由,将一个LoginForm实例添加到应用程序上下文中。然后,我们将渲染login.html模板:
login_manager.login_view = 'login'
@app.route('/login') # URL
def login(): # name of the view
form = LoginForm() # create a LoginForm instance
return render_template('login.html', form=form) # render the login.html template with a form parameter现在,您可以导航到http://localhost:5000/login。您应该看到以下表格:
但是,目前,单击表单会引发错误POST,因为默认情况下,我们的视图不允许请求。为了让它们被允许,我们必须修改app.route我们视图上的装饰器,以便我们可以添加允许的方法:
@app.route('/login', methods=["GET", "POST"])
def login():现在我们可以对这个视图进行 POST,我们可以处理它们了。以下是我们将遵循的步骤:
- 使用方法验证表单数据form.validate_on_submit()。此方法执行以下检查:
- 检查必填字段是否存在:这是由字段验证器配置的。
- 检查提供的登录名/密码是否对应于真实用户:在这里,我们需要实现自己的逻辑,以检查User具有给定登录名/密码的节点是否存在于 Neo4j 中。
- 执行此操作后,可能会出现两种可能的情况:
- 如果表单有效且用户存在,则调用该Flask_login.login_user函数管理会话。
- 否则,再次呈现登录表单。
这些操作是通过以下代码在视图中执行的:
form = LoginForm()
if form.validate_on_submit():
if Flask_login.login_user(user):
return redirect(url_for("index")) # redirect to the home page
return render_template('login.html', form=form)为了User使用给定的凭据检查 a 的存在,我们需要在validate表单中添加一个方法:
class LoginForm(FlaskForm):
# ... same as before
def validate(self):
user = User.nodes.get_or_none(
login=self.login.data,
password=self.password.data,
)
if user is None:
raise ValidationError("User/Password incorrect")
self.user = user
return self为方便起见,经过身份验证的用户保存在self.user表单属性中。这允许我们在登录视图中检索用户,而无需再次执行相同的请求。
读取数据——列出拥有的存储库
你可以自己试试这个。结果显示在以下段落中。
视图将使用current_user保存的对象Flask_login。这个当前用户已经是该User类型,所以我们可以直接访问它的成员,例如contributed_repositoriesand owned_repositories。视图的完整代码如下:
@app.route('/')
@Flask_login.login_required
def index(*args):
user = Flask_login.current_user
contributed_repositories = user.contributed_repositories.all()
owned_repositories = user.owned_repositories.all()
return render_template(
"index.html",
contributed_repositories=contributed_repositories,
owned_repositories=owned_repositories,
user=user
)您可能已经注意到使用了一个新的函数装饰器,@Flask_login.login_required. 这将在渲染视图之前检查用户是否已经登录。如果没有,用户将被重定向到登录视图。
在 HTML 模板中,我们将简单地遍历贡献和拥有的存储库,以便在项目符号列表中显示它们:
User {{ user.login }}
List of repositories I contributed to:
{% for r in contributed_repositories %}
- {{ r.id }}: {{ r.name }} (on {{ user.contributed_repositories.relationship(r).contribution_date.strftime('%Y-%m-%d %H:%M') }})
{% endfor %}
List of repositories I own:
{% for r in owned_repositories %}
- {{ r.id }}: {{ r.name }}
{% endfor %}
以下屏幕截图显示了运行上述代码段后存储库列表的外观:

在本小节中,我们从图中读取了数据。现在,让我们学习如何向其中添加数据。
改变图表——添加贡献
在本练习中,我们将让经过身份验证的用户向现有存储库添加贡献。同样,我们将使用 WTForm Flask 扩展来管理 HTML 表单。我们的表单比登录表单更简单,因为它只包含一个文本输入:用户贡献的存储库的名称:
from models import Repository
class NewContributionForm(FlaskForm):
name = StringField('Name', validators=[DataRequired()])
submit = SubmitField('Submit')验证提供的存储库名称以确保Repository具有该名称的节点已经存在,ValidationError否则引发:
def validate_name(self, field):
r = Repository.nodes.get_or_none(name=field.data)
if r is None:
raise ValidationError('Can ony add contributions to existing repositories')现在,让我们构建将呈现此表单的模板。这个模板应该不会让您感到惊讶,因为它与登录页面模板非常相似:
让我们向这个页面添加另一条信息:表单报告的验证错误。我们这样做是为了让用户知道发生了什么。这可以通过以下代码来实现。这段代码需要
{% for field, errors in form.errors.items() %}
{{ form[field].label }}: {{ ', '.join(errors) }}
{% endfor %} 我们还需要从索引页面添加一个指向我们新页面的链接。在贡献列表的末尾,添加以下项目:
Add a new contribution 现在,让我们专注于视图。用户登录并验证表单后,我们可以找到与用户输入的名称匹配的存储库,并将此存储库添加到contributed_repositories已验证用户的部分:
@app.route("/repository/contribution/new", methods=["GET", "POST"])
@Flask_login.login_required
def add_contribution(*args):
user = Flask_login.current_user
form = NewContributionForm()
if form.validate_on_submit():
repo = Repository.nodes.get(
name=form.name.data,
)
rel = user.contributed_repositories.connect(repo, {"contribution_date": datetime.now()})
return redirect(url_for("index"))
return render_template("contribution_add.html", form=form)现在,您可以导航到http://www.localhost:5000/repository/contribution/new。您将看到类似于以下内容的内容: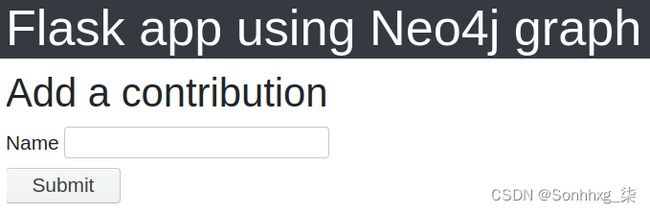
有了这个,我们构建了一个使用 Neo4j 作为后端的 Web 应用程序。我们能够从 Neo4j(登录和索引页面)读取数据并在图中创建新关系。本节的完整代码可在/Flask-app. 这个目录包含一个额外的视图,允许用户创建一个新的存储库。我建议您在查看代码之前尝试自己实现它。
这是使用 Python 与 Neo4j 交互的一种方式。可以使用另一个名为 Django 的流行 Web 框架重复相同的练习。您可以查看进一步阅读部分以查找neomodel和Django集成的参考。
在本章的其余部分,我们将使用另一种方式将应用程序与 Neo4j 连接——通过构建 GraphQL API。但是,首先,我们将通过使用 GitHub API v4 更加熟悉 GraphQL。
通过示例了解 GraphQL API – GitHub API v4
虽然在上一节中我们使用 Python 构建了一个后端数据库为 Neo4j 的完整 Web 应用程序,但在本节中,我们将移除对 Python 的依赖,并构建一个可从 Neo4j 服务器直接访问的 API。
在构建 API 时,一个非常流行的框架是Representational State Transfer ( REST )。尽管这种方法仍然适用于图形数据库(例如,检查gREST项目),但另一种方法正变得越来越流行——GraphQL,一种 API 查询语言。
为了理解 GraphQL,我们将再次使用 GitHub API。在前面的章节中,我们使用了REST版本 (v3)。但是,v4 使用 GraphQL,所以我们应该构建一些查询。为此,我们可以访问Explorer - GitHub Docs,这是传统的 GraphQL 游乐场。提供 GitHub 登录凭据后,有一个由两部分组成的窗口;左侧面板是我们编写查询的地方,而右侧面板将显示查询结果或错误消息。
为了开始使用未知的 GraphQL API,< Doc按钮(屏幕右上角-请参见以下屏幕截图)是关键。它将列出可用的操作,用于查询数据库和执行突变(创建、更新或删除对象)。让我们从读取query部件的数据开始:
前面的屏幕截图是您第一次导航到 GitHub GraphQL API 时将看到的内容。它预先填充了一个示例查询。我们将在以下部分对此进行分析。
端点
让我们从构建一个查询开始。我们将通过选择一个端点来做到这一点。其中一个被调用viewer,根据文档,它将为我们提供有关当前经过身份验证的用户的信息。要使用此端点,我们必须在查询构建器中编写以下内容:
{
viewer {
}
}如果我们尝试运行此查询,它将返回解析错误消息。原因是我们仍然缺少一条重要的信息——我们希望 API 返回的查看器的参数。
有一个可选的查询关键字可以放在查询请求的前面,如下所示:
query {
viewer {
}
}返回的属性
GraphQL 的优点之一是您可以选择返回哪些参数。这是减少从 API 接收的数据大小并加快数据呈现给用户的好方法。可用参数列表在 GraphQL 模式中定义;我们将在本章后面更详细地讨论这一点。一个有效的查询可以这样写:
{
viewer {
id
login
}
}此查询将返回查看者的id和login信息。此查询的结果是以下 JSON:
{
"data": {
"viewer": {
"id": "MDQ6VXNlcjEwMzU2NjE4",
"login": "stellasia"
}
}
}这个查询非常简单,尤其是因为它不涉及参数。但是,大多数时候,API 响应取决于一些参数:用户 ID、要返回的最大元素数(用于分页)等等。值得关注此功能,因为任何 API 都能够发送参数化请求至关重要。
查询参数
为了了解查询参数的工作原理,让我们考虑另一个端点,organization. 通过 GitHub API,假设您发送以下查询:
{
organization(login) {
id
}
}您将收到一条错误消息作为回报:
"message": "Field 'organization' is missing required arguments: login"这意味着查询必须更新为以下内容:
{
organization(login: "neo4j") {
id
}
}通过请求更多字段,例如创建日期或组织的网站,生成的数据将类似于以下内容:
{
"data": {
"organization": {
"name": "Neo4j",
"description": "",
"createdAt": "2010-02-10T15:22:20Z",
"url": "https://github.com/neo4j",
"websiteUrl": "http://neo4j.com/"
}
}
}可以构建更复杂的查询;只需浏览文档以查看可以提取哪些信息。例如,我们可以构建一个返回以下内容的查询:
- 当前查看者的登录名。
- 他们的前两个公共存储库,按创建日期降序排列,以及每个存储库的以下内容:
- 其名称
- 它的创建日期
- 其主要语言名称:
{
organization(login: "neo4j") {
repositories(last: 3, privacy: PUBLIC, orderBy: {field: CREATED_AT, direction: ASC}) {
nodes {
name
createdAt
primaryLanguage {
name
}
}
}
}
}结果显示在以下屏幕截图中: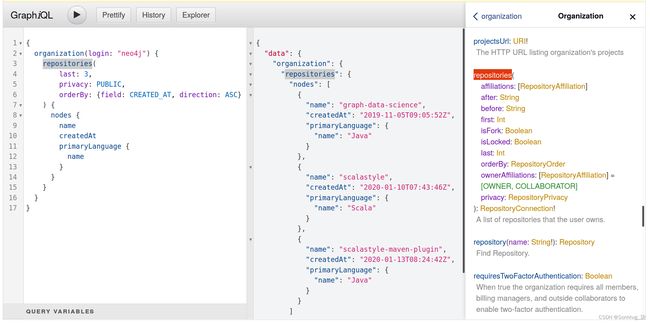
查询用于从数据库中检索数据。为了改变数据,我们需要执行另一种称为突变的操作。
Mutations
让我们研究一个 GitHub API 允许的突变示例:将星号添加到存储库。调用此突变addStar并接受单个input参数:要加星标的存储库 ID。它可以返回Starrable类型的信息(根据文档,“可以加星标的事物”)。完整的查询编写如下:
mutation {
addStar(input: {starrableId: ""}) {
starrable {
stargazers(last: 1) {
nodes {
login
}
}
}
}
} 与查询类似,每个突变的参数和返回参数都在 GraphQL 模式中定义,其文档可通过 GraphQL 游乐场的右侧面板访问。
我们将在下一节看到更多突变的例子。
Neo4j GraphQL JavaScript 包是 GRANDstack 的一部分,我们将在下一节中介绍。
使用 GRANDstack 开发 React 应用程序
如果您现在使用 Neo4j 创建应用程序,那么 GRANDstack 是最好的选择。在本节中,我们将构建一个与本章第一节中使用 Python 创建的应用程序类似的小型应用程序。
GRANDstack 的完整文档可以在Open Source GraphQL Library | Open GraphQL API Library | Neo4j找到。
GRANDstack – GraphQL、React、Apollo 和 Neo4j 数据库
GRAND 实际上是以下内容的首字母缩写词:
- GraphQL
- React
- Apollo
- Neo4j Database
我们在整本书中探索了 Neo4j,在上一节中探索了 GraphQL。React 是一个用于构建 Web 应用程序的 JavaScript 框架。Apollo 是将 GraphQL API 和 React 前端粘合在一起的块。让我们看看这些东西是如何工作的。
为了使用 GRANDstack 启动项目,我们可以使用以下代码:
npx create-grandstack-app 该脚本将询问我们的 Neo4j 连接参数(bolt URL、用户名、密码以及是否使用加密)并使用我们的应用程序名称创建一个目录。除其他外,这将包含以下元素:
.
├── api
├── LICENSE.txt
├── package.json
├── README.md
└── web-react顾名思义,该api文件夹包含 GraphQL API 的代码,而该web-react文件夹是前端 React 应用程序所在的位置。
创建 API
入门应用程序已经为我们完成了几乎所有的工作。该api文件夹的结构如下:
.
├── package.json
├── README.md
└── src
├── functions
├── graphql-schema.js
├── index.js
├── initialize.js
├── schema.graphql
└── seed我们需要修改以满足我们的应用程序目标的唯一文件是该schema.graphql文件。
编写 GraphQL 架构
仍然在用户拥有或贡献存储库的上下文中,我们将编写 GraphQL 模式,该模式将用于创建我们在本章第一部分创建的相同前端页面。
定义类型
让我们从User节点开始。我们可以使用以下代码定义属性:
type User {
login: String!
password: String!
email: String
birth_date: Date
}我们还可以向用户添加更多数据,例如:
- 他们拥有的存储库:
owned_repositories: [Repository] @relation(name: "OWNS", direction: "OUT")- 他们贡献的存储库:
contributed_repositories: [Repository] @relation(name: "CONTRIBUTED_TO", direction: "OUT"- 他们的贡献总数(对所有存储库)。在这里,我们必须从自定义 Cypher 语句中定义这个字段来编写COUNT聚合:
total_contributions: Int
@cypher(
statement: "MATCH (this)-[r:CONTRIBUTED_TO]->(:Repository) RETURN COUNT(r)"
)同样,可以使用以下模式描述存储库:
type Repository {
name: String!
owner: User @relation(name: "OWNS", direction: "IN")
contributors: [User] @relation(name: "CONTRIBUTED_TO", direction: "IN")
nb_contributors: Int @cypher(
statement: "MATCH (this)<-[:CONTRIBUTED_TO]->(u:User) RETURN COUNT(DISTINCT u)"
)
}您可以添加您认为应用程序所需的任意数量的字段。
启动应用程序
启动应用程序就像执行以下操作一样简单:
cd api
npm run默认情况下,应用程序在 port 上运行4001。现在,我们将研究两种测试一切是否按预期工作的方法;即,GraphQL 游乐场和向 API 发送直接请求。
使用 GraphQL 操场进行测试
当应用程序运行时,我们可以访问http://www.localhost:4001/graphql/并找到该应用程序的 GraphQL 游乐场。
"editor.theme": "dark",
更改为以下内容:
"editor.theme": "light",
让我们编写一个查询来收集创建应用程序登录页面所需的信息(请参阅创建 Flask 应用程序部分)。我们希望为经过身份验证的用户显示他们的登录名、他们拥有的存储库以及他们贡献的存储库。因此,我们可以使用以下查询:
{
User(login: "me") {
login
owned_repositories{
name
}
contributed_repositories{
name
}
}
}同样,要获取给定存储库的贡献者数量和所有者,请使用以下查询:
{
Repository(name: "hogan") {
nb_contributors
owner {
login
}
}
}API 现在完全启动并运行,您可以从您最喜欢的工具(curl、Postman 等)向它发送请求。在下一节中,我将演示如何使用该requests模块从 Python 查询此 API。
从 Python 调用 API
为了从 Python 发出 HTTP 请求,我们将使用 pip 可安装requests包:
import requests然后,我们需要定义请求参数:
query = """
{
User(login: "me") {
login
}
}
"""
data = {
"query": query,
}最后,我们可以使用 JSON 编码的有效负载发布请求:
r = requests.post(
"http://localhost:4001/graphql",
json=data,
headers={
}
)
print(r.json())结果如下:
{'data': {}}使用变量
我们使用的查询包含一个参数:用户名。为了使其更加可定制,GraphQL 允许我们使用变量。首先,我们需要通过添加参数定义来稍微改变我们格式化查询的方式:
query($login: String!) {该参数称为$name,属于String类型,并且是必需的(因此是最后的感叹号!)。然后可以在查询中使用此声明的参数,如下所示:
User(login: $login) {因此,最终查询如下所示:
query = """
query($login: String!) {
User(login: $login) {
login
}
}
"""但是,我们现在必须将参数提供给 API 调用中的查询。这是使用variables参数完成的。它由一个字典组成,其键是参数名称:
data = {
"query": query,
"variables": {"login": "me"},
}完成此操作后,我们可以requests.post使用之前使用的相同代码再次发布此查询。
现在,让我们学习如何使用 React 构建一个使用 GraphQL API 的前端应用程序。
Mutations
正如我们已经在 GitHub API 中看到的那样,突变会改变图形,从而创建、更新或删除节点和关系。一些突变是从 GraphQL 模式中声明的类型自动创建的;它们可以在以下文档中找到: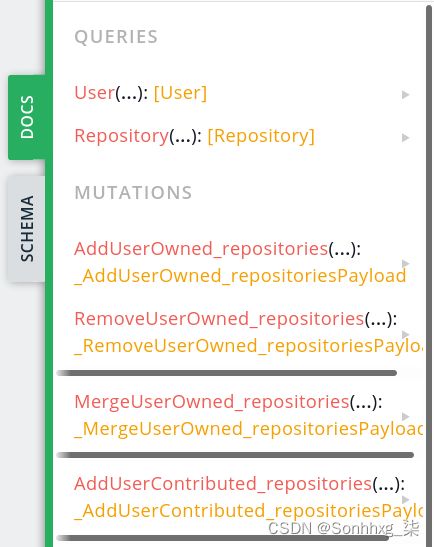
让我们创建一个新用户并向 hogan 存储库添加一个贡献。要创建用户,我们需要使用CreateUser突变,参数至少包含两个强制参数:登录名和密码。对于任何 GraphQL 查询,我们还需要在请求的第二部分列出我们希望 API 返回的参数:
mutation {
CreateUser(login: "Incognito", password: "password123") {
login
email
birth_date {year}
}
}我们还可以创建新创建的用户和 hogan 存储库之间的关系:
mutation {
AddUserContributed_repositories(
from: { login: "Incognito" }
to: { name: "hogan" }
) {
from {login}
to {name}
}
}我们可以在 Neo4j 浏览器中检查结果,或者使用相同的 GraphQL API 来检查User节点和CONTRIBUTED_TO关系是否正确创建:
{
User(login: "Incognito") {
contributed_repositories {
name
}
}
}这应该会产生以下输出:
{
"data": {
"User": [
{
"contributed_repositories": [
{
"name": "hogan"
}
]
}
]
}
}创建新存储库时,我们可能希望将其所有者添加到同一查询中。这可以通过链接突变使用 GraphQL 来实现:
mutation {
CreateRepository(name: "graphql-api") {
name
}
AddUserOwned_repositories(
from: { login: "Incognito" }
to: { name: "graphql-api" }
) {
from {
login
email
total_contributions
}
to {
name
nb_contributors
}
}
}在前面的查询中,首先,我们CreateRepository通过添加存储库来执行突变graphql-api。然后,执行AddUserOwned_repositories突变。Incognito我们通过在我们之前创建的用户和新创建的存储库之间添加关系来做到这一点graphql-api。
您现在应该能够构建自己的 GraphQL API 并查询它以获取和更改图中的数据。下一步是将此 API 插入前端应用程序。
构建用户界面
UI 正在使用 React。该应用程序附带的代码grand-stack-starter包含许多功能,但对于初学者来说也相当复杂,这就是为什么我们将使用更简单的方法重写它的一部分。我们的目标是构建一个在主页上显示用户列表的应用程序。
为了让我们的组件使用 API,我们必须将它们连接到我们在上一节中创建的 GraphQL 应用程序。
创建一个简单的组件
让我们首先构建主页并创建一个列出所有用户的组件。
从 GraphQL API 获取数据
为了检索所有注册用户,我们将使用查询所有用户而不使用任何参数,如下所示:
query Users {
User {
login
email
total_contributions
}
}这可以在 GraphQL 操场上进行测试,以检查它是否返回 Neo4j 图中的所有用户。
https ://github.com/grand-stack/grand-stack-starter/blob/master/web-react/src/components/UserList.js 。
编写一个简单的组件
该UserList组件将在src/components/UserList.js文件中实现。我们首先导入必要的工具:
import { useQuery } from '@apollo/react-hooks'
import gql from 'graphql-tag'然后,我们定义我们需要用来检索该组件所需数据的查询:
const GET_USERS = gql`
query Users {
User {
login
email
total_contributions
}
}在此之后,我们可以使用函数表示法创建组件。该函数必须返回将在浏览器中显示的 HTML 代码。
然而,在此之前,我们需要获取数据。这是useQuery使用 Apollo 的功能的地方。让我们从一个简单的实现开始,我们将useQuery在控制台中记录函数的结果并返回一个空字符串作为 HTML:
function UserList(props) {
const { loading, data, error } = useQuery(GET_USERS);
console.log("Loading=", loading);
console.log("Data=", data);
console.log("Error=", error);
return "";
};
export default UserList;我们还需要创建src/App.js文件才能使用该UserList组件。确保它包含以下内容:
import React from 'react'
import UserList from './components/UserList';
export default function App() {
return (
My app
保存这两个文件后,我们可以通过npm start在web-react文件夹中运行并访问http://localhost:3000来启动服务器。HTML 没有显示任何内容,但有趣的信息在控制台中,您可以使用Ctrl + I或按F12键(Firefox 和 Chrome)打开它。您应该会看到类似于以下内容的内容:
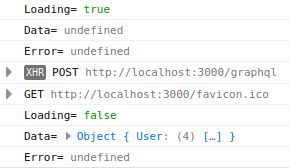
如您所见,我们的日志显示了两次。第一次发生这种情况时,loading参数为真,并且变量data和error变量都未定义。第二次发生这种情况时,会收到我们的 GraphQL API 执行的 POST 请求的结果。这一次,我们有loading=false,并且data实际上包含了一些数据。
data可以进一步探索该对象。您将看到类似于以下内容的内容:

所以,让我们修改我们的UserList函数,用一些有意义的数据替换空字符串返回语句。
我们必须考虑三种情况:
- 如果我们还没有来自 API 的数据,那么loading=true. 在这种情况下,我们将只渲染Loading...文本:
if (loading) {
return Loading...
}- API 返回了一些错误,error !== undefined. 在这里,我们将显示原始错误消息:
if (error !== undefined) {
console.error(error);
return Error
}- API 没有返回和错误,我们收到了一些数据。在这种情况下,我们将遍历data.User数组并显示其登录名、电子邮件以及每个元素的贡献总数。
最后一步是通过以下代码实现的:
return (
Login
Email
Total contributions
{data.User.map((u) => {
return (
{u.login}
{u.email}
{u.total_contributions}
)
})}
)保存新版本后UserList.js,再次访问http://localhost:3000将显示 Neo4j 中现有用户的表格。
- Neo4j
- 上一节的 API
- 应用web-react程序
现在,让我们为导航添加一些复杂性。这将使我们能够在单击用户登录时查看有关用户的更多信息。
添加导航
从列出所有用户的主页中,如果能够导航到另一个显示特定用户详细信息的页面,那就太好了。为了使这成为可能,让我们首先修改UserList组件并为用户登录添加一个链接:
{u.login} 现在,点击这样的链接会将我们重定向到http://localhost:3000/user/me. 这只是显示一个空白页面,因为我们的应用程序尚未配置。
让我们继续配置应用程序。组件的内容App必须替换为以下代码。我们将使用一个Router对象来做到这一点:
export default function App() {
return (
My app
);路由器定义了两条路由:
- "/":这将渲染UserList组件。
- "/user/
":这将渲染一个新User组件(我们现在要创建它)。登录是路由的一个参数,我们将能够在组件中检索它。
所以,让我们User在src/components/User.js; 这将显示用户拥有的存储库列表。获取此数据的查询如下:
const GET_USER_DATA = gql`
query($login: String!) {
User(login: $login) {
owned_repositories {
name
}
}
}
`;在此查询中,我们定义了一个$login变量,我们必须将其与查询一起提供给 GraphQL 端点,以获得结果。组件的开头User如下:
function User(props) {
let login = props.match.params.login
const { loading, data, error } = useQuery(GET_USER_DATA, {
variables: {
login: login
}
});login 变量是从 URL 中读取的,因为用户页面的 URL 是/user/
该User组件的其余部分非常简单。我们添加加载和错误处理,然后显示存储库列表:
if (loading) {
return Loading...
}
if (error !== undefined) {
return Error: {error}
}
let user = data.User[0];
return (
{user.owned_repositories.map((r) => {
return (
- {r.name}
)
})}
)
};
export default User;现在,导航到http://localhost:3000/user/meme将显示登录用户拥有的存储库列表。
以下小节将向我们展示编写完全可用的应用程序所需的缺失部分:mutations。
Mutation
为简单起见,我们将在新组件和新 URL 中实现此突变。
所以,首先,让我们在路由器中添加一个指向这个新页面的链接(in src/App.js):
我们还需要通过在组件的存储库列表末尾添加指向我们新页面的链接来增加用户访问该页面的可能性User( src/components/User.js):
Add new repository 然后,我们可以AddRepository在src/components/AddRepository.js. 首先,让我们根据 GraphQL 来定义突变:
const CREATE_REPO = gql`
mutation($name: String!, $login: String!) {
CreateRepository(name: $name) {
name
}
AddRepositoryOwner(from: { login: $login }, to: { name: $name }) {
from {
login
}
to {
name
}
}
}
`;与我们对查询所做的类似,我们将创建一个包含两个变量的突变:用户登录名和新的存储库名称。
以下任务包括使用以下代码创建一个突变对象:
import { useMutation } from '@apollo/react-hooks';
const [mutation, ] = useMutation(CREATE_REPO);创建突变后,我们可以在提交表单时在回调中使用它onFormSubmit:
function AddRepository(props) {
let login = props.match.params.login;
const [mutation, ] = useMutation(CREATE_REPO);
const onFormSubmit = function(e) {
e.preventDefault();
mutation({variables: {
login: login,
name: e.target.name.value,
}
});
props.history.push(`/user/${login}`);
};
return (
)
}
export default AddRepository;回调包含一个额外的onFormSubmit行,以便在操作完成后将用户重定向到主用户页面:
props.history.push(`/user/${login}`);如果我们现在运行此代码,我们将看到表单已正确提交,但其中的存储库列表/user/
突变后刷新数据
为了刷新受突变影响的查询,我们需要使用函数的refreshQueries参数mutate,如下:
import {GET_USER_DATA} from './User';
// .....
mutation({
variables: {
login: login,
name: e.target.name.value
},
refetchQueries: [ { query: GET_USER_DATA, variables: {login: login} }],
});现在,如果我们尝试添加一个新的存储库,我们将看到它出现在用户拥有的存储库列表中。
您现在应该能够使用 GraphQL 查询从 Neo4j 读取数据,并使用突变将数据插入到图中。
概括
在本章中,我们讨论了如何使用 Neo4j 作为主数据库构建 Web 应用程序。您现在应该能够使用 Python、它的包和框架构建一个由 Neo4j 支持的 Web 应用程序,以构建一个全栈 Web 应用程序(后端和前端);GraphQL,用 Neo4j 构建一个 API,可以插入到任何现有的前端;或 GRANDstack,它允许您创建一个前端应用程序,以使用 GraphQL API 从 Neo4j 检索数据。 neomodel Flask
尽管我们已经专门讨论了用户和存储库的概念,但这些知识可以很容易地扩展到任何其他类型的对象和关系;例如,存储库可以成为产品、电影或用户编写的帖子。如果您已经使用链接预测算法构建了关注者推荐引擎,就像我们在第 9 章预测 关系中所做的那样,您可以使用您在本章中获得的知识来显示推荐用户列表以关注。