GhostNet学习笔记 --- GhostNet: More Features from Cheap Operations
GhostNet: More Features from Cheap Operations
论文地址:https://arxiv.org/abs/1911.11907
Github开源地址:https://github.com/huawei-noah/ghostnet
GhostNet是华为诺亚方舟实验室新发表的一篇论文,收录于CVPR2020。
它的核心思想就是:用更少的参数来生成更多特征。
其中Ghostnet的核心模块是Ghost模块,与普通卷积神经网络相比,在不更改输出特征图大小的情况下,其所需的参数总数和计算复杂度均已降低,而且即插即用。
通产情况下,为了对输入数据有更好的理解,使用普通卷积训练的神经网络,在训练完成后会生成很多冗余的特征图,
如下图Resnet50所示,经过第一个残差块处理后的特征图,会有出现很多相似的“特征图对”——它们用相同颜色的框注释。
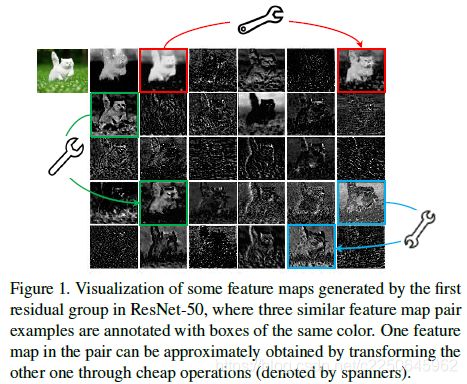
这样的操作,虽然能获得很好的性能,但是却需要驱动大量的卷积层计算,耗费大量的计算资源。
相比于谷歌的mobilenet,旷视的shufflenet思想,它们的深度卷积或者混洗的操作,都是在卷积上下功夫,通过小卷积核(浮点运算)实现。
华为另辟蹊径:
特征图对”中的一个特征图,可以通过廉价操作(上图中的扳手)将另一特征图变换而获得,则可以认为其中一个特征图是另一个的“幻影”。
那么,并非所有特征图都要用卷积操作来得到。“幻影”特征图,也可以用更廉价的操作来生成。
于是就有了GhostNet的基础——Ghost模块,用更少的参数,生成与普通卷积层相同数量的特征图,其需要的算力资源,要比普通卷积层要低,集成到现有设计好的神经网络结构中,则能够降低计算成本。
Ghost模块和普通卷积模块区别如下:
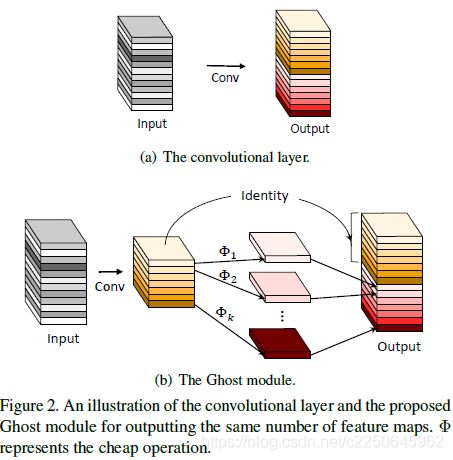
利用Ghost模块的优势,研究团队提出了一个专门为小型CNN设计的Ghost bottleneck(G-bneck)。其架构如下图所示,与ResNet中的基本残差块(Basic Residual Block)类似,集成了多个卷积层和shortcut。
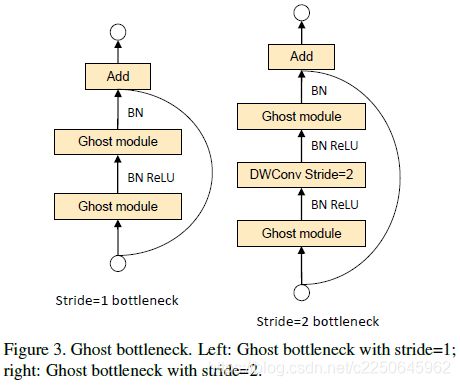
Ghost bottleneck主要由两个堆叠的Ghost模块组成。第一个用作扩展层,增加了通道数。第二个用于减少通道数,以与shortcut路径匹配。然后,使用shortcut连接这两个Ghost模块的输入和输出。
这里说的Ghost bottleneck,适用于上图Stride= 1情况。对于Stride = 2的情况,shortcut路径由下采样层和Stride = 2的深度卷积(Depthwise Convolution)来实现。
在Ghost bottleneck的基础上,研究团队提出了GhostNet——遵循MobileNetV3的基本体系结构的优势,用Ghost bottleneck替换MobileNetV3中的bottleneck。
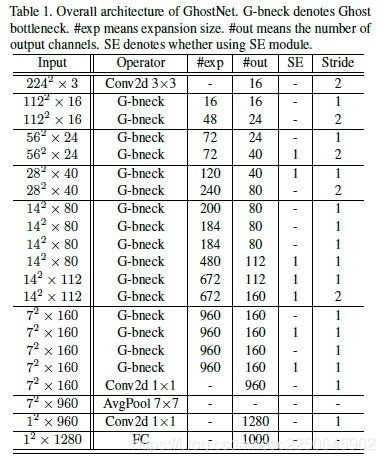
第一层是具有16个卷积核的标准卷积层,然后是一系列Ghost bottleneck,通道逐渐增加。
Ghost bottleneck根据输入特征图的大小分为不同的阶段,除了每个阶段的最后一个Ghost bottleneck是Stride = 2,其他所有Ghost bottleneck都以Stride = 1进行应用。
最后,会利用全局平均池和卷积层将特征图转换为1280维特征向量以进行最终分类。SE模块也用在了某些Ghost bottleneck中的残留层。与MobileNetV3相比,这里用ReLU换掉了Hard-swish激活函数。
实验性能
在CIFAR-10数据集上,他们将Ghost模块用在VGG-16和ResNet-56架构中,与几个代表性的最新模型进行了比较。
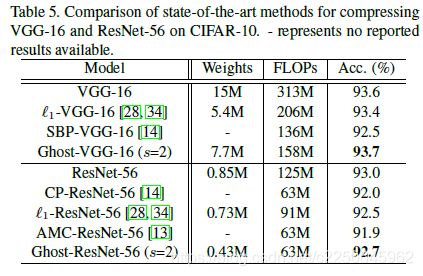
Ghost-VGG-16 ( s=2)以最高的性能(93.7%)胜过竞争对手,但算力消耗(FLOPs)明显减少。在比VGG-16小得多的ResNet-56上,基于Ghost模块的模型,将计算量降低一半,还能获得可比的精度。
研究团队在论文中提供了Ghost模块生成的特征图。下图展示了Ghost-VGG-16的第二层特征,左上方的图像是输入,左红色框中的特征图来自初始卷积,而右绿色框中的特征图是经过廉价深度变换后的幻影特征图。

研究团队表示,尽管生成的特征图来自原始特征图,但它们之间确实存在显着差异,这意味着生成的特征足够灵活,可以满足特定任务的需求。
下图展示了GhostNet与现有最优秀的几种小型网络结构的对比,参赛选手包括MobileNet系列、ShuffleNet系列、ProxylessNAS、FBNet、MnasNet等。
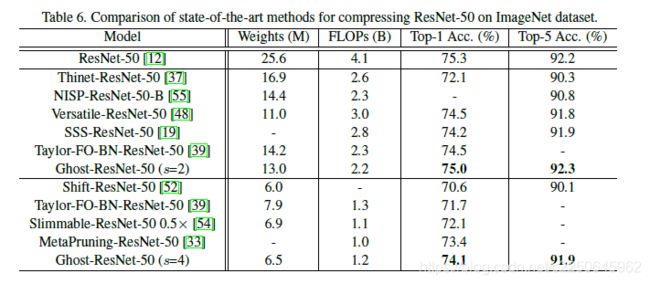
GhostNet在各种计算复杂度级别上始终优于其他竞争对手。
参考:
http://3g.163.com/news/article_cambrian/F6I7LU2K0511DSSR.html