P8-P9:Tensorboard的使用(Pytorch小土堆学习笔记)
安装直接在terminal上安装就行,注意要进入pytorch环境(用conda activate pytorch来激活)
首先说包,这个包是将内容告诉给tensorboard,并让它展示的
from torch.utils.tensorboard import SummaryWritersummarywriter部分关键注解
Help on class SummaryWriter in module torch.utils.tensorboard.writer:
class SummaryWriter(builtins.object)
| SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
|
| Writes entries directly to event files in the log_dir to be
| consumed by TensorBoard.
|
| The `SummaryWriter` class provides a high-level API to create an event file
| in a given directory and add summaries and events to it. The class updates the
| file contents asynchronously. This allows a training program to call methods
| to add data to the file directly from the training loop, without slowing down
| training.
|
| Methods defined here:
|
| __enter__(self)
|
| __exit__(self, exc_type, exc_val, exc_tb)
|
| __init__(self, log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
| Creates a `SummaryWriter` that will write out events and summaries
| to the event file.
|
| Args:
| log_dir (string): Save directory location. Default is
| runs/**CURRENT_DATETIME_HOSTNAME**, which changes after each run.
| Use hierarchical folder structure to compare
| between runs easily. e.g. pass in 'runs/exp1', 'runs/exp2', etc.
| for each new experiment to compare across them.
| comment (string): Comment log_dir suffix appended to the default
| ``log_dir``. If ``log_dir`` is assigned, this argument has no effect.
| purge_step (int):
| When logging crashes at step :math:`T+X` and restarts at step :math:`T`,
| any events whose global_step larger or equal to :math:`T` will be
| purged and hidden from TensorBoard.
| Note that crashed and resumed experiments should have the same ``log_dir``.
| max_queue (int): Size of the queue for pending events and
| summaries before one of the 'add' calls forces a flush to disk.
| Default is ten items.
| flush_secs (int): How often, in seconds, to flush the
| pending events and summaries to disk. Default is every two minutes.
| filename_suffix (string): Suffix added to all event filenames in
| the log_dir directory. More details on filename construction in
| tensorboard.summary.writer.event_file_writer.EventFileWriter.
|
| Examples::
|
| from torch.utils.tensorboard import SummaryWriter
|
| # create a summary writer with automatically generated folder name.
| writer = SummaryWriter()
| # folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
|
| # create a summary writer using the specified folder name.
| writer = SummaryWriter("my_experiment")
| # folder location: my_experiment
|
| # create a summary writer with comment appended.
| writer = SummaryWriter(comment="LR_0.1_BATCH_16")
| # folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
|
|
解释:它是一个向 log_dir写入的事件文件,这个文件可以被tensorboard解析。需要输入一个文件夹的名称,不输入的话默认文件夹为runs/**CURRENT_DATETIME_HOSTNAME**。其他的参数当前并不重要,需要的话可以自己看看。
使用的基本套路:
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter(logs)
writer.add_scalar()
writer.add_image()
writer.close()先说第一个add_scalar
这个是add_scalar的相关文档说明,主要注意一下前三个参数(标题,y轴,x轴)
add_scalars(self, main_tag, tag_scalar_dict, global_step=None, walltime=None)
| Adds many scalar data to summary.
|
| Args:
| main_tag (string): The parent name for the tags
| tag_scalar_dict (dict): Key-value pair storing the tag and corresponding values
| global_step (int): Global step value to record
| walltime (float): Optional override default walltime (time.time())
| seconds after epoch of event
|
| Examples::
|
| from torch.utils.tensorboard import SummaryWriter
| writer = SummaryWriter()
| r = 5
| for i in range(100):
| writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
| 'xcosx':i*np.cos(i/r),
| 'tanx': np.tan(i/r)}, i)
| writer.close()
| # This call adds three values to the same scalar plot with the tag
| # 'run_14h' in TensorBoard's scalar section.
|
| Expected result:
|
| .. image:: _static/img/tensorboard/add_scalars.png
| :scale: 50 %
练手代码:
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()然后点击运行,打开下面的这个并找到上面代码所在的文件夹(通过cd命令)
然后按照下图输入命令行(第一行和第三行)

tensorboard --logdir=y=2x --port=6007 #换端口然后复制网址在网页中打开
如果出现这种情况应该是你的文件名没有搞对,可以检查一下文件夹是否创建以及文件夹里面有没有文件(太多文件有的时候也会影响)
再说第二个 add_image
文档说明:
add_images(self, tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')
| Add batched image data to summary.
|
| Note that this requires the ``pillow`` package.
|
| Args:
| tag (string): Data identifier
| img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data
| global_step (int): Global step value to record
| walltime (float): Optional override default walltime (time.time())
| seconds after epoch of event
| dataformats (string): Image data format specification of the form
| NCHW, NHWC, CHW, HWC, HW, WH, etc.
| Shape:
| img_tensor: Default is :math:`(N, 3, H, W)`. If ``dataformats`` is specified, other shape will be
| accepted. e.g. NCHW or NHWC.
|
| Examples::
|
| from torch.utils.tensorboard import SummaryWriter
| import numpy as np
|
| img_batch = np.zeros((16, 3, 100, 100))
| for i in range(16):
| img_batch[i, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 / 16 * i
| img_batch[i, 1] = (1 - np.arange(0, 10000).reshape(100, 100) / 10000) / 16 * i
|
| writer = SummaryWriter()
| writer.add_images('my_image_batch', img_batch, 0)
| writer.close()
|
| Expected result:
|
| .. image:: _static/img/tensorboard/add_images.png
| :scale: 30 %
解释:tag:图片标题; img_tensor:图片类型(只有这三种torch.Tensor, numpy.array, or string/blobname)下面的JpegImagePlugin格式不行
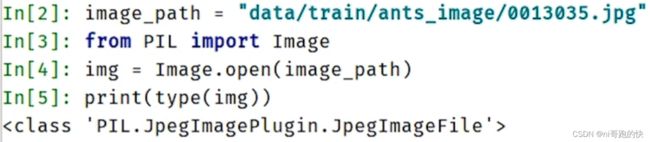
用poencv读取的是numpy类型,转换类型(主要是tensor类型变换)在后续文章深入介绍
这里说一个转换成numpy类型的方式
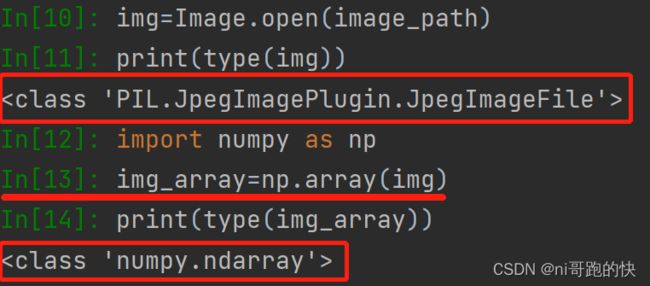
最后整体的代码:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("P9_logs_tensorboard2")
image_path1 = "data/train/bees_image/16838648_415acd9e3f.jpg"
image_path2 = "data/train/ants_image/9715481_b3cb4114ff.jpg"
#转换图片类型以符合add_imge的要求
img_PIL1 = Image.open(image_path1)
img_PIL2 = Image.open(image_path2)
img_array1 = np.array(img_PIL1)
img_array2 = np.array(img_PIL2)
# print(type(img_array1))
# print(img_array.shape)
writer.add_image("train", img_array1,1, dataformats='HWC')
writer.add_image("train", img_array2,2, dataformats='HWC')
#数字表示步长,输入不同的数字可以通过滑动进度条看不同步长的图
#dataformats表示图像传入的格式(高|宽|通道),如果不写,默认为(通道|高|宽)
writer.close() 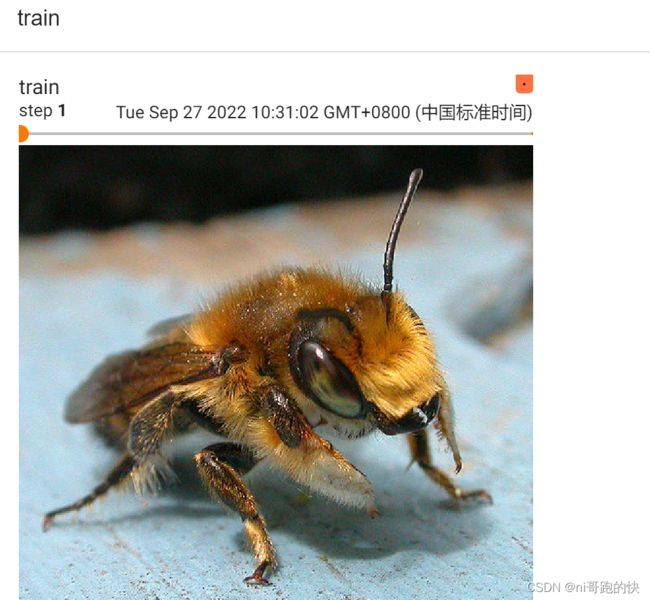
如果更改完代码之后刷新tensorboard并没有变化,需要将SummaryWriter创建的文件夹删掉,重新编译