层次softmax (hierarchical softmax)理解
目录
- 1 前言
- 2 CBOW(Continuous Bag-of-Word)
-
- 2.1 One-word context
- 2.2 Multi-word context
- 3 Skip-gram
- 4 hierarchical softmax
-
- 4.1 赫夫曼tree
- 4.2 叶子节点词的概率表示
- 4.3 各叶子节点概率值相加为1
- 4.5 怎么训练hierarchical softmax
-
- 4.5.1 预处理:构建haffman树
- 4.5.2 模型的输入
- 4.5.3 样本label
- 4.5.4 训练过程
- 4.5.5 模型预测
1 前言
基于word2vec模型学习词的语义向量表示,已在NLP许多任务中都发挥了重要的作用,接下来对词向量学习中的hierarchical softmax的应用做一个分析和学习
2 CBOW(Continuous Bag-of-Word)
2.1 One-word context
假设我们vocabulary size 为 V V V,hidden layer 神经元个数为 N N N,假设我们只有一个上下文单词,则根据这个上下文单词预测目标词,类似于一个bigram model,如下图所示:

输入是一个one-hot编码的vector(大小为 V V V),假设只给定一个上下文word,对于输入编码, { x 1 , x 2 , . . . , x v } \{x_1, x_2,...,x_v\} {x1,x2,...,xv},只有一个为1,其它都为0。如上图所示,第一层的参数权重 W V ∗ N W_{V*N} WV∗N, W W W中的每一行是一个 N N N维度的向量,代表的就是单词 w w w的向量 v w v_w vw表示。
从hidden layer到output layer,也有一个不同的权重矩阵 W ′ = { w i j ′ } W^{'}=\{w_{ij}^{'}\} W′={wij′},是一个 N ∗ V N*V N∗V的矩阵,第 j j j列代表了词 w j w_j wj的 N N N维度向量,用这个向量和hidden layer输出向量相乘,就得到在 V V V中的每个词的分值 u j u_j uj u j = v w j ′ T h (1) u_j = {v_{w_j}^{'}}^Th \text { { }(1)} uj=vwj′Th (1)
然后用softmax一个log 线性分类器,得到每个词的分布概率 p ( w j ∣ W I ) = y j = e x p ( u j ) ∑ j ′ = 1 V e x p ( u j ′ ) (2) p(w_j|W_I) = y_j = \frac{exp{(u_j)}}{\sum_{j^{'}=1}^Vexp{(u_j^{'})}} \text { { }(2)} p(wj∣WI)=yj=∑j′=1Vexp(uj′)exp(uj) (2)
其中 w I w_I wI是上下文单词, w j w_j wj是目标词, y j y_j yj是output layer层的第 j j j个神经元的输出。
v w v_w vw和 v w ′ v_w^{'} vw′是词 w w w的两个词向量表示, v w v_w vw来自input–>hidden的权重矩阵 W W W的行,而 v w ′ v_w^{'} vw′来自hidden—>output的权重矩阵 W ′ W^{'} W′的列,通过上面的语言模型,第一层权重 W W W就是我们学习的词向量矩阵。
首先让我们来看下从hidden—>output层的权重 W ′ W^{'} W′训练过程更新公式,这里就不做详细推导了,若想详细推导可以参考论文:word2vec Parameter Learning Explained, ∂ E ∂ u j = y j − t j : = e j (3) \frac {\partial E}{\partial u_j}=y_j-t_j:=e_j \text { { }(3)} ∂uj∂E=yj−tj:=ej (3) ∂ E ∂ w i j ′ = ∂ E ∂ u j . ∂ u j ∂ w i j ′ = e j . h i (4) \frac {\partial E}{\partial w_{ij}^{'}} = \frac {\partial E}{\partial u_j}. \frac {\partial u_j} {\partial w_{ij}^{'}} = e_j.h_i \text { { }(4)} ∂wij′∂E=∂uj∂E.∂wij′∂uj=ej.hi (4) v w j ′ ( n e w ) = v w j ′ ( o l d ) − η . e j . h (5) {v_{w_j}^{'}}^{(new)} = {v_{w_j}^{'}}^{(old)} - \eta.e_j.h \text { { }(5)} vwj′(new)=vwj′(old)−η.ej.h (5)
其中E为 loss function, e j e_j ej就是说的残差, t j t_j tj就是真实label(不是1就是0)从公式(2)和(5)可知,更新最后一层的权重梯度, 我们必须计算词典 V V V中的每个词,当 V V V很大的时候,最后一层softmax计算量会非常的耗时
2.2 Multi-word context
上面介绍了只有一个上下文词的情况,当多个上下文词的情况的时候,只需要将多个上下文词的向量求平均作为输入就行,如下图所示:

其中 h = 1 C W T ( x 1 + x 2 + . . . + x C ) h = \frac {1}{C} W^T(x_1+x_2+...+x_C) h=C1WT(x1+x2+...+xC)
3 Skip-gram
skip-gram model训练词向量方式和cbow输入和输出目标反过来,cbow用上下文词预测中心词,而skip-gram 用中心词预测上下文词,如下图所示:

理解了cbow模型,skip-gram也就不难理解了。有一点需要说明的是,因为一个中心词对应的上下文词可能有多个,所以正样本会有多个pair对
4 hierarchical softmax
从上面的公式(2)可以看出,softmax分母那项归一化,每次需要计算所有的V的输出值,才可以得到当前j节点的输出,当 V V V很大的时候, O ( V ) O(V) O(V)的计算代价会非常高。所以在训练word2vec模型的时候,用到了两个tricks,一个是negative sampling,每次只采少量的负label,不需要计算全部的 V V V;另外一个是hierarchical softmax,通过构建赫夫曼tree来做层级softmax,从复杂度 O ( V ) O(V) O(V)降低到 O ( l o g 2 V ) O(log_2V) O(log2V),接下来重点来说明下hierachical softmax的原理以及怎么训练hierachical softmax网络模型。
4.1 赫夫曼tree
赫夫曼tree的讲解和实现可以参考我的另外一篇博文:赫夫曼tree构建,这里就不再重复讲解了。Hierarchical softmax怎么通过赫夫曼tree来构建呢?如下图所示:
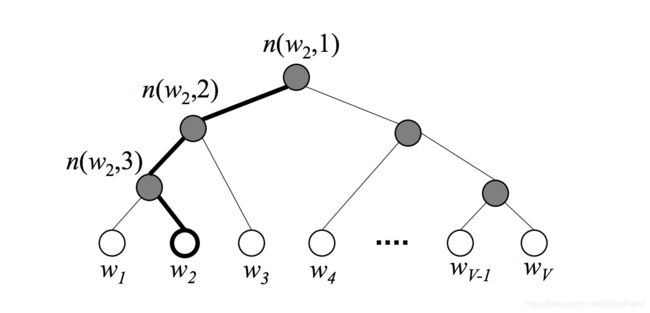
首先对所有在 V V V词表的词,根据词频来构建赫夫曼tree,词频越大,路径越短,编码信息更少。tree中的所有的叶子节点构成了词 V V V,中间节点则共有V-1个,上面的每个叶子节点存在唯一的从根到该节点的path,如上图所示, 词 w 2 w_2 w2的path n ( w 2 , 1 ) , n ( w 2 , 2 ) , n ( w 3 , 3 ) {n(w_2,1), n(w_2,2), n(w_3,3)} n(w2,1),n(w2,2),n(w3,3),其中 n ( w , j ) n(w,j) n(w,j)表示词 w w w的path的第 j j j个节点。
4.2 叶子节点词的概率表示
上图假设我们需要计算 w 2 w_2 w2的输出概率,我们定义从根节点开始,每次经过中间节点,做一个二分类任务(左边或者右边),所以我们定义中间节点的 n n n左边概率为 p ( n , l e f t ) = σ ( v n ′ T . h ) p(n, left) = σ({v_n^{'}}^T.h) p(n,left)=σ(vn′T.h)
其中 v n ′ v_n^{'} vn′是中间节点的向量,那么右边概率 p ( n , r i g h t ) = 1 − σ ( v n ′ T . h ) = σ ( − v n ′ T . h ) p(n, right)=1-σ({v_n^{'}}^T.h)= σ(-{v_n^{'}}^T.h) p(n,right)=1−σ(vn′T.h)=σ(−vn′T.h) 从根节点到 w 2 w_2 w2,我们可以计算概率值为:
p ( w 2 = w O ) = p(w_2=w_O) = p(w2=wO)=
p ( n ( w 2 , 1 ) , l e f t ) . p ( n ( w 2 , 2 ) , l e f t ) . p ( n ( w 3 , 3 ) , r i g h t ) p(n(w_2,1), left).p(n(w_2,2),left).p(n(w_3, 3), right) p(n(w2,1),left).p(n(w2,2),left).p(n(w3,3),right) = σ ( v n ( w 2 , 1 ) ′ T . h ) . σ ( v n ( w 2 , 2 ) ′ T . h ) . σ ( − v n ( w 3 , 3 ) ′ T . h ) =σ({v_{n(w_2,1)}^{'}}^T.h). σ({v_{n(w_2,2)}^{'}}^T.h). σ(-{v_{n(w_3,3)}^{'}}^T.h) =σ(vn(w2,1)′T.h).σ(vn(w2,2)′T.h).σ(−vn(w3,3)′T.h)
其中 σ为sigmoid函数
4.3 各叶子节点概率值相加为1
从论文里讲解的公式可以推导得出 ∑ i = 1 V p ( w i = w O ) = 1 \sum_{i=1}^{V}p(w_i=w_O) = 1 i=1∑Vp(wi=wO)=1
为了直观的理解,我们可以简单的计算一下,如下图所示:

假设有三个词 w 1 , w 2 , w 3 w_1,w_2,w_3 w1,w2,w3,由于每个中间节点是一个二分类,则p(left)+p(right)=1,如上图所示: w 3 = 0.4 w_3=0.4 w3=0.4, w 1 = 0.6 ∗ 0.5 = 0.3 , w 2 = 0.6 ∗ 0.5 = 0.3 w_1=0.6*0.5=0.3 , w_2=0.6*0.5=0.3 w1=0.6∗0.5=0.3,w2=0.6∗0.5=0.3,则: w 1 + w 2 + w 3 = 1 w_1+w_2+w_3=1 w1+w2+w3=1,或者用公式表示为:
w 1 + w 2 + w 3 = l 2 ∗ l 3 + l 2 ∗ l 4 + l 1 = l 2 ( l 3 + l 4 ) + l 1 = l 2 ∗ 1 + l 1 = 1 w_1+w_2+w_3 = l_2*l_3+l2*l_4+l_1=l_2(l_3+l_4)+l_1=l_2*1+l_1=1 w1+w2+w3=l2∗l3+l2∗l4+l1=l2(l3+l4)+l1=l2∗1+l1=1
所以每次预测所有叶子节点的概率之和为1,是一个分布,与softmax一致
4.5 怎么训练hierarchical softmax
借鉴Chris在youtube讲解的视频的图片,根据赫夫曼编码对每个叶子节点进行了编码,如下所示:

假设我们的词典有word [the, of ,respond, active, plutonium, ascetic, arbitrarily, chupacabra] 共8个单词。接下对hierarchical softmax训练做一个讲解,主要步骤如下:
4.5.1 预处理:构建haffman树
根据语料中的每个word的词频构建赫夫曼tree,词频越高,则离树根越近,路径越短。如上图所示,词典 V V V中的每个word都在叶子节点上,每个word需要计算两个信息:路径(经过的每个中间节点)以及赫夫曼编码,例如:
“respond”的路径经过的节点是(6,4,3),编码label是(1,0,0)
构建完赫夫曼tree后,每个叶子节点都有唯一的路径和编码,hierarchical softmax与softmax不同的是,在hierarchical softmax中,不对 V V V中的word词进行向量学习,而是对中间节点进行向量学习,而每个叶子上的节点可以通过路径中经过的中间节点去表示。
4.5.2 模型的输入
输入部分,在cbow或者skip-gram模型,要么是上下文word对应的id词向量平均,要么是中心词对应的id向量,作为hidden层的输出向量
4.5.3 样本label
不同softmax的是,每个词word对应的是一个 V V V大小的one-hot label,hierarchical softmax中每个叶子节点word,对应的label是赫夫曼编码,一般长度不超过 l o g 2 V log_2V log2V,在训练的时候,每个叶子节点的label统一编码到一个固定的长度,不足的可以进行pad
4.5.4 训练过程
我们用一个例子来描述,假如一个训练样本如下:
| input | output |
|---|---|
| chupacabra [0,0,0,…,1,0,0,…] | active [1,0,1] |
假如我们用skip-gram模型,则第一部分,根据"chupacabra" 词的one-hot编码乘以 W W W权重矩阵,得到“chupachabra”的词向量表示,也就是hidden的输出,根据目标词“active”从赫夫曼tree中得到它的路径path,即经过的节点(6,4,3),而这些中间节点的向量是模型参数需要学习的,共有 V − 1 V-1 V−1个向量,通过对应的节点id,取出相应的向量,假设是 w ′ ( 3 ∗ N ) w^{'}(3{*}N) w′(3∗N)(这里设词向量维度为N),分别与hidden输出向量相乘,再经过sigmoid函数,得到一个3*1的score分值,与实际label [1,0,1], 通过如下公式:
p a t h _ s c o r e = t f . l o g ( t f . m u l t i p l y ( l a b e l , s c o r e ) + t f . m u l t i p l y ( 1 − l a b e l , 1 − s c o r e ) ) path\_score = tf.log(tf.multiply(label, score)+tf.multiply(1-label, 1-score)) path_score=tf.log(tf.multiply(label,score)+tf.multiply(1−label,1−score))
l o s s = t f . r e d u c e _ s u m ( t f . n e g a t i v e ( p a t h _ s c o r e ) ) loss = tf.reduce\_sum(tf.negative(path\_score)) loss=tf.reduce_sum(tf.negative(path_score))
t f . m u l t i p l y ( l a b e l , s c o r e ) tf.multiply(label, score) tf.multiply(label,score)点乘,是获取该叶子节点路径中走右边各分支对应的概率分值, t f . m u l i t p l y ( 1 − l a b e l , 1 − s c o r e ) tf.mulitply(1-label, 1-score) tf.mulitply(1−label,1−score)获取路径中走左边各分支对应的概率分值,相加就是该路径[1,0,1]对应的[右分支—左分支—右分支]分别对应的概率分值 [ s c o r e 1 , s c o r e 2 , s c o r e 3 ] [score_1, score_2, score_3] [score1,score2,score3],由于小于1的分值相乘,会容易溢出,则取log,乘法变加法,loss则是与我们期望的概率值越大相反,需要取负用tf.negative实现,计算出loss,则就可以用优化器来计算模型中各参数的梯度进行更新了
在tensorflow中的实现如下:
# label [None, max_path_length], score [None, max_path_length]
path_score =tf.log(tf.multiply(label, score)+ tf.multiply(1-label, 1-score)
loss = tf.reduce_sum(tf.negative(path_score))
4.5.5 模型预测
训练过程中,每个word我们都提前知道了赫夫曼编码,所以训练的时候我们平均大概只要计算 l o g 2 V log_2V log2V的中间节点,就可以得到结果。但是在预测阶段,由于我们需要计算每个叶子节点输出概率值,然后取最大的一个概率,所以在预测阶段并不能省时间。那么怎么计算每个叶子节点也就是word的概率值?
从输入层到hidden层,得到输出向量,然后分别计算与每个叶子节点score分值。与训练过程一样,hidden向量与叶子节点的path经过的中间节点向量相乘,再sigmoid,然后用如下公式:
p a t h _ s c o r e = t f . l o g ( t f . m u l t i p l y ( l a b e l , s c o r e ) + t f . m u l t i p l y ( 1 − l a b e l , 1 − s c o r e ) ) path\_score =tf.log(tf.multiply(label, score)+tf.multiply(1-label, 1-score)) path_score=tf.log(tf.multiply(label,score)+tf.multiply(1−label,1−score))
s o c r e = t f . r e d u c e _ s u m ( p a t h _ s c o r e ) socre = tf.reduce\_sum(path\_score) socre=tf.reduce_sum(path_score)
计算所有叶子节点的score分值,取分值最大的则就是预测的word label
在tensorflow中的实现如下:
# label [None, max_path_length], score [None, max_path_length]
path_score = tf.log(tf.multiply(label, score)+ tf.multiply(1-label, 1-score))
score = tf.reduce_sum(path_score)