2022 ACL accepted论文集资料以及关键词分析
目录
- 1 会议论文数据集
-
- 1.1 爬虫获取paper基本信息
- 1.2 爬虫下载论文pdf
- 2 数据分析
-
- 2.1 关键词提取
- 2.2 可视化词云图
- 3 会议信息
1 会议论文数据集
1.1 爬虫获取paper基本信息
我们可以自己写一个简单爬虫,将2022年ACL收录的论文信息download下来,代码如下:
import sys
import requests
import pandas as pd
import numpy as np
import json
import re
import urllib
import fileinput
def get_information(url):
try:
req = requests.get(url, timeout=200)
if req.status_code != 200:
print('网页异常')
return
data = req.text
except Exception as e:
print(e)
return None
# get paper title, author, pdf link, abstract信息
# 正则提取符合条件的内容,打开网页源码,定位
title_p = re.compile(r'title = "(.*?)"')
author_p = re.compile(r'author = "([\s\S]*?)"')
link_p = re.compile(r'meta content=(https.*?pdf)')
abs_p = re.compile(r'Abstract(.*?)上面代码就是对2022 ACL中的论文进行信息提取和下载pdf论文,从上面代码来看,也比较简单,通过url访问,定位网页中论文的基本信息(标题,摘要,论文下载链接等),保存这些基本信息到2022ACL.txt文件中,同时下载每篇pdf论文,标题的形式为title.pdf。
1.2 爬虫下载论文pdf
执行上述脚本代码,我们就可以得到每篇论文的基本信息,2022ACL.txt文件的内容如下:
每行包含论文的title (红色标识部分),论文的作者 (蓝色标识部分),pdf下载url (绿色标识部分)以及论文摘要 (黄色标识部分)。这些信息接下来将用来做关键词分析。同时下载的论文pdf内容如下:
可以在百度网盘直接获取全部内容信息:链接:https://pan.baidu.com/s/1wunFwAuNOrl0vKkBiUw7uA 密码:bnxm
2 数据分析
2.1 关键词提取
接下来我们可以用一个很简单的方法进行关键词提取,基本步骤如下:
- 对每篇论文的title进行unigram, bigram以及triple生成候选关键词
- 对词进行规范化处理(词的不同式以及大小写等归一化)
- 通过unigram,bigram以及triple获取关键词候选集,根据词频以及关键词包含的单词数量等计算权重分值
我们简单的可以看下提取的效果:
unigram:
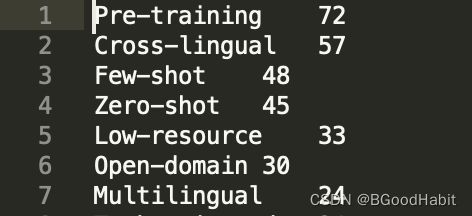
bigram:
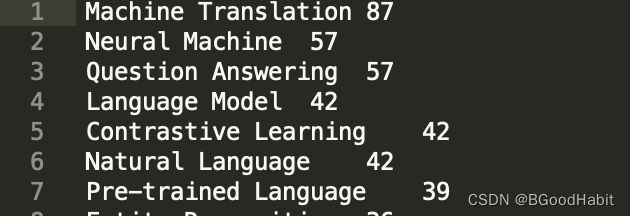
triple:

2.2 可视化词云图
对提取的关键词,根据词权重大小,我们生成词云图代码如下:
# -*-coding:utf8 -*-
import collections
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
from pyecharts import options as opts
from pyecharts.globals import ThemeType, CurrentConfig
import sys
def vision(filename, savename):
#读取词频文件 keyword \t frequency
f = open(filename)
result = dict()
for line in f:
terms = line.strip().split('\t')
result.setdefault(terms[0], terms[1])
result_sorted = sorted(result.items(), key=lambda x: x[1], reverse=True)
WC = WordCloud(init_opts=opts.InitOpts(width='1350px',height='750px', theme=ThemeType.MACARONS))
WC.add(
series_name='frequency',
data_pair=result_sorted,
shape=SymbolType.DIAMOND,
word_gap=5,
rotate_step=15,
word_size_range=[10,100],
textstyle_opts=opts.TextStyleOpts(font_family='KaiTi'),
pos_left = '100',
pos_top = '50'
)
WC.set_global_opts(
title_opts=opts.TitleOpts('关键词词云图'),
toolbox_opts=opts.ToolboxOpts(
is_show=True,
orient='vertical'),
tooltip_opts=opts.TooltipOpts(
is_show=True,
background_color='red',
border_color='yellow'))
WC.render(savename)
if __name__=='__main__':
filename, savename = sys.argv[1:]
vision(filename, savename)
生成的关键词词云图如下:

从上图可以看出在机器翻译(Machine Translation),预训练 (Pre-training)以及问答 (Question Answering)等领域备受研究人员的研究热潮。
3 会议信息
ACL (https://www.aclweb.org/portal)学术会议论文是自然语言处理与计算语言学领域的最高级别的学术会议之一,还有EMNLP (https://2022.emnlp.org/) 以及NACAL (http://naacl.org/)等也是大家所熟悉的。2022 ACL第60届大会于2022 年 5 月 22 日至 27 日在爱尔兰都柏林召开。本次会议共接收了604篇长论文,98篇短论文。其中最佳论文 (Best Paper) 来自加州大学伯克利分校研究团队,该研究提出了一种增量句法表示: Learned Incremental Representations for Parsing。论文摘要:该研究提出了一种增量句法表示,该表示包括为句子中的每个单词分配一个离散标签,其中标签是使用句子前缀的严格增量处理来预测的,并且句子标签序列完全确定了解析树,这种表示方法区别于标准表示。