【知识蒸馏】Channel-wise Knowledge Distillation for Dense Prediction

文章目录
-
- 一、背景
- 二、动机
- 三、方法
-
- 3.1 回顾 Spatial Distillation
- 3.2 Channel-wise Distillation
- 四、效果
- 五、训练和测试
- 六、代码解析
论文链接:https://arxiv.org/pdf/2011.13256.pdf
代码链接:https://github.com/irfanICMLL/TorchDistiller
MMDetection:https://github.com/pppppM/mmdetection-distiller
MMSegmentation:https://github.com/pppppM/mmsegmentation-distiller
出处:ICCV2021
一、背景
密集预测是计算机视觉的一个重要基础,如语义分割和目标检测,这些任务需要学习特征的良好表达。目前较好的方法都需要大量的计算资源,难以在移动端部署。
分类任务上的蒸馏起到了明显的效果[16, 2],但没法直接用到语义分割,因为将逐个像素分类的任务严格对齐会导致 student 模型过度学习 teacher 的输出,无法获得最优结果。
于是有一些方法 [25,24,18] 聚焦于加强不同 spatial 的联系,如图2a:
- 首先,每个空间位置上的特征图都被归一化
- 然后,通过聚合不同空间位置的子集来分析一些特定任务的关系,如 pair-wise 关系[25,35],和 inter-class 关系[18]。
二、动机

- Spatial distillation: 空间方向的蒸馏,可以理解成对所有通道的相同位置的点做归一化,然后让学生网络学习这个归一化后的分布,可以理解成对类别的蒸馏。
- Channel distillation: 通道方向的蒸馏,可以理解成对单个通道内做归一化,然后让学生网络学习这个归一化后的分布,可以理解成对位置的蒸馏。
虽然上面的这些方法比逐点对比好一些,但特征图中的每个空间位置都对 konwledge transfering 贡献相同,这样可能从 teacher 带来一些冗余信息。
还有一些方法使用了 channel 蒸馏,[50] 提出了将每个 channel 的 activation 聚合到一个聚合向量,这样更有利于 image-level 的分类,但不适合于需要空间信息的密集预测。
所以本文通过归一化每个 channel 的特征图来得到 soft probability map,如图2b,然后最小化两个网络的 channel-wise probability map 的 asymmetry Kullback-Leibler(KL)散度,该KL 散度也就是 teacher 和 student 网络的每个channel间的分布。一个例子如图2c,每个 channel 的 activation map 会更关注于每个 channel 中的突出区域,也就是每个类别的突出区域,而这些区域恰恰是对密集预测很有用的。
- COCO 上使用 RetinaNet(res50)提了3.4% mAP
- Cityscape 上使用 PSPNet 提了5.81% mIoU
三、方法

The activation values in this work include the final logits and the inner feature maps
3.1 回顾 Spatial Distillation
通常的蒸馏方法是使用 point-wise 对齐的方式,形式如下:

3.2 Channel-wise Distillation
为了更好的利用每个 channel 中的知识,作者提出了对 teacher 和 student 网络的对应 channel activation 进行 softly align。
- 首先,将每个 channel 的 activation 转换成概率分布,即可以使用概率分布度量方式来衡量其差异,如 KL 散度。如图2c所示,每个 channel 的 activation 都趋向于对每个类别的突出特征进行编码
- 然后,使用训练好的 teacher 模型来得到预测的 clear category-specific mask,如图1右侧所示,让 student 网络从 teacher 网络中学习知识
Channel-wise distillation loss 如下:

-
y T y^T yT:teacher 的 activation map
-
y S y^S yS:student 的 activation map
-
ϕ \phi ϕ:将 activation value 转换成概率分布的方式,如下所示,使用这种 softmax 归一化,就可以消除大网络和小网络之间的数值大小之差。
- c = 1 , 2 , . . . , C c = 1,2,...,C c=1,2,...,C :表示 channel
- i i i : channel 中像素位置
- T T T:温度参数,也是一个超参数,当 T T T 越大,输出的概率分布越 soft,即每个channel关注的空间区域就越大
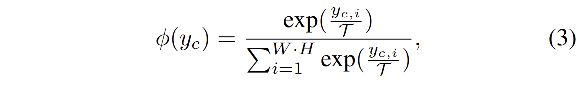
-
如何解决 teacher 和 student 的 channel 个数不一致: 使用 1x1 卷积对 student 网络个数进行上采样
-
Φ \Phi Φ:用来衡量 teacher 和 student 的每个 channel 的概率分布的差异,本文使用 KL 散度
- KL 散度是一个不对称的衡量方式
- 当 ϕ ( y c , i T ) \phi(y_{c,i}^T) ϕ(yc,iT) 越大, ϕ ( y c , i S ) \phi(y_{c,i}^S) ϕ(yc,iS) 也要越大,来最小化 KL 散度
- 当 ϕ ( y c , i T ) \phi(y_{c,i}^T) ϕ(yc,iT) 越小,则 KL 散度确不会让 ϕ ( y c , i S ) \phi(y_{c,i}^S) ϕ(yc,iS) 一直变小
- 所以,student 网络会更趋向于在前景突出特征的位置学习 teacher 网络的分布,teacher 网络分布的背景区域对学习产生的影响很小

四、效果
T = 4 T=4 T=4
logits map: α = 3 \alpha=3 α=3
feature map: α = 50 \alpha=50 α=50


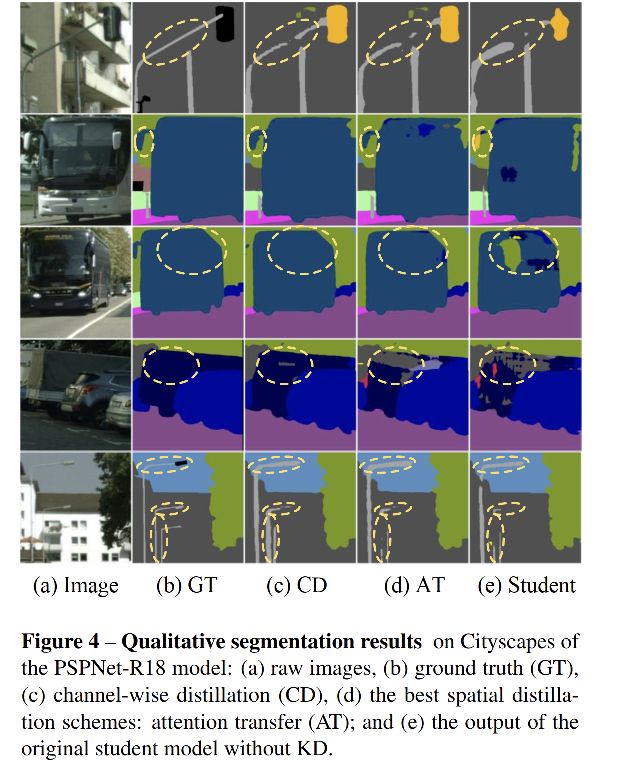
消融实验:



五、训练和测试
以 mmsegmentation 的训练代码为例
1、安装 mmsegmentation
2、软连接数据:
cd mmsegmentation_distiller
mkdir data
ln -s cityscapes .
3、下载训练好的大模型 pspnet_r101,并放到 pretrained_model下,下载模型路径
4、训练和测试
# 单 GPU 训练
python tools/train.py configs/distiller/cwd/cwd_psp_r101-d8_distill_psp_r18_d8_512_1024_80k_cityscapes.py
# 训练教师网络
python tools/train.py configs/ocrnet/ocrnet_hr48_512x1024_80k_cityscapes.py
# 多 GPU 训练
bash tools/dist_train.sh configs/distillers/cwd/cwd_psp_r101-d8_distill_psp_r18_d8_512_1024_80k_cityscapes.py 8
#单 GPU 测试
python tools/test.py configs/distillers/cwd/cwd_psp_r101-d8_distill_psp_r18_d8_512_1024_80k_cityscapes.py $CHECKPOINT --eval mIoU
#多 GPU 测试
bash tools/dist_test.sh configs/distillers/cwd/cwd_psp_r101-d8_distill_psp_r18_d8_512_1024_80k_cityscapes.py $CHECKPOINT 8 --eval mIoU
5、了解 config
config/distiller/cwd/cwd_psp_r101-d8_distill_psp_d8_512_1024_80k_cityscapes.py
_base_ = [
'../../_base_/datasets/cityscapes.py',
'../../_base_/default_runtime.py', '../../_base_/schedules/schedule_80k.py'
]
find_unused_parameters=True
weight=5.0
tau=1.0
distiller = dict(
type='SegmentationDistiller',
teacher_pretrained = 'pretrained_model/pspnet_r101b-d8_512x1024_80k_cityscapes_20201226_170012-3a4d38ab.pth',
distill_cfg = [ dict(student_module = 'decode_head.conv_seg',
teacher_module = 'decode_head.conv_seg',
output_hook = True,
methods=[dict(type='ChannelWiseDivergence',
name='loss_cwd',
student_channels = 19,
teacher_channels = 19,
tau = tau,
weight =weight,
)
]
),
]
)
student_cfg = 'configs/pspnet/pspnet_r18-d8_512x1024_80k_cityscapes.py'
teacher_cfg = 'configs/pspnet/pspnet_r101-d8_512x1024_80k_cityscapes.py'
- 教师网络
decode_head.conv_seg:
$ p teacher_modules['decode_head.conv_seg']
>>>
Conv2d(512, 19, kernel_size=(1, 1), stride=(1, 1))
- 学生网络
decode_head.conv_seg:
$ p student_modules['decode_head.conv_seg']
>>>
Conv2d(128, 19, kernel_size=(1, 1), stride=(1, 1))
6、psp 教师网络解码头结构:
(decode_head): PSPHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss()
(conv_seg): Conv2d(512, 19, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(psp_modules): PPM(
(0): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(1): Sequential(
(0): AdaptiveAvgPool2d(output_size=2)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(2): Sequential(
(0): AdaptiveAvgPool2d(output_size=3)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(3): Sequential(
(0): AdaptiveAvgPool2d(output_size=6)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(bottleneck): ConvModule(
(conv): Conv2d(4096, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(auxiliary_head): FCNHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss()
(conv_seg): Conv2d(256, 19, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
7、psp 学生网络解码头结构:
(decode_head): PSPHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss()
(conv_seg): Conv2d(128, 19, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(psp_modules): PPM(
(0): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): ConvModule(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(1): Sequential(
(0): AdaptiveAvgPool2d(output_size=2)
(1): ConvModule(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(2): Sequential(
(0): AdaptiveAvgPool2d(output_size=3)
(1): ConvModule(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(3): Sequential(
(0): AdaptiveAvgPool2d(output_size=6)
(1): ConvModule(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(bottleneck): ConvModule(
(conv): Conv2d(1024, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(auxiliary_head): FCNHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss()
(conv_seg): Conv2d(64, 19, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(256, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
(distill_losses): ModuleDict(
(loss_cwd): ChannelWiseDivergence()
)
)
这里的 decode_head.seg_conv 其实是最后一层的输出,即 PSP 头输出的最终结果,每个通道表示一个类别目标的预测。
8、如何修改为其他网络结构的蒸馏
这里以 OCR 网络为例,psp 中是使用网络的 decode_head.seg_conv 作为输入的,我们首先需要看一下 OCR 网络的 decode_head 结构,然后也取最后一层的输出,即最后一层头的 seg_conv 作为蒸馏的输入,这里以 hr48 作为教师网络,hr18s作为学生网络:
教师网络 decode_head:
ModuleList(
(0): FCNHead(
input_transform=resize_concat, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss()
(conv_seg): Conv2d(270, 19, kernel_size=(1, 1), stride=(1, 1))
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(270, 270, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(270, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(1): OCRHead(
input_transform=resize_concat, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss()
(conv_seg): Conv2d(512, 19, kernel_size=(1, 1), stride=(1, 1))
(object_context_block): ObjectAttentionBlock(
(key_project): Sequential(
(0): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(query_project): Sequential(
(0): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(value_project): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(out_project): ConvModule(
(conv): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(bottleneck): ConvModule(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(spatial_gather_module): SpatialGatherModule()
(bottleneck): ConvModule(
(conv): Conv2d(270, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
基于此,OCR 网络的蒸馏输入:
- 教师网络
$ p teacher_modules['decode_head.1.conv_seg']
>>>
Conv2d(512, 19, kernel_size=(1, 1), stride=(1, 1))
- 学生网络
$ p student_modules['decode_head.1.conv_seg']
>>>
Conv2d(512, 19, kernel_size=(1, 1), stride=(1, 1))
所以只需要修改config即可,大模型是在mmsegmentation 官方代码中下载的,最终config如下:
_base_ = [
'../../_base_/datasets/cityscapes.py',
'../../_base_/default_runtime.py', '../../_base_/schedules/schedule_80k.py'
]
find_unused_parameters=True
weight=5.0
tau=1.0
distiller = dict(
type='SegmentationDistiller',
teacher_pretrained = 'pretrained_model/ocrnet_hr48_512x1024_160k_cityscapes.pth',
distill_cfg = [ dict(student_module = 'decode_head.1.conv_seg',
teacher_module = 'decode_head.1.conv_seg',
output_hook = True,
methods=[dict(type='ChannelWiseDivergence',
name='loss_cwd',
student_channels = 19,
teacher_channels = 19,
tau = tau,
weight =weight,
)
]
),
]
)
student_cfg = 'configs/ocrnet/ocrnet_hr18s_512x1024_80k_cityscapes.py'
teacher_cfg = 'configs/ocrnet/ocrnet_hr48_512x1024_160k_cityscapes.py'
代码训练:
python tools/train.py configs/distiller/cwd/cwd_ocr_hr48-d8_distill_ocr_hr18s-d8_512_1024_80k_cityscapes.py
训练结果记录:
cityscapes/ val /512x1024/ 80k iter/
| 教师网络结构 | mIoU | 学生网络结构 | mIoU(蒸馏) | mIoU(未蒸馏) |
|---|---|---|---|---|
| psp_r101 (272.4M) | 79.74 | psp_r18 (51.2M) | 74.86 | |
| ocr_hr48 (282.2M) | 81.35 | ocr_hr18s (25.8M) | 79.68 | 77.29 |
六、代码解析

如果没有 distiller config 的话,则会按照正常训练方式训练,distiller config 如下:
distiller_cfg = cfg.get('distiller', None)
$ p disstiller_cfg
>>>
{'type': 'SegmentationDistiller', 'teacher_pretrained': 'pretrained_model/ocrnet_hr48_512x1024_160k_cityscapes.pth',
'distill_cfg': [{'student_module': 'decode_head.1.conv_seg', 'teacher_module': 'decode_head.1.conv_seg',
'output_hook': True, 'methods': [{'type': 'ChannelWiseDivergence', 'name': 'loss_cwd',
'student_channels': 19, 'teacher_channels': 19, 'tau': 1.0, 'weight': 5.0}]}]}
使用 Config.fromfile() 即可把 config 文件中的内容拿出来:
teacher_cfg = Config.fromfile(cfg.teacher_cfg)
student_cfg = Config.fromfile(cfg.student_cfg)
训练的时候使用的是 student 模型的 train_cfg 和 test_cfg:
tools/train.py # line 137
model = build_distiller(cfg.distiller,teacher_cfg,student_cfg,
train_cfg=student_cfg.get('train_cfg'),
test_cfg=student_cfg.get('test_cfg'))
蒸馏的训练方式和普通的训练方式不同之一:optimezier 优化的参数不同,蒸馏的话,只有student 的参数和蒸馏 loss 的参数参与训练。
mmseg/apis/train.py # line 72
# build runner
distiller_cfg = cfg.get('distiller',None)
if distiller_cfg is None:
optimizer = build_optimizer(model, cfg.optimizer)
else:
# base_parameters() 在 segmentation_distiller.py line 69
# base_parameters() 包括 student 和 distill_loss
optimizer = build_optimizer(model.module.base_parameters(), cfg.optimizer)
可以使用这样的方式来查看不需要参数训练的参数:
# pytorch 中需要训练的参数
model.named_parameters()
# 不需要参数训练的参数
model.named_buffers()
pytorch 可以使用 register_buffer() 来使得该参数不参与训练
# name 是名字, 参数是登记的不参与训练的参数
register_buffer(name, 参数)
buffer_key = [k for k,v in self.named_buffers()]
>>>
['student_decode_head_1_conv_seg', 'teacher_decode_head_1_conv_seg', 'teacher.backbone.bn1.running_mean', 'teacher.backbone.bn1.running_var', 'teacher.backbone.bn1.num_batches_tracked', 'teacher.backbone.bn2.running_mean', 'teacher.backbone.bn2.running_var', 'teacher.backbone.bn2.num_batches_tracked', ...
蒸馏的训练方法:分两步,第一步计算不参与蒸馏的层的 loss,然后计算参与蒸馏的层的loss
mmseg/distillation/distillers/segmentation_distiller.py
def forward_train(self, img, img_metas, gt_semantic_seg):
with torch.no_grad():
self.teacher.eval()
teacher_loss = self.teacher.forward_train(img, img_metas, gt_semantic_seg) # mmseg/models/segmentors/encoder_decoder.py(136)forward_train()
student_loss = self.student.forward_train(img, img_metas, gt_semantic_seg)
# 整体loss
# {'decode_0.loss_seg': tensor(1.1701, device='cuda:0', grad_fn=), 'decode_0.acc_seg': tensor([3.7306], device='cuda:0'), \
# 'decode_1.loss_seg': tensor(2.9231, device='cuda:0', grad_fn=), 'decode_1.acc_seg': tensor([6.0701], device='cuda:0')}
buffer_dict = dict(self.named_buffers()) # named_buffers() 查看网络中不需要更新的参数, parameters()查看网络中需要更新的参数
for item_loc in self.distill_cfg:
student_module = 'student_' + item_loc.student_module.replace('.','_') # 'student_decode_head_1_conv_seg'
teacher_module = 'teacher_' + item_loc.teacher_module.replace('.','_') # 'teacher_decode_head_1_conv_seg'
# 下面这两步是关键,提取的是教师网络和学生网络的输入 decode_head 之前的输出,如下图所示
student_feat = buffer_dict[student_module] # [b, 19, 128 256]
teacher_feat = buffer_dict[teacher_module] # [b, 19, 128 256]
for item_loss in item_loc.methods: # item_loc.methods: [{'type': 'ChannelWiseDivergence', 'name': 'loss_cwd', 'student_channels': 19, 'teacher_channels': 19, 'tau': 1.0, 'weight': 5.0}]
loss_name = item_loss.name # 'loss_cwd'
student_loss[ loss_name] = self.distill_losses[loss_name](student_feat,teacher_feat)
# 增加了蒸馏 loss 后的loss:
# {'decode_0.loss_seg': tensor(1.1701, device='cuda:0', grad_fn=), 'decode_0.acc_seg': tensor([3.7306], device='cuda:0'),
# 'decode_1.loss_seg': tensor(2.9231, device='cuda:0', grad_fn=), 'decode_1.acc_seg': tensor([6.0701], device='cuda:0'),
# 'loss_cwd': tensor(51.9439, device='cuda:0', grad_fn=)}
return student_loss
下面这两组特征的特征图如下图所示,学生网络是第一次迭代的特征图,还没有学到任何特征
student_feat = buffer_dict[student_module] # [b, 19, 128 256]
teacher_feat = buffer_dict[teacher_module] # [b, 19, 128 256]
teacher_feat:
student_feat:
看一下这两个特征是怎么来的,这里是使用 hook 来获取这两层的输出特征来得到的这两组特征,每次实例化SegmentationDistiller 这个类的时候,其 init 里边都会走一遍特征注册的过程,保证每次迭代后的特征放入 hook 里边:
hook 分为两种:
register_forward_hook(hook)register_backward_hook(hook)
hook 的作用是获取某些变量的中间结果,因为pytorch会自动舍弃图计算的中间结果,所以想要获取这些数值就需要使用 hook 函数,hook 函数在使用后需要及时删除,避免每次都运行其增加负载。
# 这里写了一个注册的 hook
def regitster_hooks(student_module,teacher_module):
def hook_teacher_forward(module, input, output):
# 这里的 input 和 output 是这层的输入和输出
self.register_buffer(teacher_module,output) # 通过register_buffer()登记过的张量:会自动成为模型中的参数,随着模型移动(gpu/cpu)而移动,但是不会随着梯度进行更新。
def hook_student_forward(module, input, output):
self.register_buffer( student_module,output )
return hook_teacher_forward,hook_student_forward
for item_loc in distill_cfg:
student_module = 'student_' + item_loc.student_module.replace('.','_') # 'student_decode_head_1_conv_seg'
teacher_module = 'teacher_' + item_loc.teacher_module.replace('.','_') # 'teacher_decode_head_1_conv_seg'
# 这里进行
hook_teacher_forward,hook_student_forward = regitster_hooks(student_module ,teacher_module )
teacher_modules[item_loc.teacher_module].register_forward_hook(hook_teacher_forward)
student_modules[item_loc.student_module].register_forward_hook(hook_student_forward)
register_forward_hook(hook) 作用就是(假设想要conv2层),那么就是根据 model(该层),该层input,该层output,可以将 output获取。
register_forward_hook(hook) 最大的作用也就是当训练好某个model,想要展示某一层对最终目标的影响效果。
求loss的方法:
import torch.nn as nn
import torch.nn.functional as F
import torch
from .utils import weight_reduce_loss
from ..builder import DISTILL_LOSSES
@DISTILL_LOSSES.register_module()
class ChannelWiseDivergence(nn.Module):
"""PyTorch version of `Channel-wise Distillation for Semantic Segmentation
`_.
Args:
student_channels(int): Number of channels in the student's feature map.
teacher_channels(int): Number of channels in the teacher's feature map.
name(str):
tau (float, optional): Temperature coefficient. Defaults to 1.0.
weight (float, optional): Weight of loss.Defaults to 1.0.
"""
def __init__(self,
student_channels,
teacher_channels,
name,
tau=1.0,
weight=1.0,
):
super(ChannelWiseDivergence, self).__init__()
self.tau = tau
self.loss_weight = weight
if student_channels != teacher_channels:
self.align = nn.Conv2d(student_channels, teacher_channels, kernel_size=1, stride=1, padding=0)
else:
self.align = None
def forward(self,
preds_S,
preds_T):
"""Forward function."""
assert preds_S.shape[-2:] == preds_T.shape[-2:],'the output dim of teacher and student differ'
N,C,W,H = preds_S.shape # [2, 19, 128, 256]
if self.align is not None:
preds_S = self.align(preds_S)
softmax_pred_T = F.softmax(preds_T.view(-1,W*H)/self.tau, dim=1)
softmax_pred_S = F.softmax(preds_S.view(-1,W*H)/self.tau, dim=1)
logsoftmax = torch.nn.LogSoftmax(dim=1)
loss = torch.sum( - softmax_pred_T * logsoftmax(preds_S.view(-1,W*H)/self.tau)) * (self.tau ** 2)
return self.loss_weight * loss / (C * N)

这里 KL 散度公式如上,展开后是这样的:
D K L = ∑ p log p − p log q = ∑ T log T − T log S D_{KL} = \sum p\ \text{log}p-p\ \text{log}q=\sum T\ \text{log}T-T\ \text{log}S DKL=∑p logp−p logq=∑T logT−T logS
前一项实际上是教师网络的输出,是固定不变的,所以最终的形式变成了 ∑ − T log S \sum-T\ \text{log}S ∑−T logS,也就是上面的代码中的形式。
这里以 OCR 为例解释一下 loss 的组成:FCN loss + OCR loss + distillation loss
1、原始loss的计算:
- OCR 是 cascade_docode_head,因为其解码头由 FCN 和 OCR 组成
- FCN 的输入是backbone的输出,FCN 拿到一组 backbone 的输出(有四组不同大小的特征图构成,通道数共为270),然后输出成 [N, 19, 128, 256] 的特征图进行loss计算,这里就是总loss中的
'decode_0.loss_seg'
所以,在 segmentation_distiller.py 中计算原本的 loss 的时候,loss 会找到 mmseg/models/segmentors/cascade_encoder_decoder.py 中来计算前向传播的loss:
def _decode_head_forward_train(self, x, img_metas, gt_semantic_seg):
"""Run forward function and calculate loss for decode head in
training."""
losses = dict()
# 先计算 decode_head[0] 的 loss,即 FPN 的 loss
# 第一个 decode_head 走的是 cascade_head.py 的 forward_train 的过程
loss_decode = self.decode_head[0].forward_train(x, img_metas, gt_semantic_seg, self.train_cfg)
# loss_decode: {'loss_seg': tensor(1.1506, device='cuda:0', grad_fn=), 'acc_seg': tensor([1.5568], device='cuda:0')}
losses.update(add_prefix(loss_decode, 'decode_0'))
# loss: {'decode_0.loss_seg': tensor(1.1506, device='cuda:0', grad_fn=), 'decode_0.acc_seg': tensor([1.5568], device='cuda:0')}
for i in range(1, self.num_stages): # config/models/ocrnet_hr18.py 中写了 num_stage=2
# forward test again, maybe unnecessary for most methods.
# prev_outputs 是将 backbone 的输出又走了一遍 FPN 得到的输出,即 decode_head[0] 的输出 [N, 19, 128, 256]
prev_outputs = self.decode_head[i - 1].forward_test(x, img_metas, self.test_cfg)
# 然后将 FPN 的输出作为 loss 的输入
# 第二个及之后的 decode_heads 都会走 cascade_decode_head 的 forward_train,走到 ocr_head.py 中去
# mmseg/models/decode_heads/cascade_decode_head.py # line 18
# 这里的 x 是 backbone的输出(270维),prev_outputs 是 FPN 的输出
# OCRnet 会利用backbone 的输出和 FPN 的输出,做一个自己的注意力操作,得到 [N, 19, 128, 256] 的输出,然后和真值做 loss
loss_decode = self.decode_head[i].forward_train(x, prev_outputs, img_metas, gt_semantic_seg, self.train_cfg)
losses.update(add_prefix(loss_decode, f'decode_{i}'))
# {'decode_0.loss_seg': tensor(1.1506, device='cuda:0', grad_fn=), 'decode_0.acc_seg': tensor([1.5568], device='cuda:0'), 'decode_1.loss_seg': tensor(2.8385, device='cuda:0', grad_fn=), 'decode_1.acc_seg': tensor([1.2970], device='cuda:0')}
return losses
# mmseg/models/decode_heads/decode_head.py # line 170
# decode_head[0] 的计算 loss
def forward_train(self, inputs, img_metas, gt_semantic_seg, train_cfg):
# inputs.shape [2, 19, 128, 256]
#
seg_logits = self.forward(inputs)
losses = self.losses(seg_logits, gt_semantic_seg)
return losses
# mmseg/models/decode_heads/cascade_decode_head.py # line 18
# decode_head[1] 及之后 head 的计算 loss
def forward_train(self, inputs, prev_output, img_metas, gt_semantic_seg,
train_cfg):
seg_logits = self.forward(inputs, prev_output)
losses = self.losses(seg_logits, gt_semantic_seg)
return losses
# mmseg/models/decode_heads/decode_head.py
@force_fp32(apply_to=('seg_logit', ))
def losses(self, seg_logit, seg_label):
"""Compute segmentation loss."""
loss = dict()
# 先把预测的 128x256 的结果上采样到 512x1024的,和真值大小一样
seg_logit = resize(
input=seg_logit,
size=seg_label.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
if self.sampler is not None:
seg_weight = self.sampler.sample(seg_logit, seg_label)
else:
seg_weight = None
seg_label = seg_label.squeeze(1)
# 进入 cross_entropy_loss # mmseg/models/losses/cross_entropy_loss.py
loss['loss_seg'] = self.loss_decode(
seg_logit,
seg_label,
weight=seg_weight,
ignore_index=self.ignore_index)
loss['acc_seg'] = accuracy(seg_logit, seg_label)
return loss
# 得到 'acc_seg' 和 'loss_seg'
2、蒸馏 loss 的计算:计算
def forward(self, preds_S, preds_T):
"""Forward function."""
assert preds_S.shape[-2:] == preds_T.shape[-2:],'the output dim of teacher and student differ'
N,C,W,H = preds_S.shape
if self.align is not None:
preds_S = self.align(preds_S)
# 这里的归一化方式是唯一能体现 channel 的地方
# 对每个channel的所有元素进行归一化,然后让学生网络学习归一化后的通道特征
softmax_pred_T = F.softmax(preds_T.view(-1,W*H)/self.tau, dim=1) #[NxC, 32768]
logsoftmax = torch.nn.LogSoftmax(dim=1)
loss = torch.sum( - softmax_pred_T * logsoftmax(preds_S.view(-1,W*H)/self.tau)) * (self.tau ** 2)
return self.loss_weight * loss / (C * N)
最终的 loss 如下:
{'decode_0.loss_seg': tensor(1.1506, device='cuda:0', grad_fn=<MulBackward0>), 'decode_0.acc_seg': tensor([1.5568], device='cuda:0'), 'decode_1.loss_seg': tensor(2.8385, device='cuda:0', grad_fn=<MulBackward0>), 'decode_1.acc_seg': tensor([1.2970], device='cuda:0'), 'loss_cwd': tensor(52.1290, device='cuda:0', grad_fn=<DivBackward0>)}
然后在 mmseg/models/segmentors/base.py 中,求 loss 的和:
loss = sum(_value for _key, _value in log_vars.items() if 'loss' in _key)
log_vars['loss'] = loss
{
'loss':
tensor(55.8550, device='cuda:0', grad_fn=<AddBackward0>),
'log_vars':
OrderedDict([('decode_0.loss_seg', 1.0829237699508667),
('decode_0.acc_seg', 10.901641845703125),
('decode_1.loss_seg', 2.7209525108337402),
('decode_1.acc_seg', 2.446269989013672),
('loss_cwd', 52.051116943359375),
('loss', 55.8549919128418)]),
'num_samples': 2
}
Register 的简要介绍:
mmseg框架里边使用了很多注册的方式,注册模块实际上是通过字典保存名字对应类的地址,其中最重要的是 register 类
首先,使用self._module_dict = dict() 来作为注册类的地址,以便后续访问。
@SEGMENTORS.register_module()
class EncoderDecoder(BaseSegmentor):
def __init__(self,
backbone,
decode_head,
neck=None,
auxiliary_head=None,
train_cfg=None,
test_cfg=None,
pretrained=None):
super(EncoderDecoder, self).__init__()
self.backbone = builder.build_backbone(backbone)
if neck is not None:
self.neck = builder.build_neck(neck)
self._init_decode_head(decode_head)
self._init_auxiliary_head(auxiliary_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
self.init_weights(pretrained=pretrained)
assert self.with_decode_head
register.py 文件如下:
import inspect
import six
def is_str(x):
"""Whether the input is an string instance."""
return isinstance(x, six.string_types)
class Registry(object):
def __init__(self, name):
self._name = name # 此处的self,是个对象(Object),是当前类的实例,name即为传进来的'detector'值
self._module_dict = dict() # 定义的属性,是一个字典
@property
def name(self): # 把方法变成属性,通过self.name 就能获得name的值。我感觉是一个私有函数
return self._name
@property
def module_dict(self):
return self._module_dict
def get(self, key):
return self._module_dict.get(key, None)
def _register_module(self, module_class):
"""
关键的一个方法,作用就是Register a module.
在model文件夹下的py文件中,里面的class定义上面都会出现 @DETECTORS.register_module,意思就是将类当做形参,
将类送入了方法register_module()中执行。@的具体用法看后面解释。
Register a module.
Args:
module (:obj:`nn.Module`): Module to be registered.
"""
# if not inspect.isclass(module_class): # 判断是否为类,是类的话,就为True,否则报错
# raise TypeError('module must be a class, but got {}'.format(
# type(module_class)))
module_name = module_class.__name__ # 获取类名
if module_name in self._module_dict: # 看该类是否已经登记在属性_module_dict中
raise KeyError('{} is already registered in {}'.format(
module_name, self.name))
self._module_dict[module_name] = module_class # 在module中dict新增key和value。key为类名,value为类对象
def register_module(self, cls): # 对上面的方法,修改了名字,添加了返回值,即返回类本身
self._register_module(cls)
return cls
def build_from_cfg(cfg, registry, default_args=None):
"""Build a module from config dict.
Args:
cfg (dict): Config dict. It should at least contain the key "type".
registry (:obj:`Registry`): The registry to search the type from.
default_args (dict, optional): Default initialization arguments.
Returns:
obj: The constructed object.
"""
assert isinstance(cfg, dict) and 'type' in cfg
assert isinstance(default_args, dict) or default_args is None
args = cfg.copy()
obj_type = args.pop('type')
if is_str(obj_type):
obj_cls = registry.get(obj_type)
if obj_cls is None:
raise KeyError('{} is not in the {} registry'.format(
obj_type, registry.name))
elif inspect.isclass(obj_type):
obj_cls = obj_type
else:
raise TypeError('type must be a str or valid type, but got {}'.format(
type(obj_type)))
if default_args is not None:
for name, value in default_args.items():
args.setdefault(name, value)
return obj_cls(**args)