【深度学习】目标检测 yolov5模型量化安装教程以及转ONXX,torchscript,engine和速度比较一栏表
模型量化
yolov5 的模型量化,好好看看export.py
# YOLOv5 by Ultralytics, GPL-3.0 license
"""
Export a YOLOv5 PyTorch model to other formats. TensorFlow exports authored by https://github.com/zldrobit
Format | `export.py --include` | Model
--- | --- | ---
PyTorch | - | yolov5s.pt
TorchScript | `torchscript` | yolov5s.torchscript
ONNX | `onnx` | yolov5s.onnx
OpenVINO | `openvino` | yolov5s_openvino_model/
TensorRT | `engine` | yolov5s.engine
CoreML | `coreml` | yolov5s.mlmodel
TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
TensorFlow GraphDef | `pb` | yolov5s.pb
TensorFlow Lite | `tflite` | yolov5s.tflite
TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
TensorFlow.js | `tfjs` | yolov5s_web_model/
PaddlePaddle | `paddle` | yolov5s_paddle_model/
Requirements:
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
Usage:
$ python export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
Inference:
$ python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
TensorFlow.js:
$ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
$ npm install
$ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
$ npm start
"""
import argparse
import json
import os
import platform
import subprocess
import sys
import time
import warnings
from pathlib import Path
import pandas as pd
import torch
from torch.utils.mobile_optimizer import optimize_for_mobile
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
if platform.system() != 'Windows':
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.experimental import attempt_load
from models.yolo import ClassificationModel, Detect
from utils.dataloaders import LoadImages
from utils.general import (LOGGER, Profile, check_dataset, check_img_size, check_requirements, check_version,
check_yaml, colorstr, file_size, get_default_args, print_args, url2file, yaml_save)
from utils.torch_utils import select_device, smart_inference_mode
def export_formats():
# YOLOv5 export formats
x = [
['PyTorch', '-', '.pt', True, True],
['TorchScript', 'torchscript', '.torchscript', True, True],
['ONNX', 'onnx', '.onnx', True, True],
['OpenVINO', 'openvino', '_openvino_model', True, False],
['TensorRT', 'engine', '.engine', False, True],
['CoreML', 'coreml', '.mlmodel', True, False],
['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
['TensorFlow GraphDef', 'pb', '.pb', True, True],
['TensorFlow Lite', 'tflite', '.tflite', True, False],
['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
['TensorFlow.js', 'tfjs', '_web_model', False, False],
['PaddlePaddle', 'paddle', '_paddle_model', True, True],]
return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
def try_export(inner_func):
# YOLOv5 export decorator, i..e @try_export
inner_args = get_default_args(inner_func)
def outer_func(*args, **kwargs):
prefix = inner_args['prefix']
try:
with Profile() as dt:
f, model = inner_func(*args, **kwargs)
LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
return f, model
except Exception as e:
LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
return None, None
return outer_func
@try_export
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
# YOLOv5 TorchScript model export
LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
f = file.with_suffix('.torchscript')
ts = torch.jit.trace(model, im, strict=False)
d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}
extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
else:
ts.save(str(f), _extra_files=extra_files)
return f, None
@try_export
def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
check_requirements('onnx')
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={
'images': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,3,640,640)
'output': {
0: 'batch',
1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
# Simplify
if simplify:
try:
cuda = torch.cuda.is_available()
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
return f, model_onnx
@try_export
def export_openvino(file, metadata, half, prefix=colorstr('OpenVINO:')):
# YOLOv5 OpenVINO export
check_requirements('openvino-dev') # requires openvino-dev: https://pypi.org/project/openvino-dev/
import openvino.inference_engine as ie
LOGGER.info(f'\n{prefix} starting export with openvino {ie.__version__}...')
f = str(file).replace('.pt', f'_openvino_model{os.sep}')
cmd = f"mo --input_model {file.with_suffix('.onnx')} --output_dir {f} --data_type {'FP16' if half else 'FP32'}"
subprocess.run(cmd.split(), check=True, env=os.environ) # export
yaml_save(Path(f) / file.with_suffix('.yaml').name, metadata) # add metadata.yaml
return f, None
@try_export
def export_paddle(model, im, file, metadata, prefix=colorstr('PaddlePaddle:')):
# YOLOv5 Paddle export
check_requirements(('paddlepaddle', 'x2paddle'))
import x2paddle
from x2paddle.convert import pytorch2paddle
LOGGER.info(f'\n{prefix} starting export with X2Paddle {x2paddle.__version__}...')
f = str(file).replace('.pt', f'_paddle_model{os.sep}')
pytorch2paddle(module=model, save_dir=f, jit_type='trace', input_examples=[im]) # export
yaml_save(Path(f) / file.with_suffix('.yaml').name, metadata) # add metadata.yaml
return f, None
@try_export
def export_coreml(model, im, file, int8, half, prefix=colorstr('CoreML:')):
# YOLOv5 CoreML export
check_requirements('coremltools')
import coremltools as ct
LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
f = file.with_suffix('.mlmodel')
ts = torch.jit.trace(model, im, strict=False) # TorchScript model
ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
bits, mode = (8, 'kmeans_lut') if int8 else (16, 'linear') if half else (32, None)
if bits < 32:
if platform.system() == 'Darwin': # quantization only supported on macOS
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=DeprecationWarning) # suppress numpy==1.20 float warning
ct_model = ct.models.neural_network.quantization_utils.quantize_weights(ct_model, bits, mode)
else:
print(f'{prefix} quantization only supported on macOS, skipping...')
ct_model.save(f)
return f, ct_model
@try_export
def export_engine(model, im, file, half, dynamic, simplify, workspace=4, verbose=False, prefix=colorstr('TensorRT:')):
# YOLOv5 TensorRT export https://developer.nvidia.com/tensorrt
assert im.device.type != 'cpu', 'export running on CPU but must be on GPU, i.e. `python export.py --device 0`'
try:
import tensorrt as trt
except Exception:
if platform.system() == 'Linux':
check_requirements('nvidia-tensorrt', cmds='-U --index-url https://pypi.ngc.nvidia.com')
import tensorrt as trt
if trt.__version__[0] == '7': # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
grid = model.model[-1].anchor_grid
model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid]
export_onnx(model, im, file, 12, False, dynamic, simplify) # opset 12
model.model[-1].anchor_grid = grid
else: # TensorRT >= 8
check_version(trt.__version__, '8.0.0', hard=True) # require tensorrt>=8.0.0
export_onnx(model, im, file, 13, False, dynamic, simplify) # opset 13
onnx = file.with_suffix('.onnx')
LOGGER.info(f'\n{prefix} starting export with TensorRT {trt.__version__}...')
assert onnx.exists(), f'failed to export ONNX file: {onnx}'
f = file.with_suffix('.engine') # TensorRT engine file
logger = trt.Logger(trt.Logger.INFO)
if verbose:
logger.min_severity = trt.Logger.Severity.VERBOSE
builder = trt.Builder(logger)
config = builder.create_builder_config()
config.max_workspace_size = workspace * 1 << 30
# config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace << 30) # fix TRT 8.4 deprecation notice
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
if not parser.parse_from_file(str(onnx)):
raise RuntimeError(f'failed to load ONNX file: {onnx}')
inputs = [network.get_input(i) for i in range(network.num_inputs)]
outputs = [network.get_output(i) for i in range(network.num_outputs)]
LOGGER.info(f'{prefix} Network Description:')
for inp in inputs:
LOGGER.info(f'{prefix}\tinput "{inp.name}" with shape {inp.shape} and dtype {inp.dtype}')
for out in outputs:
LOGGER.info(f'{prefix}\toutput "{out.name}" with shape {out.shape} and dtype {out.dtype}')
if dynamic:
if im.shape[0] <= 1:
LOGGER.warning(f"{prefix}WARNING: --dynamic model requires maximum --batch-size argument")
profile = builder.create_optimization_profile()
for inp in inputs:
profile.set_shape(inp.name, (1, *im.shape[1:]), (max(1, im.shape[0] // 2), *im.shape[1:]), im.shape)
config.add_optimization_profile(profile)
LOGGER.info(f'{prefix} building FP{16 if builder.platform_has_fast_fp16 and half else 32} engine in {f}')
if builder.platform_has_fast_fp16 and half:
config.set_flag(trt.BuilderFlag.FP16)
with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
t.write(engine.serialize())
return f, None
@try_export
def export_saved_model(model,
im,
file,
dynamic,
tf_nms=False,
agnostic_nms=False,
topk_per_class=100,
topk_all=100,
iou_thres=0.45,
conf_thres=0.25,
keras=False,
prefix=colorstr('TensorFlow SavedModel:')):
# YOLOv5 TensorFlow SavedModel export
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
from models.tf import TFModel
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
f = str(file).replace('.pt', '_saved_model')
batch_size, ch, *imgsz = list(im.shape) # BCHW
tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
im = tf.zeros((batch_size, *imgsz, ch)) # BHWC order for TensorFlow
_ = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
inputs = tf.keras.Input(shape=(*imgsz, ch), batch_size=None if dynamic else batch_size)
outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
keras_model = tf.keras.Model(inputs=inputs, outputs=outputs)
keras_model.trainable = False
keras_model.summary()
if keras:
keras_model.save(f, save_format='tf')
else:
spec = tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype)
m = tf.function(lambda x: keras_model(x)) # full model
m = m.get_concrete_function(spec)
frozen_func = convert_variables_to_constants_v2(m)
tfm = tf.Module()
tfm.__call__ = tf.function(lambda x: frozen_func(x)[:4] if tf_nms else frozen_func(x)[0], [spec])
tfm.__call__(im)
tf.saved_model.save(tfm,
f,
options=tf.saved_model.SaveOptions(experimental_custom_gradients=False) if check_version(
tf.__version__, '2.6') else tf.saved_model.SaveOptions())
return f, keras_model
@try_export
def export_pb(keras_model, file, prefix=colorstr('TensorFlow GraphDef:')):
# YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
f = file.with_suffix('.pb')
m = tf.function(lambda x: keras_model(x)) # full model
m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
frozen_func = convert_variables_to_constants_v2(m)
frozen_func.graph.as_graph_def()
tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
return f, None
@try_export
def export_tflite(keras_model, im, file, int8, data, nms, agnostic_nms, prefix=colorstr('TensorFlow Lite:')):
# YOLOv5 TensorFlow Lite export
import tensorflow as tf
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
batch_size, ch, *imgsz = list(im.shape) # BCHW
f = str(file).replace('.pt', '-fp16.tflite')
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
converter.target_spec.supported_types = [tf.float16]
converter.optimizations = [tf.lite.Optimize.DEFAULT]
if int8:
from models.tf import representative_dataset_gen
dataset = LoadImages(check_dataset(check_yaml(data))['train'], img_size=imgsz, auto=False)
converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib=100)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
converter.inference_input_type = tf.uint8 # or tf.int8
converter.inference_output_type = tf.uint8 # or tf.int8
converter.experimental_new_quantizer = True
f = str(file).replace('.pt', '-int8.tflite')
if nms or agnostic_nms:
converter.target_spec.supported_ops.append(tf.lite.OpsSet.SELECT_TF_OPS)
tflite_model = converter.convert()
open(f, "wb").write(tflite_model)
return f, None
@try_export
def export_edgetpu(file, prefix=colorstr('Edge TPU:')):
# YOLOv5 Edge TPU export https://coral.ai/docs/edgetpu/models-intro/
cmd = 'edgetpu_compiler --version'
help_url = 'https://coral.ai/docs/edgetpu/compiler/'
assert platform.system() == 'Linux', f'export only supported on Linux. See {help_url}'
if subprocess.run(f'{cmd} >/dev/null', shell=True).returncode != 0:
LOGGER.info(f'\n{prefix} export requires Edge TPU compiler. Attempting install from {help_url}')
sudo = subprocess.run('sudo --version >/dev/null', shell=True).returncode == 0 # sudo installed on system
for c in (
'curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -',
'echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list',
'sudo apt-get update', 'sudo apt-get install edgetpu-compiler'):
subprocess.run(c if sudo else c.replace('sudo ', ''), shell=True, check=True)
ver = subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1]
LOGGER.info(f'\n{prefix} starting export with Edge TPU compiler {ver}...')
f = str(file).replace('.pt', '-int8_edgetpu.tflite') # Edge TPU model
f_tfl = str(file).replace('.pt', '-int8.tflite') # TFLite model
cmd = f"edgetpu_compiler -s -d -k 10 --out_dir {file.parent} {f_tfl}"
subprocess.run(cmd.split(), check=True)
return f, None
@try_export
def export_tfjs(file, prefix=colorstr('TensorFlow.js:')):
# YOLOv5 TensorFlow.js export
check_requirements('tensorflowjs')
import re
import tensorflowjs as tfjs
LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
f = str(file).replace('.pt', '_web_model') # js dir
f_pb = file.with_suffix('.pb') # *.pb path
f_json = f'{f}/model.json' # *.json path
cmd = f'tensorflowjs_converter --input_format=tf_frozen_model ' \
f'--output_node_names=Identity,Identity_1,Identity_2,Identity_3 {f_pb} {f}'
subprocess.run(cmd.split())
json = Path(f_json).read_text()
with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
subst = re.sub(
r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}}}', r'{"outputs": {"Identity": {"name": "Identity"}, '
r'"Identity_1": {"name": "Identity_1"}, '
r'"Identity_2": {"name": "Identity_2"}, '
r'"Identity_3": {"name": "Identity_3"}}}', json)
j.write(subst)
return f, None
@smart_inference_mode()
def run(
data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
weights=ROOT / 'yolov5s.pt', # weights path
imgsz=(640, 640), # image (height, width)
batch_size=1, # batch size
device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
include=('torchscript', 'onnx'), # include formats
half=False, # FP16 half-precision export
inplace=False, # set YOLOv5 Detect() inplace=True
train=False, # model.train() mode
keras=False, # use Keras
optimize=False, # TorchScript: optimize for mobile
int8=False, # CoreML/TF INT8 quantization
dynamic=False, # ONNX/TF/TensorRT: dynamic axes
simplify=False, # ONNX: simplify model
opset=12, # ONNX: opset version
verbose=False, # TensorRT: verbose log
workspace=4, # TensorRT: workspace size (GB)
nms=False, # TF: add NMS to model
agnostic_nms=False, # TF: add agnostic NMS to model
topk_per_class=100, # TF.js NMS: topk per class to keep
topk_all=100, # TF.js NMS: topk for all classes to keep
iou_thres=0.45, # TF.js NMS: IoU threshold
conf_thres=0.25, # TF.js NMS: confidence threshold
):
t = time.time()
include = [x.lower() for x in include] # to lowercase
fmts = tuple(export_formats()['Argument'][1:]) # --include arguments
flags = [x in include for x in fmts]
assert sum(flags) == len(include), f'ERROR: Invalid --include {include}, valid --include arguments are {fmts}'
jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle = flags # export booleans
file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights) # PyTorch weights
# Load PyTorch model
device = select_device(device)
if half:
assert device.type != 'cpu' or coreml, '--half only compatible with GPU export, i.e. use --device 0'
assert not dynamic, '--half not compatible with --dynamic, i.e. use either --half or --dynamic but not both'
model = attempt_load(weights, device=device, inplace=True, fuse=True) # load FP32 model
# Checks
imgsz *= 2 if len(imgsz) == 1 else 1 # expand
if optimize:
assert device.type == 'cpu', '--optimize not compatible with cuda devices, i.e. use --device cpu'
# Input
gs = int(max(model.stride)) # grid size (max stride)
imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
# Update model
model.train() if train else model.eval() # training mode = no Detect() layer grid construction
for k, m in model.named_modules():
if isinstance(m, Detect):
m.inplace = inplace
m.dynamic = dynamic
m.export = True
for _ in range(2):
y = model(im) # dry runs
if half and not coreml:
im, model = im.half(), model.half() # to FP16
shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
metadata = {'stride': int(max(model.stride)), 'names': model.names} # model metadata
LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} with output shape {shape} ({file_size(file):.1f} MB)")
# Exports
f = [''] * len(fmts) # exported filenames
warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
if jit: # TorchScript
f[0], _ = export_torchscript(model, im, file, optimize)
if engine: # TensorRT required before ONNX
f[1], _ = export_engine(model, im, file, half, dynamic, simplify, workspace, verbose)
if onnx or xml: # OpenVINO requires ONNX
f[2], _ = export_onnx(model, im, file, opset, train, dynamic, simplify)
if xml: # OpenVINO
f[3], _ = export_openvino(file, metadata, half)
if coreml: # CoreML
f[4], _ = export_coreml(model, im, file, int8, half)
if any((saved_model, pb, tflite, edgetpu, tfjs)): # TensorFlow formats
if int8 or edgetpu: # TFLite --int8 bug https://github.com/ultralytics/yolov5/issues/5707
check_requirements('flatbuffers==1.12') # required before `import tensorflow`
assert not tflite or not tfjs, 'TFLite and TF.js models must be exported separately, please pass only one type.'
assert not isinstance(model, ClassificationModel), 'ClassificationModel export to TF formats not yet supported.'
f[5], s_model = export_saved_model(model.cpu(),
im,
file,
dynamic,
tf_nms=nms or agnostic_nms or tfjs,
agnostic_nms=agnostic_nms or tfjs,
topk_per_class=topk_per_class,
topk_all=topk_all,
iou_thres=iou_thres,
conf_thres=conf_thres,
keras=keras)
if pb or tfjs: # pb prerequisite to tfjs
f[6], _ = export_pb(s_model, file)
if tflite or edgetpu:
f[7], _ = export_tflite(s_model, im, file, int8 or edgetpu, data=data, nms=nms, agnostic_nms=agnostic_nms)
if edgetpu:
f[8], _ = export_edgetpu(file)
if tfjs:
f[9], _ = export_tfjs(file)
if paddle: # PaddlePaddle
f[10], _ = export_paddle(model, im, file, metadata)
# Finish
f = [str(x) for x in f if x] # filter out '' and None
if any(f):
h = '--half' if half else '' # --half FP16 inference arg
LOGGER.info(f'\nExport complete ({time.time() - t:.1f}s)'
f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
f"\nDetect: python detect.py --weights {f[-1]} {h}"
f"\nValidate: python val.py --weights {f[-1]} {h}"
f"\nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', '{f[-1]}')"
f"\nVisualize: https://netron.app")
return f # return list of exported files/dirs
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--keras', action='store_true', help='TF: use Keras')
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')
parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
parser.add_argument('--include',
nargs='+',
default=['torchscript'],
help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs')
opt = parser.parse_args()
print_args(vars(opt))
return opt
def main(opt):
for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
写的很清楚了,
step1:pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
step2:
python export.py --weights weights/yolov5x6.pt --include onnx torchscript engine
遇到报错:
TensorRT: export failure 0.0s: export running on CPU but must be on GPU, i.e. python export.py --device 0
那就加个参数呗, python export.py --weights weights/yolov5x6.pt --include onnx torchscript engine --device 0 继续执行
torchscript 和onnx的尾缀的模型输出了,但依然有报错:
TorchScript: starting export with torch 1.12.1…
TorchScript: export success 3.5s, saved as weights\yolov5x6.torchscript (537.8 MB)
TensorRT: export failure 0.0s: No module named ‘tensorrt’
全流程也作为贴出来了
(base) C:\Users\HP\Desktop\code\yolov5-master>python export.py --weights weights/yolov5x6.pt --include onnx torchscript engine
export: data=C:\Users\HP\Desktop\code\yolov5-master\data\coco128.yaml, weights=['weights/yolov5x6.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx', 'torchscript', 'engine']
YOLOv5 2022-9-14 Python-3.9.12 torch-1.12.1 CPU
Fusing layers...
YOLOv5x6 summary: 574 layers, 140730220 parameters, 0 gradients
PyTorch: starting from weights\yolov5x6.pt with output shape (1, 25500, 85) (269.6 MB)
TorchScript: starting export with torch 1.12.1...
TorchScript: export success 9.6s, saved as weights\yolov5x6.torchscript (537.8 MB)
TensorRT: export failure 0.0s: export running on CPU but must be on GPU, i.e. `python export.py --device 0`
ONNX: starting export with onnx 1.12.0...
ONNX: export success 14.8s, saved as weights\yolov5x6.onnx (537.3 MB)
Export complete (30.9s)
Results saved to C:\Users\HP\Desktop\code\yolov5-master\weights
Detect: python detect.py --weights weights\yolov5x6.onnx
Validate: python val.py --weights weights\yolov5x6.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'weights\yolov5x6.onnx')
Visualize: https://netron.app
(base) C:\Users\HP\Desktop\code\yolov5-master>python export.py --weights weights/yolov5x6.pt --include onnx torchscript engine --device 0
export: data=C:\Users\HP\Desktop\code\yolov5-master\data\coco128.yaml, weights=['weights/yolov5x6.pt'], imgsz=[640, 640], batch_size=1, device=0, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx', 'torchscript', 'engine']
YOLOv5 2022-9-14 Python-3.9.12 torch-1.12.1 CUDA:0 (NVIDIA GeForce RTX 3070 Laptop GPU, 8192MiB)
Fusing layers...
YOLOv5x6 summary: 574 layers, 140730220 parameters, 0 gradients
PyTorch: starting from weights\yolov5x6.pt with output shape (1, 25500, 85) (269.6 MB)
TorchScript: starting export with torch 1.12.1...
TorchScript: export success 3.5s, saved as weights\yolov5x6.torchscript (537.8 MB)
TensorRT: export failure 0.0s: No module named 'tensorrt'
ONNX: starting export with onnx 1.12.0...
ONNX: export success 16.9s, saved as weights\yolov5x6.onnx (537.3 MB)
Export complete (29.7s)
Results saved to C:\Users\HP\Desktop\code\yolov5-master\weights
Detect: python detect.py --weights weights\yolov5x6.onnx
Validate: python val.py --weights weights\yolov5x6.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'weights\yolov5x6.onnx')
Visualize: https://netron.app
安装tensorTR要小心了,需要匹配 cuda版本和cudnn版本
#查看cuda版本
nvcc -V
C:\Users\HP\Downloads>nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Fri_Dec_17_18:28:54_Pacific_Standard_Time_2021
Cuda compilation tools, release 11.6, V11.6.55
Build cuda_11.6.r11.6/compiler.30794723_0
# 查看cudnn版本
# 这个比较费劲,参考:http://www.tudoupe.com/help/202221606.html
# 我的和他的略有区别

总之,是找到cudnn的安装目录,找到它的版本信息.这里我也要抛个问题,pytorch 安装的时候,自带了cudnn,可以不安装cuda 和 cudnn,一键安装pytorch就可以用到GPU版了,但应该不可以转tensorRT, 因为这样安装的是阉割版的,不是全功能版本的.懂的大神可以下面留言回答一下
所以我的版本是cudnn8.5.0
到这里下载对应的tensorRT:https://developer.nvidia.com/nvidia-tensorrt-download
还没有8.5.0 所以我选了个最近的,不一定好用,继续往下走吧,本来都装好了,上周ssd坏了,环境全没了,所以这次要记录下来.
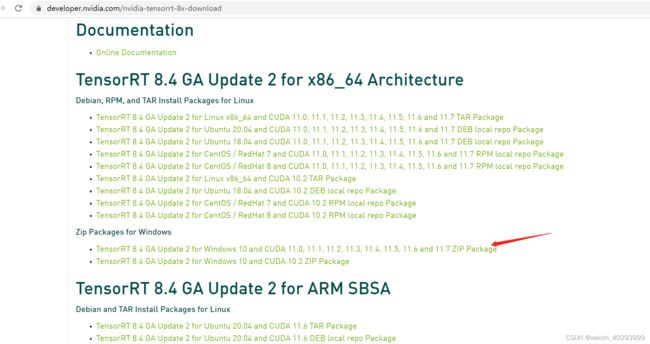
TensorRT 8.4 GA Update 2 for Windows 10 and CUDA 11.0, 11.1, 11.2, 11.3, 11.4, 11.5, 11.6 and 11.7 ZIP Package
这里插一句,tensorRT 还是onxx 只能转换对应显卡类型的模型,比如本机是3070的,那转化出来的也只能在3070上用. 我的理解是这样的,欢迎大神指正啊.
安装指引看这里:
https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-zip

解压后,进入C:\Users\HP\Downloads\TensorRT-8.4.3.1\python这个目录
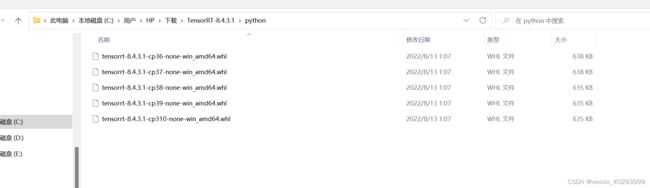
选择对应的python版本
一键安装:python.exe -m pip install tensorrt-*-cp3x-none-win_amd64.whl
(base) C:\Users\HP\Downloads\TensorRT-8.4.3.1\python>python -m pip install tensorrt-8.4.3.1-cp39-none-win_amd64.whl
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Processing c:\users\hp\downloads\tensorrt-8.4.3.1\python\tensorrt-8.4.3.1-cp39-none-win_amd64.whl
Installing collected packages: tensorrt
Successfully installed tensorrt-8.4.3.1
(base) C:\Users\HP\Downloads\TensorRT-8.4.3.1\python>
然后继续执行 export脚本命令
python export.py --weights weights/yolov5x6.pt --include onnx engine torchscript --device 0
报错:
TensorRT: export failure 0.0s: Could not find: nvinfer.dll. Is it on your PATH?
Note: Paths searched were:
['C:\\Users\\HP\\AppData\\Roaming\\Python\\Python39\\site-packages\\cv2\\../../x64/vc14/bin', 'C:\\ProgramData\\Anaconda3', 'C:\\ProgramData\\Anaconda3\\Library\\mingw-w64\\bin', 'C:\\ProgramData\\Anaconda3\\Library\\usr\\bin', 'C:\\ProgramData\\Anaconda3\\Library\\bin', 'C:\\ProgramData\\Anaconda3\\Scripts', 'C:\\ProgramData\\Anaconda3\\bin', 'C:\\ProgramData\\Anaconda3\\condabin', 'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.6\\bin', 'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.6\\libnvvp', 'C:\\Windows\\system32', 'C:\\Windows', 'C:\\Windows\\System32\\Wbem', 'C:\\Windows\\System32\\WindowsPowerShell\\v1.0', 'C:\\Windows\\System32\\OpenSSH', 'C:\\Program Files\\Git\\cmd', 'C:\\Program Files\\NVIDIA Corporation\\Nsight Compute 2022.1.0', 'C:\\Program Files (x86)\\NVIDIA Corporation\\PhysX\\Common', 'C:\\Program Files\\NVIDIA Corporation\\NVIDIA NvDLISR', 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\VC\\Tools\\MSVC\\14.16.27023\\bin\\HostX64\\arm64', 'C:\\Program Files\\dotnet', '.', 'C:\\Program Files\\Docker\\Docker\\resources\\bin', 'C:\\ProgramData\\DockerDesktop\\version-bin', 'C:\\Users\\HP\\AppData\\Local\\Microsoft\\WindowsApps', 'C:\\Program Files\\JetBrains\\PyCharm 2022.2.1\\bin', '.', 'C:\\Program Files\\JetBrains\\PhpStorm 2022.2.1\\bin', '.', 'C:\\Users\\HP\\AppData\\Local\\Programs\\Microsoft VS Code\\bin', 'C:\\ProgramData\\Anaconda3\\Library\\bin', 'C:\\Users\\HP\\.dotnet\\tools']
它在哪,应该把他设置到环境变量,everything 真是好用…

设置到环境变量,继续执行依然报错
重启后再次执行. 终于成功了,输出也比前两次多多了, 这里的问题是 它是把超参数固化下来了么?
比如:imgsz=[640, 640], batch_size=1, device=0, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25,
我猜测是的,可以再换一组试一下看看效果。地下也会列举出对比,。
(base) C:\Users\HP\Desktop\code\yolov5-master>python export.py --weights weights/yolov5x6.pt --include onnx engine torchscript --device 0
export: data=C:\Users\HP\Desktop\code\yolov5-master\data\coco128.yaml, weights=['weights/yolov5x6.pt'], imgsz=[640, 640], batch_size=1, device=0, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx', 'engine', 'torchscript']
YOLOv5 2022-9-14 Python-3.9.12 torch-1.12.1 CUDA:0 (NVIDIA GeForce RTX 3070 Laptop GPU, 8192MiB)
Fusing layers...
YOLOv5x6 summary: 574 layers, 140730220 parameters, 0 gradients
PyTorch: starting from weights\yolov5x6.pt with output shape (1, 25500, 85) (269.6 MB)
TorchScript: starting export with torch 1.12.1...
TorchScript: export success 3.4s, saved as weights\yolov5x6.torchscript (537.8 MB)
ONNX: starting export with onnx 1.12.0...
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
WARNING: The shape inference of prim::Constant type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function.
ONNX: export success 14.8s, saved as weights\yolov5x6.onnx (537.3 MB)
TensorRT: starting export with TensorRT 8.4.3.1...
[09/15/2022-03:19:46] [TRT] [I] [MemUsageChange] Init CUDA: CPU +250, GPU +0, now: CPU 14057, GPU 3793 (MiB)
[09/15/2022-03:19:48] [TRT] [I] [MemUsageChange] Init builder kernel library: CPU +343, GPU +102, now: CPU 14625, GPU 3895 (MiB)
C:\Users\HP\Desktop\code\yolov5-master\export.py:267: DeprecationWarning: Use set_memory_pool_limit instead.
config.max_workspace_size = workspace * 1 << 30
[libprotobuf WARNING E:\Perforce\rboissel_devdt_windows\sw\gpgpu\MachineLearning\DIT\dev\nvmake\externals\protobuf\3.0.0\src\google\protobuf\io\coded_stream.cc:604] Reading dangerously large protocol message. If the message turns out to be larger than 2147483647 bytes, parsing will be halted for security reasons. To increase the limit (or to disable these warnings), see CodedInputStream::SetTotalBytesLimit() in google/protobuf/io/coded_stream.h.
etTotalBytesLimit() in google/protobuf/io/coded_stream.h.[libprotobuf WARNING E:\Perforce\rboissel_devdt_windows\sw\gpgpu\MachineLearning\DIT\dev\nvmake\externals\protobuf\3.0.0\src\google\protobuf\io\coded_stream.cc:81] The total number of bytes read was 563409864
[09/15/2022-03:19:49] [TRT] [W] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
TensorRT: Network Description:
TensorRT: input "images" with shape (1, 3, 640, 640) and dtype DataType.FLOAT
TensorRT: output "output" with shape (1, 25500, 85) and dtype DataType.FLOAT
TensorRT: building FP32 engine in weights\yolov5x6.engine
C:\Users\HP\Desktop\code\yolov5-master\export.py:295: DeprecationWarning: Use build_serialized_network instead.
with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
[09/15/2022-03:19:50] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 14511, GPU 3903 (MiB)
[09/15/2022-03:19:50] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 14511, GPU 3911 (MiB)
[09/15/2022-03:19:50] [TRT] [W] TensorRT was linked against cuDNN 8.4.1 but loaded cuDNN 8.3.2[09/15/2022-03:19:50] [TRT] [I] Local timing cache in use. Profiling results in this builder pass will not be stored.
[09/15/2022-03:21:02] [TRT] [I] Some tactics do not have sufficient workspace memory to run. Increasing workspace size will enable more tactics, please check verbose output for requested sizes.
[09/15/2022-03:22:54] [TRT] [I] Detected 1 inputs and 5 output network tensors.
[09/15/2022-03:22:55] [TRT] [I] Total Host Persistent Memory: 380960
[09/15/2022-03:22:55] [TRT] [I] Total Device Persistent Memory: 2008576
[09/15/2022-03:22:55] [TRT] [I] Total Scratch Memory: 3994112
[09/15/2022-03:22:55] [TRT] [I] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 0 MiB, GPU 0 MiB
[09/15/2022-03:22:56] [TRT] [I] [BlockAssignment] Algorithm ShiftNTopDown took 388.287ms to assign 9 blocks to 447 nodes requiring 85299200 bytes.
[09/15/2022-03:22:56] [TRT] [I] Total Activation Memory: 85299200
[09/15/2022-03:22:56] [TRT] [I] [MemUsageChange] Init cuDNN: CPU -2, GPU +10, now: CPU 15384, GPU 4561 (MiB)
[09/15/2022-03:22:56] [TRT] [W] TensorRT was linked against cuDNN 8.4.1 but loaded cuDNN 8.3.2
[09/15/2022-03:22:56] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +0, GPU +0, now: CPU 0, GPU 0 (MiB)
[09/15/2022-03:22:56] [TRT] [W] The getMaxBatchSize() function should not be used with an engine built from a network created with NetworkDefinitionCreationFlag::kEXPLICIT_BATCH flag. This function will always return 1.
[09/15/2022-03:22:56] [TRT] [W] The getMaxBatchSize() function should not be used with an engine built from a network created with NetworkDefinitionCreationFlag::kEXPLICIT_BATCH flag. This function will always return 1.
TensorRT: export success 208.5s, saved as weights\yolov5x6.engine (638.1 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success 16.8s, saved as weights\yolov5x6.onnx (537.3 MB)
Export complete (237.1s)
Results saved to C:\Users\HP\Desktop\code\yolov5-master\weights
Detect: python detect.py --weights weights\yolov5x6.onnx
Validate: python val.py --weights weights\yolov5x6.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'weights\yolov5x6.onnx')
Visualize: https://netron.app
这样就可以对比了:
opt = parse_opt()
print(opt)
device = "CUDA:0"
weights = "weights/yolov5x6.pt"
source = 'data/images/bus.jpg'
dnn =False
data = 'data/coco128.yaml'
half =False
# Load model
device = select_device(device)
print(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
opt = {
'weights': weights,
'source': source,
'data': data,
'imgsz': [640, 640],
'conf_thres': 0.25,
'iou_thres': 0.45,
'max_det': 1000,
'device': device,
'view_img': False,
'save_txt': True,
'save_conf': False,
'save_crop': False,
'nosave': False,
'classes': None,
'agnostic_nms': False,
'augment': False,
'visualize': False,
'update': False,
'project': 'runs/detect',
'name': 'exp',
'exist_ok': False,
'line_thickness': 3,
'hide_labels': False,
'hide_conf': False,
'half': half,
'dnn': dnn,
'vid_stride': 1,
}
start = time.time()
for i in range(10):
main(opt)
print("{} used_time:{}".format(weights,time.time()-start))
device = select_device(device)
print(device)
weights = "weights/yolov5x6.engine"
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
opt = {
'weights': weights,
'source': source,
'data': data,
'imgsz': [640, 640],
'conf_thres': 0.25,
'iou_thres': 0.45,
'max_det': 1000,
'device': device,
'view_img': False,
'save_txt': True,
'save_conf': False,
'save_crop': False,
'nosave': False,
'classes': None,
'agnostic_nms': False,
'augment': False,
'visualize': False,
'update': False,
'project': 'runs/detect',
'name': 'exp',
'exist_ok': False,
'line_thickness': 3,
'hide_labels': False,
'hide_conf': False,
'half': half,
'dnn': dnn,
'vid_stride': 1,
}
device = select_device(device)
print(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
start = time.time()
for i in range(10):
main(opt)
print("{} used_time:{}".format(weights,time.time()-start))
device = select_device(device)
print(device)
weights = "weights/yolov5x6.onnx"
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
opt = {
'weights': weights,
'source': source,
'data': data,
'imgsz': [640, 640],
'conf_thres': 0.25,
'iou_thres': 0.45,
'max_det': 1000,
'device': device,
'view_img': False,
'save_txt': True,
'save_conf': False,
'save_crop': False,
'nosave': False,
'classes': None,
'agnostic_nms': False,
'augment': False,
'visualize': False,
'update': False,
'project': 'runs/detect',
'name': 'exp',
'exist_ok': False,
'line_thickness': 3,
'hide_labels': False,
'hide_conf': False,
'half': half,
'dnn': dnn,
'vid_stride': 1,
}
device = select_device(device)
print(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
start = time.time()
for i in range(10):
main(opt)
print("{} used_time:{}".format(weights,time.time()-start))
half = false
weights/yolov5x6.pt used_time:1.3140676021575928 30ms/pic
weights/yolov5x6.engine used_time:1.1595304012298584 27 ms/pic
weights/yolov5x6.onnx used_time:2.5584616661071777 50ms/pic
weights/yolov5x6.torchscript used_time:5.8778886795043945 39 ms/pic
half = True
weights/yolov5x6.pt used_time:1.7578420639038086
weights/yolov5x6.engine used_time:1.1905784606933594
onnx模型报错,因为精度不匹配
onnxruntime.capi.onnxruntime_pybind11_state.InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Unexpected input data type. Actual: (tensor(float16)) , expected: (tensor(float))
weights/yolov5x6.pt used_time:1.4158804416656494
weights/yolov5x6.engine used_time:1.2071385383605957
weights/yolov5x6.torchscript used_time:4.896728754043579
torchscript不灵光是因为有一个warning:
cuda:0
Loading weights\yolov5x6.torchscript for TorchScript inference...
C:\ProgramData\Anaconda3\lib\site-packages\torch\nn\modules\module.py:1130: UserWarning: FALLBACK path has been taken inside: torch::jit::fuser::cuda::runCudaFusionGroup. This is an indication that codegen Failed for some reason.
To debug try disable codegen fallback path via setting the env variable `export PYTORCH_NVFUSER_DISABLE=fallback`
(Triggered internally at C:\cb\pytorch_1000000000000\work\torch\csrc\jit\codegen\cuda\manager.cpp:334.)
return forward_call(*input, **kwargs)
image 1/1 C:\Users\HP\Desktop\code\yolov5-master\data\images\bus.jpg: 640x640 4 persons, 1 bus, 190.0ms
Speed: 2.0ms pre-process, 190.0ms inference, 2.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp218
1 labels saved to runs\detect\exp218\labels
image 1/1 C:\Users\HP\Desktop\code\yolov5-master\data\images\bus.jpg: 640x640 4 persons, 1 bus, 25.0ms
Speed: 0.0ms pre-process, 25.0ms inference, 1.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp219
1 labels saved to runs\detect\exp219\labels
image 1/1 C:\Users\HP\Desktop\code\yolov5-master\data\images\bus.jpg: 640x640 4 persons, 1 bus, 22.0ms
Speed: 0.0ms pre-process, 22.0ms inference, 1.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp220
1 labels saved to runs\detect\exp220\labels
image 1/1 C:\Users\HP\Desktop\code\yolov5-master\data\images\bus.jpg: 640x640 4 persons, 1 bus, 24.2ms
Speed: 0.0ms pre-process, 24.2ms inference, 1.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp221

这是第一次安装成功后的结论。 GPU下 engine(tensorRT)最牛, torchscript 次之, pt, 然后onnx
但第一次安装的时候,onnx没有报warning。 估计当时的版本也不一样, 我记得还有个bug(是解析engine或者onnx模型的时候),是代码顺序的问题,顺便调整了。
当时还量化了 64位 和 32位的 以及GPU和CPU版本的, 等我完全弄明白了,再回来补充!!
又在另外一台2080TI上安装了,
查看cuda版本
(py38_18) [jianming_ge@localhost shapan_alg]$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Wed_Oct_23_19:24:38_PDT_2019
Cuda compilation tools, release 10.2, V10.2.89
cudnn版本, 我的版本信息在这里, 可以全局搜一下这个文件。
cat /usr/local/cuda/include/cudnn_version.h
/**
* \file: The master cuDNN version file.
*/
#ifndef CUDNN_VERSION_H_
#define CUDNN_VERSION_H_
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 0
#define CUDNN_PATCHLEVEL 5
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
8.0.5的cudnn
有的在这个文件下,估计和安装的版本有关
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
或者 在这里
cat /usr/local/cuda/version.txt
CUDA Version 10.2.89
在这里下载对应版本的tessort,需要登陆,nvida还挺麻烦
https://developer.nvidia.com/nvidia-tensorrt-download
原始:.pt gpu 版本
YOLOv5m6 summary: 378 layers, 35704908 parameters, 0 gradients, 49.9 GFLOPs
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 12.3ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 10.9ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 10.9ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 10.9ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 11.0ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 384x640 2 persons, 1 tie, 12.3ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 384x640 2 persons, 1 tie, 11.1ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 384x640 2 persons, 1 tie, 11.2ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 384x640 2 persons, 1 tie, 11.2ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 384x640 2 persons, 1 tie, 11.2ms
Speed: 0.4ms pre-process, 11.3ms inference, 1.1ms NMS per image at shape (1, 3, 640, 640)
tensorrt 肯定得是GPU版的啊,cpu的又不支持 float64版本
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 9.4ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 9.3ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 9.3ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 9.3ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 9.3ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 9.3ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 9.3ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 9.3ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 9.3ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 9.3ms
Speed: 0.6ms pre-process, 9.3ms inference, 1.2ms NMS per image at shape (1, 3, 640, 640)
tenssort GPU float 32 版本
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/gpu_half/yolov5m6.engine, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11019MiB)
Loading weights/gpu_half/yolov5m6.engine for TensorRT inference...
[09/22/2022-16:09:31] [TRT] [I] [MemUsageChange] Init CUDA: CPU +290, GPU +0, now: CPU 368, GPU 296 (MiB)
[09/22/2022-16:09:31] [TRT] [I] Loaded engine size: 71 MiB
[09/22/2022-16:09:31] [TRT] [W] TensorRT was linked against cuBLAS/cuBLAS LT 10.2.3 but loaded cuBLAS/cuBLAS LT 10.2.2
[09/22/2022-16:09:31] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +170, GPU +70, now: CPU 622, GPU 438 (MiB)
[09/22/2022-16:09:31] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +139, GPU +90, now: CPU 761, GPU 528 (MiB)
[09/22/2022-16:09:31] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +69, now: CPU 0, GPU 69 (MiB)
[09/22/2022-16:09:31] [TRT] [W] TensorRT was linked against cuBLAS/cuBLAS LT 10.2.3 but loaded cuBLAS/cuBLAS LT 10.2.2
[09/22/2022-16:09:31] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +1, GPU +10, now: CPU 689, GPU 520 (MiB)
[09/22/2022-16:09:31] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 689, GPU 528 (MiB)
[09/22/2022-16:09:31] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +94, now: CPU 0, GPU 163 (MiB)
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 3.8ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 3.8ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 3.8ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 3.8ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 3.8ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 3.8ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 3.8ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 3.8ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 3.8ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 3.8ms
Speed: 0.6ms pre-process, 3.8ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp52
torchscript GPU
Loading weights/gpu/yolov5m6.torchscript for TorchScript inference...
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 12.8ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 12.8ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 12.8ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 12.8ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 12.8ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 12.8ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 12.8ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 12.8ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 12.8ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 12.8ms
Speed: 0.6ms pre-process, 12.8ms inference, 1.2ms NMS per image at shape (1, 3, 640, 640)
onnx 报错搁置,文章的后面会给出解决方案
下面是CPU下的表现
.pt
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/yolov5m6.pt, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=cpu, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CPU
Fusing layers...
YOLOv5m6 summary: 378 layers, 35704908 parameters, 0 gradients, 49.9 GFLOPs
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 641.9ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 588.6ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 1104.4ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 752.0ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x512 4 persons, 1 bus, 1 traffic light, 656.8ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 384x640 2 persons, 1 tie, 563.8ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 384x640 2 persons, 1 tie, 551.9ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 384x640 2 persons, 1 tie, 613.0ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 384x640 2 persons, 1 tie, 725.9ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 384x640 2 persons, 1 tie, 649.6ms
Speed: 4.8ms pre-process, 684.8ms inference, 1.4ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp13
.torchscript
Loading weights/cpu/yolov5m6.torchscript for TorchScript inference...
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 1108.0ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 958.8ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 1386.1ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 1047.3ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 765.5ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 803.2ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 1010.2ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 898.4ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 1198.4ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x6
Speed: 5.2ms pre-process, 1028.4ms inference, 1.7ms NMS per image at shape (1, 3, 640, 640)
.onnx
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/cpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=cpu, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CPU
Loading weights/cpu/yolov5m6.onnx for ONNX Runtime inference...
--=== CPUExecutionProvider --=== ['CPUExecutionProvider']
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 119.8ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 104.3ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 101.3ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 100.8ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 101.9ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 100.6ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 100.5ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 100.3ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 100.2ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 102.2ms
Speed: 7.3ms pre-process, 103.2ms inference, 1.1ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp17
ONXX 在 GPU下报错
onnx 报错搁置 也就是以上报错搁置的部分
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
2022-09-22 09:10:34.666467785 [W:onnxruntime:Default, onnxruntime_pybind_state.cc:566 CreateExecutionProviderInstance] Failed to create CUDAExecutionProvider. Please reference https://onnxruntime.ai/docs/reference/execution-providers/CUDA-ExecutionProvider.html#requirements to ensure all dependencies are met.
解决方案指引:
https://github.com/microsoft/onnxruntime/issues/11323
有人说, onnxruntime-gpu 同时支持CPU和GPU 若是同时安装了onnxruntime-gpu 和onnxruntime 就会使其找不到正确版本,
于是pip uninstall onnxruntime,继续运行依然报错,这次报错的更彻底,找不到库了,说明之前warning的部分是找不到gpu的版本,而强制使用了cpu版本
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/gpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11019MiB)
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
Traceback (most recent call last):
File "detect.py", line 257, in <module>
main(opt)
File "detect.py", line 251, in main
run(**vars(opt))
File "/home/kevin_xie/yifeinfs/jianming_ge/miniconda3/envs/py38_18/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "detect.py", line 94, in run
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
File "/home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/models/common.py", line 361, in __init__
session = onnxruntime.InferenceSession(w, providers=providers)
AttributeError: module 'onnxruntime' has no attribute 'InferenceSession'
从这里找到对应的版本:
https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html

一键安装:
pip install onnxruntime-gpu==1.6
继续运行测试,一切正常
detect: weights=weights/gpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11019MiB)
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 21.3ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 20.5ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 21.4ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 20.6ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 20.9ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 20.6ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 21.0ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 20.8ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 20.7ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 20.4ms
Speed: 0.6ms pre-process, 20.8ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)
再验证下cpu版本的onnx灵不灵,之前已经把cpu的 卸载了
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/gpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=cpu, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CPU
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
requirements: YOLOv5 requirement "onnxruntime" not found, attempting AutoUpdate...
requirements: ❌ AutoUpdate skipped (offline)
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 154.2ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 137.3ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 130.4ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 135.8ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 138.7ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 147.1ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 145.5ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 219.0ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 150.5ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 130.8ms
Speed: 7.6ms pre-process, 148.9ms inference, 1.4ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp25
能跑,但是有warning,看样子issue上有个人说的,不太对,再次安装cpu版本的
Successfully uninstalled onnxruntime-1.11.1
(py38_18) [jianming_ge@localhost yolov5-master]$ pip install onnxruntime
Defaulting to user installation because normal site-packages is not writeable
Looking in indexes: http://mirrors.aliyun.com/pypi/simple/
Collecting onnxruntime
Downloading http://mirrors.aliyun.com/pypi/packages/fb/cf/8f9887e3ced610fb158e1eee82a45b5ea22c2c5f48519f0d06bfebd46c83/onnxruntime-1.12.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (5.5 MB)
|████████████████████████████████| 5.5 MB 151 kB/s
Requirement already satisfied: numpy>=1.21.0 in /home/jianming_ge/.local/lib/python3.8/site-packages (from onnxruntime) (1.22.0)
Requirement already satisfied: protobuf in /home/kevin_xie/yifeinfs/kevin_xie/miniconda3/envs/py38_18/lib/python3.8/site-packages (from onnxruntime) (3.18.1)
Requirement already satisfied: coloredlogs in /home/jianming_ge/.local/lib/python3.8/site-packages (from onnxruntime) (15.0.1)
Requirement already satisfied: flatbuffers in /home/jianming_ge/.local/lib/python3.8/site-packages (from onnxruntime) (2.0.7)
Requirement already satisfied: packaging in /home/kevin_xie/yifeinfs/kevin_xie/miniconda3/envs/py38_18/lib/python3.8/site-packages (from onnxruntime) (21.0)
Requirement already satisfied: sympy in /home/kevin_xie/yifeinfs/kevin_xie/miniconda3/envs/py38_18/lib/python3.8/site-packages (from onnxruntime) (1.9)
Requirement already satisfied: humanfriendly>=9.1 in /home/jianming_ge/.local/lib/python3.8/site-packages (from coloredlogs->onnxruntime) (10.0)
Requirement already satisfied: pyparsing>=2.0.2 in /home/kevin_xie/yifeinfs/kevin_xie/miniconda3/envs/py38_18/lib/python3.8/site-packages (from packaging->onnxruntime) (2.4.7)
Requirement already satisfied: mpmath>=0.19 in /home/kevin_xie/yifeinfs/kevin_xie/miniconda3/envs/py38_18/lib/python3.8/site-packages (from sympy->onnxruntime) (1.2.1)
Installing collected packages: onnxruntime
Successfully installed onnxruntime-1.12.1
再次验证 onnx cpu模型
time python detect.py
detect: weights=weights/gpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=cpu, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CPU
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 114.8ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 107.1ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 107.5ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 103.5ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 104.1ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 102.3ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 103.7ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 103.8ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 101.3ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 106.1ms
Speed: 7.3ms pre-process, 105.4ms inference, 2.0ms NMS per image at shape (1, 3, 640, 640)
onnx的simply参数,设置不设置效果几乎相同~!! 不推荐
onnx gpu 模型权重
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
/home/jianming_ge/.local/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py:54: UserWarning: Specified provider 'CUDAExecutionProvider' is not in available provider names.Available providers: 'CPUExecutionProvider'
warnings.warn(
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 129.8ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 109.7ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 107.1ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 105.8ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 107.4ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 105.3ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 107.0ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 106.4ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 105.8ms
错误又来了。。。。推理时间由原来的20ms变成了100ms 这就是cpu的速度啊。很明显没有用到gpu
然后我把cpu的也降级成1.6版本
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/gpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11019MiB)
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 167.5ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 233.9ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 169.6ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 175.5ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 371.7ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 178.9ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 170.0ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 166.9ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 168.5ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 188.5ms
Speed: 0.6ms pre-process, 199.1ms inference, 2.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp31
没有报错了,但是使用推理速度更慢
错误的根源在这里:

cup和gpu版本的onnxruntime 都叫onnxruntime, 所以gpu版本的或者cpu版本的就只能有一个生效了。
而且gpu版本的的确可以兼容cpu版本的。cpu的情况下,可能是1.6版本的要慢于1.12版本。这也就解释了100ms 和 160ms的差别。
既然找到了原因,那就尝试解决一下。
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/gpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=cpu, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CPU
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 117.0ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 108.6ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 99.1ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 112.5ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 102.9ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 102.6ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 128.3ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 101.3ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 101.6ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 104.0ms
Speed: 6.9ms pre-process, 107.8ms inference, 1.5ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp42
real 0m17.360s
user 0m50.387s
sys 0m5.702s


基本思路是GPU的重命名一下,然后根据报错信息一路改下去

地方不是很多。
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/gpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11019MiB)
Loading weights/gpu/yolov5m6.onnx for ONNX Runtime inference...
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 22.8ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 21.7ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 22.7ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 21.8ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 21.8ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 21.6ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 21.9ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 22.2ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 22.0ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 21.9ms
Speed: 0.6ms pre-process, 22.0ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp50
这样以来,GPU用的是1.6 推理速度20ms
cpu用的是1.12 推理速度是100ms
(py38_18) [jianming_ge@localhost yolov5-master]$ time python detect.py
detect: weights=weights/cpu/yolov5m6.onnx, source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=cpu, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2022-9-19 Python-3.8.12 torch-1.8.0 CPU
Loading weights/cpu/yolov5m6.onnx for ONNX Runtime inference...
image 1/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 131.5ms
image 2/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus1.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 105.7ms
image 3/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus2.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 102.8ms
image 4/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus3.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 102.5ms
image 5/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/bus4.jpg: 640x640 4 persons, 1 bus, 1 traffic light, 101.3ms
image 6/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 101.5ms
image 7/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane1.jpg: 640x640 2 persons, 1 tie, 107.8ms
image 8/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane2.jpg: 640x640 2 persons, 1 tie, 99.6ms
image 9/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane3.jpg: 640x640 2 persons, 1 tie, 114.2ms
image 10/10 /home/kevin_xie/yifeinfs/jianming_ge/code/MNN/yolov5-master/data/images/zidane4.jpg: 640x640 2 persons, 1 tie, 100.8ms
Speed: 7.2ms pre-process, 106.8ms inference, 2.5ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp51
real 0m18.033s
user 0m49.095s
sys 0m6.253s
您在 /var/spool/mail/jianming_ge 中有邮件
但是这种改法不具备通用性,不推荐!
速度方面总结来说 2080TI 上的表现
gpu 上
tensort > pt > torchscript > onnx
.pt 10ms tenserrt(float64) 9ms tensorrt(float32) 3.8 ms torchscript 13ms onnx 20ms
cpu 上
onnx > .pt > torchscript
onnx 100ms torchscript 900~1000ms .pt 600-800ms
转换tensort的时候,用上 --half 参数,是很好的,可以把推理速度从9.3ms拉低到3.8ms, 但是这里面我个人有点小担心,就是很大的权重系数,会不会被干掉????先存疑把唉~~
写在后面
GPU half false coco128下的表现 fp32
Benchmarks complete (311.34s)
Format Size (MB) mAP50-95 Inference time (ms)
0 PyTorch 69.0 0.57 12.20
1 TorchScript 136.9 0.57 9.87
2 ONNX 136.6 0.57 18.43
3 OpenVINO NaN NaN NaN
4 TensorRT 166.6 0.57 8.84
5 CoreML NaN NaN NaN
6 TensorFlow SavedModel 136.6 0.57 174.23
7 TensorFlow GraphDef 136.6 0.57 173.28
8 TensorFlow Lite NaN NaN NaN
9 TensorFlow Edge TPU NaN NaN NaN
10 TensorFlow.js NaN NaN NaN
11 PaddlePaddle NaN NaN NaN
GPU half True coco128下的表现 fp16
Benchmarks complete (548.96s)
Format Size (MB) mAP50-95 Inference time (ms)
0 PyTorch 69.0 0.5705 13.95
1 TorchScript 68.8 0.5704 9.78
2 ONNX 68.3 0.5673 16.25
3 OpenVINO NaN NaN NaN
4 TensorRT 72.3 0.5699 3.72
5 CoreML NaN NaN NaN
6 TensorFlow SavedModel 136.6 0.5701 177.53
7 TensorFlow GraphDef 136.6 0.5701 183.93
8 TensorFlow Lite NaN NaN NaN
9 TensorFlow Edge TPU NaN NaN NaN
10 TensorFlow.js NaN NaN NaN
11 PaddlePaddle NaN NaN NaN
CPU下的benchmark
Benchmarks complete (648.77s)
Format Size (MB) mAP50-95 Inference time (ms)
0 PyTorch 69.0 0.57 1196.95
1 TorchScript 136.9 0.57 1135.14
2 ONNX 136.6 0.57 127.53
3 OpenVINO NaN NaN NaN
4 TensorRT NaN NaN NaN
5 CoreML NaN NaN NaN
6 TensorFlow SavedModel 136.6 0.57 235.66
7 TensorFlow GraphDef 136.6 0.57 224.86
8 TensorFlow Lite NaN NaN NaN
9 TensorFlow Edge TPU NaN NaN NaN
10 TensorFlow.js NaN NaN NaN
11 PaddlePaddle NaN NaN NaN
结论:cpu下 onnx, gpu下tensorrt float16
不装了,yolov5官网已经都给弄好了,今天刚看文档才知道的
GPU benchmark 指引:https://github.com/ultralytics/yolov5/pull/6963
CPU benchmark 指引:https://github.com/ultralytics/yolov5/pull/6613
其它关于tensorrt很有用的指引:
https://docs.nvidia.com/deeplearning/tensorrt/release-notes/index.html
https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html