PPG & Phoneme Embedding & word Embedding总结
PPG,Phoneme Embedding, word Embedding等特征目前语音领域经常看到这些名词,到底都是什么东西呢?来总结一下。
PPG
PPG的全称是 phonetic posteriorgrams,即语音后验概率。
一句话概括就是:ASR的AM的输出,把声学特征转成发说话人无关的特征。
- PPG是一个时间对类别的矩阵,其表示对于一句话的每个特定时间帧,每个语音类别的后验概率。单个音素的后验概率作为时间的函数称为后验轨迹。
- 一般来讲从目标说话者的语音中,使用与说话者无关的自动语音识别(SI‑ASR)系统来提取PPG特征。提取到的PPG用作映射不同的说话者之间的关系。PPG包括与时间范围和语音类别范围相对应的值集合,该语音类别对应于音素状态。
如下图就是一个PPG特征,横坐标表示时间,纵坐标表示音素类别,每个坐标表示在给定时间点出现这个音素的后验概率大小,颜色越深,概率越大。

具体怎么提取?
有很多不同的提取方法,例如
[1]多说话人的ASR corpus数据集上进行训练。对于语音帧x,输入MFCC特征,计算音素集合中每个音素类别s。作者吧senone作为音素类别,具体实验是在TIMIT数据集上,用Kaldi的语音识别工具搭建AI-ASR系统。该ASR系统包含4层1024个神经单元的隐藏层。由于ASR任务是与说话人无关的,PPG特征因而也是说话人无关的特征。
[2]在[1]的基础上,同样使用PPG作为context embedding,改进了说话人embedding的方式。本文的PPG同样是使用Kaldi中的ASR模型(本文使用nnet2),在LibriSpeech上进行训练。声学特征上使用的是40维的MCEPs。
[3]也是针对说话人id特征进行改进,PPG提取特征与[1]一致,也是4层1024单元的隐藏层,使用13维的MFCC,MFCC的参数,汉明窗为25ms。
[4]首次提出双语PPG,是先分别英文和中文的ASR模型,两个ASR模型都是使用Kaldi工具,基于DNN-HMM搭建的,英文的ASR模型在WSJ数据集上训练,中文的ASR模型在AI-SHELL数据集上训练。英文的ASR模型包含5层的1024个神经单元的隐藏层,最终的softmax输出132个,中文的ASR模型包含6层的2048个神经单元的隐藏层,最终的softmax输出209个。最后将中文PPG特征和英文PPG特征堆叠即为341维度的双语特征。
[1] Sun L , Li K , Hao W , et al. Phonetic posteriorgrams for many-to-one voice conversion without parallel data training[C]// 2016 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2016.
[2] Mohammadi S H , Kim T . One-Shot Voice Conversion with Disentangled Representations by Leveraging Phonetic Posteriorgrams[C]// Interspeech 2019. 2019.
[3] Liu S , Zhong J , Sun L , et al. Voice Conversion Across Arbitrary Speakers Based on a Single Target-Speaker Utterance[C]// Interspeech 2018. 2018.
[4] Zhou Y , Tian X , Xu H , et al. Cross-lingual Voice Conversion with Bilingual Phonetic PosteriorGram and Average Modeling[C]// International Conference on Acoustic, Speech and Signal Processing (ICASSP). 2019.
Word Embedding
简介
word embedding简单翻译就是词嵌入,是NLP自然语言处理中对单词处理的一种方式。就是将自然语言表示的单词转换为计算机能够理解的向量或矩阵的形式。这种技术会把单词或者短语映射到一个n维的数值化向量,核心就是一种映射关系。
通俗易懂的一篇价绍:词嵌入
由于要考虑多种因素比如词的语义(同义词近义词)、语料中词之间的关系(上下文)和向量的维度(处理复杂度)等等,我们希望近义词或者表示同类事物的单词之间的距离可以理想地近,只有拿到很理想的单词表示形式,我们才更容易地去做翻译、问答、信息抽取等进一步的工作。
Word Embedding是基于分布式假设(distributional hypothesis):
- word embedding就是一个词的低维向量表示(一般用的维度可以是几十到几千)。有了一个词的向量之后,各种基于向量的计算就可以实施,如用向量之间的相似度来度量词之间的语义相关性。其基于的分布式假设就是出现在相同上下文(context)下的词意思应该相近。所有学习word embedding的方法都是在用数学的方法建模词和context之间的关系。
但是Word Embedding也有其局限性, 比如:
- 难以对词组做分布式表达
受限于上下文window的尺寸,有些词(例如好或坏)的上下文可能没什么不同甚至完全一样,这对情感分析任务的影响非常大。 - 此外,Word Embedding对于应用场景的依赖很强,所以针对特殊的应用场景可能需要重新训练,这样就会很消耗时间和资源,为此Bengio提出了基于负采样(negative sampling)的模型。
在Word Embedding之前,常用的方法有one-hot、n-gram、co-occurrence matrix,但是他们都有各自的缺点,下面会说明。2003年,Bengio提出了NLM,是为Word Embedding的想法的雏形,而在2013年,Mikolov对其进行了优化,即Word2vec,包含了两种类型,Continuous Bag-of-Words Model 和 skip-gram model。
方法
1.one-hot编码,也翻译为独热编码。
对语料库中的每个词都用一个n维的one hot向量表示,其中n为语料库中不同单词的个数。这种方法的原理是把语料库中的不同单词排成一列,对于单词A,它在语料库中的位置为k,则它的向量表示为第k位为1,其余为0的n维向量。比如:

这种方法简单易行,但存在语料库太长导致词向量十分冗长,同时不同的词之间无法展现关联信息。缺点总结如下:
- 语义的相似性,“woman”、“madam”、“lady”从语义上有共性,如都是女性,但one-hot相互之间独立,无法表示这种共性。
- 英语单词中的复数时态,我们不会在排序是就把同一单词的不同形态区别开来,继而再进行向量表示。
- 单词之间的位置关系,很多时候句内之间多个单词(比如术语)会同时出现多次,one-hot无法表示。
- 词向量长度很大,处理会很棘手。
其他方法详见:语义特征提取
2.word2vec
可以理解为onehot向量的一种降维处理,通过一种映射关系将一个n维的onehot向量转化为一个m维的空间实数向量(可以理解为原来坐标轴上的点被压缩嵌入到一个更加紧凑的空间内),由于onehot向量在矩阵乘法的特殊性,我们得到的表示映射关系的n*m的矩阵中的每k行,其实就表示语料库中的第k个单词。
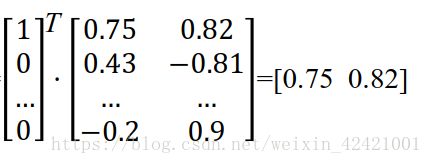
采用这种空间压缩降维的处理方式对语料库中的词进行训练,主要有两种方式:
(1)skip-gram神经网络训练模型:一种隐层为1的全连接神经网络,且隐层没有激活函数,输出层采用softmax分类器输出概率。输入为一个单词,输出为每个单词是输入单词的上下文的概率,真实值为输入单词的上下文中的某个单词。
主要通过skip-window控制,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。假如我们有一个句子“The dog barked at the mailman”,我们选取“dog”作为input word,那么我们最终获得窗口中的词(包括input word在内)就是[‘The’, ‘dog’,‘barked’, ‘at’]。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 (‘dog’, ‘barked’),(‘dog’, ‘the’)。
(2)CBOW:原理与skip-gram类似,但是输入为上下文信息,输出为信息中的中心词。
word2vec的优点:表示单词的向量维度降低,有益于后续RNN训练的收敛性。如果某两个单词的上下文很相似,则计算出来的表示这两个单词的特征向量会很相似,在空间中表示相近的物理位置,所以可以用两个单词生成的向量的长度表示其含义的远近。除了词向量的大小之外,词向量的方向还表示一种含义,若某两个词向量的方向相同,则其表示的含义也相近。如下图所示:

Phoneme Embedding
当研究者们将词嵌入应用于语音合成]和语音识别等语音相关任务时,发现结果并不像在NLP任务中那样好,其主要原因是词嵌入提取的语义和句法信息难以直接融入到与语音相关的任务中。
所以在语音领域,提出了基于音素的嵌入方法。与词嵌入不同的是,它考虑了代表音素序列发音的声语音字符来生成音素向量。在音素嵌入训练中,输入是音素标签,输出是相应的声学特征。词向量可以通过训练与语言中词汇和短语使用相关的神经网络模型来获取语义和句法信息。与之不同的是,音素嵌入的目的是捕捉声学信息(如语音特征),并将这些信息用音素向量表示出来。
参考较早的一篇文章:音素嵌入
具体方法:
在音素嵌入训练中,输入是音素标签,输出是相应的声学特征。具体来说,将音素标签的独热编码输入嵌入层,生成音素向量作为双向长短时记忆(BLSTM)循环神经网络(RNN)回归模型的输入,预测声学特征。音素嵌入分析表明,音素向量具有一些有趣的特征。声学属性相似的音素在生成的音素向量空间中余弦距离接近,经过kmeans聚类后趋于同类。
音素标签从何而来?
TTS中就从文本中提取,语音转换VC就从音频文件中提取。都是用神经网络提取。