【Pandas数据分析1】pandas数据结构
文章目录
- 一、pandas数据结构
-
- 1、Series对象
-
- 1.1 创建Series对象
- 1.2 索引
-
- 1.2.1 位置索引
- 1.2.2 标签索引
- 1.2.3 切片索引
- 1.2.4 获取Series的索引和值
- 2、DataFrame对象
-
- 2.1 创建DataFrame对象
-
- 2.1.1 列表方式
- 2.1.2 字典方式
- 2.1.3 注意事项
- 2.2 DataFrame重要属性
- 2.3 DataFrame重要函数
一、pandas数据结构
1、Series对象

- pandas库中的一种数据结构,类似于一维数组,由一组数据以及与这组数据有关的标签(索引)组成。
- Series对象可以存储整数、浮点数、字符串、python对象等多种数据类型的数据。
1.1 创建Series对象
pd.Series(data, index)
# data 数据
# index 索引
import pandas as pd
data = ['李光地', '张红云', '王鹏']
s = pd.Series(data=data, index=[1, 2, 3]) # 若不使用index,默认从0开始
print(s)
print(type(s))
1 李光地
2 张红云
3 王鹏
dtype: object
注:也可手动修改索引(索引不一定为数字)。
import pandas as pd
data = ['李光地', '张红云', '王鹏']
index = ['哈', '嘿', 'nao']
s = pd.Series(data=data, index=index)
print(s)
哈 李光地
嘿 张红云
nao 王鹏
dtype: object
1.2 索引
1.2.1 位置索引
import pandas as pd
data = ['李光地', '张红云', '王鹏']
s = pd.Series(data=data)
print(s[0])
李光地
1.2.2 标签索引
import pandas as pd
data = [333, 4444, 55555]
index = ['张三', '李四', '王五']
s = pd.Series(data=data, index=index)
print(s['李四'])
4444
获取多个标签索引值使用 [[标签索引1,标签索引2,…]],如下所示:
import pandas as pd
data = [333, 4444, 55555]
index = ['张三', '李四', '王五']
s = pd.Series(data=data, index=index)
# print(s['李四'])
print(s[['张三', '王五']])
张三 333
王五 55555
dtype: int64
1.2.3 切片索引
import pandas as pd
data = ['李光地', '张红云', '王鹏']
s = pd.Series(data=data)
print(s[0:2:1])
0 李光地
1 张红云
dtype: object
也可以对标签索引进行切片:
import pandas as pd
data = [333, 4444, 55555]
index = ['张三', '李四', '王五']
s = pd.Series(data=data, index=index)
print(s['张三':'王五':1])
张三 333
李四 4444
王五 55555
dtype: int64
注意:
- 对位置索引进行切片:含头不含尾。
- 对标签索引进行切片:含头含尾。
1.2.4 获取Series的索引和值
import pandas as pd
data = [333, 4444, 55555]
index = ['张三', '李四', '王五']
s = pd.Series(data=data, index=index)
print(s.index)
print(list(s.index))
print(s.values)
print(type(s.values))
Index(['张三', '李四', '王五'], dtype='object')
['张三', '李四', '王五']
[ 333 4444 55555]
<class 'numpy.ndarray'>
2、DataFrame对象
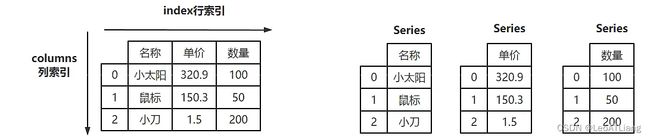
- pandas库中的一种数据结构,类似于二维表,由行和列组成。
- 与Series对象一样,支持多种数据类型。
2.1 创建DataFrame对象
pd.DataFrame(data, index, columns, dtype)
# data 数据
# index 行索引
# columns 列索引
# dtype 每一列数据的数据类型
2.1.1 列表方式
import pandas as pd
data = [['小太阳', 320.9, 100], ['鼠标', 150.3, 50], ['小刀', 1.5, 200]]
columns = ['名称', '单价', '数量']
df = pd.DataFrame(data=data, columns=columns)
print(df)
print(type(df))
名称 单价 数量
0 小太阳 320.9 100
1 鼠标 150.3 50
2 小刀 1.5 200
<class 'pandas.core.frame.DataFrame'>
2.1.2 字典方式
import pandas as pd
data = {
'名称': ['小太阳', '鼠标', '小刀'],
'单价': [320.9, 150.3, 1.5],
'数量': [100, 50, 200]
}
df = pd.DataFrame(data=data)
print(df)
名称 单价 数量
0 小太阳 320.9 100
1 鼠标 150.3 50
2 小刀 1.5 200
2.1.3 注意事项
当使用字典方式创建DataFrame对象时:
(1)如果列表(值)长度不一致,会报错ValueError: All arrays must be of the same length
import pandas as pd
data = {
'名称': ['小太阳', '鼠标', '小刀', '铅笔'], # 多一个铅笔
'单价': [320.9, 150.3, 1.5],
'数量': [100, 50, 200]
}
df = pd.DataFrame(data=data)
print(df)
Traceback (most recent call last):
...
ValueError: All arrays must be of the same length
(2)如果值是单个数据,则会自动添加
import pandas as pd
data = {
'名称': ['小太阳', '鼠标', '小刀'],
'单价': [320.9, 150.3, 1.5],
'数量': [100, 50, 200],
'公司': '东门超市'
}
df = pd.DataFrame(data=data)
print(df)
名称 单价 数量 公司
0 小太阳 320.9 100 东门超市
1 鼠标 150.3 50 东门超市
2 小刀 1.5 200 东门超市
2.2 DataFrame重要属性
| 序号 | 属性 | 描述 |
|---|---|---|
| 1 | values | 查看所有元素的值 |
| 2 | dtypes | 查看所有元素的类型 |
| 3 | index | 查看所有行名、重命名行名 |
| 4 | columns | 查看所有列名、重命名列名 |
| 5 | T | 行列数据转换 |
| 6 | head | 查看前N条数据,默认5条 |
| 7 | tai | 查看后N条数据,默认5条 |
| 8 | shape | 查看行数和列数:shape[0]表示行,shape[1]表示列 |
| 9 | info | 查看索引、数据类型和内存信息 |
import pandas as pd
data = [['小太阳', 320.9, 100], ['鼠标', 150.3, 50], ['小刀', 1.5, 200]]
columns = ['名称', '单价', '数量']
df = pd.DataFrame(data=data, columns=columns)
print(df)
名称 单价 数量
0 小太阳 320.9 100
1 鼠标 150.3 50
2 小刀 1.5 200
1、查看所有元素的值:
print(df.values)
[['小太阳' 320.9 100]
['鼠标' 150.3 50]
['小刀' 1.5 200]]
2、查看所有元素的类型:
print(df.dtypes)
名称 object
单价 float64
数量 int64
dtype: object
3、查看所有行名:
print(df.index)
print(list(df.index))
RangeIndex(start=0, stop=3, step=1)
[0, 1, 2]
4、查看所有列名:
print(df.columns)
Index(['名称', '单价', '数量'], dtype='object')
5、行列数据转换:
pd.set_option('display.unicode.east_asian_width', True) # 规整格式
new_df = df.T
print(new_df)
0 1 2
名称 小太阳 鼠标 小刀
单价 320.9 150.3 1.5
数量 100 50 200
6、查看前N条数据:
print(df.head(1))
名称 单价 数量
0 小太阳 320.9 100
7、查看后N条数据:
print(df.tail(1))
名称 单价 数量
2 小刀 1.5 200
8、查看行数和列数:
print('行', df.shape[0], '列', df.shape[1])
行 3 列 3
9、查看索引、数据类型和内存信息:
print(df.info)
<bound method DataFrame.info of 名称 单价 数量
0 小太阳 320.9 100
1 鼠标 150.3 50
2 小刀 1.5 200>
2.3 DataFrame重要函数
| 序号 | 函数 | 描述 |
|---|---|---|
| 1 | describe() | 查看每列的统计汇总信息,DataFrame类型 |
| 2 | count() | 返回每一列的非空值的个数 |
| 3 | sum() | 返回每一列的和,无法计算返回空值 |
| 4 | max() | 返回每一列的最大值 |
| 5 | min() | 返回每一列的最小值 |
import pandas as pd
data = [['小太阳', 320.9, 100], ['鼠标', 150.3, 50], ['小刀', 1.5, 200]]
columns = ['名称', '单价', '数量']
df = pd.DataFrame(data=data, columns=columns)
print(df)
# 1、查看每列的统计汇总信息:
print(df.describe())
# 2、返回每一列的非空值的个数:
print(df.count())
# 3、返回每一列的和:
print(df.sum())
# 4、返回每一列的最大值:
print(df.max())
# 5、返回每一列的最小值:
print(df.min())
名称 单价 数量
0 小太阳 320.9 100
1 鼠标 150.3 50
2 小刀 1.5 200
单价 数量
count 3.000000 3.000000
mean 157.566667 116.666667
std 159.823945 76.376262
min 1.500000 50.000000
25% 75.900000 75.000000
50% 150.300000 100.000000
75% 235.600000 150.000000
max 320.900000 200.000000
名称 3
单价 3
数量 3
dtype: int64
名称 小太阳鼠标小刀
单价 472.7
数量 350
dtype: object
名称 鼠标
单价 320.9
数量 200
dtype: object
名称 小刀
单价 1.5
数量 50
dtype: object