机器学习---决策树(ID3,C5.0,CART)
目录
1. 什么是决策树
2. 决策树介绍
3. ID3 算法
信息熵
代码实现信息熵的计算:
信息增益
python实现信息增益公式
4. C4.5算法
5. C5.0算法
6. CART算法
基尼指数 Gini指标
Python代码实现信息增益的计算
7. 连续属性离散化
8. 过拟合的解决方案
9、构建决策树模型
10. 例子
1. 准备数据及读取
2. 决策树的特征向量化
3. 决策树训练
4. 决策树可视化
5 预测结果
8. 如果你用基尼指数, 也就是CART算法
11. 例子 -基于Iris数据集的训练
1. 什么是决策树
决策树是什么,我们来“决策树”这个词进行分词,那么就会是决策/树。大家不妨思考一下,重点是决策还是树呢?其实啊,决策树的关键点在树上。
我们平时写代码的那一串一串的If Else其实就是决策树的思想了。看下面的图是不是觉得很熟悉呢?
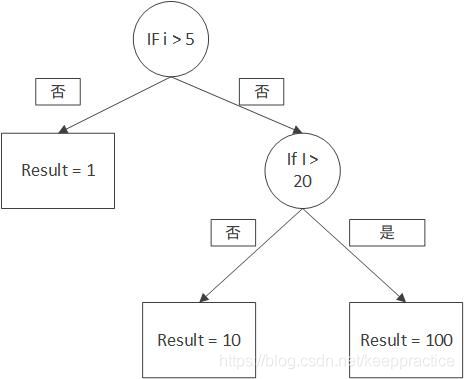
2. 决策树介绍
决策树之所以叫决策树,就是因为它的结构是树形状的,如果你之前没了解过树这种数据结构,那么你至少要知道以下几个名词是什么意思。
- 根节点:最顶部的那个节点
- 叶子节点:每条路径最末尾的那个节点,也就是最外层的节点
- 非叶子节点:一些条件的节点,下面会有更多分支,也叫做分支节点
- 分支:也就是分叉
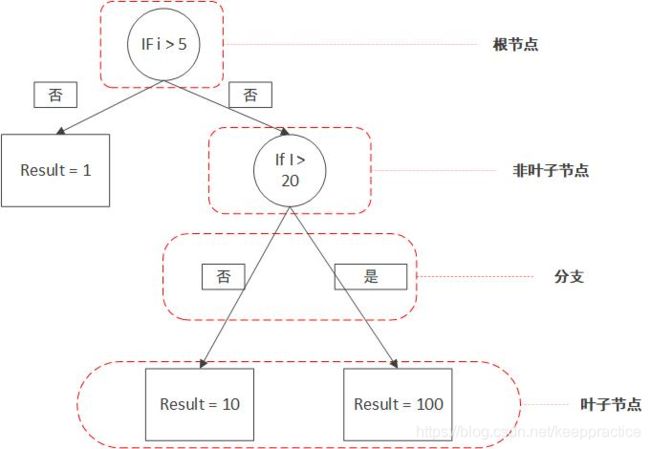
3. ID3 算法
- ID3算法是在每个结点处选取能获得最高信息增益的分支属性进行分裂
- 在每个决策结点处划分分支、选取分支属性的目的是将整个决策树的样本
纯度提升 - 衡量样本集合纯度的指标则是
信息熵
信息熵 :一个系统越是有序,比如上边说的太阳东升西落,信息熵就越低;相反,一个系统越是混乱,信息熵就越高。所以,信息熵被认为是一个系统有序程度的度量。
信息熵就是用来描述系统信息量的不确定度。信息熵越高,表示随机变量X是均匀分布,各种取值情况都是等概率出现的;随机变量X取值不是等概率出现,有的事件概率大,有的事件概率小。请看下面的图:右边的图,信息熵小但是表示的信息量很大。
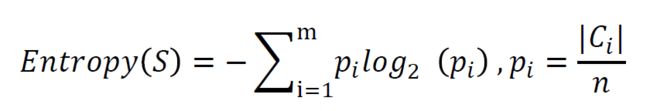
举例来说,如果有一个大小为10的布尔值样本集S,其中有6个真值、4个
假值,那么该布尔型样本分类的熵为:
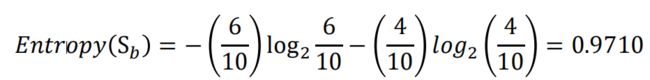
代码实现信息熵的计算:
import numpy as np
import pandas as pd
# 1. 准备数据
data = pd.DataFrame(
{'学历': ['专科', '专科', '专科', '专科', '专科', '本科', '本科', '本科', '本科', '本科', '研究生', '研究生', '研究生', '研究生', '研究生'],
'婚否': ['否', '否', '是', '是', '否', '否', '否', '是', '否', '否', '否', '否', '是', '是', '否'],
'是否有车': ['否', '否', '否', '是', '否', '否', '否', '是', '是', '是', '是', '是', '否', '否', '否'],
'收入水平': ['中', '高', '高', '中', '中', '中', '高', '高', '很高', '很高', '很高', '高', '高', '很高', '中'],
'类别': ['否', '否', '是', '是', '否', '否', '否', '是', '是', '是', '是', '是', '是', '是', '否']})
# 2. 定义信息熵函数
# 定义计算信息熵的函数:计算Infor(D)
def infor(data):
a = pd.value_counts(data) / len(data)
return sum(np.log2(a) * a * (-1))
# 数据测试
# print(infor(data["学历"])) #测试结果为: 1.584962500721156
信息增益
- 计算分支属性对于样本集分类好坏程度的度量——信息增益
- 由于分裂后样本集的纯度提高,则样本集的熵降低,熵降低的值即为该分 裂方法的信息增益

脊椎动物分类训练样本集
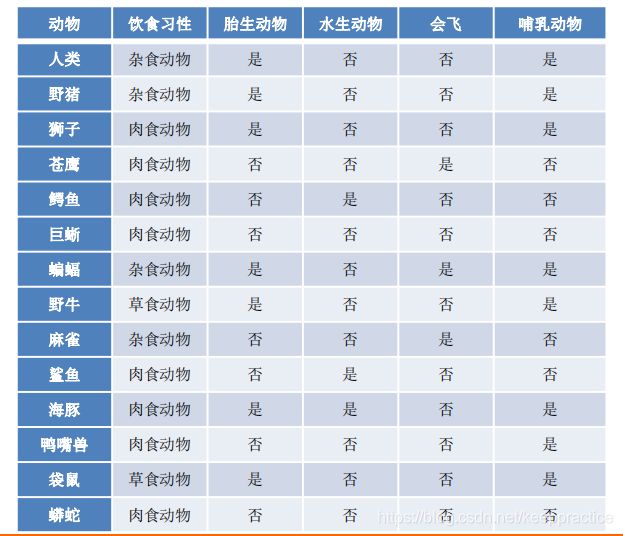
共有14个样本,其中8个正例,6个反例,设此样本集为 S,则分裂前的熵值为

脊椎动物训练样本集以“饮食习性”作为分支属性的分裂情况
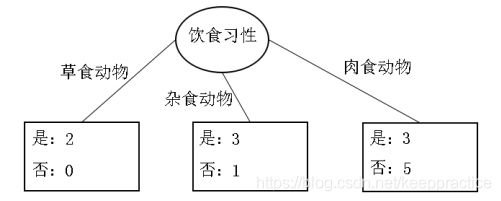
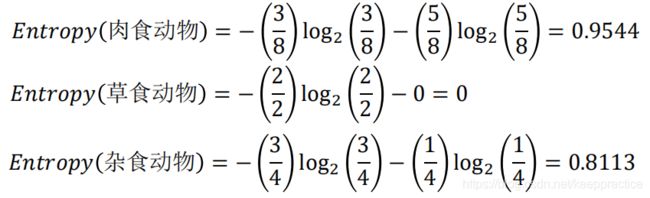
设“饮食习性”属性为Y,由此可以计算得出,作为分支属性进行分裂之后的
信息增益为
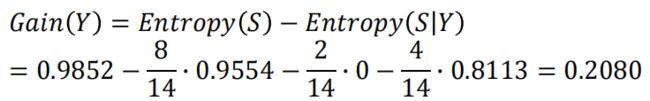
同理, 计算可得,以“胎生动物”“水生动物”“会飞”作为分支属性时的信息 增益分别为0.6893、0.0454、0.0454
由此可知“胎生动物”作为分支属性时能获得最大的信息增益,即具有最强的区分样本的能力,所以在此选择使用“胎生动物”作为分支属性对根结点进行划分
由根结点通过计算信息增益选取合适的属性进行分裂,若新生成的结点的分类属性不唯一,则对新生的结点继续进行分裂,不断重复此步骤,直至所有样本属于同 一类,或者达到要求的分类条件为止
python实现信息增益公式
# 3. 定义信息增益函数
# 定义计算信息增益的函数:计算g(D|A)
def g(data, str1, str2):
e1 = data.groupby(str1).apply(lambda x: infor(x[str2]))
p1 = pd.value_counts(data[str1]) / len(data[str1])
# 计算Infor(D|A)
e2 = sum(e1 * p1)
return infor(data[str2]) - e2
print("学历信息增益:{}".format(g(data, "学历", "类别")))
# 输出结果为:学历信息增益:0.08300749985576883
4. C4.5算法
C4.5算法总体思路与ID3类似,都是通过构造决策树进行分类,其区别在于分支的处理,在分支属性的选取上,ID3算法使用信息增益作为度量,而C4.5算法引入了信息增益率作为度量

由信息增益率公式中可见,当比较大时,信息增益率会明显降低,从而在一定程度上能够解决ID3算法存在的往往选择取值较多的分支属性的问题
在前面例子中,假设选择“饮食习性”作为分支属性,其信息增益率为
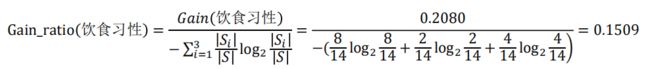
5. C5.0算法
C5.0算法是Quinlan在C4.5算法的基础上提出的商用改进版本,目的是对含有 大量数据的数据集进行分析
C5.0算法与C4.5算法相比有以下优势:
– 决策树构建时间要比C4.5算法快上数倍,同时生成的决策树规模也更小,拥有更少的叶子结
点数
– 使用了提升法(boosting),组合多个决策树来做出分类,使准确率大大提高
– 提供可选项由使用者视情况决定,例如是否考虑样本的权重、样本错误分类成本等
6. CART算法
基尼指数 Gini指标
CART算法在分支处理中分支属性的度量指标
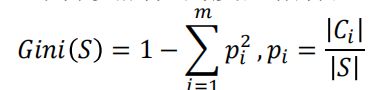
在前面例子中,假设选择“会飞”作为分支属性,其Gini指标为
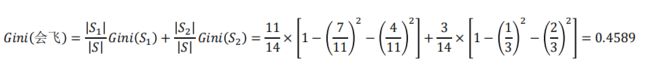
Python代码实现信息增益的计算
# 4. 定义信息增益率函数
# 定义计算信息增益率的函数:计算gr(D,A)
def gr(data, str1, str2):
return g(data, str1, str2) / infor(data[str1])
print("学历信息增益率:", gr(data, "学历", "类别"))
# 输出结果为:学历信息增益率: 0.05237190142858302
7. 连续属性离散化
如果是连续的数值型是如年龄,我们一般把它离散化,如离散化为幼年,中年,老年
因为你不可能让把每个年龄都分成一个特征,那样会很多,也没必要。
8. 过拟合的解决方案
一方面要注意数据训练集的质量,选取具有代表性样本的训练样本集
要避免决策树过度增长,通过限制树的深度来减少数据中的噪声对于决策树构建的影响,一般可以采取剪枝的方法
剪枝包括预剪枝和后剪枝两类
预剪枝的思路是提前终止决策树的增长,在形成完全拟合训练样本集的决 策树之前就停止树的增长,避免决策树规模过大而产生过拟合
后剪枝策略先让决策树完全生长,之后针对子树进行判断,用叶子结点或者子树中最常用的分支替换子树,以此方式不断改进决策树,直至无法改进为止
9、构建决策树模型
由于选取的是类型标签不是数值标签,这里导入的是决策树分类器,如果要进行决策树回归的话就导入下面注释的语句代码
from sklearn.tree import DecisionTreeClassifier
# 如果是回归问题,就要引入回归模型#from sklearn.tree import DecisionTreeRegressor
# 建立模型
clf_tree = DecisionTreeClassifier(criterion='gini',
splitter='best',
max_depth=3,
min_samples_split=2,
min_samples_leaf=5,
max_features=None,
max_leaf_nodes=10,
min_impurity_decrease=0.0,
min_impurity_split=None,
class_weight=None)
# 训练决策树模型
clf_tree.fit(x,y)
print(clf_tree)
–> 输出的结果为:
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=3,
max_features=None, max_leaf_nodes=10,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
决策树参数讲解
criterion:划分算法 默认是gini,另外一种是entropy就是信息增益, 回归模型可以选择mse或mae
splitter:两个选择,best(中小型数据)或者random(大数据)。
max_features:控制所搜的特征数量(一般是默认,如果建模数据量过大,建议调整一下这个参数)
max_depth: 控制树的深度(控制过拟合的重要参数,过拟合限制,欠拟合就增加深度)
min_samples_split: 任意节点样本量达到多少的时候就不再分裂(推荐默认值,也是控制过拟合的,适用大数据)
min_samples_leaf:每一个叶子上最少的样本数(控制最后一个叶节点的样本量,一般提高这个值可以防止过拟合)
max_leaf_nodes:最大叶节点数量(切分数据集的最大的叶节点的数量,有个上界)
min_impurity_decrease: 切分点不纯度最小减少程度(后剪枝的控制参数)
min_impurity_split: 切分点最小不纯度(预剪枝的控制参数)
class_weight:指定样本各类别的的权重(分类模型特有的,防止某个样本的权重过大,导致决策树过于偏向这个样本特征)
10. 例子
安装panda 和 scikit-learn 如果你没有安装的话
conda install pandas
conda install scikit-learn
1. 准备数据及读取
季节 时间已过 8 点 风力情况 要不要赖床
spring no breeze yes
winter no no wind yes
autumn yes breeze yes
winter no no wind yes
summer no breeze yes
winter yes breeze yes
winter no gale yes
winter no no wind yes
spring yes no wind no
summer yes gale no
summer no gale no
autumn yes breeze no
2. 决策树的特征向量化
sklearn的DictVectorizer能对字典进行向量化。什么叫向量化呢?比如说你有季节这个属性有[春,夏,秋,冬]四个可选值,那么如果是春季,就可以用[1,0,0,0]表示,夏季就可以用[0,1,0,0]表示。不过在调用DictVectorizer它会将这些属性打乱,不会按照我们的思路来运行,但我们也可以一个方法查看,我们看看代码就明白了
通过DictVectorizer,我们就能够把字符型的数据,转化成0 1的矩阵,方便后面进行运算。额外说一句,这种转换方式其实就是one-hot编码。
import pandas as pd
import sklearn as sklearn
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
# pandas 读取 csv 文件,header = None 表示不将首行作为列
data = pd.read_csv('data/laic.csv', header=None)
# 指定列
data.columns = ['season', 'after 8', 'wind', 'lay bed']
# sparse=False意思是不产生稀疏矩阵
vec = DictVectorizer(sparse=False)
# 先用 pandas 对每行生成字典,然后进行向量化
feature = data[['season', 'after 8', 'wind']]
X_train = vec.fit_transform(feature.to_dict(orient='record'))
# 打印各个变量
print('show feature\n', feature)
print('show vector\n', X_train)
print('show vector name\n', vec.get_feature_names())
print('show vector name\n', vec.vocabulary_)
执行结果
season after 8 wind
0 spring no breeze
1 winter no no wind
2 autumn yes breeze
3 winter no no wind
4 summer no breeze
5 winter yes breeze
6 winter no gale
7 winter no no wind
8 spring yes no wind
9 summer yes gale
10 summer no gale
11 autumn yes breeze
show vector
[[1. 0. 0. 1. 0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0. 1. 0. 0. 1.]
[0. 1. 1. 0. 0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 0. 1. 0. 1. 0. 0.]
[0. 1. 0. 0. 0. 1. 1. 0. 0.]
[1. 0. 0. 0. 0. 1. 0. 1. 0.]
[1. 0. 0. 0. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 0. 0. 1. 0.]
[0. 1. 1. 0. 0. 0. 1. 0. 0.]]
show vector name
['after 8=no', 'after 8=yes', 'season=autumn', 'season=spring', 'season=summer','season=winter', 'wind=breeze', 'wind=gale', 'wind=no wind']
show vector name
{'season=spring': 3, 'after 8=no': 0, 'wind=breeze': 6, 'season=winter': 5, 'wind=no wind': 8, 'season=autumn': 2, 'after 8=yes': 1, 'season=summer': 4, 'wind=gale': 7}
3. 决策树训练
Y_train = data['lay bed']
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(X_train, Y_train)4. 决策树可视化
当完成一棵树的训练的时候,我们也可以让它可视化展示出来,不过sklearn没有提供这种功能,它仅仅能够让训练的模型保存到dot文件中。但我们可以借助其他工具让模型可视化,先看保存到dot的代码:
with open("out.dot", 'w') as f :
f = tree.export_graphviz(clf, out_file = f,
feature_names = vec.get_feature_names())5 预测结果
result = clf.predict([[1., 0., 0. ,1. , 0. , 0. , 1. , 0. , 0.]])
print(result)然后可以执行下面命令生成一个out.pdf
dot out.dot -T pdf -o out.pdf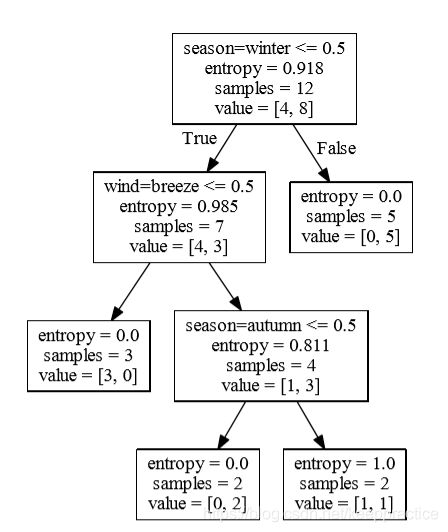
8. 如果你用基尼指数, 也就是CART算法
只需要把entropy 改成 gini就可以了
clf = tree.DecisionTreeClassifier(criterion='gini')
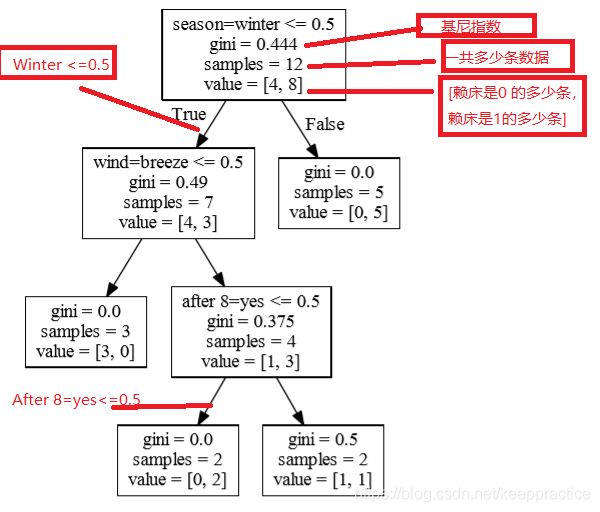
11. 例子 -基于Iris数据集的训练
from sklearn import datasets
from sklearn import tree
import pydotplus
from sklearn.externals.six import StringIO
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
# 特征
iris_feature = iris.data
# 分类标签
iris_label = iris.target
iris_target_name=iris['target_names']
feature_names = iris['feature_names']
# 划分
X_train, X_test, Y_train, Y_test = train_test_split(iris_feature, iris_label, test_size=0.3, random_state=42)
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(X_train, Y_train)
s = clf.score(X_test, Y_test)
print(s)#输出结果
0.9777777777777777决策树(decision tree)是一种基本的分类与回归方法。决策树学习通常包括三个步骤:特征选择,决策树的生成、决策树的修剪。而随机森林则是由多个决策树所构成的一种分类器,更准确的说,随机森林是由多个弱分类器组合形成的强分类器(后面讲到随机森林)。