【hw1】b站刘二大人,第八讲课后题Titanic
【pre】
代码没啥新意,很多人都分享过了。主要想记录一下自己遇到的bug以及收获。
【bug】
1. RuntimeError: mat1 and mat2 shapes cannot be multiplied (32x5 and 6x3)
nn.linear() 中,两参数(矩阵)的维度不一致。
FC公式:y=w*x+b,所以这里报错的原因是w和x维度不一致。
print了一下,发现x是5列,但源代码里作者认为是6列——“五个特征转化为了6维,因为get_dummies将性别这一个特征用两个维度来表示,即男性[1,0],女性[0,1]”。
可能是数据集的差异吧,我这里print后发现,性别直接用了0,1来表示,所以还是5维。
于是把线性层的输入改成了5。
问题解决,跑起来了。
【tips】
1.离散数据编码方式总结
根据某一feature的值之间有无大小关系,从而决定使用数字编码或是one-hot编码方式。(参考
2.优化神经网络(参考)
(1)梯度下降算法(本文用了mini-batch)

(2)BP算法
在网络的训练过程中经过前向传播后得到的最终结果跟训练样本的真实值总是存在一定误差,这个误差便是损失函数。想要减小这个误差,就从后往前,依次求各个参数的偏导,这就是反向传播(Back Propagation)。BP算法与梯度下降算法相结合,对网络中所有权重计算损失函数的梯度,并利用梯度值来更新权值以最小化损失函数。
(3)学习率退火(参考1,2)
每一个参数对目标函数的依赖不同——有的参数已经优化到了极小值附近,有的参数仍然有很大的梯度,所以不能使用统一学习率。
学习率太小,会有一个很慢的收敛速度,学习率很大,会使已经优化的差不多的参数不稳定。
一般合理的做法是对每一个参数设置不同的学习率。
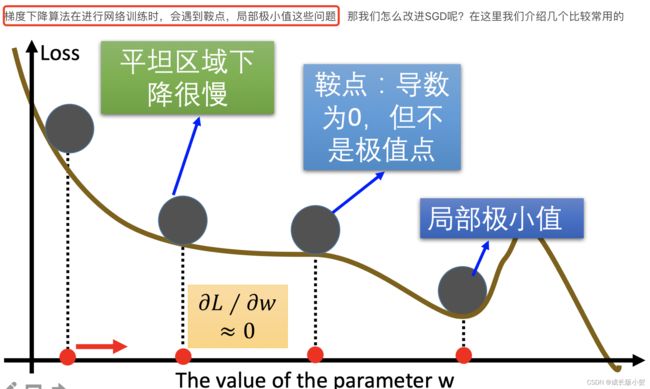
*优化梯度下降算法:
-动量算法(Momentum)——解决鞍点
-adaGrad
-RMSProp
-Adam
【代码】
'''
b站刘二大人第8讲的课后作业
'''
import numpy as np
import pandas as pd
import torch
import matplotlib.pyplot as plt
from torch.utils.data import Dataset # 抽象类 被继承
from torch.utils.data import DataLoader # 加载数
'''
prepare dataset
'''
class TitanicDataset(Dataset):
def __init__(self,filepath):
xy = pd.read_csv(filepath)
self.len = xy.shape[0] # xy.shape()可以得到xy的行列,[0]取行,[1]取列
#选取需要的特征
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
# xy[feature]的类型是DataFrame,先进行独热表示,然后转成array,最后转成tensor用于进行矩阵计算。
self.x_data = torch.from_numpy(np.array(pd.get_dummies(xy[feature]))) # pd.get_dummies(): 将原本不好区分的数据进行再次打标签区分,从而得到更细的数据。
self.y_data = torch.from_numpy(np.array(xy["Survived"]))
print('xy[feature]=',xy[feature])
print('pd.get_dummies()=',pd.get_dummies(xy[feature]))
print('arry=',np.array(pd.get_dummies(xy[feature])))
print('x_data=',self.x_data)
def __getitem__(self,index): # 魔法函数,支持 dataset[index]
return self.x_data[index],self.y_data[index]
def __len__(self): # 魔法函数, 支持 len()
return self.len
# 实例化自定义类,并传入数据地址
dataset = TitanicDataset('titanic.csv')
# num_workers是否要进行多线程服务,num_worker=2 就是2个进程并行运行
# 采用 Mini-Batch 的训练方法
train_loader = DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 2) # 双线程
'''
design model
'''
class Model(torch.nn.Module): # 设置要从torch神经网络模块中要继承的模型函数
def __init__(self):
super(Model,self).__init__() # 对继承于torch.nn的父模块类进行初始化
self.linear1 = torch.nn.Linear(5,3) # 输入5 输出3;五个特征转化为了6维,因为get_dummies将性别这一个特征用两个维度来表示,即男性[1,0],女性[0,1]
self.linear2 = torch.nn.Linear(3,1)
self.sigmoid = torch.nn.Sigmoid() # 调用nn下的模块,作为运算模块
# 正向传播
def forward(self,x):
x= self.sigmoid(self.linear1(x))
print('-----x1=',x)
x= self.sigmoid(self.linear2(x))
print('-----x2=',x)
return x
# 预测函数, 用在测试集
def predict(self,x):
with torch.no_grad(): #上下文管理器,被该语句 wrap 起来的部分将不会 track 梯度。
x=self.sigmoid(self.linear1(x))
x=self.sigmoid(self.linear2(x))
y=[]
# 根据二分法原理,划分y的值
for i in x:
if i >0.5:
y.append(1)
else:
y.append(0)
return y
model = Model()
'''
criterion & optimizer
'''
criterion = torch.nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
'''
training cycle + testing
'''
# 防止windows系统报错
if __name__ == '__main__':
loss_lst = []
# 采用 Mini-Batch 的方法训练, 要采用多层嵌套循环
# 所有数据都跑100遍
for epoch in range(100):
sum = 0
# data从train_loader中取出数据(取出的是一个元组数据):(x,y)
# enumerate可以获得当前是第几次迭代,内部迭代每一次跑一个Mini-Batch
for i, data in enumerate(train_loader, 0):
# 准备数据 inputs 获取到 data 中的 x 的值,labels 获取到 data 中的 y 值
inputs, labels = data
inputs = inputs.float()
labels = labels.float()
# 正向传播
y_pred = model(inputs)
y_pred = y_pred.squeeze(-1) # 前向输出结果是[[12],[34],[35],[23],[11]]这种,需要将这个二维矩阵转换成一行[12,34,35,23,11]
loss = criterion(y_pred, labels)
print('epoch, i, loss.item()=',epoch, i, loss.item())
sum += loss.item()
# 反向传播
optimizer.zero_grad()
loss.backward()
# 更新
optimizer.step()
loss_lst.append(sum / train_loader.batch_size)
# 可视化
num_lst = [i for i in range(len(loss_lst))]
plt.plot(num_lst, loss_lst)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
# 测试集数据准备
test_data = pd.read_csv('titanic.csv') #读取数据
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"] # 和训练集保持特征的一致性 选取相同的项
test = torch.from_numpy(np.array(pd.get_dummies(test_data[feature]))) # 与训练集保持一致
# 进行预测,并将结果以CSV格式保存
y = model.predict(test.float()) # 浮点数
outputs = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': y})
outputs.to_csv('predict_titantic', index=False) # index=False 代表不保存索
# 观察一下结果
outputs.head()